 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJan Stefan Kirschke
MedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023



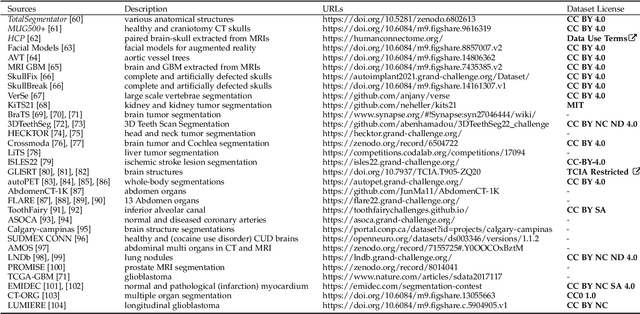
We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
Denoising diffusion-based MR to CT image translation enables whole spine vertebral segmentation in 2D and 3D without manual annotations
Aug 18, 2023



Background: Automated segmentation of spinal MR images plays a vital role both scientifically and clinically. However, accurately delineating posterior spine structures presents challenges. Methods: This retrospective study, approved by the ethical committee, involved translating T1w and T2w MR image series into CT images in a total of n=263 pairs of CT/MR series. Landmark-based registration was performed to align image pairs. We compared 2D paired (Pix2Pix, denoising diffusion implicit models (DDIM) image mode, DDIM noise mode) and unpaired (contrastive unpaired translation, SynDiff) image-to-image translation using "peak signal to noise ratio" (PSNR) as quality measure. A publicly available segmentation network segmented the synthesized CT datasets, and Dice scores were evaluated on in-house test sets and the "MRSpineSeg Challenge" volumes. The 2D findings were extended to 3D Pix2Pix and DDIM. Results: 2D paired methods and SynDiff exhibited similar translation performance and Dice scores on paired data. DDIM image mode achieved the highest image quality. SynDiff, Pix2Pix, and DDIM image mode demonstrated similar Dice scores (0.77). For craniocaudal axis rotations, at least two landmarks per vertebra were required for registration. The 3D translation outperformed the 2D approach, resulting in improved Dice scores (0.80) and anatomically accurate segmentations in a higher resolution than the original MR image. Conclusion: Two landmarks per vertebra registration enabled paired image-to-image translation from MR to CT and outperformed all unpaired approaches. The 3D techniques provided anatomically correct segmentations, avoiding underprediction of small structures like the spinous process.