 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenliang Zhao
DPMesh: Exploiting Diffusion Prior for Occluded Human Mesh Recovery
Apr 01, 2024
The recovery of occluded human meshes presents challenges for current methods due to the difficulty in extracting effective image features under severe occlusion. In this paper, we introduce DPMesh, an innovative framework for occluded human mesh recovery that capitalizes on the profound diffusion prior about object structure and spatial relationships embedded in a pre-trained text-to-image diffusion model. Unlike previous methods reliant on conventional backbones for vanilla feature extraction, DPMesh seamlessly integrates the pre-trained denoising U-Net with potent knowledge as its image backbone and performs a single-step inference to provide occlusion-aware information. To enhance the perception capability for occluded poses, DPMesh incorporates well-designed guidance via condition injection, which produces effective controls from 2D observations for the denoising U-Net. Furthermore, we explore a dedicated noisy key-point reasoning approach to mitigate disturbances arising from occlusion and crowded scenarios. This strategy fully unleashes the perceptual capability of the diffusion prior, thereby enhancing accuracy. Extensive experiments affirm the efficacy of our framework, as we outperform state-of-the-art methods on both occlusion-specific and standard datasets. The persuasive results underscore its ability to achieve precise and robust 3D human mesh recovery, particularly in challenging scenarios involving occlusion and crowded scenes.
MaskINT: Video Editing via Interpolative Non-autoregressive Masked Transformers
Dec 19, 2023Recent advances in generative AI have significantly enhanced image and video editing, particularly in the context of text prompt control. State-of-the-art approaches predominantly rely on diffusion models to accomplish these tasks. However, the computational demands of diffusion-based methods are substantial, often necessitating large-scale paired datasets for training, and therefore challenging the deployment in practical applications. This study addresses this challenge by breaking down the text-based video editing process into two separate stages. In the first stage, we leverage an existing text-to-image diffusion model to simultaneously edit a few keyframes without additional fine-tuning. In the second stage, we introduce an efficient model called MaskINT, which is built on non-autoregressive masked generative transformers and specializes in frame interpolation between the keyframes, benefiting from structural guidance provided by intermediate frames. Our comprehensive set of experiments illustrates the efficacy and efficiency of MaskINT when compared to other diffusion-based methodologies. This research offers a practical solution for text-based video editing and showcases the potential of non-autoregressive masked generative transformers in this domain.
OpenVoice: Versatile Instant Voice Cloning
Dec 03, 2023We introduce OpenVoice, a versatile voice cloning approach that requires only a short audio clip from the reference speaker to replicate their voice and generate speech in multiple languages. OpenVoice represents a significant advancement in addressing the following open challenges in the field: 1) Flexible Voice Style Control. OpenVoice enables granular control over voice styles, including emotion, accent, rhythm, pauses, and intonation, in addition to replicating the tone color of the reference speaker. The voice styles are not directly copied from and constrained by the style of the reference speaker. Previous approaches lacked the ability to flexibly manipulate voice styles after cloning. 2) Zero-Shot Cross-Lingual Voice Cloning. OpenVoice achieves zero-shot cross-lingual voice cloning for languages not included in the massive-speaker training set. Unlike previous approaches, which typically require extensive massive-speaker multi-lingual (MSML) dataset for all languages, OpenVoice can clone voices into a new language without any massive-speaker training data for that language. OpenVoice is also computationally efficient, costing tens of times less than commercially available APIs that offer even inferior performance. To foster further research in the field, we have made the source code and trained model publicly accessible. We also provide qualitative results in our demo website. Prior to its public release, our internal version of OpenVoice was used tens of millions of times by users worldwide between May and October 2023, serving as the backend of MyShell.ai.
Unleashing Text-to-Image Diffusion Models for Visual Perception
Mar 03, 2023

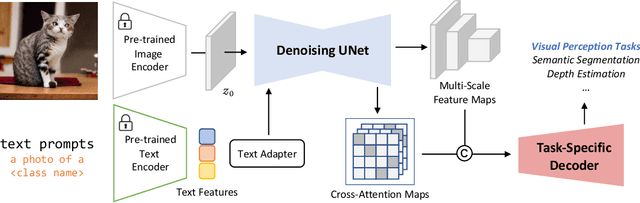
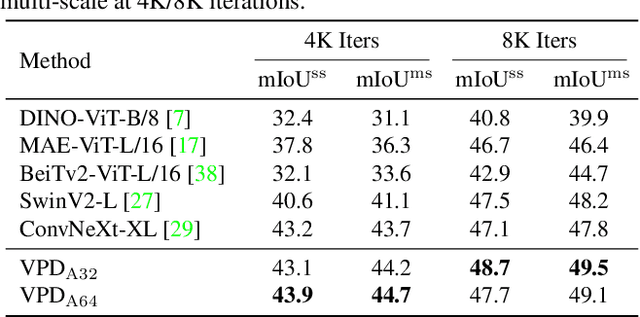
Diffusion models (DMs) have become the new trend of generative models and have demonstrated a powerful ability of conditional synthesis. Among those, text-to-image diffusion models pre-trained on large-scale image-text pairs are highly controllable by customizable prompts. Unlike the unconditional generative models that focus on low-level attributes and details, text-to-image diffusion models contain more high-level knowledge thanks to the vision-language pre-training. In this paper, we propose VPD (Visual Perception with a pre-trained Diffusion model), a new framework that exploits the semantic information of a pre-trained text-to-image diffusion model in visual perception tasks. Instead of using the pre-trained denoising autoencoder in a diffusion-based pipeline, we simply use it as a backbone and aim to study how to take full advantage of the learned knowledge. Specifically, we prompt the denoising decoder with proper textual inputs and refine the text features with an adapter, leading to a better alignment to the pre-trained stage and making the visual contents interact with the text prompts. We also propose to utilize the cross-attention maps between the visual features and the text features to provide explicit guidance. Compared with other pre-training methods, we show that vision-language pre-trained diffusion models can be faster adapted to downstream visual perception tasks using the proposed VPD. Extensive experiments on semantic segmentation, referring image segmentation and depth estimation demonstrates the effectiveness of our method. Notably, VPD attains 0.254 RMSE on NYUv2 depth estimation and 73.3% oIoU on RefCOCO-val referring image segmentation, establishing new records on these two benchmarks. Code is available at https://github.com/wl-zhao/VPD
UniPC: A Unified Predictor-Corrector Framework for Fast Sampling of Diffusion Models
Feb 12, 2023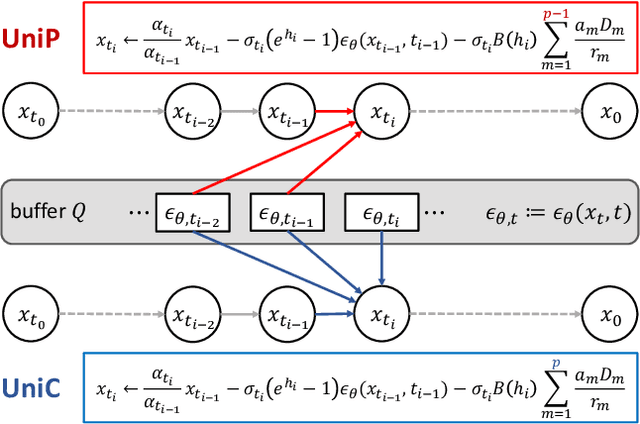


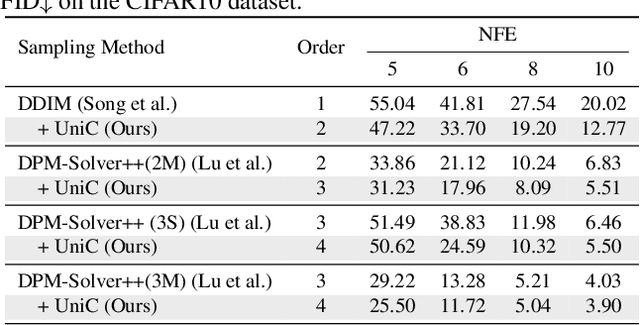
Diffusion probabilistic models (DPMs) have demonstrated a very promising ability in high-resolution image synthesis. However, sampling from a pre-trained DPM usually requires hundreds of model evaluations, which is computationally expensive. Despite recent progress in designing high-order solvers for DPMs, there still exists room for further speedup, especially in extremely few steps (e.g., 5~10 steps). Inspired by the predictor-corrector for ODE solvers, we develop a unified corrector (UniC) that can be applied after any existing DPM sampler to increase the order of accuracy without extra model evaluations, and derive a unified predictor (UniP) that supports arbitrary order as a byproduct. Combining UniP and UniC, we propose a unified predictor-corrector framework called UniPC for the fast sampling of DPMs, which has a unified analytical form for any order and can significantly improve the sampling quality over previous methods. We evaluate our methods through extensive experiments including both unconditional and conditional sampling using pixel-space and latent-space DPMs. Our UniPC can achieve 3.87 FID on CIFAR10 (unconditional) and 7.51 FID on ImageNet 256$\times$256 (conditional) with only 10 function evaluations. Code is available at https://github.com/wl-zhao/UniPC
DiffTalk: Crafting Diffusion Models for Generalized Talking Head Synthesis
Jan 10, 2023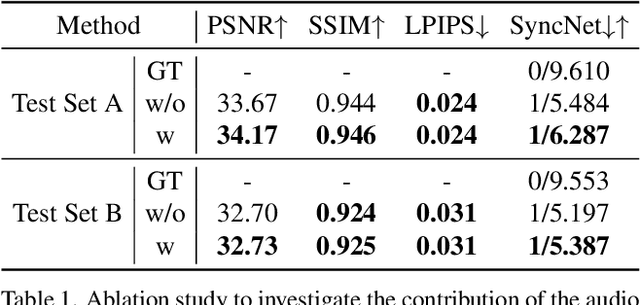
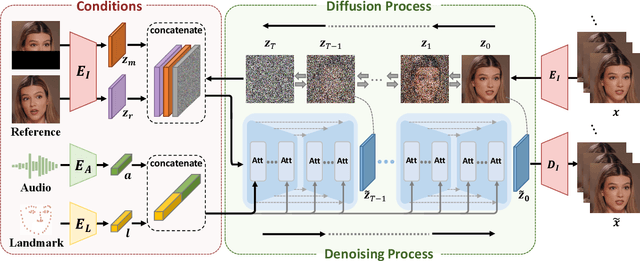
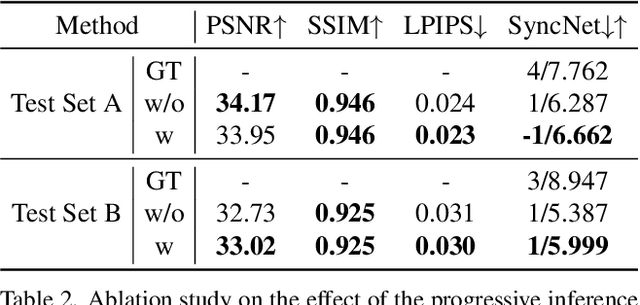
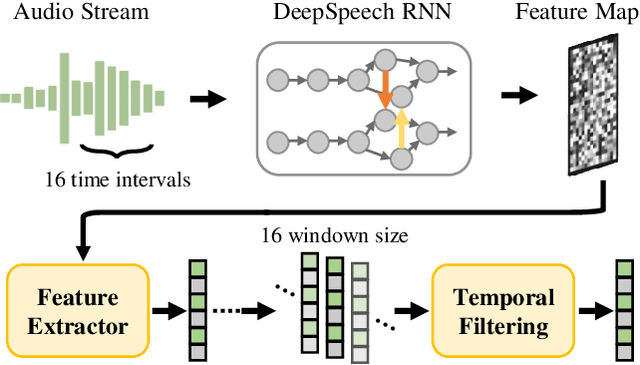
Talking head synthesis is a promising approach for the video production industry. Recently, a lot of effort has been devoted in this research area to improve the generation quality or enhance the model generalization. However, there are few works able to address both issues simultaneously, which is essential for practical applications. To this end, in this paper, we turn attention to the emerging powerful Latent Diffusion Models, and model the Talking head generation as an audio-driven temporally coherent denoising process (DiffTalk). More specifically, instead of employing audio signals as the single driving factor, we investigate the control mechanism of the talking face, and incorporate reference face images and landmarks as conditions for personality-aware generalized synthesis. In this way, the proposed DiffTalk is capable of producing high-quality talking head videos in synchronization with the source audio, and more importantly, it can be naturally generalized across different identities without any further fine-tuning. Additionally, our DiffTalk can be gracefully tailored for higher-resolution synthesis with negligible extra computational cost. Extensive experiments show that the proposed DiffTalk efficiently synthesizes high-fidelity audio-driven talking head videos for generalized novel identities. For more video results, please refer to this demonstration \url{https://cloud.tsinghua.edu.cn/f/e13f5aad2f4c4f898ae7/}.
HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions
Aug 09, 2022



Recent progress in vision Transformers exhibits great success in various tasks driven by the new spatial modeling mechanism based on dot-product self-attention. In this paper, we show that the key ingredients behind the vision Transformers, namely input-adaptive, long-range and high-order spatial interactions, can also be efficiently implemented with a convolution-based framework. We present the Recursive Gated Convolution ($\textit{g}^\textit{n}$Conv) that performs high-order spatial interactions with gated convolutions and recursive designs. The new operation is highly flexible and customizable, which is compatible with various variants of convolution and extends the two-order interactions in self-attention to arbitrary orders without introducing significant extra computation. $\textit{g}^\textit{n}$Conv can serve as a plug-and-play module to improve various vision Transformers and convolution-based models. Based on the operation, we construct a new family of generic vision backbones named HorNet. Extensive experiments on ImageNet classification, COCO object detection and ADE20K semantic segmentation show HorNet outperform Swin Transformers and ConvNeXt by a significant margin with similar overall architecture and training configurations. HorNet also shows favorable scalability to more training data and a larger model size. Apart from the effectiveness in visual encoders, we also show $\textit{g}^\textit{n}$Conv can be applied to task-specific decoders and consistently improve dense prediction performance with less computation. Our results demonstrate that $\textit{g}^\textit{n}$Conv can be a new basic module for visual modeling that effectively combines the merits of both vision Transformers and CNNs. Code is available at https://github.com/raoyongming/HorNet
Dynamic Spatial Sparsification for Efficient Vision Transformers and Convolutional Neural Networks
Jul 04, 2022


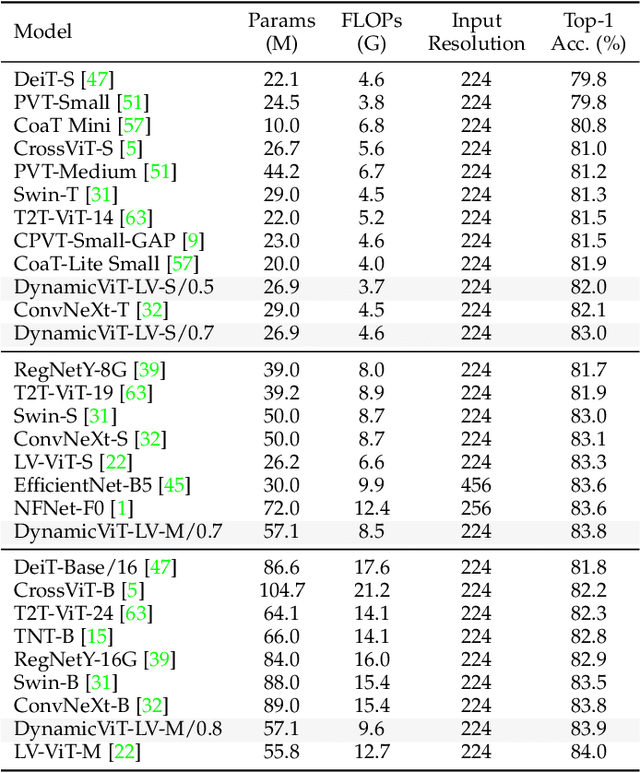
In this paper, we present a new approach for model acceleration by exploiting spatial sparsity in visual data. We observe that the final prediction in vision Transformers is only based on a subset of the most informative tokens, which is sufficient for accurate image recognition. Based on this observation, we propose a dynamic token sparsification framework to prune redundant tokens progressively and dynamically based on the input to accelerate vision Transformers. Specifically, we devise a lightweight prediction module to estimate the importance score of each token given the current features. The module is added to different layers to prune redundant tokens hierarchically. While the framework is inspired by our observation of the sparse attention in vision Transformers, we find the idea of adaptive and asymmetric computation can be a general solution for accelerating various architectures. We extend our method to hierarchical models including CNNs and hierarchical vision Transformers as well as more complex dense prediction tasks that require structured feature maps by formulating a more generic dynamic spatial sparsification framework with progressive sparsification and asymmetric computation for different spatial locations. By applying lightweight fast paths to less informative features and using more expressive slow paths to more important locations, we can maintain the structure of feature maps while significantly reducing the overall computations. Extensive experiments demonstrate the effectiveness of our framework on various modern architectures and different visual recognition tasks. Our results clearly demonstrate that dynamic spatial sparsification offers a new and more effective dimension for model acceleration. Code is available at https://github.com/raoyongming/DynamicViT
A Roadmap for Big Model
Apr 02, 2022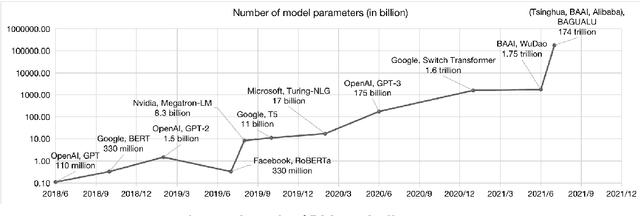
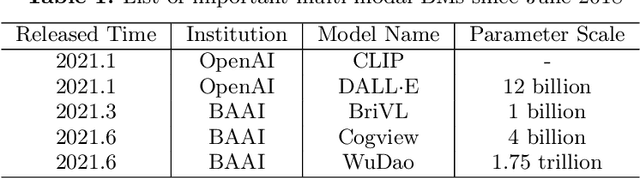
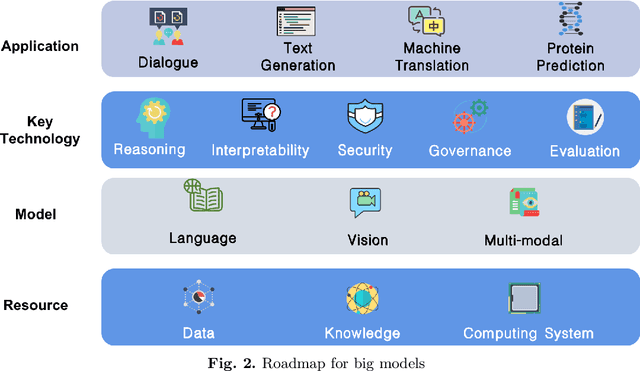
With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
Dec 02, 2021
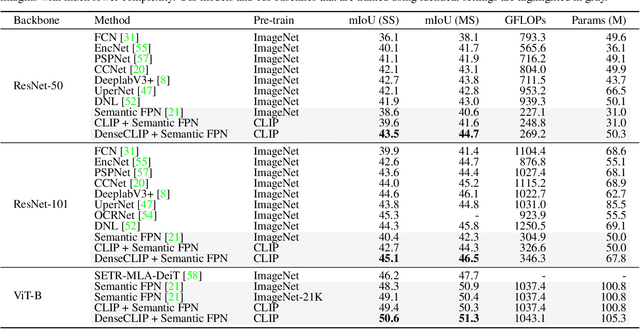


Recent progress has shown that large-scale pre-training using contrastive image-text pairs can be a promising alternative for high-quality visual representation learning from natural language supervision. Benefiting from a broader source of supervision, this new paradigm exhibits impressive transferability to downstream classification tasks and datasets. However, the problem of transferring the knowledge learned from image-text pairs to more complex dense prediction tasks has barely been visited. In this work, we present a new framework for dense prediction by implicitly and explicitly leveraging the pre-trained knowledge from CLIP. Specifically, we convert the original image-text matching problem in CLIP to a pixel-text matching problem and use the pixel-text score maps to guide the learning of dense prediction models. By further using the contextual information from the image to prompt the language model, we are able to facilitate our model to better exploit the pre-trained knowledge. Our method is model-agnostic, which can be applied to arbitrary dense prediction systems and various pre-trained visual backbones including both CLIP models and ImageNet pre-trained models. Extensive experiments demonstrate the superior performance of our methods on semantic segmentation, object detection, and instance segmentation tasks. Code is available at https://github.com/raoyongming/DenseCLIP