 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChaojun Xiao
The Elephant in the Room: Rethinking the Usage of Pre-trained Language Model in Sequential Recommendation
Apr 12, 2024
Sequential recommendation (SR) has seen significant advancements with the help of Pre-trained Language Models (PLMs). Some PLM-based SR models directly use PLM to encode user historical behavior's text sequences to learn user representations, while there is seldom an in-depth exploration of the capability and suitability of PLM in behavior sequence modeling. In this work, we first conduct extensive model analyses between PLMs and PLM-based SR models, discovering great underutilization and parameter redundancy of PLMs in behavior sequence modeling. Inspired by this, we explore different lightweight usages of PLMs in SR, aiming to maximally stimulate the ability of PLMs for SR while satisfying the efficiency and usability demands of practical systems. We discover that adopting behavior-tuned PLMs for item initializations of conventional ID-based SR models is the most economical framework of PLM-based SR, which would not bring in any additional inference cost but could achieve a dramatic performance boost compared with the original version. Extensive experiments on five datasets show that our simple and universal framework leads to significant improvement compared to classical SR and SOTA PLM-based SR models without additional inference costs.
Robust and Scalable Model Editing for Large Language Models
Mar 26, 2024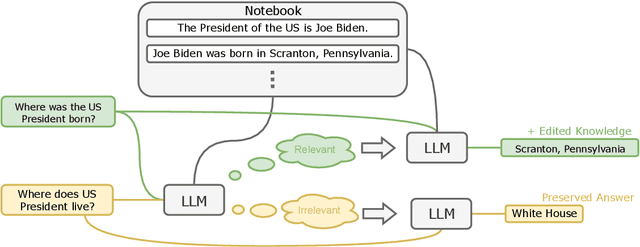



Large language models (LLMs) can make predictions using parametric knowledge--knowledge encoded in the model weights--or contextual knowledge--knowledge presented in the context. In many scenarios, a desirable behavior is that LLMs give precedence to contextual knowledge when it conflicts with the parametric knowledge, and fall back to using their parametric knowledge when the context is irrelevant. This enables updating and correcting the model's knowledge by in-context editing instead of retraining. Previous works have shown that LLMs are inclined to ignore contextual knowledge and fail to reliably fall back to parametric knowledge when presented with irrelevant context. In this work, we discover that, with proper prompting methods, instruction-finetuned LLMs can be highly controllable by contextual knowledge and robust to irrelevant context. Utilizing this feature, we propose EREN (Edit models by REading Notes) to improve the scalability and robustness of LLM editing. To better evaluate the robustness of model editors, we collect a new dataset, that contains irrelevant questions that are more challenging than the ones in existing datasets. Empirical results show that our method outperforms current state-of-the-art methods by a large margin. Unlike existing techniques, it can integrate knowledge from multiple edits, and correctly respond to syntactically similar but semantically unrelated inputs (and vice versa). The source code can be found at https://github.com/thunlp/EREN.
Ouroboros: Speculative Decoding with Large Model Enhanced Drafting
Feb 21, 2024Drafting-then-verifying decoding methods such as speculative decoding are widely adopted training-free methods to accelerate the inference of large language models (LLMs). Instead of employing an autoregressive process to decode tokens sequentially, speculative decoding initially creates drafts with an efficient small model. Then LLMs are required to conduct verification and correction in a non-autoregressive fashion to minimize time overhead. Generating longer drafts can lead to even more significant speedups once verified, but also incurs substantial trial and error costs if it fails. Suffering from the high verification failure probability, existing decoding methods cannot draft too much content for verification at one time, achieving sub-optimal inference acceleration. In this paper, we introduce Ouroboros, which constructs a phrase candidate pool from the verification process of LLMs to provide candidates for draft generation of the small model. Thereby, Ouroboros can further improve the efficiency and effectiveness of the initial drafts. The experimental results on typical text generation tasks show that Ouroboros achieves speedups of up to 1.9x and 2.8x compared to lookahead decoding and speculative decoding, respectively. The source code of Ouroboros is available at https://github.com/thunlp/Ouroboros.
InfLLM: Unveiling the Intrinsic Capacity of LLMs for Understanding Extremely Long Sequences with Training-Free Memory
Feb 07, 2024Large language models (LLMs) have emerged as a cornerstone in real-world applications with lengthy streaming inputs, such as LLM-driven agents. However, existing LLMs, pre-trained on sequences with restricted maximum length, cannot generalize to longer sequences due to the out-of-domain and distraction issues. To alleviate these issues, existing efforts employ sliding attention windows and discard distant tokens to achieve the processing of extremely long sequences. Unfortunately, these approaches inevitably fail to capture long-distance dependencies within sequences to deeply understand semantics. This paper introduces a training-free memory-based method, InfLLM, to unveil the intrinsic ability of LLMs to process streaming long sequences. Specifically, InfLLM stores distant contexts into additional memory units and employs an efficient mechanism to lookup token-relevant units for attention computation. Thereby, InfLLM allows LLMs to efficiently process long sequences while maintaining the ability to capture long-distance dependencies. Without any training, InfLLM enables LLMs pre-trained on sequences of a few thousand tokens to achieve superior performance than competitive baselines continually training these LLMs on long sequences. Even when the sequence length is scaled to $1,024$K, InfLLM still effectively captures long-distance dependencies.
ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs
Feb 06, 2024Sparse computation offers a compelling solution for the inference of Large Language Models (LLMs) in low-resource scenarios by dynamically skipping the computation of inactive neurons. While traditional approaches focus on ReLU-based LLMs, leveraging zeros in activation values, we broaden the scope of sparse LLMs beyond zero activation values. We introduce a general method that defines neuron activation through neuron output magnitudes and a tailored magnitude threshold, demonstrating that non-ReLU LLMs also exhibit sparse activation. To find the most efficient activation function for sparse computation, we propose a systematic framework to examine the sparsity of LLMs from three aspects: the trade-off between sparsity and performance, the predictivity of sparsity, and the hardware affinity. We conduct thorough experiments on LLMs utilizing different activation functions, including ReLU, SwiGLU, ReGLU, and ReLU$^2$. The results indicate that models employing ReLU$^2$ excel across all three evaluation aspects, highlighting its potential as an efficient activation function for sparse LLMs. We will release the code to facilitate future research.
MUSER: A Multi-View Similar Case Retrieval Dataset
Oct 24, 2023
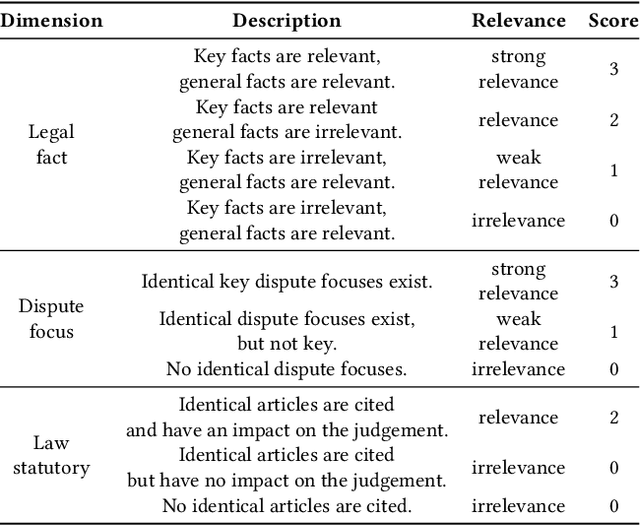

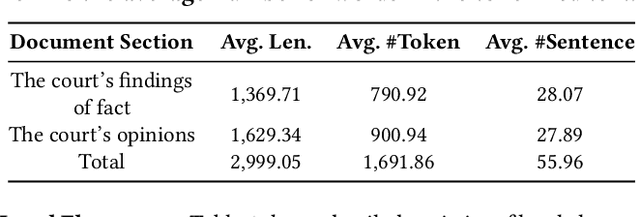
Similar case retrieval (SCR) is a representative legal AI application that plays a pivotal role in promoting judicial fairness. However, existing SCR datasets only focus on the fact description section when judging the similarity between cases, ignoring other valuable sections (e.g., the court's opinion) that can provide insightful reasoning process behind. Furthermore, the case similarities are typically measured solely by the textual semantics of the fact descriptions, which may fail to capture the full complexity of legal cases from the perspective of legal knowledge. In this work, we present MUSER, a similar case retrieval dataset based on multi-view similarity measurement and comprehensive legal element with sentence-level legal element annotations. Specifically, we select three perspectives (legal fact, dispute focus, and law statutory) and build a comprehensive and structured label schema of legal elements for each of them, to enable accurate and knowledgeable evaluation of case similarities. The constructed dataset originates from Chinese civil cases and contains 100 query cases and 4,024 candidate cases. We implement several text classification algorithms for legal element prediction and various retrieval methods for retrieving similar cases on MUSER. The experimental results indicate that incorporating legal elements can benefit the performance of SCR models, but further efforts are still required to address the remaining challenges posed by MUSER. The source code and dataset are released at https://github.com/THUlawtech/MUSER.
* Accepted by CIKM 2023 Resource Track
Variator: Accelerating Pre-trained Models with Plug-and-Play Compression Modules
Oct 24, 2023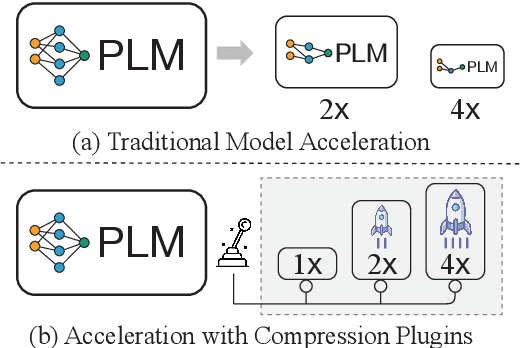
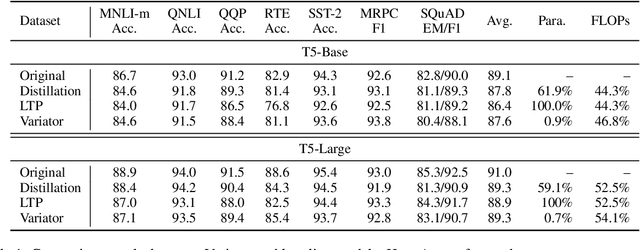
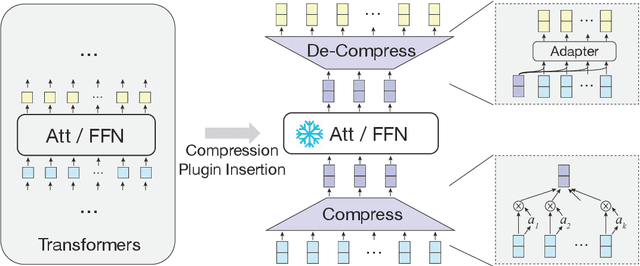
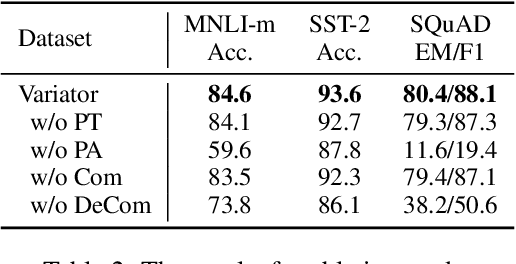
Pre-trained language models (PLMs) have achieved remarkable results on NLP tasks but at the expense of huge parameter sizes and the consequent computational costs. In this paper, we propose Variator, a parameter-efficient acceleration method that enhances computational efficiency through plug-and-play compression plugins. Compression plugins are designed to reduce the sequence length via compressing multiple hidden vectors into one and trained with original PLMs frozen. Different from traditional model acceleration methods, which compress PLMs to smaller sizes, Variator offers two distinct advantages: (1) In real-world applications, the plug-and-play nature of our compression plugins enables dynamic selection of different compression plugins with varying acceleration ratios based on the current workload. (2) The compression plugin comprises a few compact neural network layers with minimal parameters, significantly saving storage and memory overhead, particularly in scenarios with a growing number of tasks. We validate the effectiveness of Variator on seven datasets. Experimental results show that Variator can save 53% computational costs using only 0.9% additional parameters with a performance drop of less than 2%. Moreover, when the model scales to billions of parameters, Variator matches the strong performance of uncompressed PLMs.
Thoroughly Modeling Multi-domain Pre-trained Recommendation as Language
Oct 20, 2023

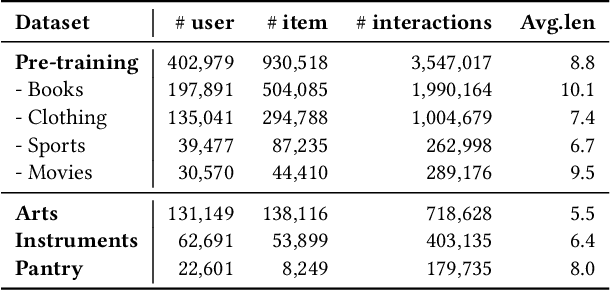
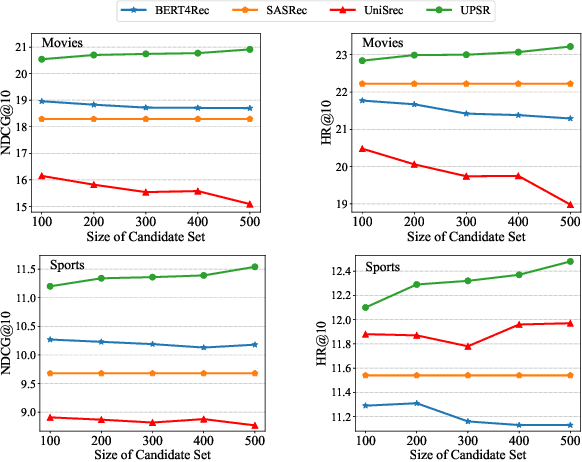
With the thriving of pre-trained language model (PLM) widely verified in various of NLP tasks, pioneer efforts attempt to explore the possible cooperation of the general textual information in PLM with the personalized behavioral information in user historical behavior sequences to enhance sequential recommendation (SR). However, despite the commonalities of input format and task goal, there are huge gaps between the behavioral and textual information, which obstruct thoroughly modeling SR as language modeling via PLM. To bridge the gap, we propose a novel Unified pre-trained language model enhanced sequential recommendation (UPSR), aiming to build a unified pre-trained recommendation model for multi-domain recommendation tasks. We formally design five key indicators, namely naturalness, domain consistency, informativeness, noise & ambiguity, and text length, to guide the text->item adaptation and behavior sequence->text sequence adaptation differently for pre-training and fine-tuning stages, which are essential but under-explored by previous works. In experiments, we conduct extensive evaluations on seven datasets with both tuning and zero-shot settings and achieve the overall best performance. Comprehensive model analyses also provide valuable insights for behavior modeling via PLM, shedding light on large pre-trained recommendation models. The source codes will be released in the future.
Plug-and-Play Document Modules for Pre-trained Models
May 28, 2023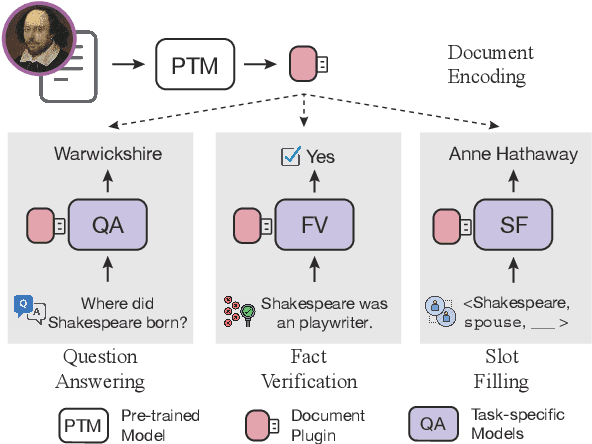
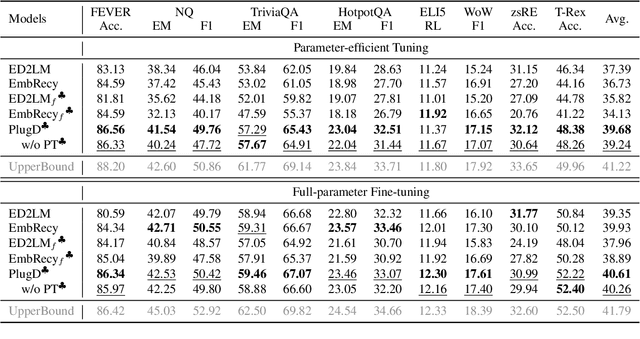
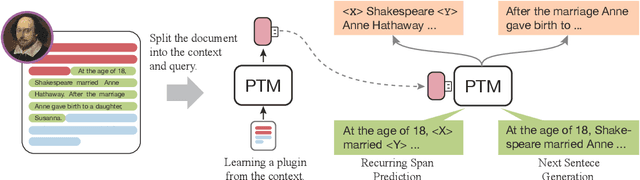
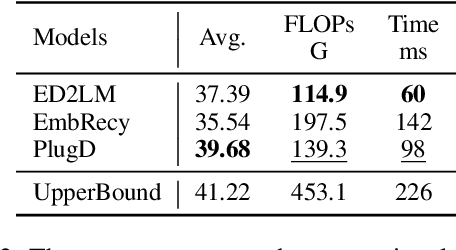
Large-scale pre-trained models (PTMs) have been widely used in document-oriented NLP tasks, such as question answering. However, the encoding-task coupling requirement results in the repeated encoding of the same documents for different tasks and queries, which is highly computationally inefficient. To this end, we target to decouple document encoding from downstream tasks, and propose to represent each document as a plug-and-play document module, i.e., a document plugin, for PTMs (PlugD). By inserting document plugins into the backbone PTM for downstream tasks, we can encode a document one time to handle multiple tasks, which is more efficient than conventional encoding-task coupling methods that simultaneously encode documents and input queries using task-specific encoders. Extensive experiments on 8 datasets of 4 typical NLP tasks show that PlugD enables models to encode documents once and for all across different scenarios. Especially, PlugD can save $69\%$ computational costs while achieving comparable performance to state-of-the-art encoding-task coupling methods. Additionally, we show that PlugD can serve as an effective post-processing way to inject knowledge into task-specific models, improving model performance without any additional model training.
Plug-and-Play Knowledge Injection for Pre-trained Language Models
May 28, 2023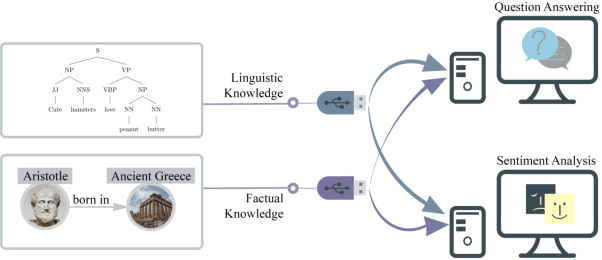

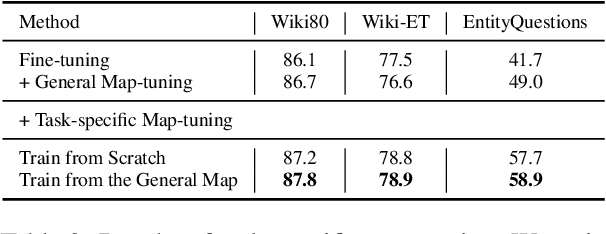
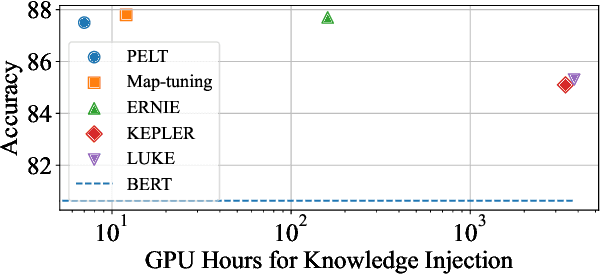
Injecting external knowledge can improve the performance of pre-trained language models (PLMs) on various downstream NLP tasks. However, massive retraining is required to deploy new knowledge injection methods or knowledge bases for downstream tasks. In this work, we are the first to study how to improve the flexibility and efficiency of knowledge injection by reusing existing downstream models. To this end, we explore a new paradigm plug-and-play knowledge injection, where knowledge bases are injected into frozen existing downstream models by a knowledge plugin. Correspondingly, we propose a plug-and-play injection method map-tuning, which trains a mapping of knowledge embeddings to enrich model inputs with mapped embeddings while keeping model parameters frozen. Experimental results on three knowledge-driven NLP tasks show that existing injection methods are not suitable for the new paradigm, while map-tuning effectively improves the performance of downstream models. Moreover, we show that a frozen downstream model can be well adapted to different domains with different mapping networks of domain knowledge. Our code and models are available at https://github.com/THUNLP/Knowledge-Plugin.