 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongwei Bran Li
The Brain Tumor Segmentation in Pediatrics (BraTS-PEDs) Challenge: Focus on Pediatrics (CBTN-CONNECT-DIPGR-ASNR-MICCAI BraTS-PEDs)
Apr 29, 2024
Pediatric tumors of the central nervous system are the most common cause of cancer-related death in children. The five-year survival rate for high-grade gliomas in children is less than 20%. Due to their rarity, the diagnosis of these entities is often delayed, their treatment is mainly based on historic treatment concepts, and clinical trials require multi-institutional collaborations. Here we present the CBTN-CONNECT-DIPGR-ASNR-MICCAI BraTS-PEDs challenge, focused on pediatric brain tumors with data acquired across multiple international consortia dedicated to pediatric neuro-oncology and clinical trials. The CBTN-CONNECT-DIPGR-ASNR-MICCAI BraTS-PEDs challenge brings together clinicians and AI/imaging scientists to lead to faster development of automated segmentation techniques that could benefit clinical trials, and ultimately the care of children with brain tumors.
Multi-Center Fetal Brain Tissue Annotation (FeTA) Challenge 2022 Results
Feb 08, 2024Segmentation is a critical step in analyzing the developing human fetal brain. There have been vast improvements in automatic segmentation methods in the past several years, and the Fetal Brain Tissue Annotation (FeTA) Challenge 2021 helped to establish an excellent standard of fetal brain segmentation. However, FeTA 2021 was a single center study, and the generalizability of algorithms across different imaging centers remains unsolved, limiting real-world clinical applicability. The multi-center FeTA Challenge 2022 focuses on advancing the generalizability of fetal brain segmentation algorithms for magnetic resonance imaging (MRI). In FeTA 2022, the training dataset contained images and corresponding manually annotated multi-class labels from two imaging centers, and the testing data contained images from these two imaging centers as well as two additional unseen centers. The data from different centers varied in many aspects, including scanners used, imaging parameters, and fetal brain super-resolution algorithms applied. 16 teams participated in the challenge, and 17 algorithms were evaluated. Here, a detailed overview and analysis of the challenge results are provided, focusing on the generalizability of the submissions. Both in- and out of domain, the white matter and ventricles were segmented with the highest accuracy, while the most challenging structure remains the cerebral cortex due to anatomical complexity. The FeTA Challenge 2022 was able to successfully evaluate and advance generalizability of multi-class fetal brain tissue segmentation algorithms for MRI and it continues to benchmark new algorithms. The resulting new methods contribute to improving the analysis of brain development in utero.
Benchmarking the CoW with the TopCoW Challenge: Topology-Aware Anatomical Segmentation of the Circle of Willis for CTA and MRA
Dec 29, 2023The Circle of Willis (CoW) is an important network of arteries connecting major circulations of the brain. Its vascular architecture is believed to affect the risk, severity, and clinical outcome of serious neuro-vascular diseases. However, characterizing the highly variable CoW anatomy is still a manual and time-consuming expert task. The CoW is usually imaged by two angiographic imaging modalities, magnetic resonance angiography (MRA) and computed tomography angiography (CTA), but there exist limited public datasets with annotations on CoW anatomy, especially for CTA. Therefore we organized the TopCoW Challenge in 2023 with the release of an annotated CoW dataset and invited submissions worldwide for the CoW segmentation task, which attracted over 140 registered participants from four continents. TopCoW dataset was the first public dataset with voxel-level annotations for CoW's 13 vessel components, made possible by virtual-reality (VR) technology. It was also the first dataset with paired MRA and CTA from the same patients. TopCoW challenge aimed to tackle the CoW characterization problem as a multiclass anatomical segmentation task with an emphasis on topological metrics. The top performing teams managed to segment many CoW components to Dice scores around 90%, but with lower scores for communicating arteries and rare variants. There were also topological mistakes for predictions with high Dice scores. Additional topological analysis revealed further areas for improvement in detecting certain CoW components and matching CoW variant's topology accurately. TopCoW represented a first attempt at benchmarking the CoW anatomical segmentation task for MRA and CTA, both morphologically and topologically.
Resolution- and Stimulus-agnostic Super-Resolution of Ultra-High-Field Functional MRI: Application to Visual Studies
Nov 25, 2023High-resolution fMRI provides a window into the brain's mesoscale organization. Yet, higher spatial resolution increases scan times, to compensate for the low signal and contrast-to-noise ratio. This work introduces a deep learning-based 3D super-resolution (SR) method for fMRI. By incorporating a resolution-agnostic image augmentation framework, our method adapts to varying voxel sizes without retraining. We apply this innovative technique to localize fine-scale motion-selective sites in the early visual areas. Detection of these sites typically requires a resolution higher than 1 mm isotropic, whereas here, we visualize them based on lower resolution (2-3mm isotropic) fMRI data. Remarkably, the super-resolved fMRI is able to recover high-frequency detail of the interdigitated organization of these sites (relative to the color-selective sites), even with training data sourced from different subjects and experimental paradigms -- including non-visual resting-state fMRI, underscoring its robustness and versatility. Quantitative and qualitative results indicate that our method has the potential to enhance the spatial resolution of fMRI, leading to a drastic reduction in acquisition time.
3D Arterial Segmentation via Single 2D Projections and Depth Supervision in Contrast-Enhanced CT Images
Sep 15, 2023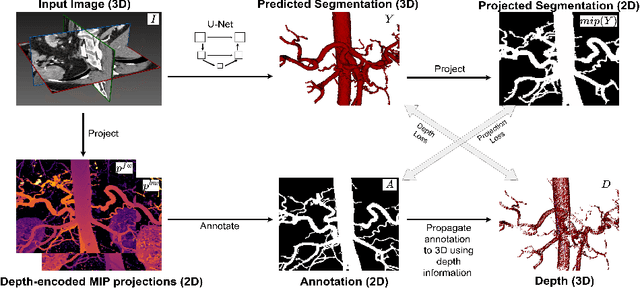
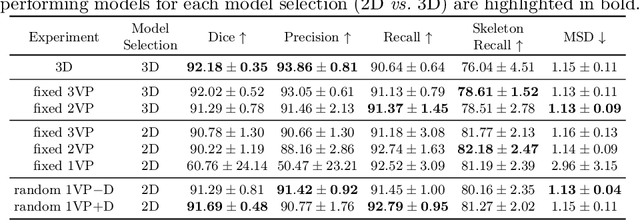
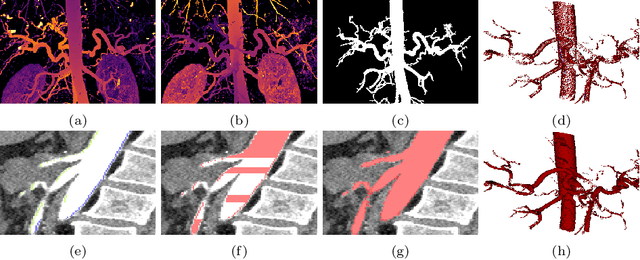
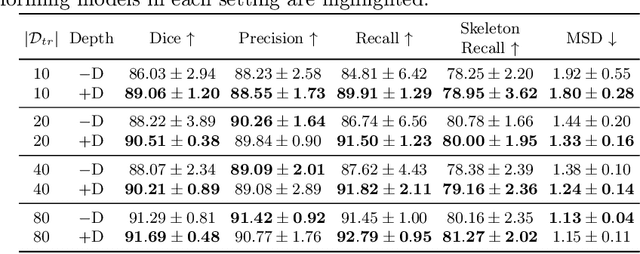
Automated segmentation of the blood vessels in 3D volumes is an essential step for the quantitative diagnosis and treatment of many vascular diseases. 3D vessel segmentation is being actively investigated in existing works, mostly in deep learning approaches. However, training 3D deep networks requires large amounts of manual 3D annotations from experts, which are laborious to obtain. This is especially the case for 3D vessel segmentation, as vessels are sparse yet spread out over many slices and disconnected when visualized in 2D slices. In this work, we propose a novel method to segment the 3D peripancreatic arteries solely from one annotated 2D projection per training image with depth supervision. We perform extensive experiments on the segmentation of peripancreatic arteries on 3D contrast-enhanced CT images and demonstrate how well we capture the rich depth information from 2D projections. We demonstrate that by annotating a single, randomly chosen projection for each training sample, we obtain comparable performance to annotating multiple 2D projections, thereby reducing the annotation effort. Furthermore, by mapping the 2D labels to the 3D space using depth information and incorporating this into training, we almost close the performance gap between 3D supervision and 2D supervision. Our code is available at: https://github.com/alinafdima/3Dseg-mip-depth.
MedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023


We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
Self-pruning Graph Neural Network for Predicting Inflammatory Disease Activity in Multiple Sclerosis from Brain MR Images
Aug 31, 2023



Multiple Sclerosis (MS) is a severe neurological disease characterized by inflammatory lesions in the central nervous system. Hence, predicting inflammatory disease activity is crucial for disease assessment and treatment. However, MS lesions can occur throughout the brain and vary in shape, size and total count among patients. The high variance in lesion load and locations makes it challenging for machine learning methods to learn a globally effective representation of whole-brain MRI scans to assess and predict disease. Technically it is non-trivial to incorporate essential biomarkers such as lesion load or spatial proximity. Our work represents the first attempt to utilize graph neural networks (GNN) to aggregate these biomarkers for a novel global representation. We propose a two-stage MS inflammatory disease activity prediction approach. First, a 3D segmentation network detects lesions, and a self-supervised algorithm extracts their image features. Second, the detected lesions are used to build a patient graph. The lesions act as nodes in the graph and are initialized with image features extracted in the first stage. Finally, the lesions are connected based on their spatial proximity and the inflammatory disease activity prediction is formulated as a graph classification task. Furthermore, we propose a self-pruning strategy to auto-select the most critical lesions for prediction. Our proposed method outperforms the existing baseline by a large margin (AUCs of 0.67 vs. 0.61 and 0.66 vs. 0.60 for one-year and two-year inflammatory disease activity, respectively). Finally, our proposed method enjoys inherent explainability by assigning an importance score to each lesion for the overall prediction. Code is available at https://github.com/chinmay5/ms_ida.git
Global k-Space Interpolation for Dynamic MRI Reconstruction using Masked Image Modeling
Jul 24, 2023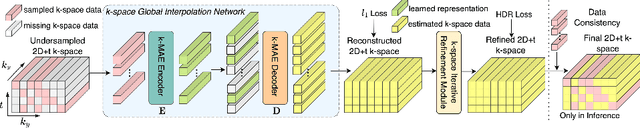
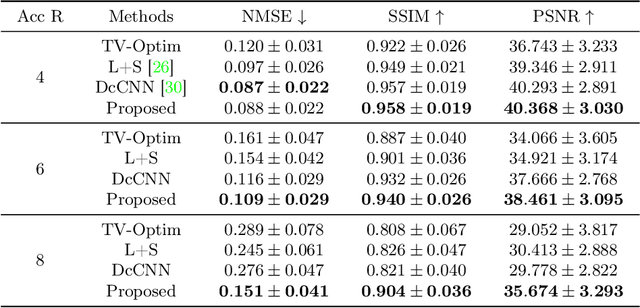
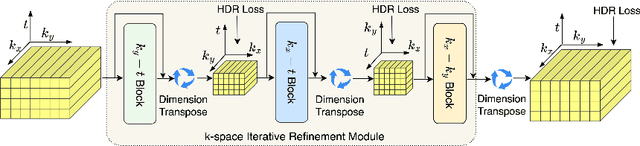
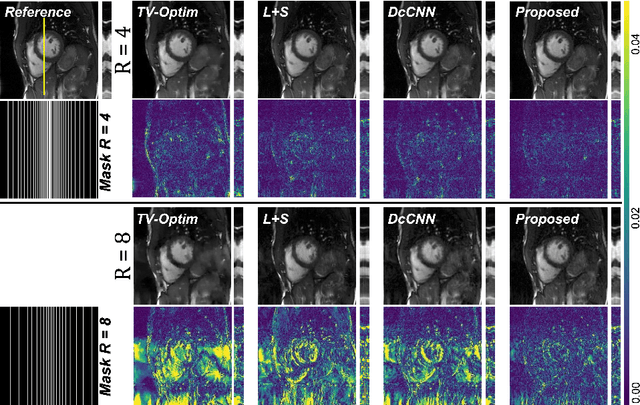
In dynamic Magnetic Resonance Imaging (MRI), k-space is typically undersampled due to limited scan time, resulting in aliasing artifacts in the image domain. Hence, dynamic MR reconstruction requires not only modeling spatial frequency components in the x and y directions of k-space but also considering temporal redundancy. Most previous works rely on image-domain regularizers (priors) to conduct MR reconstruction. In contrast, we focus on interpolating the undersampled k-space before obtaining images with Fourier transform. In this work, we connect masked image modeling with k-space interpolation and propose a novel Transformer-based k-space Global Interpolation Network, termed k-GIN. Our k-GIN learns global dependencies among low- and high-frequency components of 2D+t k-space and uses it to interpolate unsampled data. Further, we propose a novel k-space Iterative Refinement Module (k-IRM) to enhance the high-frequency components learning. We evaluate our approach on 92 in-house 2D+t cardiac MR subjects and compare it to MR reconstruction methods with image-domain regularizers. Experiments show that our proposed k-space interpolation method quantitatively and qualitatively outperforms baseline methods. Importantly, the proposed approach achieves substantially higher robustness and generalizability in cases of highly-undersampled MR data.
Inter-Rater Uncertainty Quantification in Medical Image Segmentation via Rater-Specific Bayesian Neural Networks
Jun 28, 2023
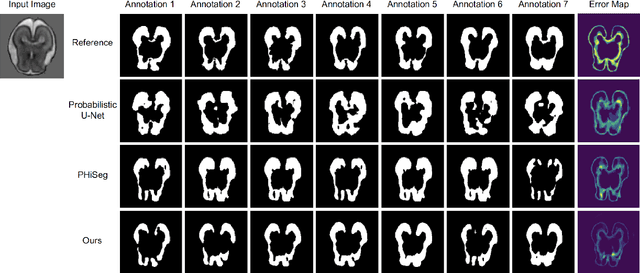

Automated medical image segmentation inherently involves a certain degree of uncertainty. One key factor contributing to this uncertainty is the ambiguity that can arise in determining the boundaries of a target region of interest, primarily due to variations in image appearance. On top of this, even among experts in the field, different opinions can emerge regarding the precise definition of specific anatomical structures. This work specifically addresses the modeling of segmentation uncertainty, known as inter-rater uncertainty. Its primary objective is to explore and analyze the variability in segmentation outcomes that can occur when multiple experts in medical imaging interpret and annotate the same images. We introduce a novel Bayesian neural network-based architecture to estimate inter-rater uncertainty in medical image segmentation. Our approach has three key advancements. Firstly, we introduce a one-encoder-multi-decoder architecture specifically tailored for uncertainty estimation, enabling us to capture the rater-specific representation of each expert involved. Secondly, we propose Bayesian modeling for the new architecture, allowing efficient capture of the inter-rater distribution, particularly in scenarios with limited annotations. Lastly, we enhance the rater-specific representation by integrating an attention module into each decoder. This module facilitates focused and refined segmentation results for each rater. We conduct extensive evaluations using synthetic and real-world datasets to validate our technical innovations rigorously. Our method surpasses existing baseline methods in five out of seven diverse tasks on the publicly available \emph{QUBIQ} dataset, considering two evaluation metrics encompassing different uncertainty aspects. Our codes, models, and the new dataset are available through our GitHub repository: https://github.com/HaoWang420/bOEMD-net .
The Impact of ChatGPT and LLMs on Medical Imaging Stakeholders: Perspectives and Use Cases
Jun 11, 2023


This study investigates the transformative potential of Large Language Models (LLMs), such as OpenAI ChatGPT, in medical imaging. With the aid of public data, these models, which possess remarkable language understanding and generation capabilities, are augmenting the interpretive skills of radiologists, enhancing patient-physician communication, and streamlining clinical workflows. The paper introduces an analytic framework for presenting the complex interactions between LLMs and the broader ecosystem of medical imaging stakeholders, including businesses, insurance entities, governments, research institutions, and hospitals (nicknamed BIGR-H). Through detailed analyses, illustrative use cases, and discussions on the broader implications and future directions, this perspective seeks to raise discussion in strategic planning and decision-making in the era of AI-enabled healthcare.