 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMin Shi
FairCLIP: Harnessing Fairness in Vision-Language Learning
Apr 05, 2024
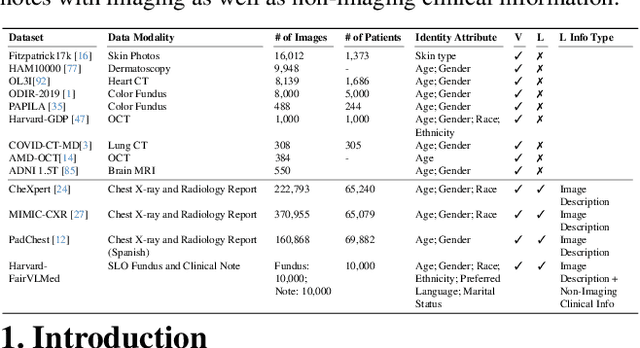
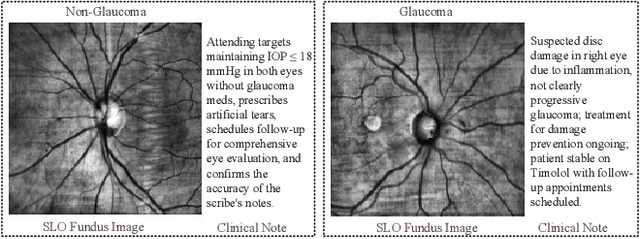
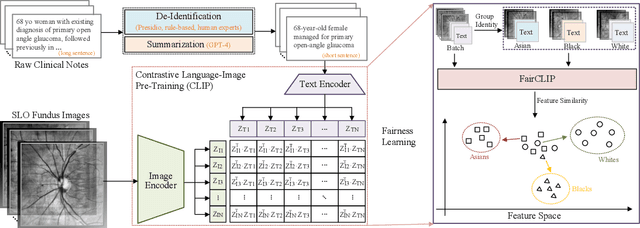
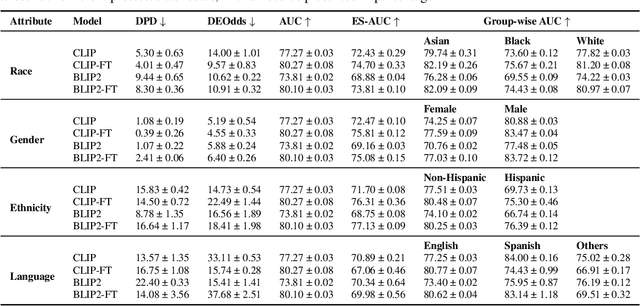
Fairness is a critical concern in deep learning, especially in healthcare, where these models influence diagnoses and treatment decisions. Although fairness has been investigated in the vision-only domain, the fairness of medical vision-language (VL) models remains unexplored due to the scarcity of medical VL datasets for studying fairness. To bridge this research gap, we introduce the first fair vision-language medical dataset Harvard-FairVLMed that provides detailed demographic attributes, ground-truth labels, and clinical notes to facilitate an in-depth examination of fairness within VL foundation models. Using Harvard-FairVLMed, we conduct a comprehensive fairness analysis of two widely-used VL models (CLIP and BLIP2), pre-trained on both natural and medical domains, across four different protected attributes. Our results highlight significant biases in all VL models, with Asian, Male, Non-Hispanic, and Spanish being the preferred subgroups across the protected attributes of race, gender, ethnicity, and language, respectively. In order to alleviate these biases, we propose FairCLIP, an optimal-transport-based approach that achieves a favorable trade-off between performance and fairness by reducing the Sinkhorn distance between the overall sample distribution and the distributions corresponding to each demographic group. As the first VL dataset of its kind, Harvard-FairVLMed holds the potential to catalyze advancements in the development of machine learning models that are both ethically aware and clinically effective. Our dataset and code are available at https://ophai.hms.harvard.edu/datasets/harvard-fairvlmed10k.
3DTopia: Large Text-to-3D Generation Model with Hybrid Diffusion Priors
Mar 04, 2024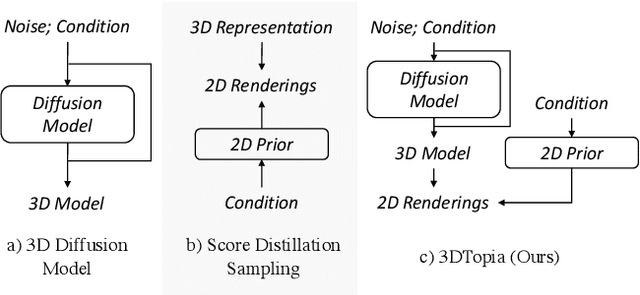

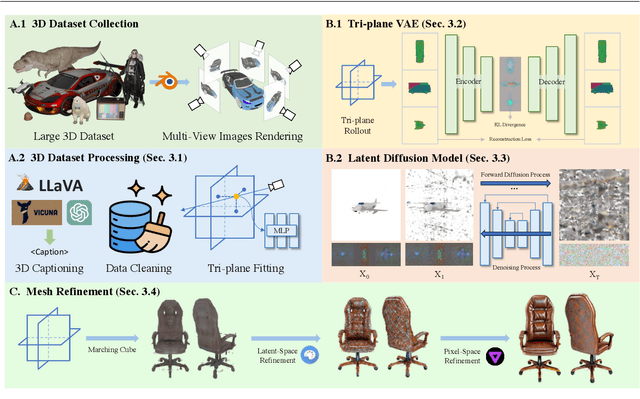
We present a two-stage text-to-3D generation system, namely 3DTopia, which generates high-quality general 3D assets within 5 minutes using hybrid diffusion priors. The first stage samples from a 3D diffusion prior directly learned from 3D data. Specifically, it is powered by a text-conditioned tri-plane latent diffusion model, which quickly generates coarse 3D samples for fast prototyping. The second stage utilizes 2D diffusion priors to further refine the texture of coarse 3D models from the first stage. The refinement consists of both latent and pixel space optimization for high-quality texture generation. To facilitate the training of the proposed system, we clean and caption the largest open-source 3D dataset, Objaverse, by combining the power of vision language models and large language models. Experiment results are reported qualitatively and quantitatively to show the performance of the proposed system. Our codes and models are available at https://github.com/3DTopia/3DTopia
FairSeg: A Large-scale Medical Image Segmentation Dataset for Fairness Learning with Fair Error-Bound Scaling
Nov 03, 2023Fairness in artificial intelligence models has gained significantly more attention in recent years, especially in the area of medicine, as fairness in medical models is critical to people's well-being and lives. High-quality medical fairness datasets are needed to promote fairness learning research. Existing medical fairness datasets are all for classification tasks, and no fairness datasets are available for medical segmentation, while medical segmentation is an equally important clinical task as classifications, which can provide detailed spatial information on organ abnormalities ready to be assessed by clinicians. In this paper, we propose the first fairness dataset for medical segmentation named FairSeg with 10,000 subject samples. In addition, we propose a fair error-bound scaling approach to reweight the loss function with the upper error-bound in each identity group. We anticipate that the segmentation performance equity can be improved by explicitly tackling the hard cases with high training errors in each identity group. To facilitate fair comparisons, we propose new equity-scaled segmentation performance metrics, such as the equity-scaled Dice coefficient, which is calculated as the overall Dice coefficient divided by one plus the standard deviation of group Dice coefficients. Through comprehensive experiments, we demonstrate that our fair error-bound scaling approach either has superior or comparable fairness performance to the state-of-the-art fairness learning models. The dataset and code are publicly accessible via \url{https://github.com/Harvard-Ophthalmology-AI-Lab/FairSeg}.
Harvard Eye Fairness: A Large-Scale 3D Imaging Dataset for Equitable Eye Diseases Screening and Fair Identity Scaling
Oct 05, 2023Fairness or equity in machine learning is profoundly important for societal well-being, but limited public datasets hinder its progress, especially in the area of medicine. It is undeniable that fairness in medicine is one of the most important areas for fairness learning's applications. Currently, no large-scale public medical datasets with 3D imaging data for fairness learning are available, while 3D imaging data in modern clinics are standard tests for disease diagnosis. In addition, existing medical fairness datasets are actually repurposed datasets, and therefore they typically have limited demographic identity attributes with at most three identity attributes of age, gender, and race for fairness modeling. To address this gap, we introduce our Eye Fairness dataset with 30,000 subjects (Harvard-EF) covering three major eye diseases including age-related macular degeneration, diabetic retinopathy, and glaucoma affecting 380 million patients globally. Our Harvard-EF dataset includes both 2D fundus photos and 3D optical coherence tomography scans with six demographic identity attributes including age, gender, race, ethnicity, preferred language, and marital status. We also propose a fair identity scaling (FIS) approach combining group and individual scaling together to improve model fairness. Our FIS approach is compared with various state-of-the-art fairness learning methods with superior performance in the racial, gender, and ethnicity fairness tasks with 2D and 3D imaging data, which demonstrate the utilities of our Harvard-EF dataset for fairness learning. To facilitate fairness comparisons between different models, we propose performance-scaled disparity measures, which can be used to compare model fairness accounting for overall performance levels. The dataset and code are publicly accessible via https://ophai.hms.harvard.edu/datasets/harvard-ef30k.
When Epipolar Constraint Meets Non-local Operators in Multi-View Stereo
Sep 29, 2023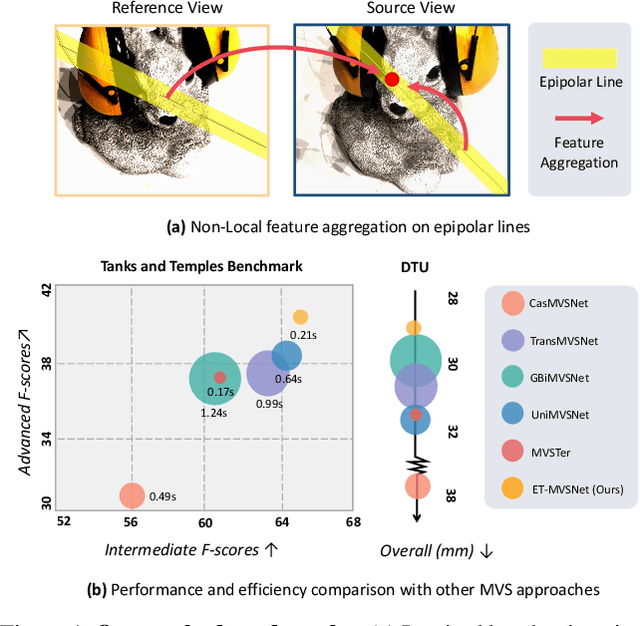
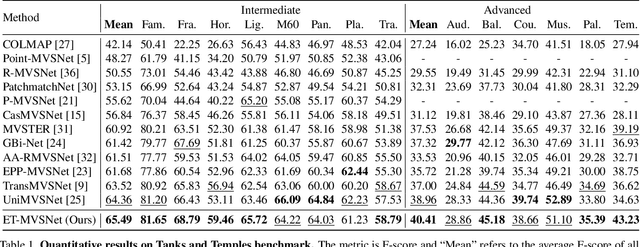
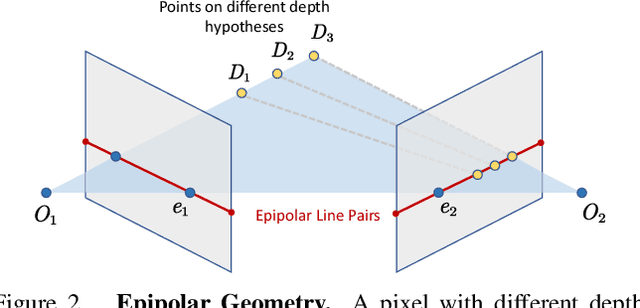
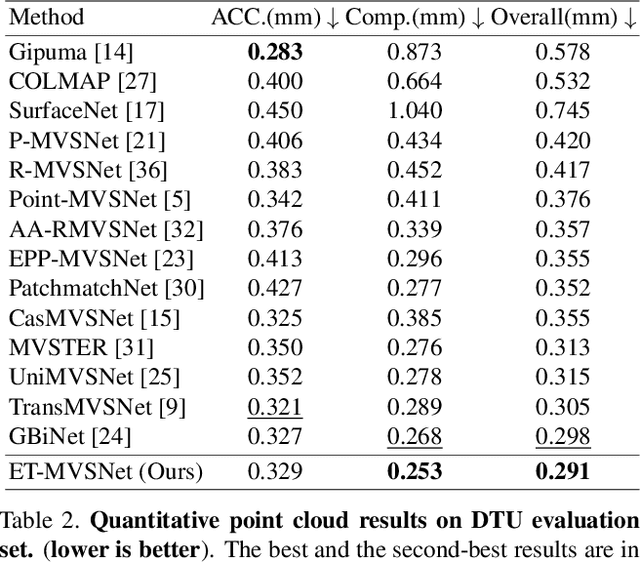
Learning-based multi-view stereo (MVS) method heavily relies on feature matching, which requires distinctive and descriptive representations. An effective solution is to apply non-local feature aggregation, e.g., Transformer. Albeit useful, these techniques introduce heavy computation overheads for MVS. Each pixel densely attends to the whole image. In contrast, we propose to constrain non-local feature augmentation within a pair of lines: each point only attends the corresponding pair of epipolar lines. Our idea takes inspiration from the classic epipolar geometry, which shows that one point with different depth hypotheses will be projected to the epipolar line on the other view. This constraint reduces the 2D search space into the epipolar line in stereo matching. Similarly, this suggests that the matching of MVS is to distinguish a series of points lying on the same line. Inspired by this point-to-line search, we devise a line-to-point non-local augmentation strategy. We first devise an optimized searching algorithm to split the 2D feature maps into epipolar line pairs. Then, an Epipolar Transformer (ET) performs non-local feature augmentation among epipolar line pairs. We incorporate the ET into a learning-based MVS baseline, named ET-MVSNet. ET-MVSNet achieves state-of-the-art reconstruction performance on both the DTU and Tanks-and-Temples benchmark with high efficiency. Code is available at https://github.com/TQTQliu/ET-MVSNet.
EANet: Expert Attention Network for Online Trajectory Prediction
Sep 11, 2023


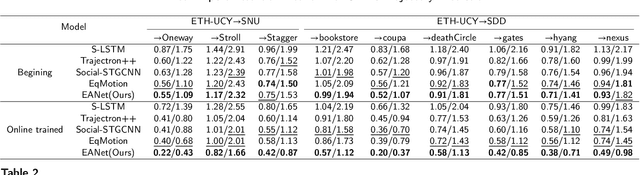
Trajectory prediction plays a crucial role in autonomous driving. Existing mainstream research and continuoual learning-based methods all require training on complete datasets, leading to poor prediction accuracy when sudden changes in scenarios occur and failing to promptly respond and update the model. Whether these methods can make a prediction in real-time and use data instances to update the model immediately(i.e., online learning settings) remains a question. The problem of gradient explosion or vanishing caused by data instance streams also needs to be addressed. Inspired by Hedge Propagation algorithm, we propose Expert Attention Network, a complete online learning framework for trajectory prediction. We introduce expert attention, which adjusts the weights of different depths of network layers, avoiding the model updated slowly due to gradient problem and enabling fast learning of new scenario's knowledge to restore prediction accuracy. Furthermore, we propose a short-term motion trend kernel function which is sensitive to scenario change, allowing the model to respond quickly. To the best of our knowledge, this work is the first attempt to address the online learning problem in trajectory prediction. The experimental results indicate that traditional methods suffer from gradient problems and that our method can quickly reduce prediction errors and reach the state-of-the-art prediction accuracy.
Harvard Glaucoma Detection and Progression: A Multimodal Multitask Dataset and Generalization-Reinforced Semi-Supervised Learning
Aug 25, 2023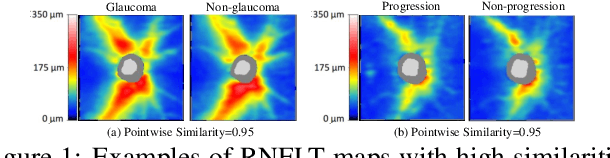
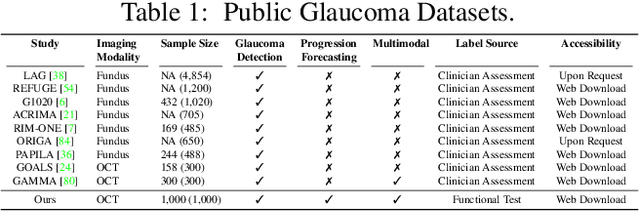
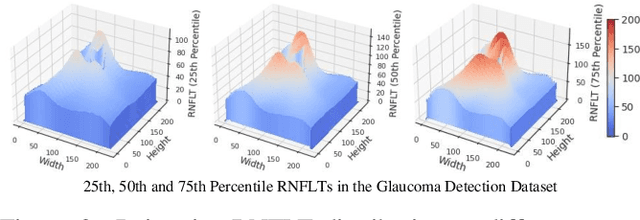
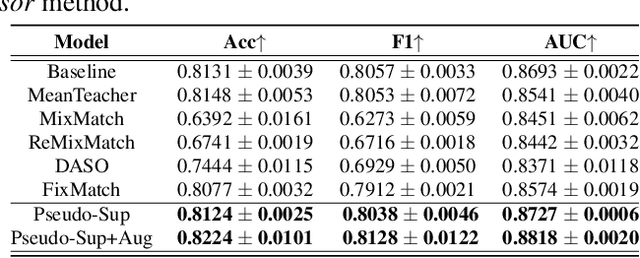
Glaucoma is the number one cause of irreversible blindness globally. A major challenge for accurate glaucoma detection and progression forecasting is the bottleneck of limited labeled patients with the state-of-the-art (SOTA) 3D retinal imaging data of optical coherence tomography (OCT). To address the data scarcity issue, this paper proposes two solutions. First, we develop a novel generalization-reinforced semi-supervised learning (SSL) model called pseudo supervisor to optimally utilize unlabeled data. Compared with SOTA models, the proposed pseudo supervisor optimizes the policy of predicting pseudo labels with unlabeled samples to improve empirical generalization. Our pseudo supervisor model is evaluated with two clinical tasks consisting of glaucoma detection and progression forecasting. The progression forecasting task is evaluated both unimodally and multimodally. Our pseudo supervisor model demonstrates superior performance than SOTA SSL comparison models. Moreover, our model also achieves the best results on the publicly available LAG fundus dataset. Second, we introduce the Harvard Glaucoma Detection and Progression (Harvard-GDP) Dataset, a multimodal multitask dataset that includes data from 1,000 patients with OCT imaging data, as well as labels for glaucoma detection and progression. This is the largest glaucoma detection dataset with 3D OCT imaging data and the first glaucoma progression forecasting dataset that is publicly available. Detailed sex and racial analysis are provided, which can be used by interested researchers for fairness learning studies. Our released dataset is benchmarked with several SOTA supervised CNN and transformer deep learning models. The dataset and code are made publicly available via \url{https://ophai.hms.harvard.edu/datasets/harvard-gdp1000}.
Neural Video Depth Stabilizer
Aug 10, 2023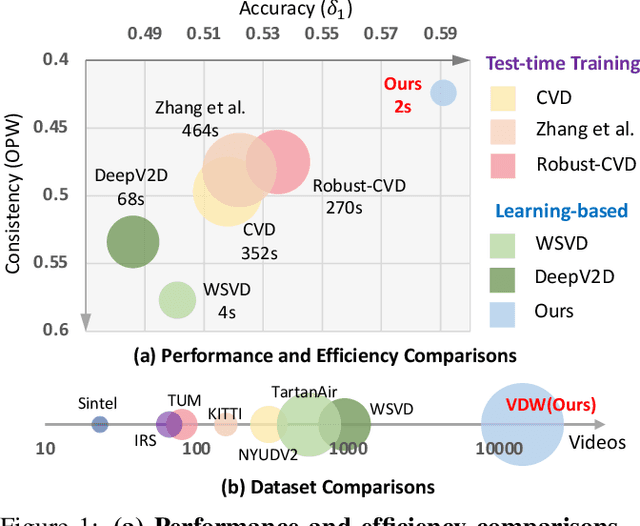
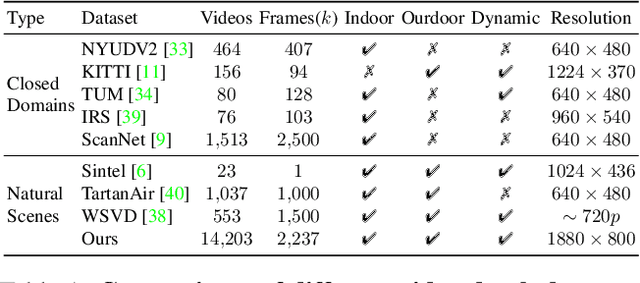
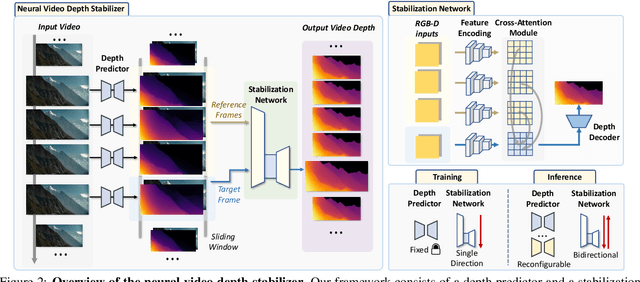
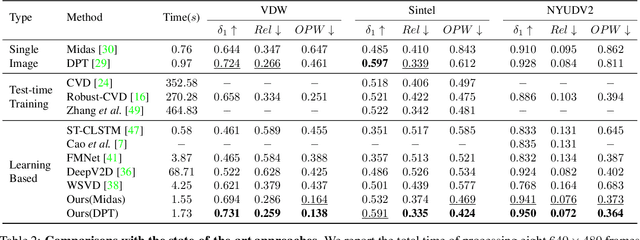
Video depth estimation aims to infer temporally consistent depth. Some methods achieve temporal consistency by finetuning a single-image depth model during test time using geometry and re-projection constraints, which is inefficient and not robust. An alternative approach is to learn how to enforce temporal consistency from data, but this requires well-designed models and sufficient video depth data. To address these challenges, we propose a plug-and-play framework called Neural Video Depth Stabilizer (NVDS) that stabilizes inconsistent depth estimations and can be applied to different single-image depth models without extra effort. We also introduce a large-scale dataset, Video Depth in the Wild (VDW), which consists of 14,203 videos with over two million frames, making it the largest natural-scene video depth dataset to our knowledge. We evaluate our method on the VDW dataset as well as two public benchmarks and demonstrate significant improvements in consistency, accuracy, and efficiency compared to previous approaches. Our work serves as a solid baseline and provides a data foundation for learning-based video depth models. We will release our dataset and code for future research.
The All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of the Open World
Aug 03, 2023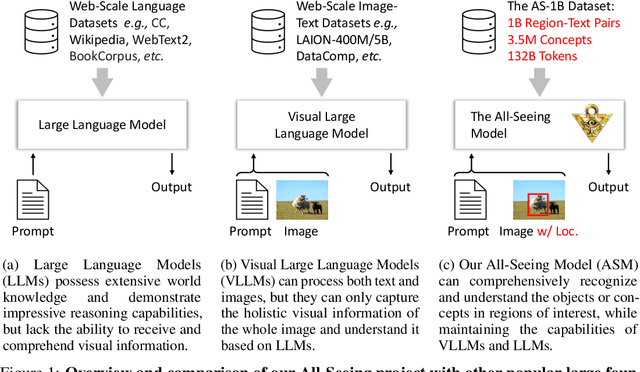
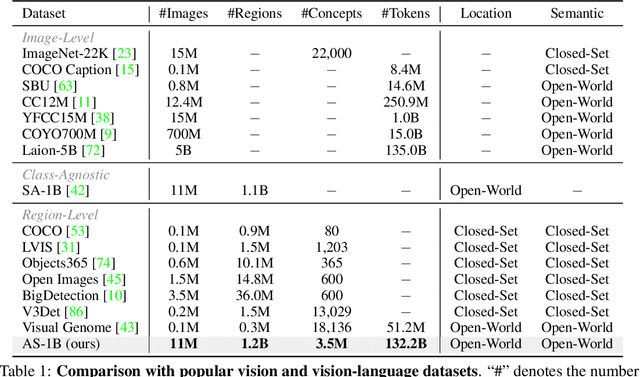
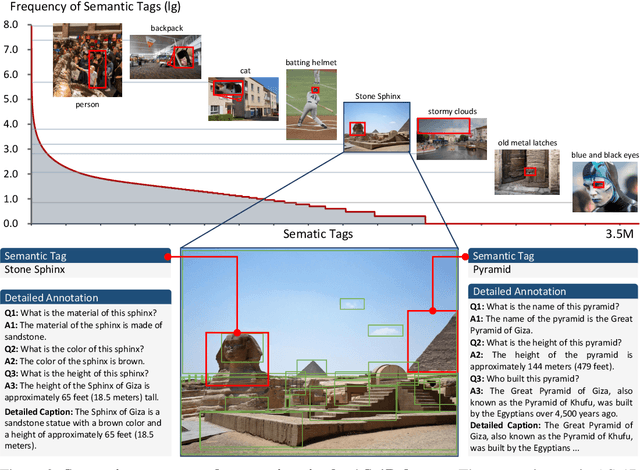
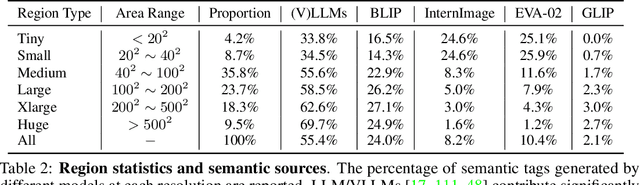
We present the All-Seeing (AS) project: a large-scale data and model for recognizing and understanding everything in the open world. Using a scalable data engine that incorporates human feedback and efficient models in the loop, we create a new dataset (AS-1B) with over 1 billion regions annotated with semantic tags, question-answering pairs, and detailed captions. It covers a wide range of 3.5 million common and rare concepts in the real world, and has 132.2 billion tokens that describe the concepts and their attributes. Leveraging this new dataset, we develop the All-Seeing model (ASM), a unified framework for panoptic visual recognition and understanding. The model is trained with open-ended language prompts and locations, which allows it to generalize to various vision and language tasks with remarkable zero-shot performance, including region-text retrieval, region recognition, captioning, and question-answering. We hope that this project can serve as a foundation for vision-language artificial general intelligence research. Models and the dataset shall be released at https://github.com/OpenGVLab/All-Seeing, and demo can be seen at https://huggingface.co/spaces/OpenGVLab/all-seeing.
Harvard Glaucoma Fairness: A Retinal Nerve Disease Dataset for Fairness Learning and Fair Identity Normalization
Jun 15, 2023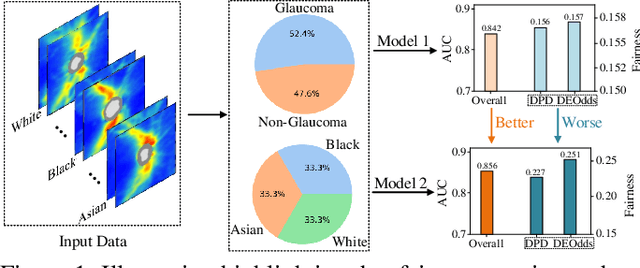
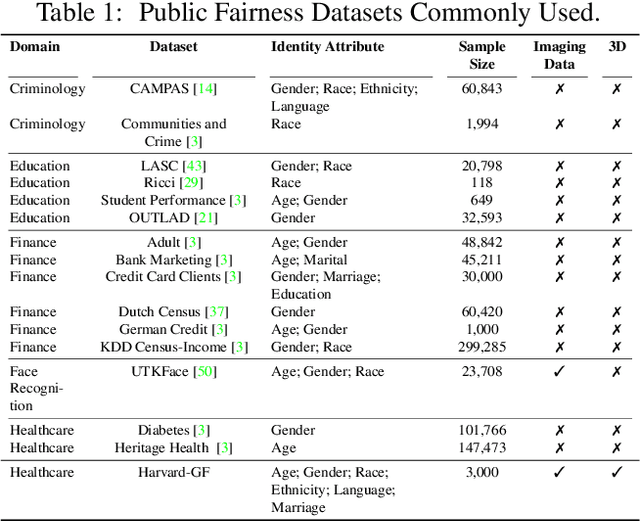
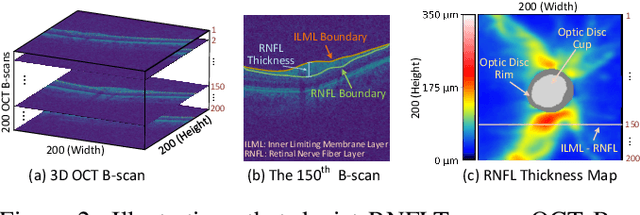
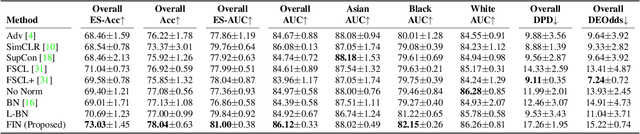
Fairness in machine learning is important for societal well-being, but limited public datasets hinder its progress. Currently, no dedicated public medical datasets with imaging data for fairness learning are available, though minority groups suffer from more health issues. To address this gap, we introduce Harvard Glaucoma Fairness (Harvard-GF), a retinal nerve disease dataset with both 2D and 3D imaging data and balanced racial groups for glaucoma detection. Glaucoma is the leading cause of irreversible blindness globally with Blacks having doubled glaucoma prevalence than other races. We also propose a fair identity normalization (FIN) approach to equalize the feature importance between different identity groups. Our FIN approach is compared with various the-state-of-the-arts fairness learning methods with superior performance in both racial and gender fairness tasks with 2D and 3D imaging data, which demonstrate the utilities of our dataset Harvard-GF for fairness learning. To facilitate fairness comparisons between different models, we propose an equity-scaled performance measure, which can be flexibly used to compare all kinds of performance metrics in the context of fairness. The dataset and code are publicly accessible via https://doi.org/10.7910/DVN/A4XMO1 and https://github.com/luoyan407/Harvard-GF, respectively.