 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHanjie Chen
Will the Real Linda Please Stand up...to Large Language Models? Examining the Representativeness Heuristic in LLMs
Apr 01, 2024
Although large language models (LLMs) have demonstrated remarkable proficiency in understanding text and generating human-like text, they may exhibit biases acquired from training data in doing so. Specifically, LLMs may be susceptible to a common cognitive trap in human decision-making called the representativeness heuristic. This is a concept in psychology that refers to judging the likelihood of an event based on how closely it resembles a well-known prototype or typical example versus considering broader facts or statistical evidence. This work investigates the impact of the representativeness heuristic on LLM reasoning. We created REHEAT (Representativeness Heuristic AI Testing), a dataset containing a series of problems spanning six common types of representativeness heuristics. Experiments reveal that four LLMs applied to REHEAT all exhibited representativeness heuristic biases. We further identify that the model's reasoning steps are often incorrectly based on a stereotype rather than the problem's description. Interestingly, the performance improves when adding a hint in the prompt to remind the model of using its knowledge. This suggests the uniqueness of the representativeness heuristic compared to traditional biases. It can occur even when LLMs possess the correct knowledge while failing in a cognitive trap. This highlights the importance of future research focusing on the representativeness heuristic in model reasoning and decision-making and on developing solutions to address it.
Benchmarking Large Language Models on Answering and Explaining Challenging Medical Questions
Mar 13, 2024LLMs have demonstrated impressive performance in answering medical questions, such as passing scores on medical licensing examinations. However, medical board exam questions or general clinical questions do not capture the complexity of realistic clinical cases. Moreover, the lack of reference explanations means we cannot easily evaluate the reasoning of model decisions, a crucial component of supporting doctors in making complex medical decisions. To address these challenges, we construct two new datasets: JAMA Clinical Challenge and Medbullets. JAMA Clinical Challenge consists of questions based on challenging clinical cases, while Medbullets comprises USMLE Step 2&3 style clinical questions. Both datasets are structured as multiple-choice question-answering tasks, where each question is accompanied by an expert-written explanation. We evaluate four LLMs on the two datasets using various prompts. Experiments demonstrate that our datasets are harder than previous benchmarks. The inconsistency between automatic and human evaluations of model-generated explanations highlights the need to develop new metrics to support future research on explainable medical QA.
RORA: Robust Free-Text Rationale Evaluation
Mar 01, 2024Free-text rationales play a pivotal role in explainable NLP, bridging the knowledge and reasoning gaps behind a model's decision-making. However, due to the diversity of potential reasoning paths and a corresponding lack of definitive ground truth, their evaluation remains a challenge. Existing evaluation metrics rely on the degree to which a rationale supports a target label, but we find these fall short in evaluating rationales that inadvertently leak the labels. To address this problem, we propose RORA, a Robust free-text Rationale evaluation against label leakage. RORA quantifies the new information supplied by a rationale to justify the label. This is achieved by assessing the conditional V-information \citep{hewitt-etal-2021-conditional} with a predictive family robust against leaky features that can be exploited by a small model. RORA consistently outperforms existing approaches in evaluating human-written, synthetic, or model-generated rationales, particularly demonstrating robustness against label leakage. We also show that RORA aligns well with human judgment, providing a more reliable and accurate measurement across diverse free-text rationales.
Explainability for Large Language Models: A Survey
Sep 17, 2023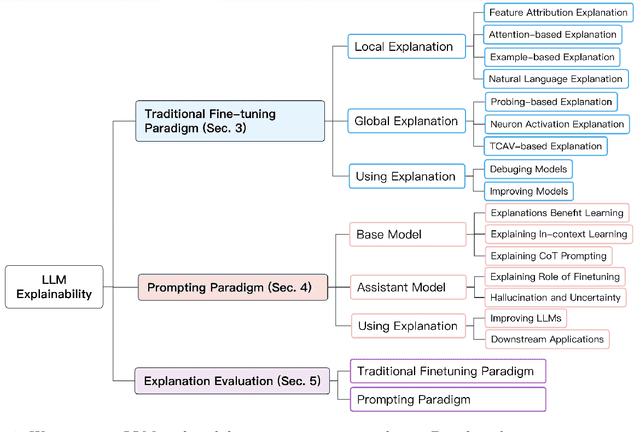

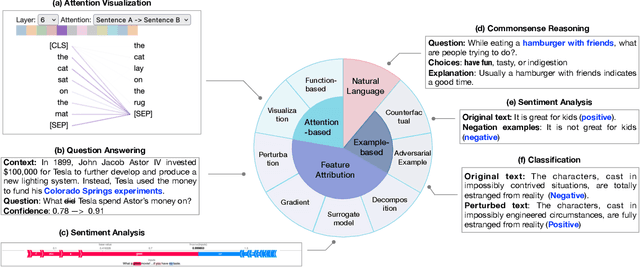
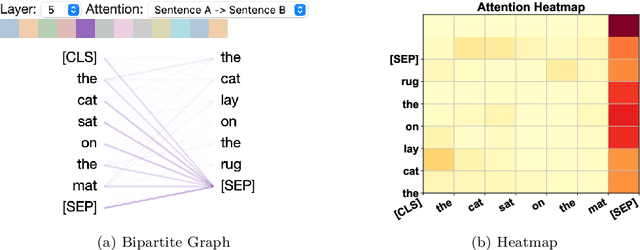
Large language models (LLMs) have demonstrated impressive capabilities in natural language processing. However, their internal mechanisms are still unclear and this lack of transparency poses unwanted risks for downstream applications. Therefore, understanding and explaining these models is crucial for elucidating their behaviors, limitations, and social impacts. In this paper, we introduce a taxonomy of explainability techniques and provide a structured overview of methods for explaining Transformer-based language models. We categorize techniques based on the training paradigms of LLMs: traditional fine-tuning-based paradigm and prompting-based paradigm. For each paradigm, we summarize the goals and dominant approaches for generating local explanations of individual predictions and global explanations of overall model knowledge. We also discuss metrics for evaluating generated explanations, and discuss how explanations can be leveraged to debug models and improve performance. Lastly, we examine key challenges and emerging opportunities for explanation techniques in the era of LLMs in comparison to conventional machine learning models.
Improving Interpretability via Explicit Word Interaction Graph Layer
Feb 03, 2023
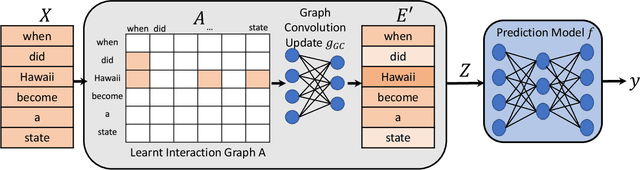
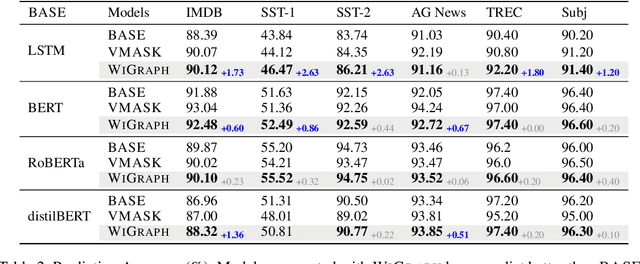
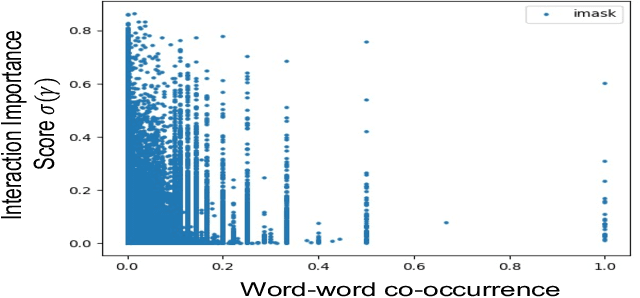
Recent NLP literature has seen growing interest in improving model interpretability. Along this direction, we propose a trainable neural network layer that learns a global interaction graph between words and then selects more informative words using the learned word interactions. Our layer, we call WIGRAPH, can plug into any neural network-based NLP text classifiers right after its word embedding layer. Across multiple SOTA NLP models and various NLP datasets, we demonstrate that adding the WIGRAPH layer substantially improves NLP models' interpretability and enhances models' prediction performance at the same time.
* 15 pages, AAAI 2023
KNIFE: Knowledge Distillation with Free-Text Rationales
Dec 19, 2022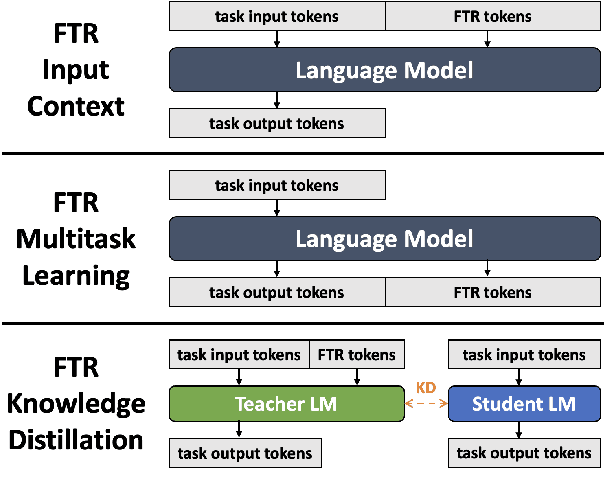
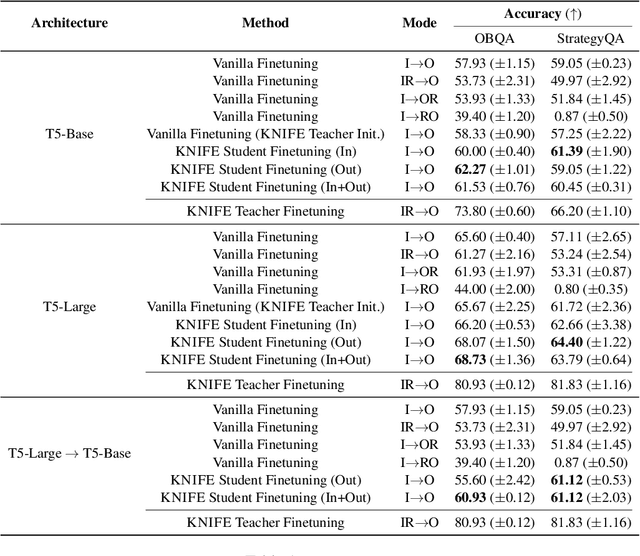
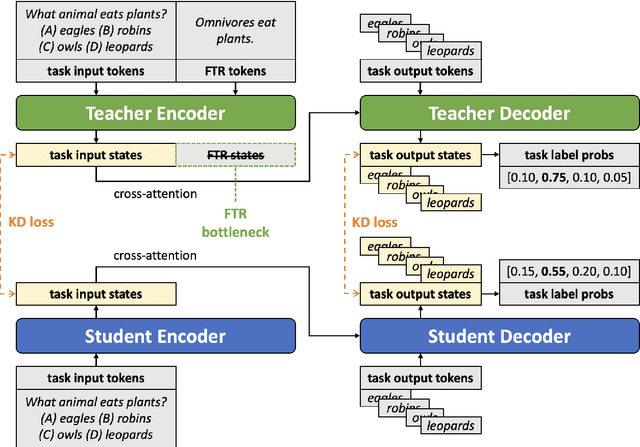

Free-text rationales (FTRs) follow how humans communicate by explaining reasoning processes via natural language. A number of recent works have studied how to improve language model (LM) generalization by using FTRs to teach LMs the correct reasoning processes behind correct task outputs. These prior works aim to learn from FTRs by appending them to the LM input or target output, but this may introduce an input distribution shift or conflict with the task objective, respectively. We propose KNIFE, which distills FTR knowledge from an FTR-augmented teacher LM (takes both task input and FTR) to a student LM (takes only task input), which is used for inference. Crucially, the teacher LM's forward computation has a bottleneck stage in which all of its FTR states are masked out, which pushes knowledge from the FTR states into the task input/output states. Then, FTR knowledge is distilled to the student LM by training its task input/output states to align with the teacher LM's. On two question answering datasets, we show that KNIFE significantly outperforms existing FTR learning methods, in both fully-supervised and low-resource settings.
Identifying the Source of Vulnerability in Explanation Discrepancy: A Case Study in Neural Text Classification
Dec 10, 2022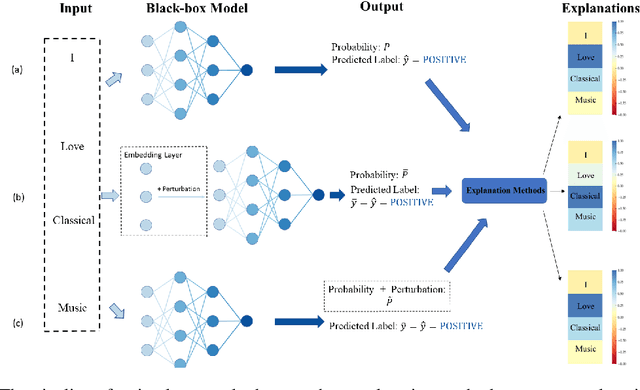

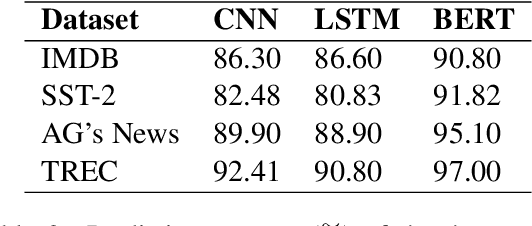
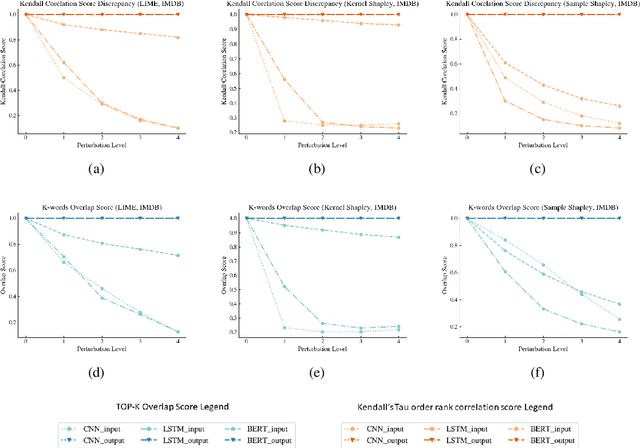
Some recent works observed the instability of post-hoc explanations when input side perturbations are applied to the model. This raises the interest and concern in the stability of post-hoc explanations. However, the remaining question is: is the instability caused by the neural network model or the post-hoc explanation method? This work explores the potential source that leads to unstable post-hoc explanations. To separate the influence from the model, we propose a simple output probability perturbation method. Compared to prior input side perturbation methods, the output probability perturbation method can circumvent the neural model's potential effect on the explanations and allow the analysis on the explanation method. We evaluate the proposed method with three widely-used post-hoc explanation methods (LIME (Ribeiro et al., 2016), Kernel Shapley (Lundberg and Lee, 2017a), and Sample Shapley (Strumbelj and Kononenko, 2010)). The results demonstrate that the post-hoc methods are stable, barely producing discrepant explanations under output probability perturbations. The observation suggests that neural network models may be the primary source of fragile explanations.
REV: Information-Theoretic Evaluation of Free-Text Rationales
Oct 10, 2022

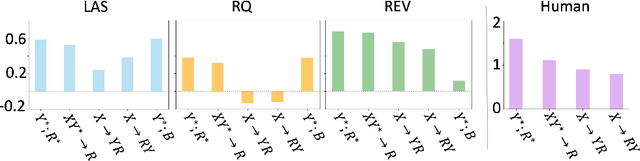
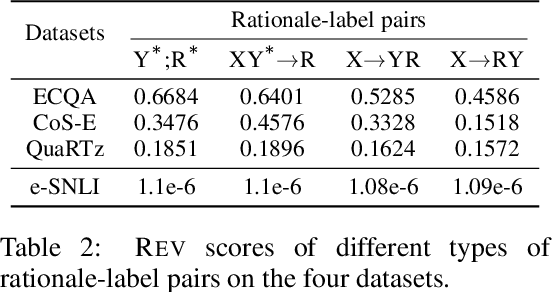
Free-text rationales are a promising step towards explainable AI, yet their evaluation remains an open research problem. While existing metrics have mostly focused on measuring the direct association between the rationale and a given label, we argue that an ideal metric should also be able to focus on the new information uniquely provided in the rationale that is otherwise not provided in the input or the label. We investigate this research problem from an information-theoretic perspective using the conditional V-information. More concretely, we propose a metric called REV (Rationale Evaluation with conditional V-information), that can quantify the new information in a rationale supporting a given label beyond the information already available in the input or the label. Experiments on reasoning tasks across four benchmarks, including few-shot prompting with GPT-3, demonstrate the effectiveness of REV in evaluating different types of rationale-label pairs, compared to existing metrics. Through several quantitative comparisons, we demonstrate the capability of REV in providing more sensitive measurements of new information in free-text rationales with respect to a label. Furthermore, REV is consistent with human judgments on rationale evaluations. Overall, when used alongside traditional performance metrics, REV provides deeper insights into a models' reasoning and prediction processes.
Self-augmented Data Selection for Few-shot Dialogue Generation
May 19, 2022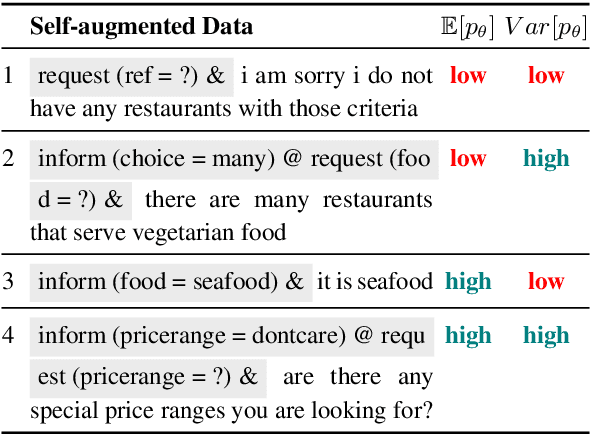



The natural language generation (NLG) module in task-oriented dialogue systems translates structured meaning representations (MRs) into text responses, which has a great impact on users' experience as the human-machine interaction interface. However, in practice, developers often only have a few well-annotated data and confront a high data collection cost to build the NLG module. In this work, we adopt the self-training framework to deal with the few-shot MR-to-Text generation problem. We leverage the pre-trained language model to self-augment many pseudo-labeled data. To prevent the gradual drift from target data distribution to noisy augmented data distribution, we propose a novel data selection strategy to select the data that our generation model is most uncertain about. Compared with existing data selection methods, our method is: (1) parameter-efficient, which does not require training any additional neural models, (2) computation-efficient, which only needs to apply several stochastic forward passes of the model to estimate the uncertainty. We conduct empirical experiments on two benchmark datasets: FewShotWOZ and FewShotSGD, and show that our proposed framework consistently outperforms other baselines in terms of BLEU and ERR.
Pathologies of Pre-trained Language Models in Few-shot Fine-tuning
Apr 17, 2022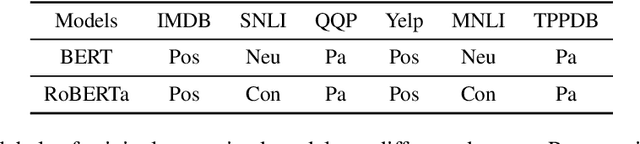
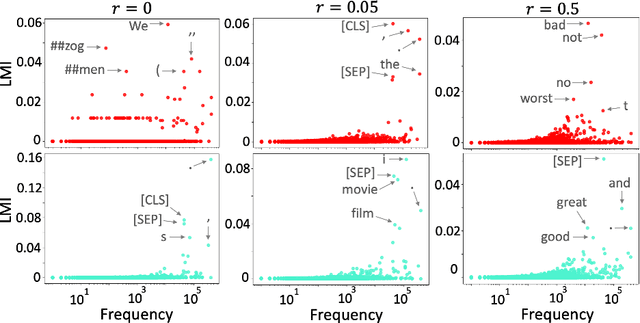
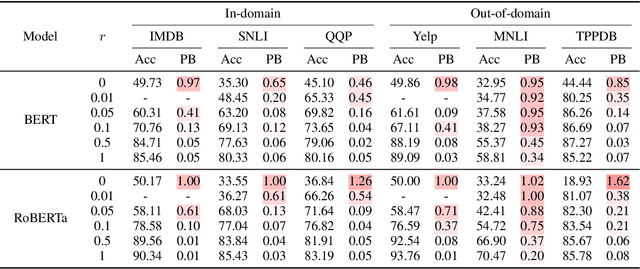
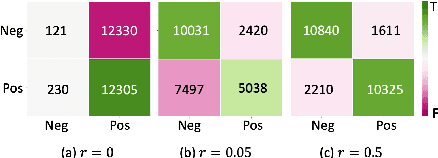
Although adapting pre-trained language models with few examples has shown promising performance on text classification, there is a lack of understanding of where the performance gain comes from. In this work, we propose to answer this question by interpreting the adaptation behavior using post-hoc explanations from model predictions. By modeling feature statistics of explanations, we discover that (1) without fine-tuning, pre-trained models (e.g. BERT and RoBERTa) show strong prediction bias across labels; (2) although few-shot fine-tuning can mitigate the prediction bias and demonstrate promising prediction performance, our analysis shows models gain performance improvement by capturing non-task-related features (e.g. stop words) or shallow data patterns (e.g. lexical overlaps). These observations alert that pursuing model performance with fewer examples may incur pathological prediction behavior, which requires further sanity check on model predictions and careful design in model evaluations in few-shot fine-tuning.