 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWanhua Li
Joint-Task Regularization for Partially Labeled Multi-Task Learning
Apr 02, 2024
Multi-task learning has become increasingly popular in the machine learning field, but its practicality is hindered by the need for large, labeled datasets. Most multi-task learning methods depend on fully labeled datasets wherein each input example is accompanied by ground-truth labels for all target tasks. Unfortunately, curating such datasets can be prohibitively expensive and impractical, especially for dense prediction tasks which require per-pixel labels for each image. With this in mind, we propose Joint-Task Regularization (JTR), an intuitive technique which leverages cross-task relations to simultaneously regularize all tasks in a single joint-task latent space to improve learning when data is not fully labeled for all tasks. JTR stands out from existing approaches in that it regularizes all tasks jointly rather than separately in pairs -- therefore, it achieves linear complexity relative to the number of tasks while previous methods scale quadratically. To demonstrate the validity of our approach, we extensively benchmark our method across a wide variety of partially labeled scenarios based on NYU-v2, Cityscapes, and Taskonomy.
$R^2$-Tuning: Efficient Image-to-Video Transfer Learning for Video Temporal Grounding
Mar 31, 2024Video temporal grounding (VTG) is a fine-grained video understanding problem that aims to ground relevant clips in untrimmed videos given natural language queries. Most existing VTG models are built upon frame-wise final-layer CLIP features, aided by additional temporal backbones (e.g., SlowFast) with sophisticated temporal reasoning mechanisms. In this work, we claim that CLIP itself already shows great potential for fine-grained spatial-temporal modeling, as each layer offers distinct yet useful information under different granularity levels. Motivated by this, we propose Reversed Recurrent Tuning ($R^2$-Tuning), a parameter- and memory-efficient transfer learning framework for video temporal grounding. Our method learns a lightweight $R^2$ Block containing only 1.5% of the total parameters to perform progressive spatial-temporal modeling. Starting from the last layer of CLIP, $R^2$ Block recurrently aggregates spatial features from earlier layers, then refines temporal correlation conditioning on the given query, resulting in a coarse-to-fine scheme. $R^2$-Tuning achieves state-of-the-art performance across three VTG tasks (i.e., moment retrieval, highlight detection, and video summarization) on six public benchmarks (i.e., QVHighlights, Charades-STA, Ego4D-NLQ, TACoS, YouTube Highlights, and TVSum) even without the additional backbone, demonstrating the significance and effectiveness of the proposed scheme. Our code is available at https://github.com/yeliudev/R2-Tuning.
TriSAM: Tri-Plane SAM for zero-shot cortical blood vessel segmentation in VEM images
Jan 25, 2024In this paper, we address a significant gap in the field of neuroimaging by introducing the largest-to-date public benchmark, BvEM, designed specifically for cortical blood vessel segmentation in Volume Electron Microscopy (VEM) images. The intricate relationship between cerebral blood vessels and neural function underscores the vital role of vascular analysis in understanding brain health. While imaging techniques at macro and mesoscales have garnered substantial attention and resources, the microscale VEM imaging, capable of revealing intricate vascular details, has lacked the necessary benchmarking infrastructure. As researchers delve deeper into the microscale intricacies of cerebral vasculature, our BvEM benchmark represents a critical step toward unraveling the mysteries of neurovascular coupling and its impact on brain function and pathology. The BvEM dataset is based on VEM image volumes from three mammal species: adult mouse, macaque, and human. We standardized the resolution, addressed imaging variations, and meticulously annotated blood vessels through semi-automatic, manual, and quality control processes, ensuring high-quality 3D segmentation. Furthermore, we developed a zero-shot cortical blood vessel segmentation method named TriSAM, which leverages the powerful segmentation model SAM for 3D segmentation. To lift SAM from 2D segmentation to 3D volume segmentation, TriSAM employs a multi-seed tracking framework, leveraging the reliability of certain image planes for tracking while using others to identify potential turning points. This approach, consisting of Tri-Plane selection, SAM-based tracking, and recursive redirection, effectively achieves long-term 3D blood vessel segmentation without model training or fine-tuning. Experimental results show that TriSAM achieved superior performances on the BvEM benchmark across three species.
LangSplat: 3D Language Gaussian Splatting
Dec 26, 2023Human lives in a 3D world and commonly uses natural language to interact with a 3D scene. Modeling a 3D language field to support open-ended language queries in 3D has gained increasing attention recently. This paper introduces LangSplat, which constructs a 3D language field that enables precise and efficient open-vocabulary querying within 3D spaces. Unlike existing methods that ground CLIP language embeddings in a NeRF model, LangSplat advances the field by utilizing a collection of 3D Gaussians, each encoding language features distilled from CLIP, to represent the language field. By employing a tile-based splatting technique for rendering language features, we circumvent the costly rendering process inherent in NeRF. Instead of directly learning CLIP embeddings, LangSplat first trains a scene-wise language autoencoder and then learns language features on the scene-specific latent space, thereby alleviating substantial memory demands imposed by explicit modeling. Existing methods struggle with imprecise and vague 3D language fields, which fail to discern clear boundaries between objects. We delve into this issue and propose to learn hierarchical semantics using SAM, thereby eliminating the need for extensively querying the language field across various scales and the regularization of DINO features. Extensive experiments on open-vocabulary 3D object localization and semantic segmentation demonstrate that LangSplat significantly outperforms the previous state-of-the-art method LERF by a large margin. Notably, LangSplat is extremely efficient, achieving a {\speed} $\times$ speedup compared to LERF at the resolution of 1440 $\times$ 1080. We strongly recommend readers to check out our video results at https://langsplat.github.io
CLIPTrans: Transferring Visual Knowledge with Pre-trained Models for Multimodal Machine Translation
Aug 29, 2023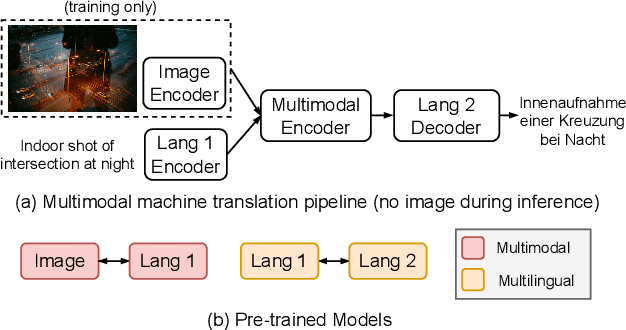
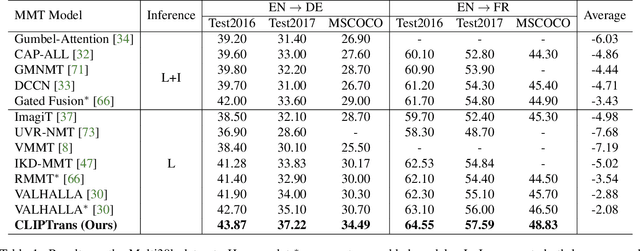
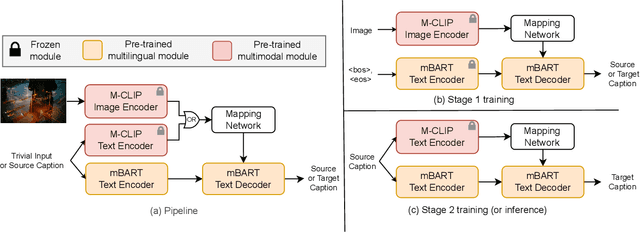
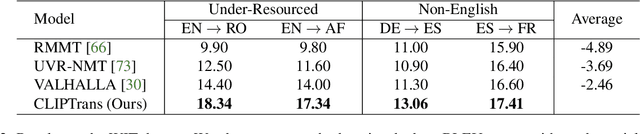
There has been a growing interest in developing multimodal machine translation (MMT) systems that enhance neural machine translation (NMT) with visual knowledge. This problem setup involves using images as auxiliary information during training, and more recently, eliminating their use during inference. Towards this end, previous works face a challenge in training powerful MMT models from scratch due to the scarcity of annotated multilingual vision-language data, especially for low-resource languages. Simultaneously, there has been an influx of multilingual pre-trained models for NMT and multimodal pre-trained models for vision-language tasks, primarily in English, which have shown exceptional generalisation ability. However, these are not directly applicable to MMT since they do not provide aligned multimodal multilingual features for generative tasks. To alleviate this issue, instead of designing complex modules for MMT, we propose CLIPTrans, which simply adapts the independently pre-trained multimodal M-CLIP and the multilingual mBART. In order to align their embedding spaces, mBART is conditioned on the M-CLIP features by a prefix sequence generated through a lightweight mapping network. We train this in a two-stage pipeline which warms up the model with image captioning before the actual translation task. Through experiments, we demonstrate the merits of this framework and consequently push forward the state-of-the-art across standard benchmarks by an average of +2.67 BLEU. The code can be found at www.github.com/devaansh100/CLIPTrans.
DiffTalk: Crafting Diffusion Models for Generalized Talking Head Synthesis
Jan 10, 2023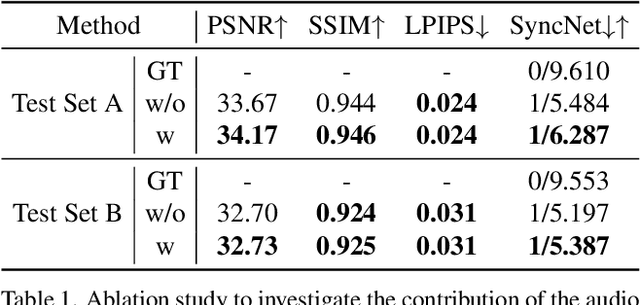
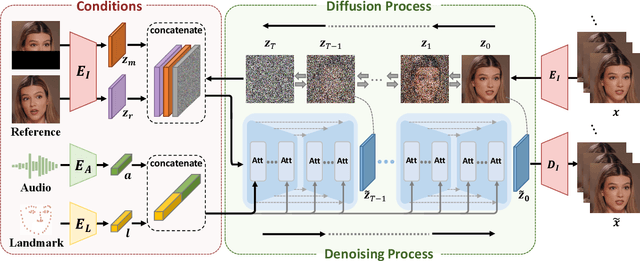
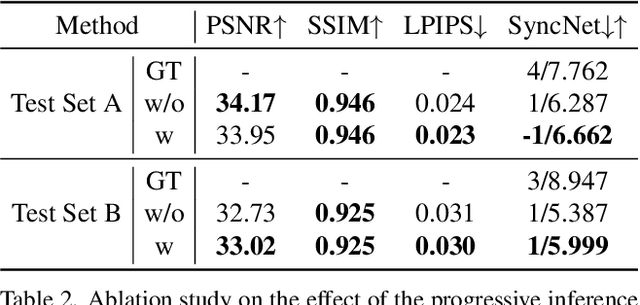
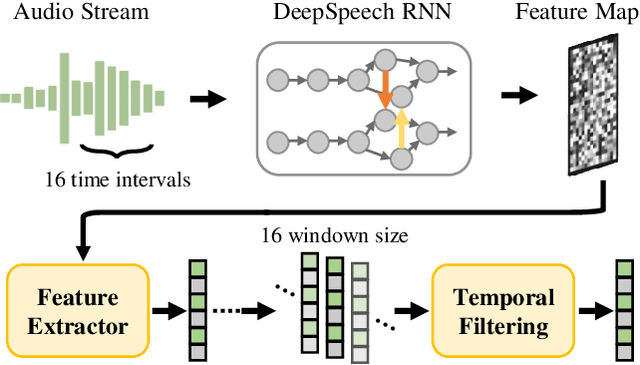
Talking head synthesis is a promising approach for the video production industry. Recently, a lot of effort has been devoted in this research area to improve the generation quality or enhance the model generalization. However, there are few works able to address both issues simultaneously, which is essential for practical applications. To this end, in this paper, we turn attention to the emerging powerful Latent Diffusion Models, and model the Talking head generation as an audio-driven temporally coherent denoising process (DiffTalk). More specifically, instead of employing audio signals as the single driving factor, we investigate the control mechanism of the talking face, and incorporate reference face images and landmarks as conditions for personality-aware generalized synthesis. In this way, the proposed DiffTalk is capable of producing high-quality talking head videos in synchronization with the source audio, and more importantly, it can be naturally generalized across different identities without any further fine-tuning. Additionally, our DiffTalk can be gracefully tailored for higher-resolution synthesis with negligible extra computational cost. Extensive experiments show that the proposed DiffTalk efficiently synthesizes high-fidelity audio-driven talking head videos for generalized novel identities. For more video results, please refer to this demonstration \url{https://cloud.tsinghua.edu.cn/f/e13f5aad2f4c4f898ae7/}.
Learning Dynamic Facial Radiance Fields for Few-Shot Talking Head Synthesis
Jul 24, 2022

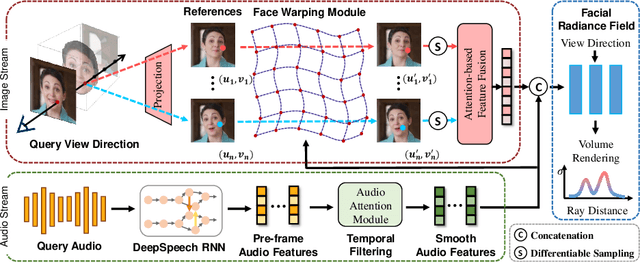
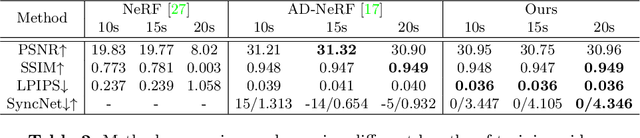
Talking head synthesis is an emerging technology with wide applications in film dubbing, virtual avatars and online education. Recent NeRF-based methods generate more natural talking videos, as they better capture the 3D structural information of faces. However, a specific model needs to be trained for each identity with a large dataset. In this paper, we propose Dynamic Facial Radiance Fields (DFRF) for few-shot talking head synthesis, which can rapidly generalize to an unseen identity with few training data. Different from the existing NeRF-based methods which directly encode the 3D geometry and appearance of a specific person into the network, our DFRF conditions face radiance field on 2D appearance images to learn the face prior. Thus the facial radiance field can be flexibly adjusted to the new identity with few reference images. Additionally, for better modeling of the facial deformations, we propose a differentiable face warping module conditioned on audio signals to deform all reference images to the query space. Extensive experiments show that with only tens of seconds of training clip available, our proposed DFRF can synthesize natural and high-quality audio-driven talking head videos for novel identities with only 40k iterations. We highly recommend readers view our supplementary video for intuitive comparisons. Code is available in https://sstzal.github.io/DFRF/.
Label2Label: A Language Modeling Framework for Multi-Attribute Learning
Jul 18, 2022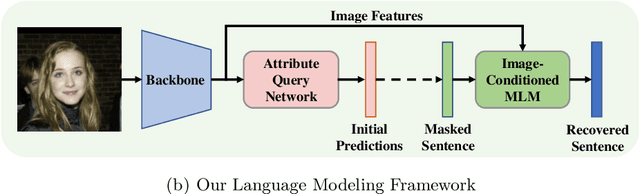

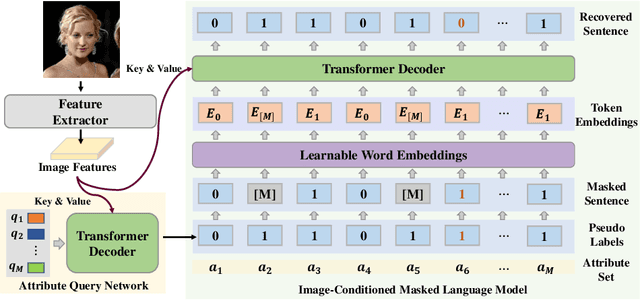
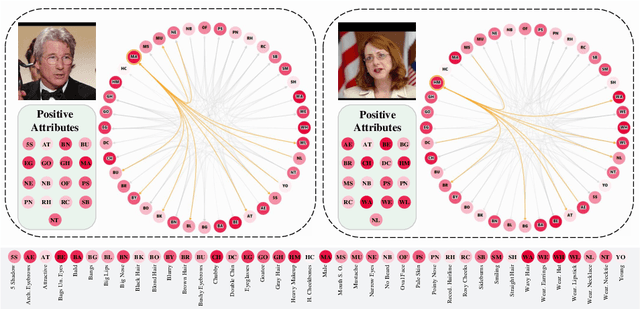
Objects are usually associated with multiple attributes, and these attributes often exhibit high correlations. Modeling complex relationships between attributes poses a great challenge for multi-attribute learning. This paper proposes a simple yet generic framework named Label2Label to exploit the complex attribute correlations. Label2Label is the first attempt for multi-attribute prediction from the perspective of language modeling. Specifically, it treats each attribute label as a "word" describing the sample. As each sample is annotated with multiple attribute labels, these "words" will naturally form an unordered but meaningful "sentence", which depicts the semantic information of the corresponding sample. Inspired by the remarkable success of pre-training language models in NLP, Label2Label introduces an image-conditioned masked language model, which randomly masks some of the "word" tokens from the label "sentence" and aims to recover them based on the masked "sentence" and the context conveyed by image features. Our intuition is that the instance-wise attribute relations are well grasped if the neural net can infer the missing attributes based on the context and the remaining attribute hints. Label2Label is conceptually simple and empirically powerful. Without incorporating task-specific prior knowledge and highly specialized network designs, our approach achieves state-of-the-art results on three different multi-attribute learning tasks, compared to highly customized domain-specific methods. Code is available at https://github.com/Li-Wanhua/Label2Label.
MetaAge: Meta-Learning Personalized Age Estimators
Jul 12, 2022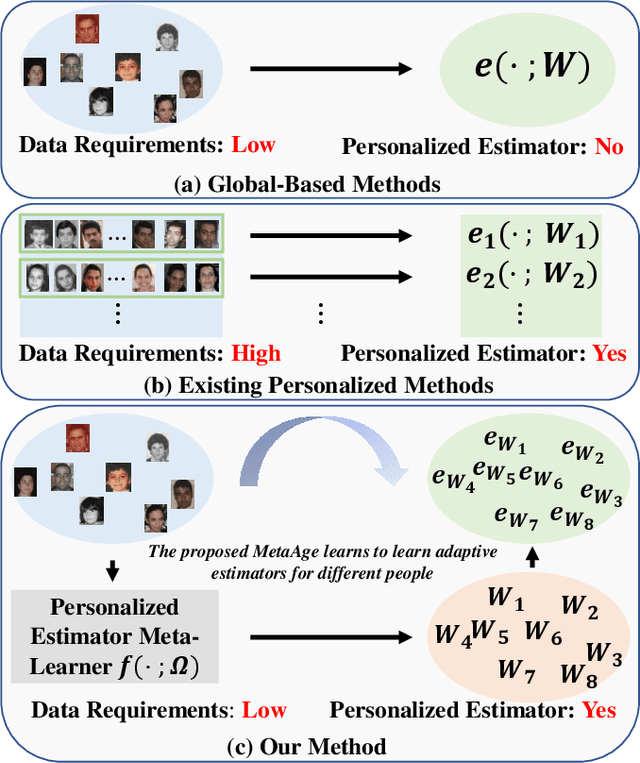
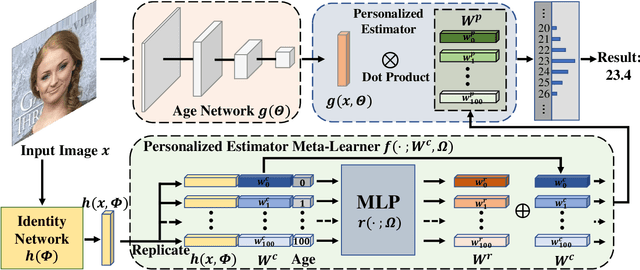
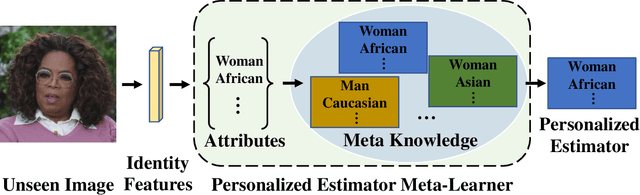
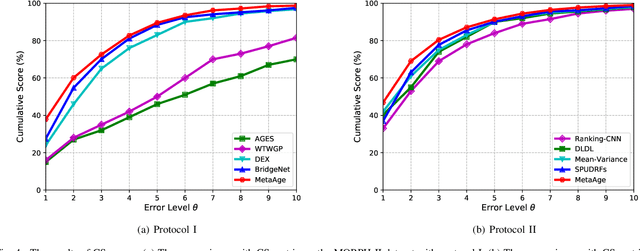
Different people age in different ways. Learning a personalized age estimator for each person is a promising direction for age estimation given that it better models the personalization of aging processes. However, most existing personalized methods suffer from the lack of large-scale datasets due to the high-level requirements: identity labels and enough samples for each person to form a long-term aging pattern. In this paper, we aim to learn personalized age estimators without the above requirements and propose a meta-learning method named MetaAge for age estimation. Unlike most existing personalized methods that learn the parameters of a personalized estimator for each person in the training set, our method learns the mapping from identity information to age estimator parameters. Specifically, we introduce a personalized estimator meta-learner, which takes identity features as the input and outputs the parameters of customized estimators. In this way, our method learns the meta knowledge without the above requirements and seamlessly transfers the learned meta knowledge to the test set, which enables us to leverage the existing large-scale age datasets without any additional annotations. Extensive experimental results on three benchmark datasets including MORPH II, ChaLearn LAP 2015 and ChaLearn LAP 2016 databases demonstrate that our MetaAge significantly boosts the performance of existing personalized methods and outperforms the state-of-the-art approaches.
OrdinalCLIP: Learning Rank Prompts for Language-Guided Ordinal Regression
Jun 06, 2022
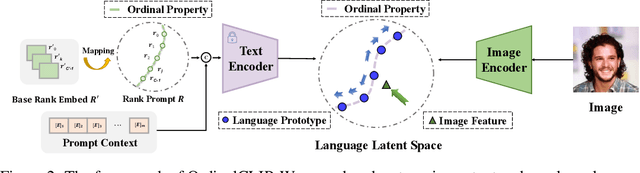
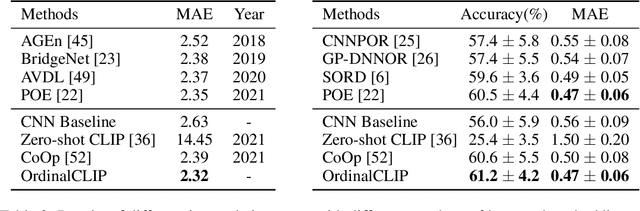
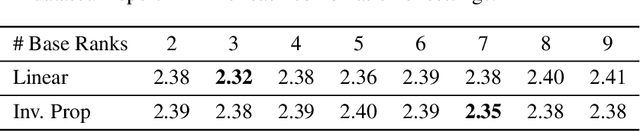
This paper presents a language-powered paradigm for ordinal regression. Existing methods usually treat each rank as a category and employ a set of weights to learn these concepts. These methods are easy to overfit and usually attain unsatisfactory performance as the learned concepts are mainly derived from the training set. Recent large pre-trained vision-language models like CLIP have shown impressive performance on various visual tasks. In this paper, we propose to learn the rank concepts from the rich semantic CLIP latent space. Specifically, we reformulate this task as an image-language matching problem with a contrastive objective, which regards labels as text and obtains a language prototype from a text encoder for each rank. While prompt engineering for CLIP is extremely time-consuming, we propose OrdinalCLIP, a differentiable prompting method for adapting CLIP for ordinal regression. OrdinalCLIP consists of learnable context tokens and learnable rank embeddings; The learnable rank embeddings are constructed by explicitly modeling numerical continuity, resulting in well-ordered, compact language prototypes in the CLIP space. Once learned, we can only save the language prototypes and discard the huge language model, resulting in zero additional computational overhead compared with the linear head counterpart. Experimental results show that our paradigm achieves competitive performance in general ordinal regression tasks, and gains improvements in few-shot and distribution shift settings for age estimation.