 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiyuan Zeng
WanJuan-CC: A Safe and High-Quality Open-sourced English Webtext Dataset
Mar 12, 2024
This paper presents WanJuan-CC, a safe and high-quality open-sourced English webtext dataset derived from Common Crawl data. The study addresses the challenges of constructing large-scale pre-training datasets for language models, which require vast amounts of high-quality data. A comprehensive process was designed to handle Common Crawl data, including extraction, heuristic rule filtering, fuzzy deduplication, content safety filtering, and data quality filtering. From approximately 68 billion original English documents, we obtained 2.22T Tokens of safe data and selected 1.0T Tokens of high-quality data as part of WanJuan-CC. We have open-sourced 100B Tokens from this dataset. The paper also provides statistical information related to data quality, enabling users to select appropriate data according to their needs. To evaluate the quality and utility of the dataset, we trained 1B-parameter and 3B-parameter models using WanJuan-CC and another dataset, RefinedWeb. Results show that WanJuan-CC performs better on validation datasets and downstream tasks.
Turn Waste into Worth: Rectifying Top-$k$ Router of MoE
Feb 21, 2024Sparse Mixture of Experts (MoE) models are popular for training large language models due to their computational efficiency. However, the commonly used top-$k$ routing mechanism suffers from redundancy computation and memory costs due to the unbalanced routing. Some experts are overflow, where the exceeding tokens are dropped. While some experts are vacant, which are padded with zeros, negatively impacting model performance. To address the dropped tokens and padding, we propose the Rectify-Router, comprising the Intra-GPU Rectification and the Fill-in Rectification. The Intra-GPU Rectification handles dropped tokens, efficiently routing them to experts within the GPU where they are located to avoid inter-GPU communication. The Fill-in Rectification addresses padding by replacing padding tokens with the tokens that have high routing scores. Our experimental results demonstrate that the Intra-GPU Rectification and the Fill-in Rectification effectively handle dropped tokens and padding, respectively. Furthermore, the combination of them achieves superior performance, surpassing the accuracy of the vanilla top-1 router by 4.7%.
Query of CC: Unearthing Large Scale Domain-Specific Knowledge from Public Corpora
Jan 26, 2024Large language models have demonstrated remarkable potential in various tasks, however, there remains a significant scarcity of open-source models and data for specific domains. Previous works have primarily focused on manually specifying resources and collecting high-quality data on specific domains, which significantly consume time and effort. To address this limitation, we propose an efficient data collection method~\textit{Query of CC} based on large language models. This method bootstraps seed information through a large language model and retrieves related data from public corpora. It not only collects knowledge-related data for specific domains but unearths the data with potential reasoning procedures. Through the application of this method, we have curated a high-quality dataset called~\textsc{Knowledge Pile}, encompassing four major domains, including stem and humanities sciences, among others. Experimental results demonstrate that~\textsc{Knowledge Pile} significantly improves the performance of large language models in mathematical and knowledge-related reasoning ability tests. To facilitate academic sharing, we open-source our dataset and code, providing valuable support to the academic community.
Evaluating Large Language Models at Evaluating Instruction Following
Oct 11, 2023As research in large language models (LLMs) continues to accelerate, LLM-based evaluation has emerged as a scalable and cost-effective alternative to human evaluations for comparing the ever increasing list of models. This paper investigates the efficacy of these "LLM evaluators", particularly in using them to assess instruction following, a metric that gauges how closely generated text adheres to the given instruction. We introduce a challenging meta-evaluation benchmark, LLMBar, designed to test the ability of an LLM evaluator in discerning instruction-following outputs. The authors manually curated 419 pairs of outputs, one adhering to instructions while the other diverging, yet may possess deceptive qualities that mislead an LLM evaluator, e.g., a more engaging tone. Contrary to existing meta-evaluation, we discover that different evaluators (i.e., combinations of LLMs and prompts) exhibit distinct performance on LLMBar and even the highest-scoring ones have substantial room for improvement. We also present a novel suite of prompting strategies that further close the gap between LLM and human evaluators. With LLMBar, we hope to offer more insight into LLM evaluators and foster future research in developing better instruction-following models.
Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
Oct 10, 2023The popularity of LLaMA (Touvron et al., 2023a;b) and other recently emerged moderate-sized large language models (LLMs) highlights the potential of building smaller yet powerful LLMs. Regardless, the cost of training such models from scratch on trillions of tokens remains high. In this work, we study structured pruning as an effective means to develop smaller LLMs from pre-trained, larger models. Our approach employs two key techniques: (1) targeted structured pruning, which prunes a larger model to a specified target shape by removing layers, heads, and intermediate and hidden dimensions in an end-to-end manner, and (2) dynamic batch loading, which dynamically updates the composition of sampled data in each training batch based on varying losses across different domains. We demonstrate the efficacy of our approach by presenting the Sheared-LLaMA series, pruning the LLaMA2-7B model down to 1.3B and 2.7B parameters. Sheared-LLaMA models outperform state-of-the-art open-source models of equivalent sizes, such as Pythia, INCITE, and OpenLLaMA models, on a wide range of downstream and instruction tuning evaluations, while requiring only 3% of compute compared to training such models from scratch. This work provides compelling evidence that leveraging existing LLMs with structured pruning is a far more cost-effective approach for building smaller LLMs.
Emergent Modularity in Pre-trained Transformers
May 28, 2023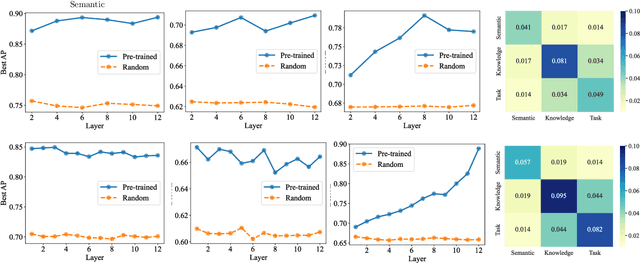

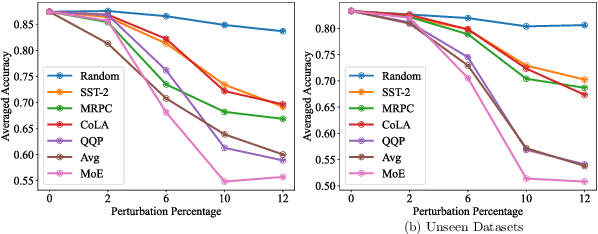

This work examines the presence of modularity in pre-trained Transformers, a feature commonly found in human brains and thought to be vital for general intelligence. In analogy to human brains, we consider two main characteristics of modularity: (1) functional specialization of neurons: we evaluate whether each neuron is mainly specialized in a certain function, and find that the answer is yes. (2) function-based neuron grouping: we explore finding a structure that groups neurons into modules by function, and each module works for its corresponding function. Given the enormous amount of possible structures, we focus on Mixture-of-Experts as a promising candidate, which partitions neurons into experts and usually activates different experts for different inputs. Experimental results show that there are functional experts, where clustered are the neurons specialized in a certain function. Moreover, perturbing the activations of functional experts significantly affects the corresponding function. Finally, we study how modularity emerges during pre-training, and find that the modular structure is stabilized at the early stage, which is faster than neuron stabilization. It suggests that Transformers first construct the modular structure and then learn fine-grained neuron functions. Our code and data are available at https://github.com/THUNLP/modularity-analysis.
Plug-and-Play Knowledge Injection for Pre-trained Language Models
May 28, 2023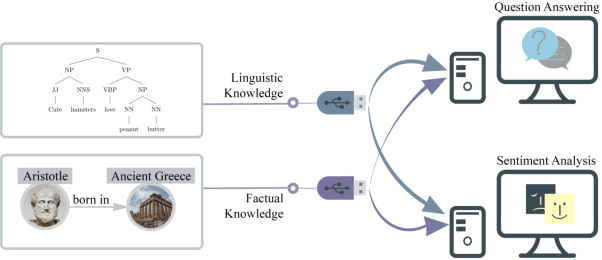

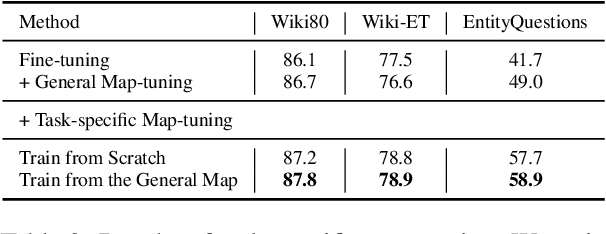
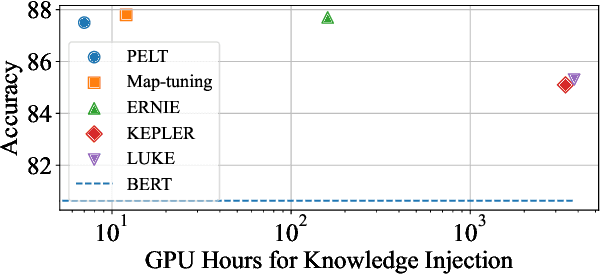
Injecting external knowledge can improve the performance of pre-trained language models (PLMs) on various downstream NLP tasks. However, massive retraining is required to deploy new knowledge injection methods or knowledge bases for downstream tasks. In this work, we are the first to study how to improve the flexibility and efficiency of knowledge injection by reusing existing downstream models. To this end, we explore a new paradigm plug-and-play knowledge injection, where knowledge bases are injected into frozen existing downstream models by a knowledge plugin. Correspondingly, we propose a plug-and-play injection method map-tuning, which trains a mapping of knowledge embeddings to enrich model inputs with mapped embeddings while keeping model parameters frozen. Experimental results on three knowledge-driven NLP tasks show that existing injection methods are not suitable for the new paradigm, while map-tuning effectively improves the performance of downstream models. Moreover, we show that a frozen downstream model can be well adapted to different domains with different mapping networks of domain knowledge. Our code and models are available at https://github.com/THUNLP/Knowledge-Plugin.
KNIFE: Knowledge Distillation with Free-Text Rationales
Dec 19, 2022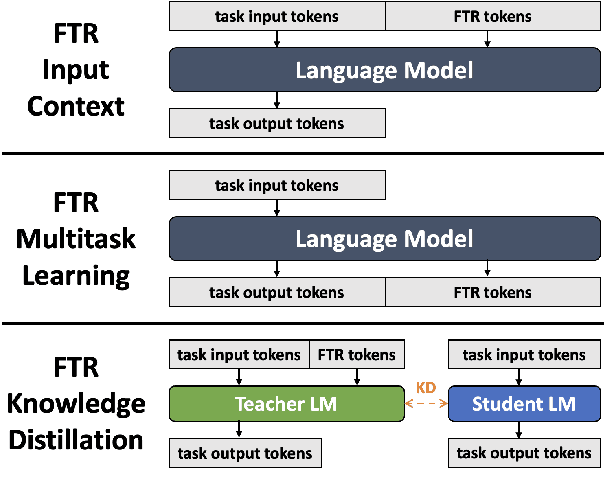
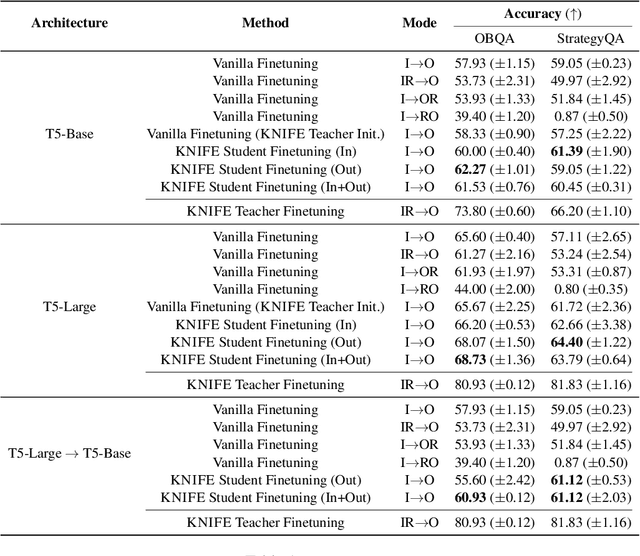
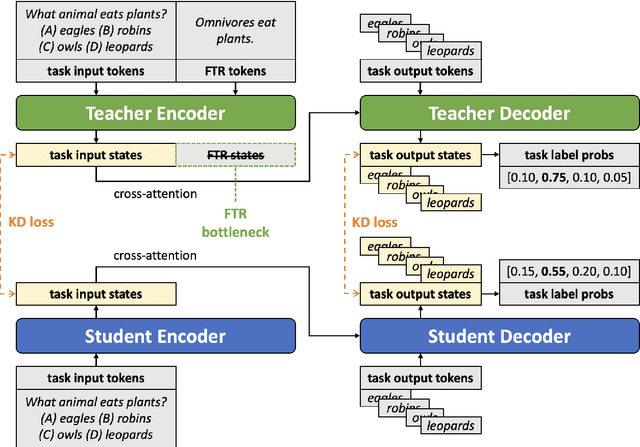

Free-text rationales (FTRs) follow how humans communicate by explaining reasoning processes via natural language. A number of recent works have studied how to improve language model (LM) generalization by using FTRs to teach LMs the correct reasoning processes behind correct task outputs. These prior works aim to learn from FTRs by appending them to the LM input or target output, but this may introduce an input distribution shift or conflict with the task objective, respectively. We propose KNIFE, which distills FTR knowledge from an FTR-augmented teacher LM (takes both task input and FTR) to a student LM (takes only task input), which is used for inference. Crucially, the teacher LM's forward computation has a bottleneck stage in which all of its FTR states are masked out, which pushes knowledge from the FTR states into the task input/output states. Then, FTR knowledge is distilled to the student LM by training its task input/output states to align with the teacher LM's. On two question answering datasets, we show that KNIFE significantly outperforms existing FTR learning methods, in both fully-supervised and low-resource settings.
Disentangling Confidence Score Distribution for Out-of-Domain Intent Detection with Energy-Based Learning
Oct 17, 2022
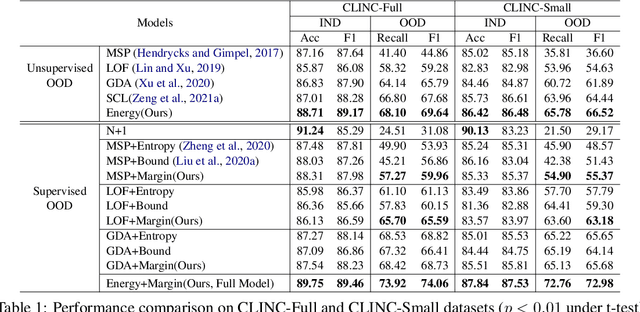
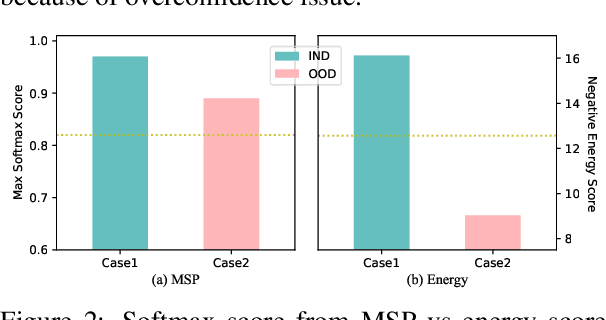
Detecting Out-of-Domain (OOD) or unknown intents from user queries is essential in a task-oriented dialog system. Traditional softmax-based confidence scores are susceptible to the overconfidence issue. In this paper, we propose a simple but strong energy-based score function to detect OOD where the energy scores of OOD samples are higher than IND samples. Further, given a small set of labeled OOD samples, we introduce an energy-based margin objective for supervised OOD detection to explicitly distinguish OOD samples from INDs. Comprehensive experiments and analysis prove our method helps disentangle confidence score distributions of IND and OOD data.\footnote{Our code is available at \url{https://github.com/pris-nlp/EMNLP2022-energy_for_OOD/}.}
Distribution Calibration for Out-of-Domain Detection with Bayesian Approximation
Sep 14, 2022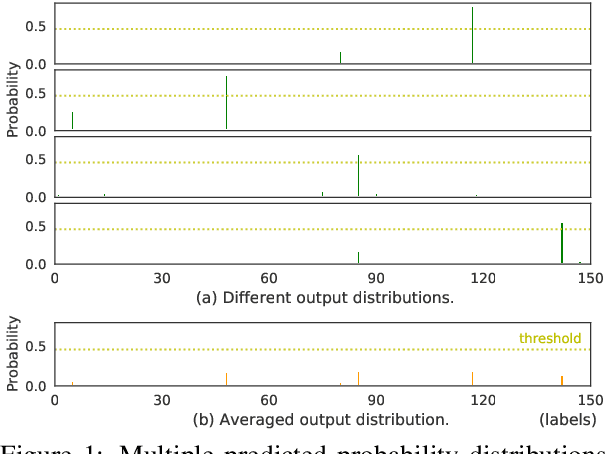
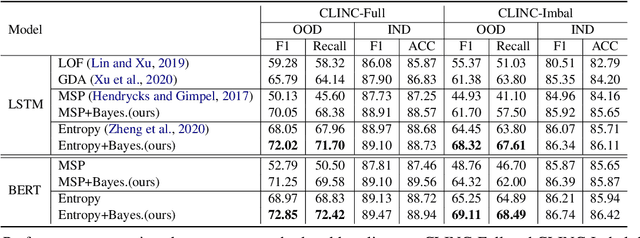
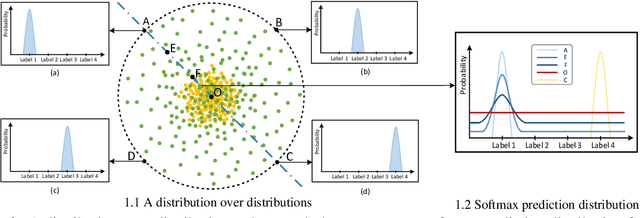
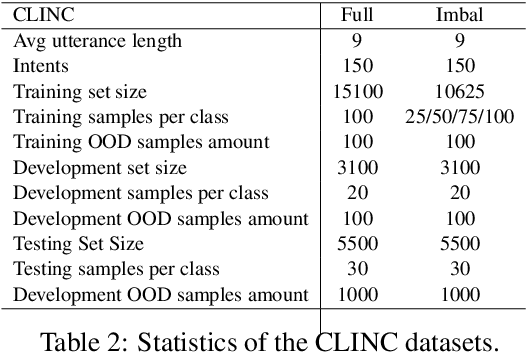
Out-of-Domain (OOD) detection is a key component in a task-oriented dialog system, which aims to identify whether a query falls outside the predefined supported intent set. Previous softmax-based detection algorithms are proved to be overconfident for OOD samples. In this paper, we analyze overconfident OOD comes from distribution uncertainty due to the mismatch between the training and test distributions, which makes the model can't confidently make predictions thus probably causing abnormal softmax scores. We propose a Bayesian OOD detection framework to calibrate distribution uncertainty using Monte-Carlo Dropout. Our method is flexible and easily pluggable into existing softmax-based baselines and gains 33.33\% OOD F1 improvements with increasing only 0.41\% inference time compared to MSP. Further analyses show the effectiveness of Bayesian learning for OOD detection.