 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiyu Pan
Joint Estimation of Identity Verification and Relative Pose for Partial Fingerprints
May 07, 2024
Currently, portable electronic devices are becoming more and more popular. For lightweight considerations, their fingerprint recognition modules usually use limited-size sensors. However, partial fingerprints have few matchable features, especially when there are differences in finger pressing posture or image quality, which makes partial fingerprint verification challenging. Most existing methods regard fingerprint position rectification and identity verification as independent tasks, ignoring the coupling relationship between them -- relative pose estimation typically relies on paired features as anchors, and authentication accuracy tends to improve with more precise pose alignment. Consequently, in this paper we propose a method that jointly estimates identity verification and relative pose for partial fingerprints, aiming to leverage their inherent correlation to improve each other. To achieve this, we propose a multi-task CNN (Convolutional Neural Network)-Transformer hybrid network, and design a pre-training task to enhance the feature extraction capability. Experiments on multiple public datasets (NIST SD14, FVC2002 DB1A & DB3A, FVC2004 DB1A & DB2A, FVC2006 DB1A) and an in-house dataset show that our method achieves state-of-the-art performance in both partial fingerprint verification and relative pose estimation, while being more efficient than previous methods.
Latent Fingerprint Matching via Dense Minutia Descriptor
May 02, 2024Latent fingerprint matching is a daunting task, primarily due to the poor quality of latent fingerprints. In this study, we propose a deep-learning based dense minutia descriptor (DMD) for latent fingerprint matching. A DMD is obtained by extracting the fingerprint patch aligned by its central minutia, capturing detailed minutia information and texture information. Our dense descriptor takes the form of a three-dimensional representation, with two dimensions associated with the original image plane and the other dimension representing the abstract features. Additionally, the extraction process outputs the fingerprint segmentation map, ensuring that the descriptor is only valid in the foreground region. The matching between two descriptors occurs in their overlapping regions, with a score normalization strategy to reduce the impact brought by the differences outside the valid area. Our descriptor achieves state-of-the-art performance on several latent fingerprint datasets. Overall, our DMD is more representative and interpretable compared to previous methods.
Sports Analysis and VR Viewing System Based on Player Tracking and Pose Estimation with Multimodal and Multiview Sensors
May 02, 2024Sports analysis and viewing play a pivotal role in the current sports domain, offering significant value not only to coaches and athletes but also to fans and the media. In recent years, the rapid development of virtual reality (VR) and augmented reality (AR) technologies have introduced a new platform for watching games. Visualization of sports competitions in VR/AR represents a revolutionary technology, providing audiences with a novel immersive viewing experience. However, there is still a lack of related research in this area. In this work, we present for the first time a comprehensive system for sports competition analysis and real-time visualization on VR/AR platforms. First, we utilize multiview LiDARs and cameras to collect multimodal game data. Subsequently, we propose a framework for multi-player tracking and pose estimation based on a limited amount of supervised data, which extracts precise player positions and movements from point clouds and images. Moreover, we perform avatar modeling of players to obtain their 3D models. Ultimately, using these 3D player data, we conduct competition analysis and real-time visualization on VR/AR. Extensive quantitative experiments demonstrate the accuracy and robustness of our multi-player tracking and pose estimation framework. The visualization results showcase the immense potential of our sports visualization system on the domain of watching games on VR/AR devices. The multimodal competition dataset we collected and all related code will be released soon.
Converting High-Performance and Low-Latency SNNs through Explicit Modelling of Residual Error in ANNs
Apr 26, 2024Spiking neural networks (SNNs) have garnered interest due to their energy efficiency and superior effectiveness on neuromorphic chips compared with traditional artificial neural networks (ANNs). One of the mainstream approaches to implementing deep SNNs is the ANN-SNN conversion, which integrates the efficient training strategy of ANNs with the energy-saving potential and fast inference capability of SNNs. However, under extreme low-latency conditions, the existing conversion theory suggests that the problem of misrepresentation of residual membrane potentials in SNNs, i.e., the inability of IF neurons with a reset-by-subtraction mechanism to respond to residual membrane potentials beyond the range from resting potential to threshold, leads to a performance gap in the converted SNNs compared to the original ANNs. This severely limits the possibility of practical application of SNNs on delay-sensitive edge devices. Existing conversion methods addressing this problem usually involve modifying the state of the conversion spiking neurons. However, these methods do not consider their adaptability and compatibility with neuromorphic chips. We propose a new approach based on explicit modeling of residual errors as additive noise. The noise is incorporated into the activation function of the source ANN, which effectively reduces the residual error. Our experiments on the CIFAR10/100 dataset verify that our approach exceeds the prevailing ANN-SNN conversion methods and directly trained SNNs concerning accuracy and the required time steps. Overall, our method provides new ideas for improving SNN performance under ultra-low-latency conditions and is expected to promote practical neuromorphic hardware applications for further development.
Geometry-aware Reconstruction and Fusion-refined Rendering for Generalizable Neural Radiance Fields
Apr 26, 2024Generalizable NeRF aims to synthesize novel views for unseen scenes. Common practices involve constructing variance-based cost volumes for geometry reconstruction and encoding 3D descriptors for decoding novel views. However, existing methods show limited generalization ability in challenging conditions due to inaccurate geometry, sub-optimal descriptors, and decoding strategies. We address these issues point by point. First, we find the variance-based cost volume exhibits failure patterns as the features of pixels corresponding to the same point can be inconsistent across different views due to occlusions or reflections. We introduce an Adaptive Cost Aggregation (ACA) approach to amplify the contribution of consistent pixel pairs and suppress inconsistent ones. Unlike previous methods that solely fuse 2D features into descriptors, our approach introduces a Spatial-View Aggregator (SVA) to incorporate 3D context into descriptors through spatial and inter-view interaction. When decoding the descriptors, we observe the two existing decoding strategies excel in different areas, which are complementary. A Consistency-Aware Fusion (CAF) strategy is proposed to leverage the advantages of both. We incorporate the above ACA, SVA, and CAF into a coarse-to-fine framework, termed Geometry-aware Reconstruction and Fusion-refined Rendering (GeFu). GeFu attains state-of-the-art performance across multiple datasets. Code is available at https://github.com/TQTQliu/GeFu .
Self-Supervised Class-Agnostic Motion Prediction with Spatial and Temporal Consistency Regularizations
Mar 21, 2024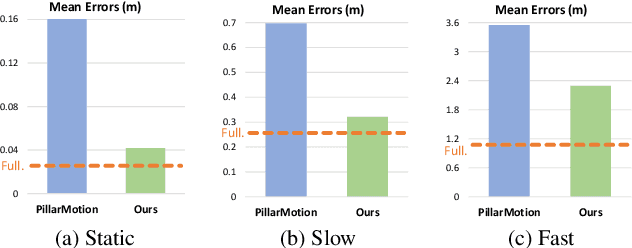
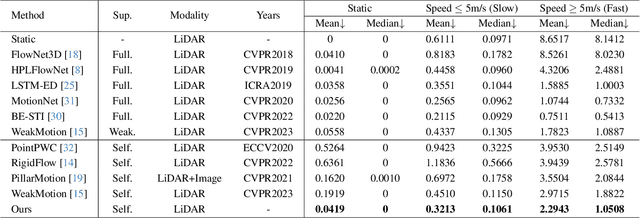
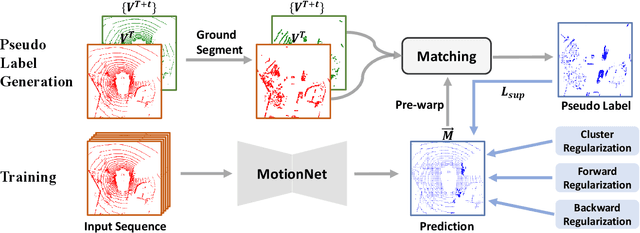
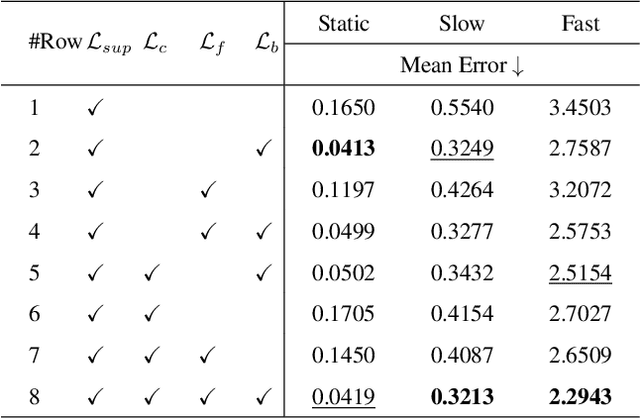
The perception of motion behavior in a dynamic environment holds significant importance for autonomous driving systems, wherein class-agnostic motion prediction methods directly predict the motion of the entire point cloud. While most existing methods rely on fully-supervised learning, the manual labeling of point cloud data is laborious and time-consuming. Therefore, several annotation-efficient methods have been proposed to address this challenge. Although effective, these methods rely on weak annotations or additional multi-modal data like images, and the potential benefits inherent in the point cloud sequence are still underexplored. To this end, we explore the feasibility of self-supervised motion prediction with only unlabeled LiDAR point clouds. Initially, we employ an optimal transport solver to establish coarse correspondences between current and future point clouds as the coarse pseudo motion labels. Training models directly using such coarse labels leads to noticeable spatial and temporal prediction inconsistencies. To mitigate these issues, we introduce three simple spatial and temporal regularization losses, which facilitate the self-supervised training process effectively. Experimental results demonstrate the significant superiority of our approach over the state-of-the-art self-supervised methods.
LM-HT SNN: Enhancing the Performance of SNN to ANN Counterpart through Learnable Multi-hierarchical Threshold Model
Feb 01, 2024Compared to traditional Artificial Neural Network (ANN), Spiking Neural Network (SNN) has garnered widespread academic interest for its intrinsic ability to transmit information in a more biological-inspired and energy-efficient manner. However, despite previous efforts to optimize the learning gradients and model structure of SNNs through various methods, SNNs still lag behind ANNs in terms of performance to some extent. The recently proposed multi-threshold model provides more possibilities for further enhancing the learning capability of SNNs. In this paper, we rigorously analyze the relationship among the multi-threshold model, vanilla spiking model and quantized ANNs from a mathematical perspective, then propose a novel LM-HT model, which is an equidistant multi-hierarchical model that can dynamically regulate the global input current and membrane potential leakage on the time dimension. In addition, we note that the direct training algorithm based on the LM-HT model can seamlessly integrate with the traditional ANN-SNN Conversion framework. This novel hybrid learning framework can effectively improve the relatively poor performance of converted SNNs under low time latency. Extensive experimental results have demonstrated that our LM-HT model can significantly outperform previous state-of-the-art works on various types of datasets, which promote SNNs to achieve a brand-new level of performance comparable to quantized ANNs.
Semi-Supervised Class-Agnostic Motion Prediction with Pseudo Label Regeneration and BEVMix
Dec 14, 2023Class-agnostic motion prediction methods aim to comprehend motion within open-world scenarios, holding significance for autonomous driving systems. However, training a high-performance model in a fully-supervised manner always requires substantial amounts of manually annotated data, which can be both expensive and time-consuming to obtain. To address this challenge, our study explores the potential of semi-supervised learning (SSL) for class-agnostic motion prediction. Our SSL framework adopts a consistency-based self-training paradigm, enabling the model to learn from unlabeled data by generating pseudo labels through test-time inference. To improve the quality of pseudo labels, we propose a novel motion selection and re-generation module. This module effectively selects reliable pseudo labels and re-generates unreliable ones. Furthermore, we propose two data augmentation strategies: temporal sampling and BEVMix. These strategies facilitate consistency regularization in SSL. Experiments conducted on nuScenes demonstrate that our SSL method can surpass the self-supervised approach by a large margin by utilizing only a tiny fraction of labeled data. Furthermore, our method exhibits comparable performance to weakly and some fully supervised methods. These results highlight the ability of our method to strike a favorable balance between annotation costs and performance. Code will be available at https://github.com/kwwcv/SSMP.
PointVoxel: A Simple and Effective Pipeline for Multi-View Multi-Modal 3D Human Pose Estimation
Dec 12, 2023Recently, several methods have been proposed to estimate 3D human pose from multi-view images and achieved impressive performance on public datasets collected in relatively easy scenarios. However, there are limited approaches for extracting 3D human skeletons from multimodal inputs (e.g., RGB and pointcloud) that can enhance the accuracy of predicting 3D poses in challenging situations. We fill this gap by introducing a pipeline called PointVoxel that fuses multi-view RGB and pointcloud inputs to obtain 3D human poses. We demonstrate that volumetric representation is an effective architecture for integrating these different modalities. Moreover, in order to overcome the challenges of annotating 3D human pose labels in difficult scenarios, we develop a synthetic dataset generator for pretraining and design an unsupervised domain adaptation strategy so that we can obtain a well-trained 3D human pose estimator without using any manual annotations. We evaluate our approach on four datasets (two public datasets, one synthetic dataset, and one challenging dataset named BasketBall collected by ourselves), showing promising results. The code and dataset will be released soon.
LiDAR-based Person Re-identification
Dec 11, 2023Camera-based person re-identification (ReID) systems have been widely applied in the field of public security. However, cameras often lack the perception of 3D morphological information of human and are susceptible to various limitations, such as inadequate illumination, complex background, and personal privacy. In this paper, we propose a LiDAR-based ReID framework, ReID3D, that utilizes pre-training strategy to retrieve features of 3D body shape and introduces Graph-based Complementary Enhancement Encoder for extracting comprehensive features. Due to the lack of LiDAR datasets, we build LReID, the first LiDAR-based person ReID dataset, which is collected in several outdoor scenes with variations in natural conditions. Additionally, we introduce LReID-sync, a simulated pedestrian dataset designed for pre-training encoders with tasks of point cloud completion and shape parameter learning. Extensive experiments on LReID show that ReID3D achieves exceptional performance with a rank-1 accuracy of 94.0, highlighting the significant potential of LiDAR in addressing person ReID tasks. To the best of our knowledge, we are the first to propose a solution for LiDAR-based ReID. The code and datasets will be released soon.