 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu-Shen Liu
UDiFF: Generating Conditional Unsigned Distance Fields with Optimal Wavelet Diffusion
Apr 10, 2024
Diffusion models have shown remarkable results for image generation, editing and inpainting. Recent works explore diffusion models for 3D shape generation with neural implicit functions, i.e., signed distance function and occupancy function. However, they are limited to shapes with closed surfaces, which prevents them from generating diverse 3D real-world contents containing open surfaces. In this work, we present UDiFF, a 3D diffusion model for unsigned distance fields (UDFs) which is capable to generate textured 3D shapes with open surfaces from text conditions or unconditionally. Our key idea is to generate UDFs in spatial-frequency domain with an optimal wavelet transformation, which produces a compact representation space for UDF generation. Specifically, instead of selecting an appropriate wavelet transformation which requires expensive manual efforts and still leads to large information loss, we propose a data-driven approach to learn the optimal wavelet transformation for UDFs. We evaluate UDiFF to show our advantages by numerical and visual comparisons with the latest methods on widely used benchmarks. Page: https://weiqi-zhang.github.io/UDiFF.
GridFormer: Point-Grid Transformer for Surface Reconstruction
Jan 04, 2024Implicit neural networks have emerged as a crucial technology in 3D surface reconstruction. To reconstruct continuous surfaces from discrete point clouds, encoding the input points into regular grid features (plane or volume) has been commonly employed in existing approaches. However, these methods typically use the grid as an index for uniformly scattering point features. Compared with the irregular point features, the regular grid features may sacrifice some reconstruction details but improve efficiency. To take full advantage of these two types of features, we introduce a novel and high-efficiency attention mechanism between the grid and point features named Point-Grid Transformer (GridFormer). This mechanism treats the grid as a transfer point connecting the space and point cloud. Our method maximizes the spatial expressiveness of grid features and maintains computational efficiency. Furthermore, optimizing predictions over the entire space could potentially result in blurred boundaries. To address this issue, we further propose a boundary optimization strategy incorporating margin binary cross-entropy loss and boundary sampling. This approach enables us to achieve a more precise representation of the object structure. Our experiments validate that our method is effective and outperforms the state-of-the-art approaches under widely used benchmarks by producing more precise geometry reconstructions. The code is available at https://github.com/list17/GridFormer.
Learning Continuous Implicit Field with Local Distance Indicator for Arbitrary-Scale Point Cloud Upsampling
Dec 23, 2023Point cloud upsampling aims to generate dense and uniformly distributed point sets from a sparse point cloud, which plays a critical role in 3D computer vision. Previous methods typically split a sparse point cloud into several local patches, upsample patch points, and merge all upsampled patches. However, these methods often produce holes, outliers or nonuniformity due to the splitting and merging process which does not maintain consistency among local patches. To address these issues, we propose a novel approach that learns an unsigned distance field guided by local priors for point cloud upsampling. Specifically, we train a local distance indicator (LDI) that predicts the unsigned distance from a query point to a local implicit surface. Utilizing the learned LDI, we learn an unsigned distance field to represent the sparse point cloud with patch consistency. At inference time, we randomly sample queries around the sparse point cloud, and project these query points onto the zero-level set of the learned implicit field to generate a dense point cloud. We justify that the implicit field is naturally continuous, which inherently enables the application of arbitrary-scale upsampling without necessarily retraining for various scales. We conduct comprehensive experiments on both synthetic data and real scans, and report state-of-the-art results under widely used benchmarks.
NeuSurf: On-Surface Priors for Neural Surface Reconstruction from Sparse Input Views
Dec 22, 2023Recently, neural implicit functions have demonstrated remarkable results in the field of multi-view reconstruction. However, most existing methods are tailored for dense views and exhibit unsatisfactory performance when dealing with sparse views. Several latest methods have been proposed for generalizing implicit reconstruction to address the sparse view reconstruction task, but they still suffer from high training costs and are merely valid under carefully selected perspectives. In this paper, we propose a novel sparse view reconstruction framework that leverages on-surface priors to achieve highly faithful surface reconstruction. Specifically, we design several constraints on global geometry alignment and local geometry refinement for jointly optimizing coarse shapes and fine details. To achieve this, we train a neural network to learn a global implicit field from the on-surface points obtained from SfM and then leverage it as a coarse geometric constraint. To exploit local geometric consistency, we project on-surface points onto seen and unseen views, treating the consistent loss of projected features as a fine geometric constraint. The experimental results with DTU and BlendedMVS datasets in two prevalent sparse settings demonstrate significant improvements over the state-of-the-art methods.
Differentiable Registration of Images and LiDAR Point Clouds with VoxelPoint-to-Pixel Matching
Dec 07, 2023Cross-modality registration between 2D images from cameras and 3D point clouds from LiDARs is a crucial task in computer vision and robotic. Previous methods estimate 2D-3D correspondences by matching point and pixel patterns learned by neural networks, and use Perspective-n-Points (PnP) to estimate rigid transformation during post-processing. However, these methods struggle to map points and pixels to a shared latent space robustly since points and pixels have very different characteristics with patterns learned in different manners (MLP and CNN), and they also fail to construct supervision directly on the transformation since the PnP is non-differentiable, which leads to unstable registration results. To address these problems, we propose to learn a structured cross-modality latent space to represent pixel features and 3D features via a differentiable probabilistic PnP solver. Specifically, we design a triplet network to learn VoxelPoint-to-Pixel matching, where we represent 3D elements using both voxels and points to learn the cross-modality latent space with pixels. We design both the voxel and pixel branch based on CNNs to operate convolutions on voxels/pixels represented in grids, and integrate an additional point branch to regain the information lost during voxelization. We train our framework end-to-end by imposing supervisions directly on the predicted pose distribution with a probabilistic PnP solver. To explore distinctive patterns of cross-modality features, we design a novel loss with adaptive-weighted optimization for cross-modality feature description. The experimental results on KITTI and nuScenes datasets show significant improvements over the state-of-the-art methods. The code and models are available at https://github.com/junshengzhou/VP2P-Match.
GeoDream: Disentangling 2D and Geometric Priors for High-Fidelity and Consistent 3D Generation
Dec 01, 2023Text-to-3D generation by distilling pretrained large-scale text-to-image diffusion models has shown great promise but still suffers from inconsistent 3D geometric structures (Janus problems) and severe artifacts. The aforementioned problems mainly stem from 2D diffusion models lacking 3D awareness during the lifting. In this work, we present GeoDream, a novel method that incorporates explicit generalized 3D priors with 2D diffusion priors to enhance the capability of obtaining unambiguous 3D consistent geometric structures without sacrificing diversity or fidelity. Specifically, we first utilize a multi-view diffusion model to generate posed images and then construct cost volume from the predicted image, which serves as native 3D geometric priors, ensuring spatial consistency in 3D space. Subsequently, we further propose to harness 3D geometric priors to unlock the great potential of 3D awareness in 2D diffusion priors via a disentangled design. Notably, disentangling 2D and 3D priors allows us to refine 3D geometric priors further. We justify that the refined 3D geometric priors aid in the 3D-aware capability of 2D diffusion priors, which in turn provides superior guidance for the refinement of 3D geometric priors. Our numerical and visual comparisons demonstrate that GeoDream generates more 3D consistent textured meshes with high-resolution realistic renderings (i.e., 1024 $\times$ 1024) and adheres more closely to semantic coherence.
NeuralGF: Unsupervised Point Normal Estimation by Learning Neural Gradient Function
Nov 01, 2023Normal estimation for 3D point clouds is a fundamental task in 3D geometry processing. The state-of-the-art methods rely on priors of fitting local surfaces learned from normal supervision. However, normal supervision in benchmarks comes from synthetic shapes and is usually not available from real scans, thereby limiting the learned priors of these methods. In addition, normal orientation consistency across shapes remains difficult to achieve without a separate post-processing procedure. To resolve these issues, we propose a novel method for estimating oriented normals directly from point clouds without using ground truth normals as supervision. We achieve this by introducing a new paradigm for learning neural gradient functions, which encourages the neural network to fit the input point clouds and yield unit-norm gradients at the points. Specifically, we introduce loss functions to facilitate query points to iteratively reach the moving targets and aggregate onto the approximated surface, thereby learning a global surface representation of the data. Meanwhile, we incorporate gradients into the surface approximation to measure the minimum signed deviation of queries, resulting in a consistent gradient field associated with the surface. These techniques lead to our deep unsupervised oriented normal estimator that is robust to noise, outliers and density variations. Our excellent results on widely used benchmarks demonstrate that our method can learn more accurate normals for both unoriented and oriented normal estimation tasks than the latest methods. The source code and pre-trained model are publicly available at https://github.com/LeoQLi/NeuralGF.
Uni3D: Exploring Unified 3D Representation at Scale
Oct 10, 2023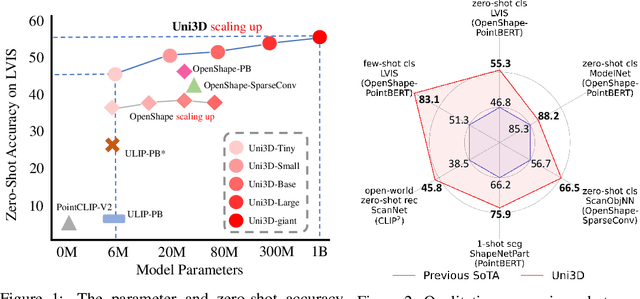
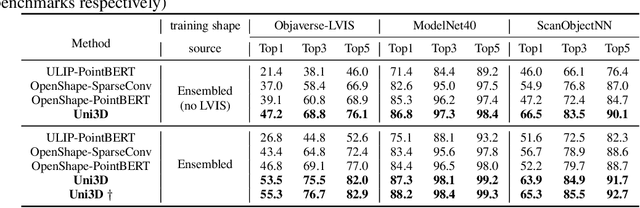
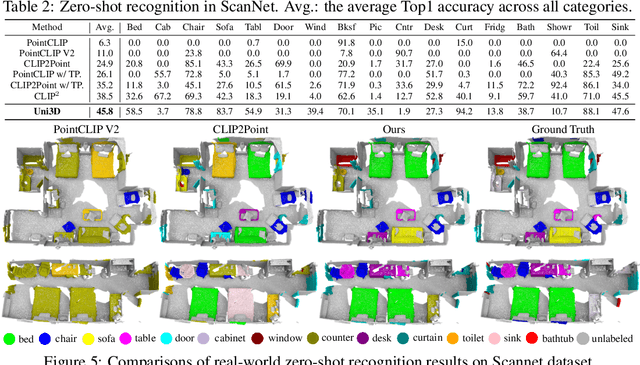
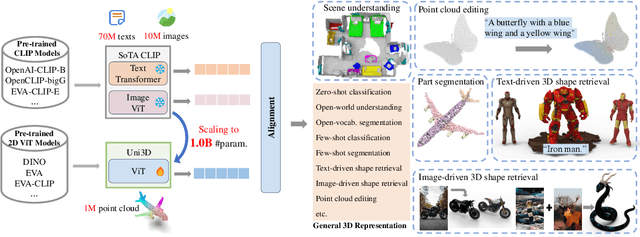
Scaling up representations for images or text has been extensively investigated in the past few years and has led to revolutions in learning vision and language. However, scalable representation for 3D objects and scenes is relatively unexplored. In this work, we present Uni3D, a 3D foundation model to explore the unified 3D representation at scale. Uni3D uses a 2D initialized ViT end-to-end pretrained to align the 3D point cloud features with the image-text aligned features. Via the simple architecture and pretext task, Uni3D can leverage abundant 2D pretrained models as initialization and image-text aligned models as the target, unlocking the great potential of 2D models and scaling-up strategies to the 3D world. We efficiently scale up Uni3D to one billion parameters, and set new records on a broad range of 3D tasks, such as zero-shot classification, few-shot classification, open-world understanding and part segmentation. We show that the strong Uni3D representation also enables applications such as 3D painting and retrieval in the wild. We believe that Uni3D provides a new direction for exploring both scaling up and efficiency of the representation in 3D domain.
Neural Gradient Learning and Optimization for Oriented Point Normal Estimation
Sep 17, 2023We propose Neural Gradient Learning (NGL), a deep learning approach to learn gradient vectors with consistent orientation from 3D point clouds for normal estimation. It has excellent gradient approximation properties for the underlying geometry of the data. We utilize a simple neural network to parameterize the objective function to produce gradients at points using a global implicit representation. However, the derived gradients usually drift away from the ground-truth oriented normals due to the lack of local detail descriptions. Therefore, we introduce Gradient Vector Optimization (GVO) to learn an angular distance field based on local plane geometry to refine the coarse gradient vectors. Finally, we formulate our method with a two-phase pipeline of coarse estimation followed by refinement. Moreover, we integrate two weighting functions, i.e., anisotropic kernel and inlier score, into the optimization to improve the robust and detail-preserving performance. Our method efficiently conducts global gradient approximation while achieving better accuracy and generalization ability of local feature description. This leads to a state-of-the-art normal estimator that is robust to noise, outliers and point density variations. Extensive evaluations show that our method outperforms previous works in both unoriented and oriented normal estimation on widely used benchmarks. The source code and pre-trained models are available at https://github.com/LeoQLi/NGLO.