 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYi Fang
Q-PEFT: Query-dependent Parameter Efficient Fine-tuning for Text Reranking with Large Language Models
Apr 12, 2024
Parameter Efficient Fine-Tuning (PEFT) methods have been extensively utilized in Large Language Models (LLMs) to improve the down-streaming tasks without the cost of fine-tuing the whole LLMs. Recent studies have shown how to effectively use PEFT for fine-tuning LLMs in ranking tasks with convincing performance; there are some limitations, including the learned prompt being fixed for different documents, overfitting to specific tasks, and low adaptation ability. In this paper, we introduce a query-dependent parameter efficient fine-tuning (Q-PEFT) approach for text reranking to leak the information of the true queries to LLMs and then make the generation of true queries from input documents much easier. Specifically, we utilize the query to extract the top-$k$ tokens from concatenated documents, serving as contextual clues. We further augment Q-PEFT by substituting the retrieval mechanism with a multi-head attention layer to achieve end-to-end training and cover all the tokens in the documents, guiding the LLMs to generate more document-specific synthetic queries, thereby further improving the reranking performance. Extensive experiments are conducted on four public datasets, demonstrating the effectiveness of our proposed approach.
Mitigating Receiver Impact on Radio Frequency Fingerprint Identification via Domain Adaptation
Apr 12, 2024Radio Frequency Fingerprint Identification (RFFI), which exploits non-ideal hardware-induced unique distortion resident in the transmit signals to identify an emitter, is emerging as a means to enhance the security of communication systems. Recently, machine learning has achieved great success in developing state-of-the-art RFFI models. However, few works consider cross-receiver RFFI problems, where the RFFI model is trained and deployed on different receivers. Due to altered receiver characteristics, direct deployment of RFFI model on a new receiver leads to significant performance degradation. To address this issue, we formulate the cross-receiver RFFI as a model adaptation problem, which adapts the trained model to unlabeled signals from a new receiver. We first develop a theoretical generalization error bound for the adaptation model. Motivated by the bound, we propose a novel method to solve the cross-receiver RFFI problem, which includes domain alignment and adaptive pseudo-labeling. The former aims at finding a feature space where both domains exhibit similar distributions, effectively reducing the domain discrepancy. Meanwhile, the latter employs a dynamic pseudo-labeling scheme to implicitly transfer the label information from the labeled receiver to the new receiver. Experimental results indicate that the proposed method can effectively mitigate the receiver impact and improve the cross-receiver RFFI performance.
FairCLIP: Harnessing Fairness in Vision-Language Learning
Apr 05, 2024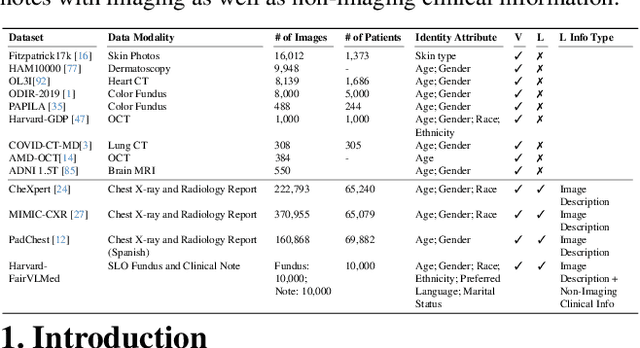
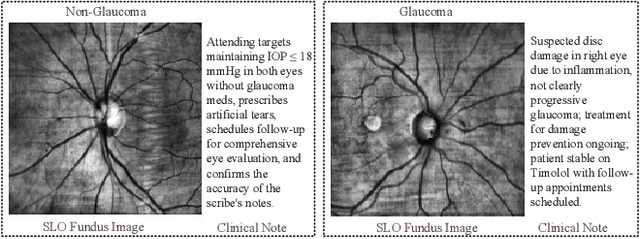
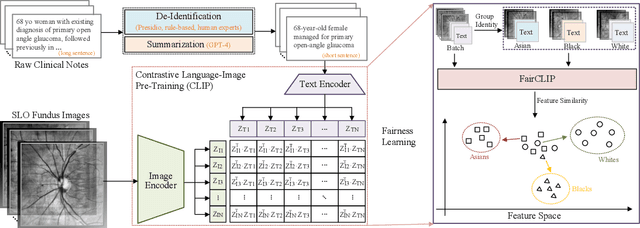
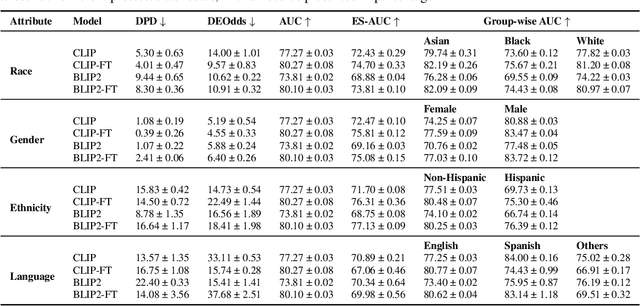
Fairness is a critical concern in deep learning, especially in healthcare, where these models influence diagnoses and treatment decisions. Although fairness has been investigated in the vision-only domain, the fairness of medical vision-language (VL) models remains unexplored due to the scarcity of medical VL datasets for studying fairness. To bridge this research gap, we introduce the first fair vision-language medical dataset Harvard-FairVLMed that provides detailed demographic attributes, ground-truth labels, and clinical notes to facilitate an in-depth examination of fairness within VL foundation models. Using Harvard-FairVLMed, we conduct a comprehensive fairness analysis of two widely-used VL models (CLIP and BLIP2), pre-trained on both natural and medical domains, across four different protected attributes. Our results highlight significant biases in all VL models, with Asian, Male, Non-Hispanic, and Spanish being the preferred subgroups across the protected attributes of race, gender, ethnicity, and language, respectively. In order to alleviate these biases, we propose FairCLIP, an optimal-transport-based approach that achieves a favorable trade-off between performance and fairness by reducing the Sinkhorn distance between the overall sample distribution and the distributions corresponding to each demographic group. As the first VL dataset of its kind, Harvard-FairVLMed holds the potential to catalyze advancements in the development of machine learning models that are both ethically aware and clinically effective. Our dataset and code are available at https://ophai.hms.harvard.edu/datasets/harvard-fairvlmed10k.
Do Large Language Models Rank Fairly? An Empirical Study on the Fairness of LLMs as Rankers
Apr 04, 2024The integration of Large Language Models (LLMs) in information retrieval has raised a critical reevaluation of fairness in the text-ranking models. LLMs, such as GPT models and Llama2, have shown effectiveness in natural language understanding tasks, and prior works (e.g., RankGPT) have also demonstrated that the LLMs exhibit better performance than the traditional ranking models in the ranking task. However, their fairness remains largely unexplored. This paper presents an empirical study evaluating these LLMs using the TREC Fair Ranking dataset, focusing on the representation of binary protected attributes such as gender and geographic location, which are historically underrepresented in search outcomes. Our analysis delves into how these LLMs handle queries and documents related to these attributes, aiming to uncover biases in their ranking algorithms. We assess fairness from both user and content perspectives, contributing an empirical benchmark for evaluating LLMs as the fair ranker.
Mathematical Foundation and Corrections for Full Range Head Pose Estimation
Mar 26, 2024
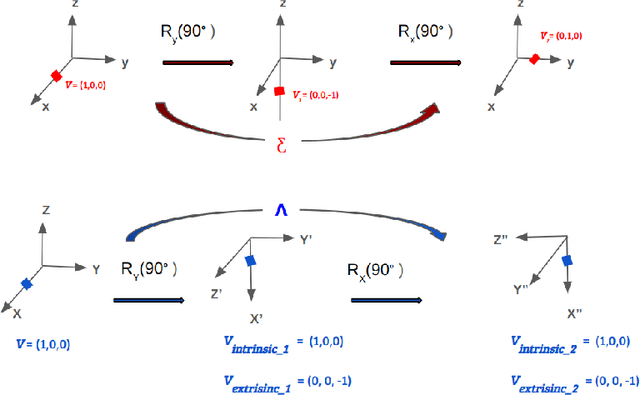
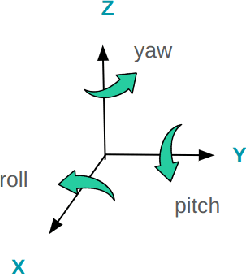
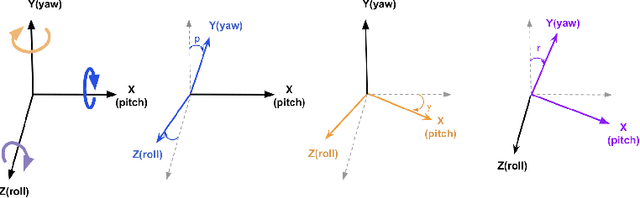
Numerous works concerning head pose estimation (HPE) offer algorithms or proposed neural network-based approaches for extracting Euler angles from either facial key points or directly from images of the head region. However, many works failed to provide clear definitions of the coordinate systems and Euler or Tait-Bryan angles orders in use. It is a well-known fact that rotation matrices depend on coordinate systems, and yaw, roll, and pitch angles are sensitive to their application order. Without precise definitions, it becomes challenging to validate the correctness of the output head pose and drawing routines employed in prior works. In this paper, we thoroughly examined the Euler angles defined in the 300W-LP dataset, head pose estimation such as 3DDFA-v2, 6D-RepNet, WHENet, etc, and the validity of their drawing routines of the Euler angles. When necessary, we infer their coordinate system and sequence of yaw, roll, pitch from provided code. This paper presents (1) code and algorithms for inferring coordinate system from provided source code, code for Euler angle application order and extracting precise rotation matrices and the Euler angles, (2) code and algorithms for converting poses from one rotation system to another, (3) novel formulae for 2D augmentations of the rotation matrices, and (4) derivations and code for the correct drawing routines for rotation matrices and poses. This paper also addresses the feasibility of defining rotations with right-handed coordinate system in Wikipedia and SciPy, which makes the Euler angle extraction much easier for full-range head pose research.
How Secure Are Large Language Models (LLMs) for Navigation in Urban Environments?
Feb 14, 2024In the field of robotics and automation, navigation systems based on Large Language Models (LLMs) have recently shown impressive performance. However, the security aspects of these systems have received relatively less attention. This paper pioneers the exploration of vulnerabilities in LLM-based navigation models in urban outdoor environments, a critical area given the technology's widespread application in autonomous driving, logistics, and emergency services. Specifically, we introduce a novel Navigational Prompt Suffix (NPS) Attack that manipulates LLM-based navigation models by appending gradient-derived suffixes to the original navigational prompt, leading to incorrect actions. We conducted comprehensive experiments on an LLMs-based navigation model that employs various LLMs for reasoning. Our results, derived from the Touchdown and Map2Seq street-view datasets under both few-shot learning and fine-tuning configurations, demonstrate notable performance declines across three metrics in the face of both white-box and black-box attacks. These results highlight the generalizability and transferability of the NPS Attack, emphasizing the need for enhanced security in LLM-based navigation systems. As an initial countermeasure, we propose the Navigational Prompt Engineering (NPE) Defense strategy, concentrating on navigation-relevant keywords to reduce the impact of adversarial suffixes. While initial findings indicate that this strategy enhances navigational safety, there remains a critical need for the wider research community to develop stronger defense methods to effectively tackle the real-world challenges faced by these systems.
Differentiable Registration of Images and LiDAR Point Clouds with VoxelPoint-to-Pixel Matching
Dec 07, 2023Cross-modality registration between 2D images from cameras and 3D point clouds from LiDARs is a crucial task in computer vision and robotic. Previous methods estimate 2D-3D correspondences by matching point and pixel patterns learned by neural networks, and use Perspective-n-Points (PnP) to estimate rigid transformation during post-processing. However, these methods struggle to map points and pixels to a shared latent space robustly since points and pixels have very different characteristics with patterns learned in different manners (MLP and CNN), and they also fail to construct supervision directly on the transformation since the PnP is non-differentiable, which leads to unstable registration results. To address these problems, we propose to learn a structured cross-modality latent space to represent pixel features and 3D features via a differentiable probabilistic PnP solver. Specifically, we design a triplet network to learn VoxelPoint-to-Pixel matching, where we represent 3D elements using both voxels and points to learn the cross-modality latent space with pixels. We design both the voxel and pixel branch based on CNNs to operate convolutions on voxels/pixels represented in grids, and integrate an additional point branch to regain the information lost during voxelization. We train our framework end-to-end by imposing supervisions directly on the predicted pose distribution with a probabilistic PnP solver. To explore distinctive patterns of cross-modality features, we design a novel loss with adaptive-weighted optimization for cross-modality feature description. The experimental results on KITTI and nuScenes datasets show significant improvements over the state-of-the-art methods. The code and models are available at https://github.com/junshengzhou/VP2P-Match.
MemoryCompanion: A Smart Healthcare Solution to Empower Efficient Alzheimer's Care Via Unleashing Generative AI
Nov 20, 2023With the rise of Large Language Models (LLMs), notably characterized by GPT frameworks, there emerges a catalyst for novel healthcare applications. Earlier iterations of chatbot caregivers, though existent, have yet to achieve a dimension of human-like authenticity. This paper unveils `MemoryCompanion' a pioneering digital health solution explicitly tailored for Alzheimer's disease (AD) patients and their caregivers. Drawing upon the nuances of GPT technology and prompt engineering, MemoryCompanion manifests a personalized caregiving paradigm, fostering interactions via voice-cloning and talking-face mechanisms that resonate with the familiarity of known companions. Using advanced prompt-engineering, the system intricately adapts to each patient's distinct profile, curating its content and communication style accordingly. This approach strives to counteract prevalent issues of social isolation and loneliness frequently observed in AD demographics. Our methodology, grounded in its innovative design, addresses both the caregiving and technological challenges intrinsic to this domain.
NeuralGF: Unsupervised Point Normal Estimation by Learning Neural Gradient Function
Nov 01, 2023Normal estimation for 3D point clouds is a fundamental task in 3D geometry processing. The state-of-the-art methods rely on priors of fitting local surfaces learned from normal supervision. However, normal supervision in benchmarks comes from synthetic shapes and is usually not available from real scans, thereby limiting the learned priors of these methods. In addition, normal orientation consistency across shapes remains difficult to achieve without a separate post-processing procedure. To resolve these issues, we propose a novel method for estimating oriented normals directly from point clouds without using ground truth normals as supervision. We achieve this by introducing a new paradigm for learning neural gradient functions, which encourages the neural network to fit the input point clouds and yield unit-norm gradients at the points. Specifically, we introduce loss functions to facilitate query points to iteratively reach the moving targets and aggregate onto the approximated surface, thereby learning a global surface representation of the data. Meanwhile, we incorporate gradients into the surface approximation to measure the minimum signed deviation of queries, resulting in a consistent gradient field associated with the surface. These techniques lead to our deep unsupervised oriented normal estimator that is robust to noise, outliers and density variations. Our excellent results on widely used benchmarks demonstrate that our method can learn more accurate normals for both unoriented and oriented normal estimation tasks than the latest methods. The source code and pre-trained model are publicly available at https://github.com/LeoQLi/NeuralGF.
VisPercep: A Vision-Language Approach to Enhance Visual Perception for People with Blindness and Low Vision
Oct 31, 2023People with blindness and low vision (pBLV) encounter substantial challenges when it comes to comprehensive scene recognition and precise object identification in unfamiliar environments. Additionally, due to the vision loss, pBLV have difficulty in accessing and identifying potential tripping hazards on their own. In this paper, we present a pioneering approach that leverages a large vision-language model to enhance visual perception for pBLV, offering detailed and comprehensive descriptions of the surrounding environments and providing warnings about the potential risks. Our method begins by leveraging a large image tagging model (i.e., Recognize Anything (RAM)) to identify all common objects present in the captured images. The recognition results and user query are then integrated into a prompt, tailored specifically for pBLV using prompt engineering. By combining the prompt and input image, a large vision-language model (i.e., InstructBLIP) generates detailed and comprehensive descriptions of the environment and identifies potential risks in the environment by analyzing the environmental objects and scenes, relevant to the prompt. We evaluate our approach through experiments conducted on both indoor and outdoor datasets. Our results demonstrate that our method is able to recognize objects accurately and provide insightful descriptions and analysis of the environment for pBLV.