 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobert Graf
SPINEPS -- Automatic Whole Spine Segmentation of T2-weighted MR images using a Two-Phase Approach to Multi-class Semantic and Instance Segmentation
Feb 26, 2024
Purpose. To present SPINEPS, an open-source deep learning approach for semantic and instance segmentation of 14 spinal structures (ten vertebra substructures, intervertebral discs, spinal cord, spinal canal, and sacrum) in whole body T2w MRI. Methods. During this HIPPA-compliant, retrospective study, we utilized the public SPIDER dataset (218 subjects, 63% female) and a subset of the German National Cohort (1423 subjects, mean age 53, 49% female) for training and evaluation. We combined CT and T2w segmentations to train models that segment 14 spinal structures in T2w sagittal scans both semantically and instance-wise. Performance evaluation metrics included Dice similarity coefficient, average symmetrical surface distance, panoptic quality, segmentation quality, and recognition quality. Statistical significance was assessed using the Wilcoxon signed-rank test. An in-house dataset was used to qualitatively evaluate out-of-distribution samples. Results. On the public dataset, our approach outperformed the baseline (instance-wise vertebra dice score 0.929 vs. 0.907, p-value<0.001). Training on auto-generated annotations and evaluating on manually corrected test data from the GNC yielded global dice scores of 0.900 for vertebrae, 0.960 for intervertebral discs, and 0.947 for the spinal canal. Incorporating the SPIDER dataset during training increased these scores to 0.920, 0.967, 0.958, respectively. Conclusions. The proposed segmentation approach offers robust segmentation of 14 spinal structures in T2w sagittal images, including the spinal cord, spinal canal, intervertebral discs, endplate, sacrum, and vertebrae. The approach yields both a semantic and instance mask as output, thus being easy to utilize. This marks the first publicly available algorithm for whole spine segmentation in sagittal T2w MR imaging.
3D Arterial Segmentation via Single 2D Projections and Depth Supervision in Contrast-Enhanced CT Images
Sep 15, 2023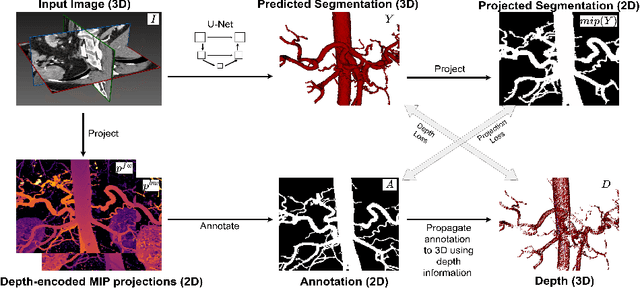
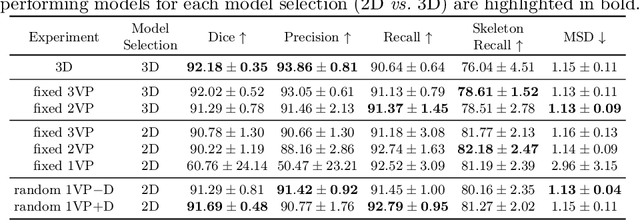
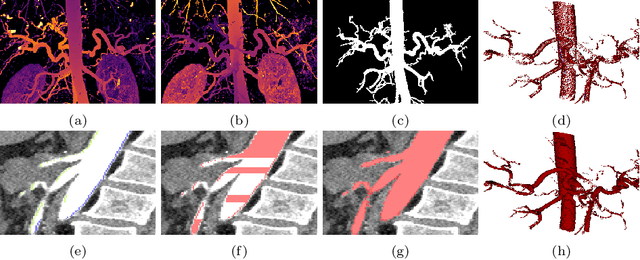
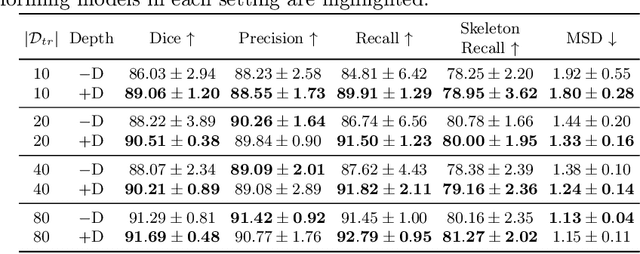
Automated segmentation of the blood vessels in 3D volumes is an essential step for the quantitative diagnosis and treatment of many vascular diseases. 3D vessel segmentation is being actively investigated in existing works, mostly in deep learning approaches. However, training 3D deep networks requires large amounts of manual 3D annotations from experts, which are laborious to obtain. This is especially the case for 3D vessel segmentation, as vessels are sparse yet spread out over many slices and disconnected when visualized in 2D slices. In this work, we propose a novel method to segment the 3D peripancreatic arteries solely from one annotated 2D projection per training image with depth supervision. We perform extensive experiments on the segmentation of peripancreatic arteries on 3D contrast-enhanced CT images and demonstrate how well we capture the rich depth information from 2D projections. We demonstrate that by annotating a single, randomly chosen projection for each training sample, we obtain comparable performance to annotating multiple 2D projections, thereby reducing the annotation effort. Furthermore, by mapping the 2D labels to the 3D space using depth information and incorporating this into training, we almost close the performance gap between 3D supervision and 2D supervision. Our code is available at: https://github.com/alinafdima/3Dseg-mip-depth.
Denoising diffusion-based MR to CT image translation enables whole spine vertebral segmentation in 2D and 3D without manual annotations
Aug 18, 2023



Background: Automated segmentation of spinal MR images plays a vital role both scientifically and clinically. However, accurately delineating posterior spine structures presents challenges. Methods: This retrospective study, approved by the ethical committee, involved translating T1w and T2w MR image series into CT images in a total of n=263 pairs of CT/MR series. Landmark-based registration was performed to align image pairs. We compared 2D paired (Pix2Pix, denoising diffusion implicit models (DDIM) image mode, DDIM noise mode) and unpaired (contrastive unpaired translation, SynDiff) image-to-image translation using "peak signal to noise ratio" (PSNR) as quality measure. A publicly available segmentation network segmented the synthesized CT datasets, and Dice scores were evaluated on in-house test sets and the "MRSpineSeg Challenge" volumes. The 2D findings were extended to 3D Pix2Pix and DDIM. Results: 2D paired methods and SynDiff exhibited similar translation performance and Dice scores on paired data. DDIM image mode achieved the highest image quality. SynDiff, Pix2Pix, and DDIM image mode demonstrated similar Dice scores (0.77). For craniocaudal axis rotations, at least two landmarks per vertebra were required for registration. The 3D translation outperformed the 2D approach, resulting in improved Dice scores (0.80) and anatomically accurate segmentations in a higher resolution than the original MR image. Conclusion: Two landmarks per vertebra registration enabled paired image-to-image translation from MR to CT and outperformed all unpaired approaches. The 3D techniques provided anatomically correct segmentations, avoiding underprediction of small structures like the spinous process.
The Brain Tumor Segmentation (BraTS) Challenge 2023: Local Synthesis of Healthy Brain Tissue via Inpainting
May 15, 2023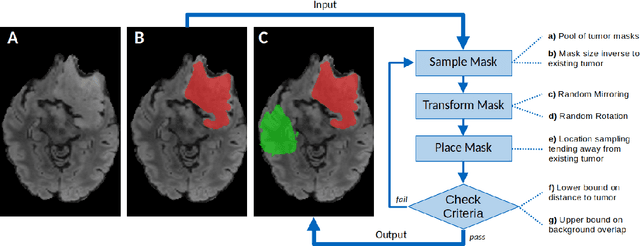
A myriad of algorithms for the automatic analysis of brain MR images is available to support clinicians in their decision-making. For brain tumor patients, the image acquisition time series typically starts with a scan that is already pathological. This poses problems, as many algorithms are designed to analyze healthy brains and provide no guarantees for images featuring lesions. Examples include but are not limited to algorithms for brain anatomy parcellation, tissue segmentation, and brain extraction. To solve this dilemma, we introduce the BraTS 2023 inpainting challenge. Here, the participants' task is to explore inpainting techniques to synthesize healthy brain scans from lesioned ones. The following manuscript contains the task formulation, dataset, and submission procedure. Later it will be updated to summarize the findings of the challenge. The challenge is organized as part of the BraTS 2023 challenge hosted at the MICCAI 2023 conference in Vancouver, Canada.
Multi-contrast MRI Super-resolution via Implicit Neural Representations
Mar 27, 2023
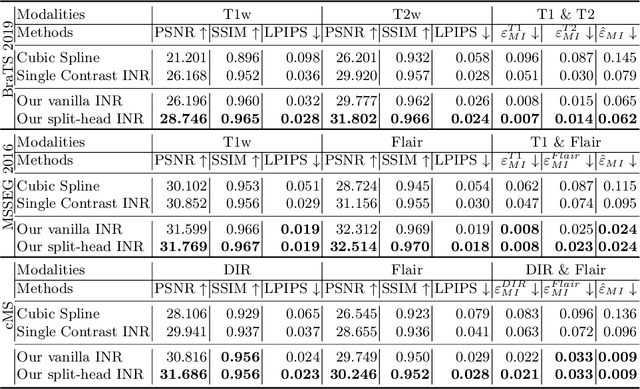
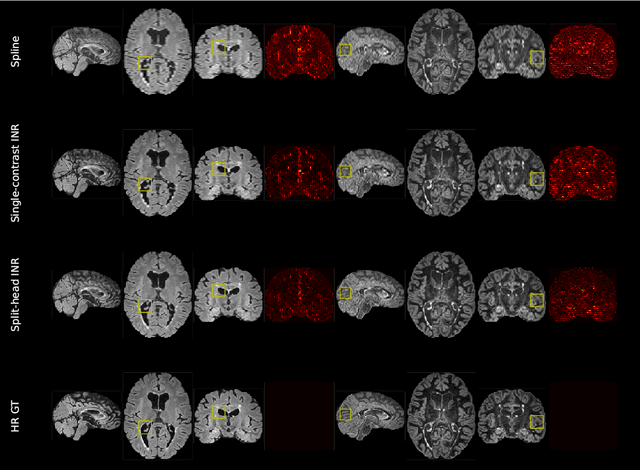

Clinical routine and retrospective cohorts commonly include multi-parametric Magnetic Resonance Imaging; however, they are mostly acquired in different anisotropic 2D views due to signal-to-noise-ratio and scan-time constraints. Thus acquired views suffer from poor out-of-plane resolution and affect downstream volumetric image analysis that typically requires isotropic 3D scans. Combining different views of multi-contrast scans into high-resolution isotropic 3D scans is challenging due to the lack of a large training cohort, which calls for a subject-specific framework.This work proposes a novel solution to this problem leveraging Implicit Neural Representations (INR). Our proposed INR jointly learns two different contrasts of complementary views in a continuous spatial function and benefits from exchanging anatomical information between them. Trained within minutes on a single commodity GPU, our model provides realistic super-resolution across different pairs of contrasts in our experiments with three datasets. Using Mutual Information (MI) as a metric, we find that our model converges to an optimum MI amongst sequences, achieving anatomically faithful reconstruction. Code is available at: https://github.com/jqmcginnis/multi_contrast_inr.
Attention-based Saliency Maps Improve Interpretability of Pneumothorax Classification
Mar 03, 2023



Purpose: To investigate chest radiograph (CXR) classification performance of vision transformers (ViT) and interpretability of attention-based saliency using the example of pneumothorax classification. Materials and Methods: In this retrospective study, ViTs were fine-tuned for lung disease classification using four public data sets: CheXpert, Chest X-Ray 14, MIMIC CXR, and VinBigData. Saliency maps were generated using transformer multimodal explainability and gradient-weighted class activation mapping (GradCAM). Classification performance was evaluated on the Chest X-Ray 14, VinBigData, and SIIM-ACR data sets using the area under the receiver operating characteristic curve analysis (AUC) and compared with convolutional neural networks (CNNs). The explainability methods were evaluated with positive/negative perturbation, sensitivity-n, effective heat ratio, intra-architecture repeatability and interarchitecture reproducibility. In the user study, three radiologists classified 160 CXRs with/without saliency maps for pneumothorax and rated their usefulness. Results: ViTs had comparable CXR classification AUCs compared with state-of-the-art CNNs 0.95 (95% CI: 0.943, 0.950) versus 0.83 (95%, CI 0.826, 0.842) on Chest X-Ray 14, 0.84 (95% CI: 0.769, 0.912) versus 0.83 (95% CI: 0.760, 0.895) on VinBigData, and 0.85 (95% CI: 0.847, 0.861) versus 0.87 (95% CI: 0.868, 0.882) on SIIM ACR. Both saliency map methods unveiled a strong bias toward pneumothorax tubes in the models. Radiologists found 47% of the attention-based saliency maps useful and 39% of GradCAM. The attention-based methods outperformed GradCAM on all metrics. Conclusion: ViTs performed similarly to CNNs in CXR classification, and their attention-based saliency maps were more useful to radiologists and outperformed GradCAM.