 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXuyang Wu
Q-PEFT: Query-dependent Parameter Efficient Fine-tuning for Text Reranking with Large Language Models
Apr 12, 2024
Parameter Efficient Fine-Tuning (PEFT) methods have been extensively utilized in Large Language Models (LLMs) to improve the down-streaming tasks without the cost of fine-tuing the whole LLMs. Recent studies have shown how to effectively use PEFT for fine-tuning LLMs in ranking tasks with convincing performance; there are some limitations, including the learned prompt being fixed for different documents, overfitting to specific tasks, and low adaptation ability. In this paper, we introduce a query-dependent parameter efficient fine-tuning (Q-PEFT) approach for text reranking to leak the information of the true queries to LLMs and then make the generation of true queries from input documents much easier. Specifically, we utilize the query to extract the top-$k$ tokens from concatenated documents, serving as contextual clues. We further augment Q-PEFT by substituting the retrieval mechanism with a multi-head attention layer to achieve end-to-end training and cover all the tokens in the documents, guiding the LLMs to generate more document-specific synthetic queries, thereby further improving the reranking performance. Extensive experiments are conducted on four public datasets, demonstrating the effectiveness of our proposed approach.
Do Large Language Models Rank Fairly? An Empirical Study on the Fairness of LLMs as Rankers
Apr 04, 2024The integration of Large Language Models (LLMs) in information retrieval has raised a critical reevaluation of fairness in the text-ranking models. LLMs, such as GPT models and Llama2, have shown effectiveness in natural language understanding tasks, and prior works (e.g., RankGPT) have also demonstrated that the LLMs exhibit better performance than the traditional ranking models in the ranking task. However, their fairness remains largely unexplored. This paper presents an empirical study evaluating these LLMs using the TREC Fair Ranking dataset, focusing on the representation of binary protected attributes such as gender and geographic location, which are historically underrepresented in search outcomes. Our analysis delves into how these LLMs handle queries and documents related to these attributes, aiming to uncover biases in their ranking algorithms. We assess fairness from both user and content perspectives, contributing an empirical benchmark for evaluating LLMs as the fair ranker.
Mathematical Foundation and Corrections for Full Range Head Pose Estimation
Mar 26, 2024
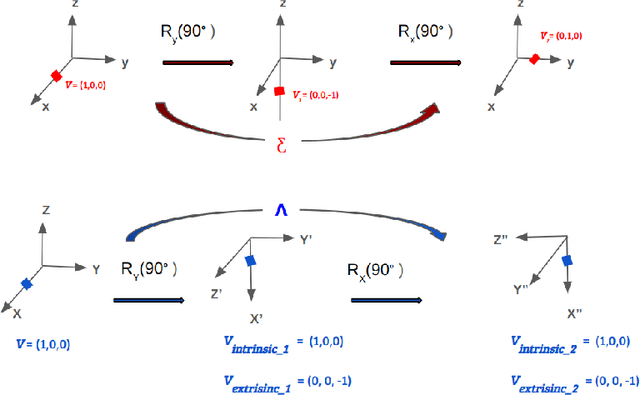
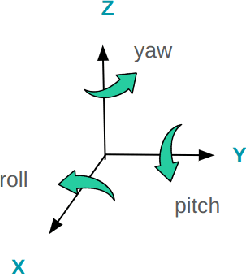
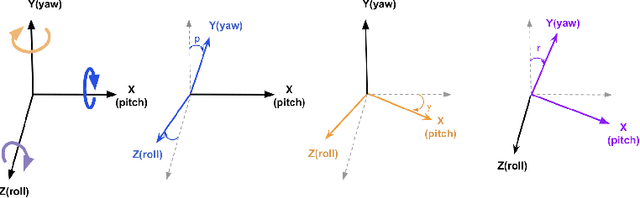
Numerous works concerning head pose estimation (HPE) offer algorithms or proposed neural network-based approaches for extracting Euler angles from either facial key points or directly from images of the head region. However, many works failed to provide clear definitions of the coordinate systems and Euler or Tait-Bryan angles orders in use. It is a well-known fact that rotation matrices depend on coordinate systems, and yaw, roll, and pitch angles are sensitive to their application order. Without precise definitions, it becomes challenging to validate the correctness of the output head pose and drawing routines employed in prior works. In this paper, we thoroughly examined the Euler angles defined in the 300W-LP dataset, head pose estimation such as 3DDFA-v2, 6D-RepNet, WHENet, etc, and the validity of their drawing routines of the Euler angles. When necessary, we infer their coordinate system and sequence of yaw, roll, pitch from provided code. This paper presents (1) code and algorithms for inferring coordinate system from provided source code, code for Euler angle application order and extracting precise rotation matrices and the Euler angles, (2) code and algorithms for converting poses from one rotation system to another, (3) novel formulae for 2D augmentations of the rotation matrices, and (4) derivations and code for the correct drawing routines for rotation matrices and poses. This paper also addresses the feasibility of defining rotations with right-handed coordinate system in Wikipedia and SciPy, which makes the Euler angle extraction much easier for full-range head pose research.
Asynchronous Distributed Optimization with Delay-free Parameters
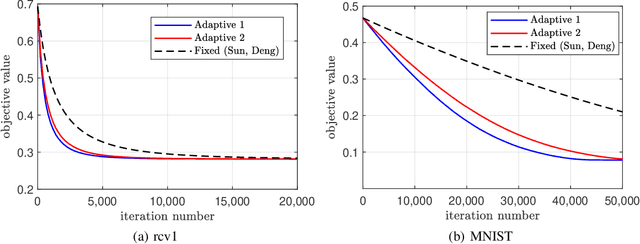
Dec 11, 2023Existing asynchronous distributed optimization algorithms often use diminishing step-sizes that cause slow practical convergence, or use fixed step-sizes that depend on and decrease with an upper bound of the delays. Not only are such delay bounds hard to obtain in advance, but they also tend to be large and rarely attained, resulting in unnecessarily slow convergence. This paper develops asynchronous versions of two distributed algorithms, Prox-DGD and DGD-ATC, for solving consensus optimization problems over undirected networks. In contrast to alternatives, our algorithms can converge to the fixed point set of their synchronous counterparts using step-sizes that are independent of the delays. We establish convergence guarantees for strongly and weakly convex problems under both partial and total asynchrony. We also show that the convergence speed of the two asynchronous methods adapts to the actual level of asynchrony rather than being constrained by the worst-case. Numerical experiments demonstrate a strong practical performance of our asynchronous algorithms.
Soft Prompt Tuning for Augmenting Dense Retrieval with Large Language Models
Jul 25, 2023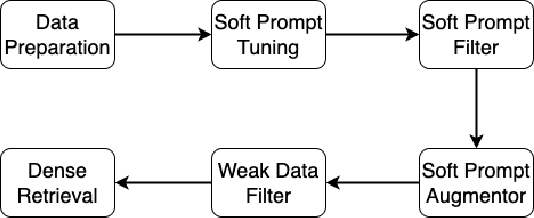

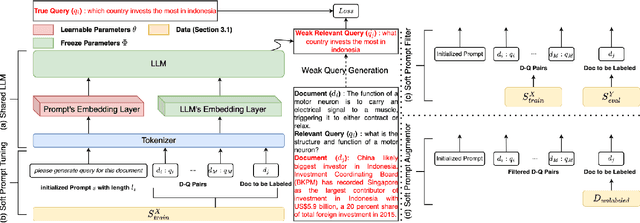

Dense retrieval (DR) converts queries and documents into dense embeddings and measures the similarity between queries and documents in vector space. One of the challenges in DR is the lack of domain-specific training data. While DR models can learn from large-scale public datasets like MS MARCO through transfer learning, evidence shows that not all DR models and domains can benefit from transfer learning equally. Recently, some researchers have resorted to large language models (LLMs) to improve the zero-shot and few-shot DR models. However, the hard prompts or human-written prompts utilized in these works cannot guarantee the good quality of generated weak queries. To tackle this, we propose soft prompt tuning for augmenting DR (SPTAR): For each task, we leverage soft prompt-tuning to optimize a task-specific soft prompt on limited ground truth data and then prompt the LLMs to tag unlabeled documents with weak queries, yielding enough weak document-query pairs to train task-specific dense retrievers. We design a filter to select high-quality example document-query pairs in the prompt to further improve the quality of weak tagged queries. To the best of our knowledge, there is no prior work utilizing soft prompt tuning to augment DR models. The experiments demonstrate that SPTAR outperforms the unsupervised baselines BM25 and the recently proposed LLMs-based augmentation method for DR.
Delay-adaptive step-sizes for asynchronous learning
Feb 27, 2022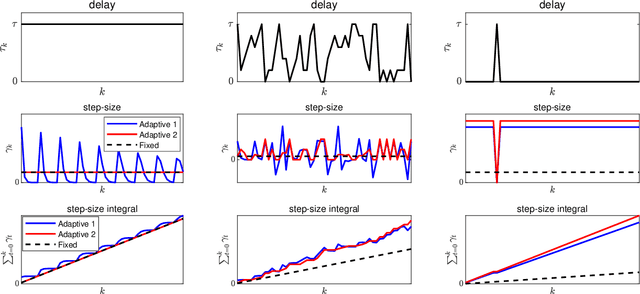

In scalable machine learning systems, model training is often parallelized over multiple nodes that run without tight synchronization. Most analysis results for the related asynchronous algorithms use an upper bound on the information delays in the system to determine learning rates. Not only are such bounds hard to obtain in advance, but they also result in unnecessarily slow convergence. In this paper, we show that it is possible to use learning rates that depend on the actual time-varying delays in the system. We develop general convergence results for delay-adaptive asynchronous iterations and specialize these to proximal incremental gradient descent and block-coordinate descent algorithms. For each of these methods, we demonstrate how delays can be measured on-line, present delay-adaptive step-size policies, and illustrate their theoretical and practical advantages over the state-of-the-art.
A Multi-task Learning Framework for Product Ranking with BERT
Feb 10, 2022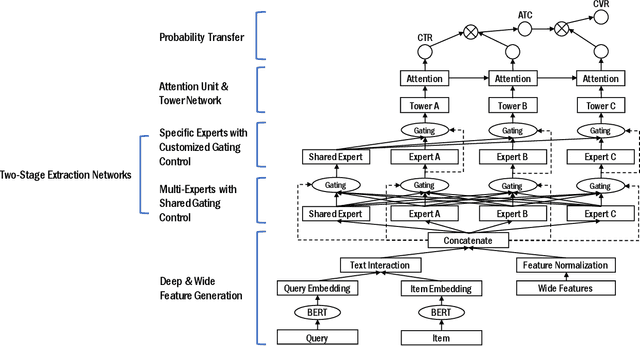

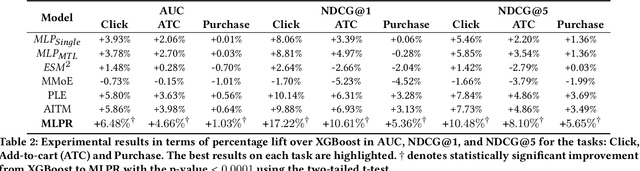
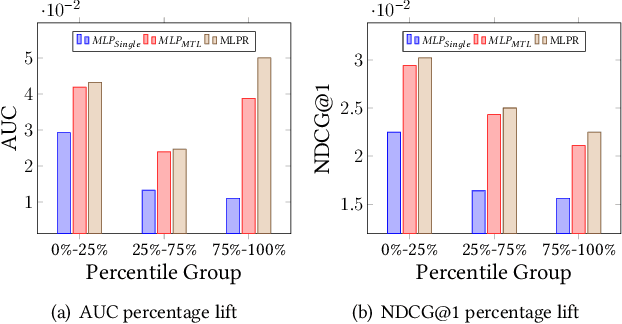
Product ranking is a crucial component for many e-commerce services. One of the major challenges in product search is the vocabulary mismatch between query and products, which may be a larger vocabulary gap problem compared to other information retrieval domains. While there is a growing collection of neural learning to match methods aimed specifically at overcoming this issue, they do not leverage the recent advances of large language models for product search. On the other hand, product ranking often deals with multiple types of engagement signals such as clicks, add-to-cart, and purchases, while most of the existing works are focused on optimizing one single metric such as click-through rate, which may suffer from data sparsity. In this work, we propose a novel end-to-end multi-task learning framework for product ranking with BERT to address the above challenges. The proposed model utilizes domain-specific BERT with fine-tuning to bridge the vocabulary gap and employs multi-task learning to optimize multiple objectives simultaneously, which yields a general end-to-end learning framework for product search. We conduct a set of comprehensive experiments on a real-world e-commerce dataset and demonstrate significant improvement of the proposed approach over the state-of-the-art baseline methods.