 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianjiang Feng
3D Vascular Segmentation Supervised by 2D Annotation of Maximum Intensity Projection
Feb 19, 2024
Vascular structure segmentation plays a crucial role in medical analysis and clinical applications. The practical adoption of fully supervised segmentation models is impeded by the intricacy and time-consuming nature of annotating vessels in the 3D space. This has spurred the exploration of weakly-supervised approaches that reduce reliance on expensive segmentation annotations. Despite this, existing weakly supervised methods employed in organ segmentation, which encompass points, bounding boxes, or graffiti, have exhibited suboptimal performance when handling sparse vascular structure. To alleviate this issue, we employ maximum intensity projection (MIP) to decrease the dimensionality of 3D volume to 2D image for efficient annotation, and the 2D labels are utilized to provide guidance and oversight for training 3D vessel segmentation model. Initially, we generate pseudo-labels for 3D blood vessels using the annotations of 2D projections. Subsequently, taking into account the acquisition method of the 2D labels, we introduce a weakly-supervised network that fuses 2D-3D deep features via MIP to further improve segmentation performance. Furthermore, we integrate confidence learning and uncertainty estimation to refine the generated pseudo-labels, followed by fine-tuning the segmentation network. Our method is validated on five datasets (including cerebral vessel, aorta and coronary artery), demonstrating highly competitive performance in segmenting vessels and the potential to significantly reduce the time and effort required for vessel annotation. Our code is available at: https://github.com/gzq17/Weakly-Supervised-by-MIP.
PointVoxel: A Simple and Effective Pipeline for Multi-View Multi-Modal 3D Human Pose Estimation
Dec 12, 2023Recently, several methods have been proposed to estimate 3D human pose from multi-view images and achieved impressive performance on public datasets collected in relatively easy scenarios. However, there are limited approaches for extracting 3D human skeletons from multimodal inputs (e.g., RGB and pointcloud) that can enhance the accuracy of predicting 3D poses in challenging situations. We fill this gap by introducing a pipeline called PointVoxel that fuses multi-view RGB and pointcloud inputs to obtain 3D human poses. We demonstrate that volumetric representation is an effective architecture for integrating these different modalities. Moreover, in order to overcome the challenges of annotating 3D human pose labels in difficult scenarios, we develop a synthetic dataset generator for pretraining and design an unsupervised domain adaptation strategy so that we can obtain a well-trained 3D human pose estimator without using any manual annotations. We evaluate our approach on four datasets (two public datasets, one synthetic dataset, and one challenging dataset named BasketBall collected by ourselves), showing promising results. The code and dataset will be released soon.
LiDAR-based Person Re-identification
Dec 11, 2023Camera-based person re-identification (ReID) systems have been widely applied in the field of public security. However, cameras often lack the perception of 3D morphological information of human and are susceptible to various limitations, such as inadequate illumination, complex background, and personal privacy. In this paper, we propose a LiDAR-based ReID framework, ReID3D, that utilizes pre-training strategy to retrieve features of 3D body shape and introduces Graph-based Complementary Enhancement Encoder for extracting comprehensive features. Due to the lack of LiDAR datasets, we build LReID, the first LiDAR-based person ReID dataset, which is collected in several outdoor scenes with variations in natural conditions. Additionally, we introduce LReID-sync, a simulated pedestrian dataset designed for pre-training encoders with tasks of point cloud completion and shape parameter learning. Extensive experiments on LReID show that ReID3D achieves exceptional performance with a rank-1 accuracy of 94.0, highlighting the significant potential of LiDAR in addressing person ReID tasks. To the best of our knowledge, we are the first to propose a solution for LiDAR-based ReID. The code and datasets will be released soon.
HumanReg: Self-supervised Non-rigid Registration of Human Point Cloud
Dec 09, 2023In this paper, we present a novel registration framework, HumanReg, that learns a non-rigid transformation between two human point clouds end-to-end. We introduce body prior into the registration process to efficiently handle this type of point cloud. Unlike most exsisting supervised registration techniques that require expensive point-wise flow annotations, HumanReg can be trained in a self-supervised manner benefiting from a set of novel loss functions. To make our model better converge on real-world data, we also propose a pretraining strategy, and a synthetic dataset (HumanSyn4D) consists of dynamic, sparse human point clouds and their auto-generated ground truth annotations. Our experiments shows that HumanReg achieves state-of-the-art performance on CAPE-512 dataset and gains a qualitative result on another more challenging real-world dataset. Furthermore, our ablation studies demonstrate the effectiveness of our synthetic dataset and novel loss functions. Our code and synthetic dataset is available at https://github.com/chenyifanthu/HumanReg.
Fingerprint Matching with Localized Deep Representation
Nov 30, 2023Compared to minutia-based fingerprint representations, fixed-length representations are attractive due to simple and efficient matching. However, fixed-length fingerprint representations are limited in accuracy when matching fingerprints with different visible areas, which can occur due to different finger poses or acquisition methods. To address this issue, we propose a localized deep representation of fingerprint, named LDRF. By focusing on the discriminative characteristics within local regions, LDRF provides a more robust and accurate fixed-length representation for fingerprints with variable visible areas. LDRF can be adapted to retain information within any valid area, making it highly flexible. The matching scores produced by LDRF also exhibit intuitive statistical characteristics, which led us to propose a matching score normalization technique to mitigate the uncertainty in the cases of very small overlapping area. With this new technique, we can maintain a high level of accuracy and reliability in our fingerprint matching, even as the size of the database grows rapidly. Our experimental results on 21 datasets containing over 140K fingerprints of various finger poses and impression types show that LDRF outperforms other fixed-length representations and is robust to sensing technologies and impression types. Besides, the proposed matching score normalization effectively reduces the false match rate (FMR) in large-scale identification experiments comprising over 5.11 million fingerprints. Specifically, this technique results in a reduction of two orders of magnitude compared to matching without matching score normalization and five orders of magnitude compared to prior works.
LiDAR-HMR: 3D Human Mesh Recovery from LiDAR
Nov 20, 2023In recent years, point cloud perception tasks have been garnering increasing attention. This paper presents the first attempt to estimate 3D human body mesh from sparse LiDAR point clouds. We found that the major challenge in estimating human pose and mesh from point clouds lies in the sparsity, noise, and incompletion of LiDAR point clouds. Facing these challenges, we propose an effective sparse-to-dense reconstruction scheme to reconstruct 3D human mesh. This involves estimating a sparse representation of a human (3D human pose) and gradually reconstructing the body mesh. To better leverage the 3D structural information of point clouds, we employ a cascaded graph transformer (graphormer) to introduce point cloud features during sparse-to-dense reconstruction. Experimental results on three publicly available databases demonstrate the effectiveness of the proposed approach. Code: https://github.com/soullessrobot/LiDAR-HMR/
Human-M3: A Multi-view Multi-modal Dataset for 3D Human Pose Estimation in Outdoor Scenes
Aug 06, 2023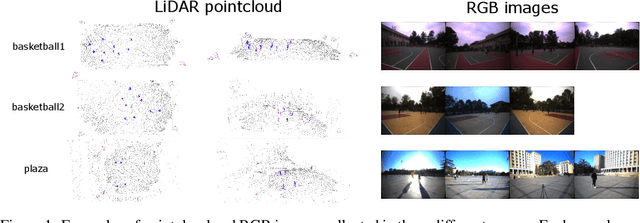


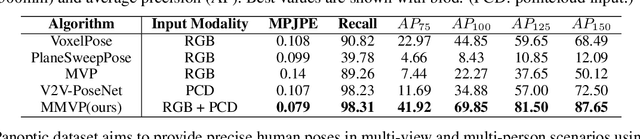
3D human pose estimation in outdoor environments has garnered increasing attention recently. However, prevalent 3D human pose datasets pertaining to outdoor scenes lack diversity, as they predominantly utilize only one type of modality (RGB image or pointcloud), and often feature only one individual within each scene. This limited scope of dataset infrastructure considerably hinders the variability of available data. In this article, we propose Human-M3, an outdoor multi-modal multi-view multi-person human pose database which includes not only multi-view RGB videos of outdoor scenes but also corresponding pointclouds. In order to obtain accurate human poses, we propose an algorithm based on multi-modal data input to generate ground truth annotation. This benefits from robust pointcloud detection and tracking, which solves the problem of inaccurate human localization and matching ambiguity that may exist in previous multi-view RGB videos in outdoor multi-person scenes, and generates reliable ground truth annotations. Evaluation of multiple different modalities algorithms has shown that this database is challenging and suitable for future research. Furthermore, we propose a 3D human pose estimation algorithm based on multi-modal data input, which demonstrates the advantages of multi-modal data input for 3D human pose estimation. Code and data will be released on https://github.com/soullessrobot/Human-M3-Dataset.
A Flexible Multi-view Multi-modal Imaging System for Outdoor Scenes
Feb 21, 2023
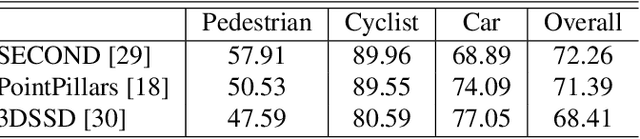
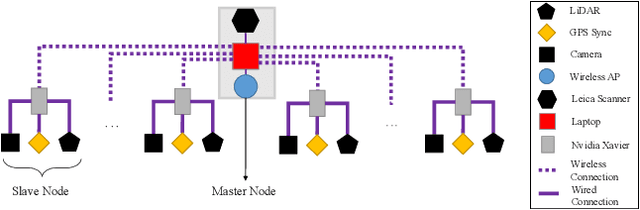
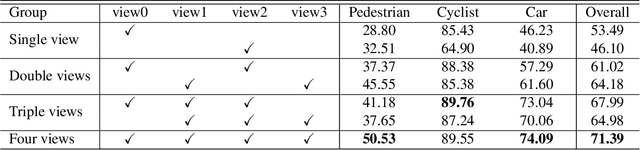
Multi-view imaging systems enable uniform coverage of 3D space and reduce the impact of occlusion, which is beneficial for 3D object detection and tracking accuracy. However, existing imaging systems built with multi-view cameras or depth sensors are limited by the small applicable scene and complicated composition. In this paper, we propose a wireless multi-view multi-modal 3D imaging system generally applicable to large outdoor scenes, which consists of a master node and several slave nodes. Multiple spatially distributed slave nodes equipped with cameras and LiDARs are connected to form a wireless sensor network. While providing flexibility and scalability, the system applies automatic spatio-temporal calibration techniques to obtain accurate 3D multi-view multi-modal data. This system is the first imaging system that integrates mutli-view RGB cameras and LiDARs in large outdoor scenes among existing 3D imaging systems. We perform point clouds based 3D object detection and long-term tracking using the 3D imaging dataset collected by this system. The experimental results show that multi-view point clouds greatly improve 3D object detection and tracking accuracy regardless of complex and various outdoor environments.
Cerebrovascular Segmentation via Vessel Oriented Filtering Network
Oct 17, 2022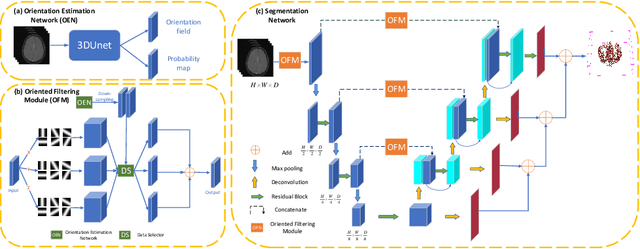
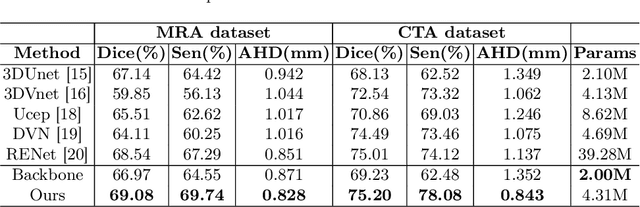
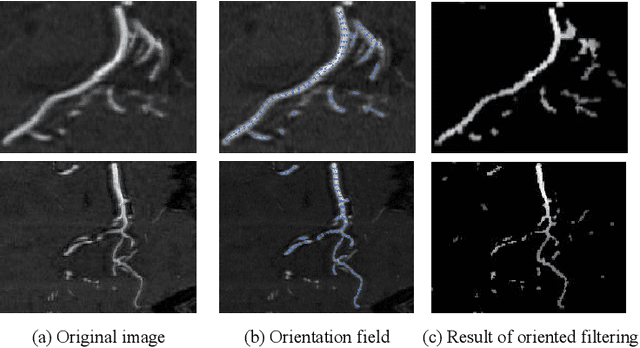

Accurate cerebrovascular segmentation from Magnetic Resonance Angiography (MRA) and Computed Tomography Angiography (CTA) is of great significance in diagnosis and treatment of cerebrovascular pathology. Due to the complexity and topology variability of blood vessels, complete and accurate segmentation of vascular network is still a challenge. In this paper, we proposed a Vessel Oriented Filtering Network (VOF-Net) which embeds domain knowledge into the convolutional neural network. We design oriented filters for blood vessels according to vessel orientation field, which is obtained by orientation estimation network. Features extracted by oriented filtering are injected into segmentation network, so as to make use of the prior information that the blood vessels are slender and curved tubular structure. Experimental results on datasets of CTA and MRA show that the proposed method is effective for vessel segmentation, and embedding the specific vascular filter improves the segmentation performance.
Label2Label: A Language Modeling Framework for Multi-Attribute Learning
Jul 18, 2022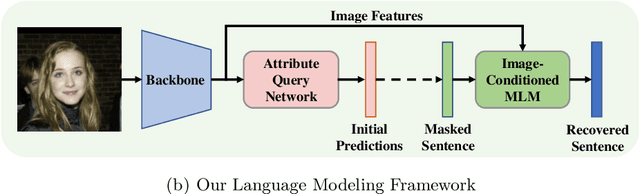

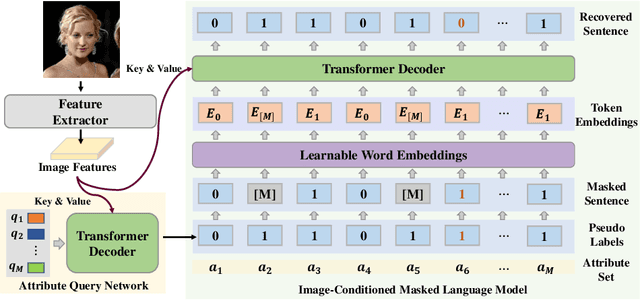
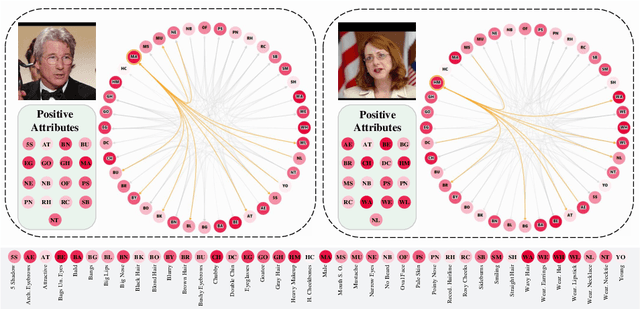
Objects are usually associated with multiple attributes, and these attributes often exhibit high correlations. Modeling complex relationships between attributes poses a great challenge for multi-attribute learning. This paper proposes a simple yet generic framework named Label2Label to exploit the complex attribute correlations. Label2Label is the first attempt for multi-attribute prediction from the perspective of language modeling. Specifically, it treats each attribute label as a "word" describing the sample. As each sample is annotated with multiple attribute labels, these "words" will naturally form an unordered but meaningful "sentence", which depicts the semantic information of the corresponding sample. Inspired by the remarkable success of pre-training language models in NLP, Label2Label introduces an image-conditioned masked language model, which randomly masks some of the "word" tokens from the label "sentence" and aims to recover them based on the masked "sentence" and the context conveyed by image features. Our intuition is that the instance-wise attribute relations are well grasped if the neural net can infer the missing attributes based on the context and the remaining attribute hints. Label2Label is conceptually simple and empirically powerful. Without incorporating task-specific prior knowledge and highly specialized network designs, our approach achieves state-of-the-art results on three different multi-attribute learning tasks, compared to highly customized domain-specific methods. Code is available at https://github.com/Li-Wanhua/Label2Label.