 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuanfeng Ji
Large Language Models as Automated Aligners for benchmarking Vision-Language Models
Nov 24, 2023
With the advancements in Large Language Models (LLMs), Vision-Language Models (VLMs) have reached a new level of sophistication, showing notable competence in executing intricate cognition and reasoning tasks. However, existing evaluation benchmarks, primarily relying on rigid, hand-crafted datasets to measure task-specific performance, face significant limitations in assessing the alignment of these increasingly anthropomorphic models with human intelligence. In this work, we address the limitations via Auto-Bench, which delves into exploring LLMs as proficient aligners, measuring the alignment between VLMs and human intelligence and value through automatic data curation and assessment. Specifically, for data curation, Auto-Bench utilizes LLMs (e.g., GPT-4) to automatically generate a vast set of question-answer-reasoning triplets via prompting on visual symbolic representations (e.g., captions, object locations, instance relationships, and etc.). The curated data closely matches human intent, owing to the extensive world knowledge embedded in LLMs. Through this pipeline, a total of 28.5K human-verified and 3,504K unfiltered question-answer-reasoning triplets have been curated, covering 4 primary abilities and 16 sub-abilities. We subsequently engage LLMs like GPT-3.5 to serve as judges, implementing the quantitative and qualitative automated assessments to facilitate a comprehensive evaluation of VLMs. Our validation results reveal that LLMs are proficient in both evaluation data curation and model assessment, achieving an average agreement rate of 85%. We envision Auto-Bench as a flexible, scalable, and comprehensive benchmark for evaluating the evolving sophisticated VLMs.
MedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023


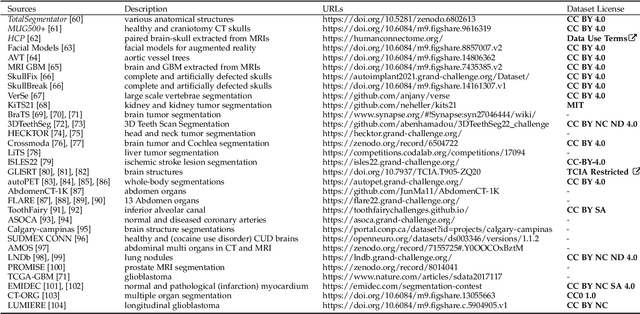
We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
SyNDock: N Rigid Protein Docking via Learnable Group Synchronization
May 25, 2023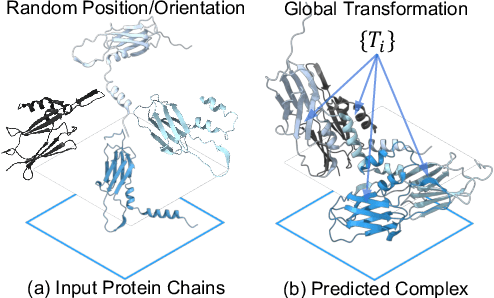

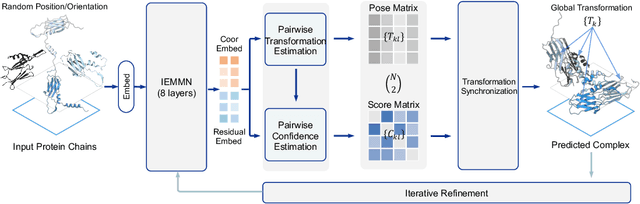

The regulation of various cellular processes heavily relies on the protein complexes within a living cell, necessitating a comprehensive understanding of their three-dimensional structures to elucidate the underlying mechanisms. While neural docking techniques have exhibited promising outcomes in binary protein docking, the application of advanced neural architectures to multimeric protein docking remains uncertain. This study introduces SyNDock, an automated framework that swiftly assembles precise multimeric complexes within seconds, showcasing performance that can potentially surpass or be on par with recent advanced approaches. SyNDock possesses several appealing advantages not present in previous approaches. Firstly, SyNDock formulates multimeric protein docking as a problem of learning global transformations to holistically depict the placement of chain units of a complex, enabling a learning-centric solution. Secondly, SyNDock proposes a trainable two-step SE(3) algorithm, involving initial pairwise transformation and confidence estimation, followed by global transformation synchronization. This enables effective learning for assembling the complex in a globally consistent manner. Lastly, extensive experiments conducted on our proposed benchmark dataset demonstrate that SyNDock outperforms existing docking software in crucial performance metrics, including accuracy and runtime. For instance, it achieves a 4.5% improvement in performance and a remarkable millionfold acceleration in speed.
DDP: Diffusion Model for Dense Visual Prediction
Mar 30, 2023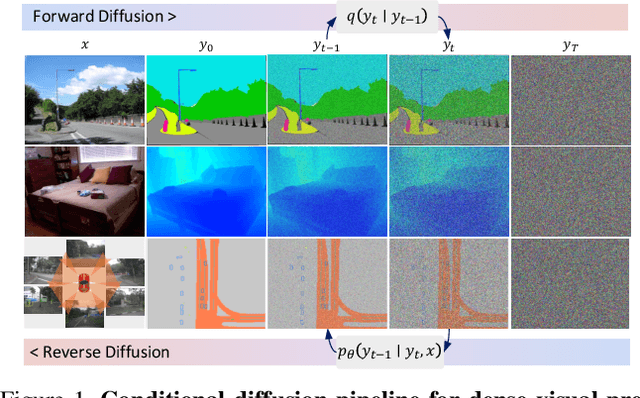
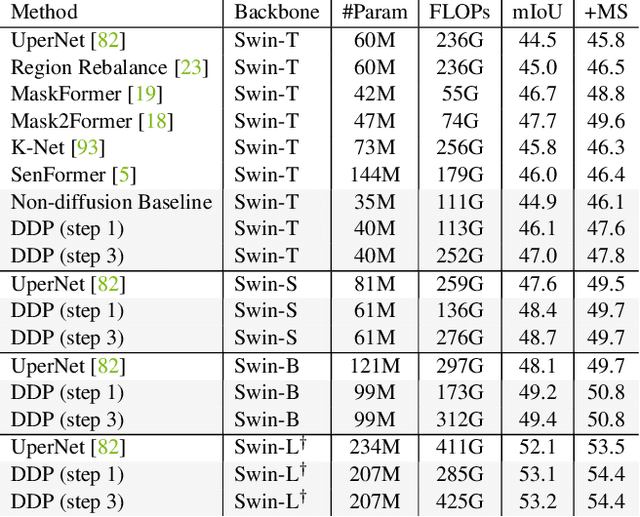
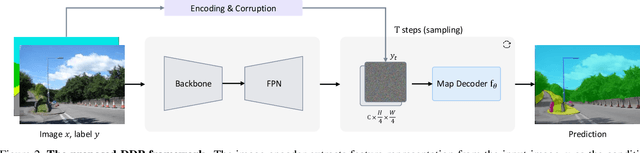
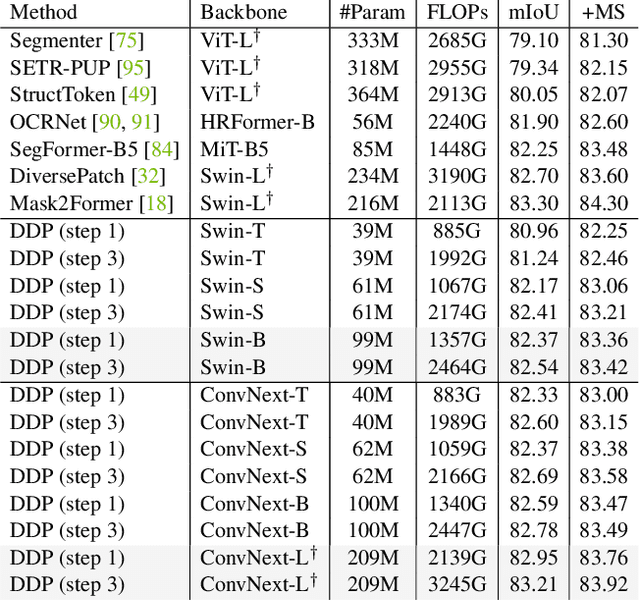
We propose a simple, efficient, yet powerful framework for dense visual predictions based on the conditional diffusion pipeline. Our approach follows a "noise-to-map" generative paradigm for prediction by progressively removing noise from a random Gaussian distribution, guided by the image. The method, called DDP, efficiently extends the denoising diffusion process into the modern perception pipeline. Without task-specific design and architecture customization, DDP is easy to generalize to most dense prediction tasks, e.g., semantic segmentation and depth estimation. In addition, DDP shows attractive properties such as dynamic inference and uncertainty awareness, in contrast to previous single-step discriminative methods. We show top results on three representative tasks with six diverse benchmarks, without tricks, DDP achieves state-of-the-art or competitive performance on each task compared to the specialist counterparts. For example, semantic segmentation (83.9 mIoU on Cityscapes), BEV map segmentation (70.6 mIoU on nuScenes), and depth estimation (0.05 REL on KITTI). We hope that our approach will serve as a solid baseline and facilitate future research
AMOS: A Large-Scale Abdominal Multi-Organ Benchmark for Versatile Medical Image Segmentation
Jun 16, 2022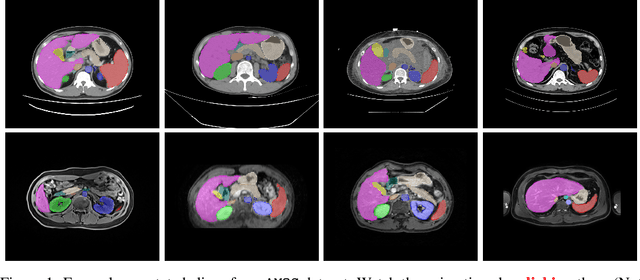

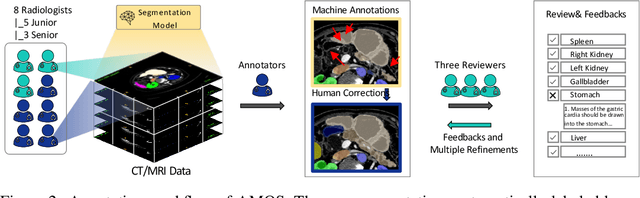
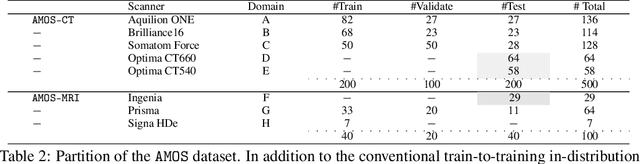
Despite the considerable progress in automatic abdominal multi-organ segmentation from CT/MRI scans in recent years, a comprehensive evaluation of the models' capabilities is hampered by the lack of a large-scale benchmark from diverse clinical scenarios. Constraint by the high cost of collecting and labeling 3D medical data, most of the deep learning models to date are driven by datasets with a limited number of organs of interest or samples, which still limits the power of modern deep models and makes it difficult to provide a fully comprehensive and fair estimate of various methods. To mitigate the limitations, we present AMOS, a large-scale, diverse, clinical dataset for abdominal organ segmentation. AMOS provides 500 CT and 100 MRI scans collected from multi-center, multi-vendor, multi-modality, multi-phase, multi-disease patients, each with voxel-level annotations of 15 abdominal organs, providing challenging examples and test-bed for studying robust segmentation algorithms under diverse targets and scenarios. We further benchmark several state-of-the-art medical segmentation models to evaluate the status of the existing methods on this new challenging dataset. We have made our datasets, benchmark servers, and baselines publicly available, and hope to inspire future research. Information can be found at https://amos22.grand-challenge.org.
DrugOOD: Out-of-Distribution (OOD) Dataset Curator and Benchmark for AI-aided Drug Discovery -- A Focus on Affinity Prediction Problems with Noise Annotations
Jan 24, 2022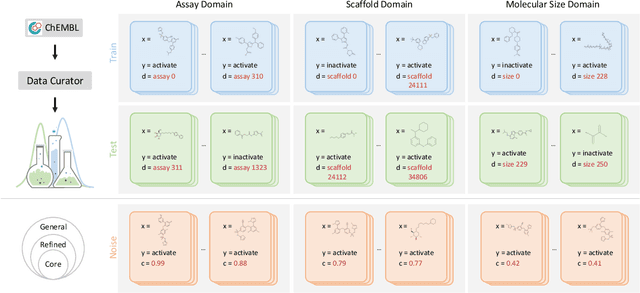

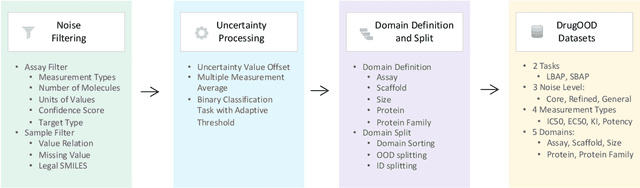

AI-aided drug discovery (AIDD) is gaining increasing popularity due to its promise of making the search for new pharmaceuticals quicker, cheaper and more efficient. In spite of its extensive use in many fields, such as ADMET prediction, virtual screening, protein folding and generative chemistry, little has been explored in terms of the out-of-distribution (OOD) learning problem with \emph{noise}, which is inevitable in real world AIDD applications. In this work, we present DrugOOD, a systematic OOD dataset curator and benchmark for AI-aided drug discovery, which comes with an open-source Python package that fully automates the data curation and OOD benchmarking processes. We focus on one of the most crucial problems in AIDD: drug target binding affinity prediction, which involves both macromolecule (protein target) and small-molecule (drug compound). In contrast to only providing fixed datasets, DrugOOD offers automated dataset curator with user-friendly customization scripts, rich domain annotations aligned with biochemistry knowledge, realistic noise annotations and rigorous benchmarking of state-of-the-art OOD algorithms. Since the molecular data is often modeled as irregular graphs using graph neural network (GNN) backbones, DrugOOD also serves as a valuable testbed for \emph{graph OOD learning} problems. Extensive empirical studies have shown a significant performance gap between in-distribution and out-of-distribution experiments, which highlights the need to develop better schemes that can allow for OOD generalization under noise for AIDD.
Multi-frame Collaboration for Effective Endoscopic Video Polyp Detection via Spatial-Temporal Feature Transformation
Jul 08, 2021
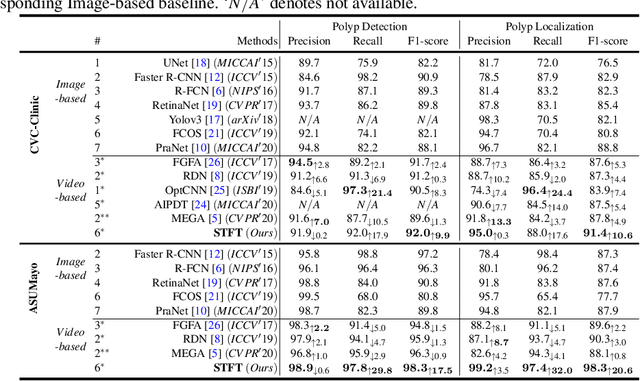
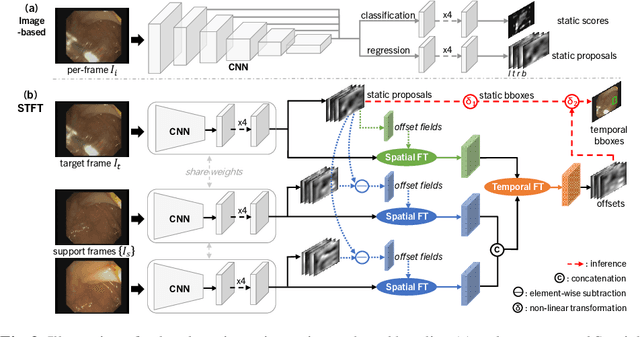

Precise localization of polyp is crucial for early cancer screening in gastrointestinal endoscopy. Videos given by endoscopy bring both richer contextual information as well as more challenges than still images. The camera-moving situation, instead of the common camera-fixed-object-moving one, leads to significant background variation between frames. Severe internal artifacts (e.g. water flow in the human body, specular reflection by tissues) can make the quality of adjacent frames vary considerately. These factors hinder a video-based model to effectively aggregate features from neighborhood frames and give better predictions. In this paper, we present Spatial-Temporal Feature Transformation (STFT), a multi-frame collaborative framework to address these issues. Spatially, STFT mitigates inter-frame variations in the camera-moving situation with feature alignment by proposal-guided deformable convolutions. Temporally, STFT proposes a channel-aware attention module to simultaneously estimate the quality and correlation of adjacent frames for adaptive feature aggregation. Empirical studies and superior results demonstrate the effectiveness and stability of our method. For example, STFT improves the still image baseline FCOS by 10.6% and 20.6% on the comprehensive F1-score of the polyp localization task in CVC-Clinic and ASUMayo datasets, respectively, and outperforms the state-of-the-art video-based method by 3.6% and 8.0%, respectively. Code is available at \url{https://github.com/lingyunwu14/STFT}.
Multi-Compound Transformer for Accurate Biomedical Image Segmentation
Jun 28, 2021
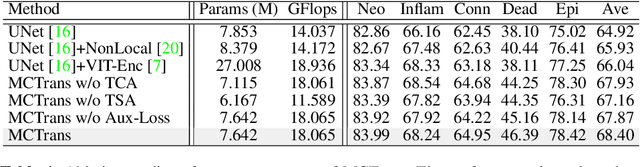
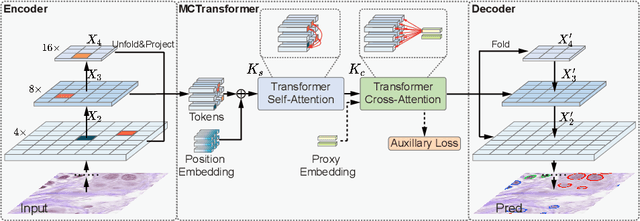
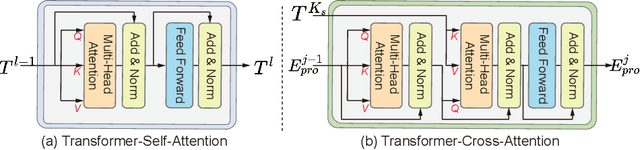
The recent vision transformer(i.e.for image classification) learns non-local attentive interaction of different patch tokens. However, prior arts miss learning the cross-scale dependencies of different pixels, the semantic correspondence of different labels, and the consistency of the feature representations and semantic embeddings, which are critical for biomedical segmentation. In this paper, we tackle the above issues by proposing a unified transformer network, termed Multi-Compound Transformer (MCTrans), which incorporates rich feature learning and semantic structure mining into a unified framework. Specifically, MCTrans embeds the multi-scale convolutional features as a sequence of tokens and performs intra- and inter-scale self-attention, rather than single-scale attention in previous works. In addition, a learnable proxy embedding is also introduced to model semantic relationship and feature enhancement by using self-attention and cross-attention, respectively. MCTrans can be easily plugged into a UNet-like network and attains a significant improvement over the state-of-the-art methods in biomedical image segmentation in six standard benchmarks. For example, MCTrans outperforms UNet by 3.64%, 3.71%, 4.34%, 2.8%, 1.88%, 1.57% in Pannuke, CVC-Clinic, CVC-Colon, Etis, Kavirs, ISIC2018 dataset, respectively. Code is available at https://github.com/JiYuanFeng/MCTrans.
The Medical Segmentation Decathlon
Jun 10, 2021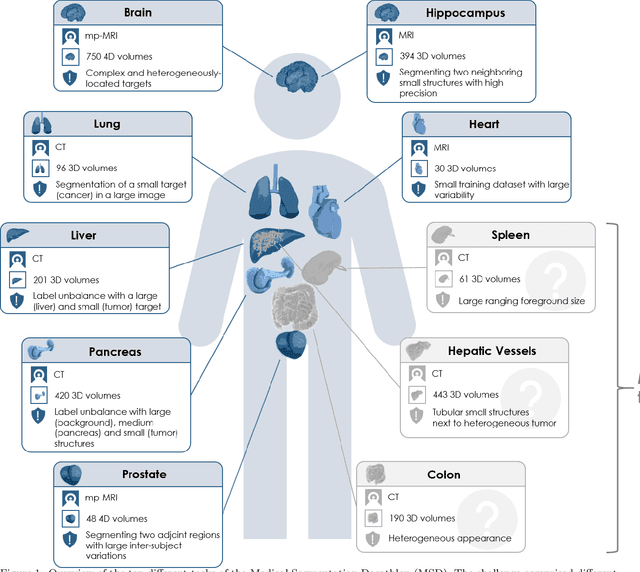
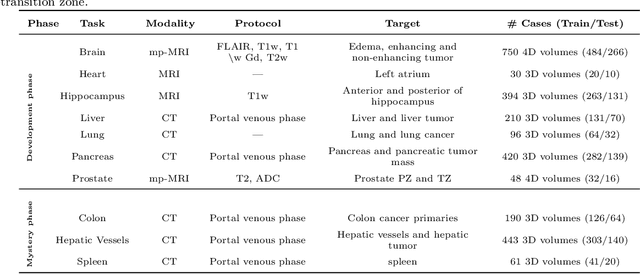
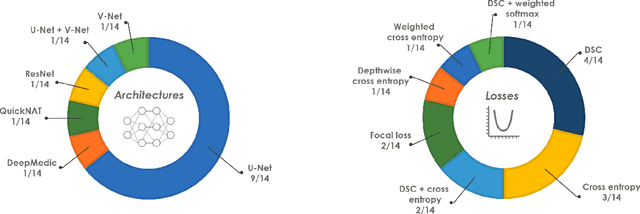
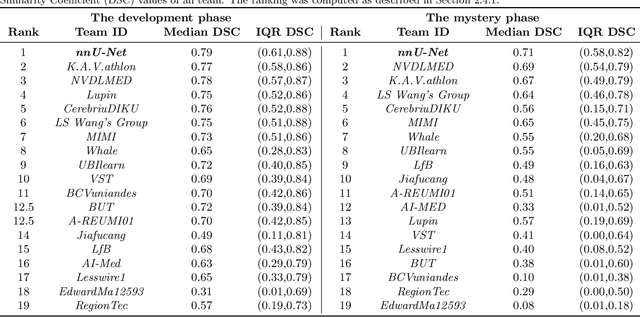
International challenges have become the de facto standard for comparative assessment of image analysis algorithms given a specific task. Segmentation is so far the most widely investigated medical image processing task, but the various segmentation challenges have typically been organized in isolation, such that algorithm development was driven by the need to tackle a single specific clinical problem. We hypothesized that a method capable of performing well on multiple tasks will generalize well to a previously unseen task and potentially outperform a custom-designed solution. To investigate the hypothesis, we organized the Medical Segmentation Decathlon (MSD) - a biomedical image analysis challenge, in which algorithms compete in a multitude of both tasks and modalities. The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data and small objects. The MSD challenge confirmed that algorithms with a consistent good performance on a set of tasks preserved their good average performance on a different set of previously unseen tasks. Moreover, by monitoring the MSD winner for two years, we found that this algorithm continued generalizing well to a wide range of other clinical problems, further confirming our hypothesis. Three main conclusions can be drawn from this study: (1) state-of-the-art image segmentation algorithms are mature, accurate, and generalize well when retrained on unseen tasks; (2) consistent algorithmic performance across multiple tasks is a strong surrogate of algorithmic generalizability; (3) the training of accurate AI segmentation models is now commoditized to non AI experts.
UXNet: Searching Multi-level Feature Aggregation for 3D Medical Image Segmentation
Sep 16, 2020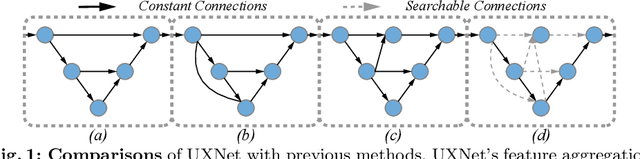
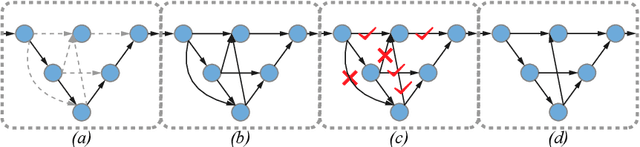
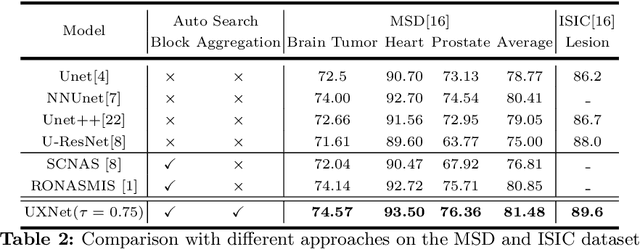
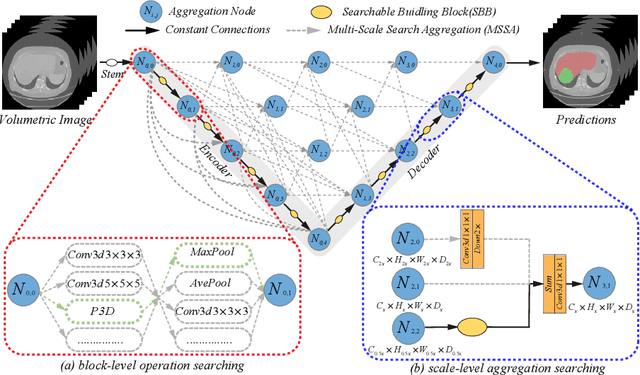
Aggregating multi-level feature representation plays a critical role in achieving robust volumetric medical image segmentation, which is important for the auxiliary diagnosis and treatment. Unlike the recent neural architecture search (NAS) methods that typically searched the optimal operators in each network layer, but missed a good strategy to search for feature aggregations, this paper proposes a novel NAS method for 3D medical image segmentation, named UXNet, which searches both the scale-wise feature aggregation strategies as well as the block-wise operators in the encoder-decoder network. UXNet has several appealing benefits. (1) It significantly improves flexibility of the classical UNet architecture, which only aggregates feature representations of encoder and decoder in equivalent resolution. (2) A continuous relaxation of UXNet is carefully designed, enabling its searching scheme performed in an efficient differentiable manner. (3) Extensive experiments demonstrate the effectiveness of UXNet compared with recent NAS methods for medical image segmentation. The architecture discovered by UXNet outperforms existing state-of-the-art models in terms of Dice on several public 3D medical image segmentation benchmarks, especially for the boundary locations and tiny tissues. The searching computational complexity of UXNet is cheap, enabling to search a network with the best performance less than 1.5 days on two TitanXP GPUs.