 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuaiqiang Wang
XL$^2$Bench: A Benchmark for Extremely Long Context Understanding with Long-range Dependencies
Apr 08, 2024
Large Language Models (LLMs) have demonstrated remarkable performance across diverse tasks but are constrained by their small context window sizes. Various efforts have been proposed to expand the context window to accommodate even up to 200K input tokens. Meanwhile, building high-quality benchmarks with much longer text lengths and more demanding tasks to provide comprehensive evaluations is of immense practical interest to facilitate long context understanding research of LLMs. However, prior benchmarks create datasets that ostensibly cater to long-text comprehension by expanding the input of traditional tasks, which falls short to exhibit the unique characteristics of long-text understanding, including long dependency tasks and longer text length compatible with modern LLMs' context window size. In this paper, we introduce a benchmark for extremely long context understanding with long-range dependencies, XL$^2$Bench, which includes three scenarios: Fiction Reading, Paper Reading, and Law Reading, and four tasks of increasing complexity: Memory Retrieval, Detailed Understanding, Overall Understanding, and Open-ended Generation, covering 27 subtasks in English and Chinese. It has an average length of 100K+ words (English) and 200K+ characters (Chinese). Evaluating six leading LLMs on XL$^2$Bench, we find that their performance significantly lags behind human levels. Moreover, the observed decline in performance across both the original and enhanced datasets underscores the efficacy of our approach to mitigating data contamination.
Improving the Robustness of Large Language Models via Consistency Alignment
Mar 22, 2024



Large language models (LLMs) have shown tremendous success in following user instructions and generating helpful responses. Nevertheless, their robustness is still far from optimal, as they may generate significantly inconsistent responses due to minor changes in the verbalized instructions. Recent literature has explored this inconsistency issue, highlighting the importance of continued improvement in the robustness of response generation. However, systematic analysis and solutions are still lacking. In this paper, we quantitatively define the inconsistency problem and propose a two-stage training framework consisting of instruction-augmented supervised fine-tuning and consistency alignment training. The first stage helps a model generalize on following instructions via similar instruction augmentations. In the second stage, we improve the diversity and help the model understand which responses are more aligned with human expectations by differentiating subtle differences in similar responses. The training process is accomplished by self-rewards inferred from the trained model at the first stage without referring to external human preference resources. We conduct extensive experiments on recent publicly available LLMs on instruction-following tasks and demonstrate the effectiveness of our training framework.
The Good and The Bad: Exploring Privacy Issues in Retrieval-Augmented Generation (RAG)
Feb 23, 2024Retrieval-augmented generation (RAG) is a powerful technique to facilitate language model with proprietary and private data, where data privacy is a pivotal concern. Whereas extensive research has demonstrated the privacy risks of large language models (LLMs), the RAG technique could potentially reshape the inherent behaviors of LLM generation, posing new privacy issues that are currently under-explored. In this work, we conduct extensive empirical studies with novel attack methods, which demonstrate the vulnerability of RAG systems on leaking the private retrieval database. Despite the new risk brought by RAG on the retrieval data, we further reveal that RAG can mitigate the leakage of the LLMs' training data. Overall, we provide new insights in this paper for privacy protection of retrieval-augmented LLMs, which benefit both LLMs and RAG systems builders. Our code is available at https://github.com/phycholosogy/RAG-privacy.
KnowTuning: Knowledge-aware Fine-tuning for Large Language Models
Feb 17, 2024Despite their success at many natural language processing (NLP) tasks, large language models (LLMs) still struggle to effectively leverage knowledge for knowledge-intensive tasks, manifesting limitations such as generating incomplete, non-factual, or illogical answers. These limitations stem from inadequate knowledge awareness of LLMs during vanilla fine-tuning. To address these problems, we propose a knowledge-aware fine-tuning (KnowTuning) method to explicitly and implicitly improve the knowledge awareness of LLMs. We devise an explicit knowledge-aware generation stage to train LLMs to explicitly identify knowledge triples in answers. We also propose an implicit knowledge-aware comparison stage to train LLMs to implicitly distinguish between reliable and unreliable knowledge, in three aspects: completeness, factuality, and logicality. Extensive experiments on both generic and medical question answering (QA) datasets confirm the effectiveness of KnowTuning, through automatic and human evaluations, across various sizes of LLMs. Finally, we demonstrate that the improvements of KnowTuning generalize to unseen QA datasets.
Towards Verifiable Text Generation with Evolving Memory and Self-Reflection
Dec 14, 2023
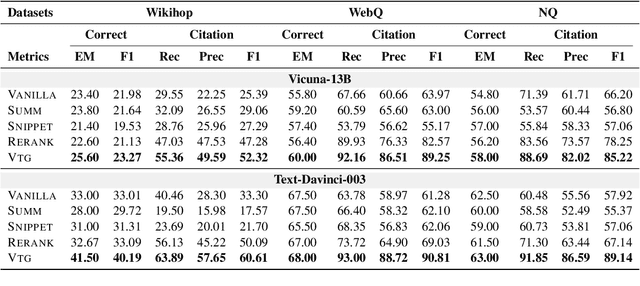
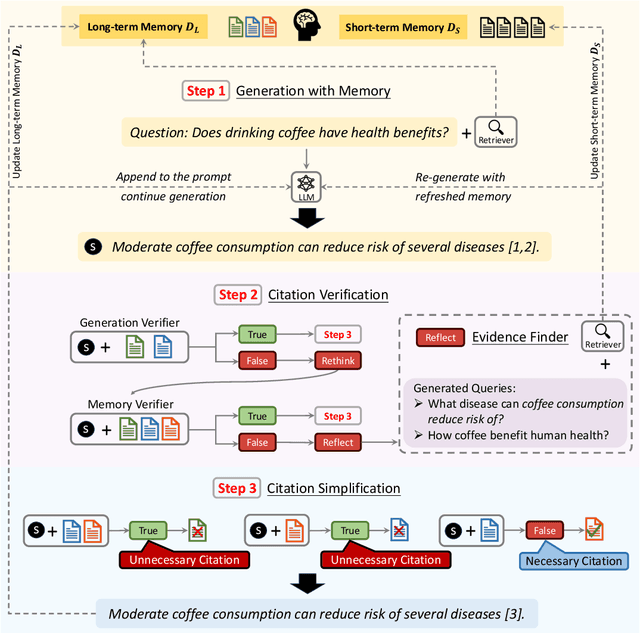
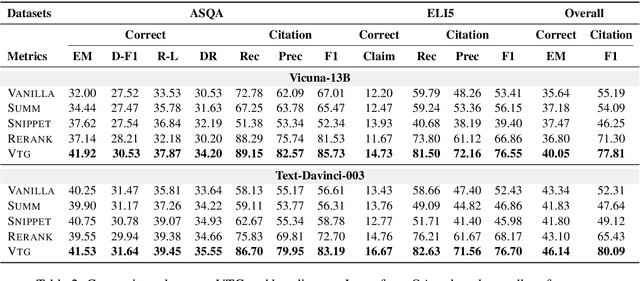
Large Language Models (LLMs) face several challenges, including the tendency to produce incorrect outputs, known as hallucination. An effective solution is verifiable text generation, which prompts LLMs to generate content with citations for accuracy verification. However, verifiable text generation is non-trivial due to the focus-shifting phenomenon, the dilemma between the precision and scope in document retrieval, and the intricate reasoning required to discern the relationship between the claim and citations. In this paper, we present VTG, an innovative approach for Verifiable Text Generation with evolving memory and self-reflection. VTG maintains evolving long short-term memory to retain both valuable documents and up-to-date documents. Active retrieval and diverse query generation are utilized to enhance both the precision and scope of the retrieved documents. Furthermore, VTG features a two-tier verifier and an evidence finder, enabling rethinking and reflection on the relationship between the claim and citations. We conduct extensive experiments on five datasets across three knowledge-intensive tasks and the results reveal that VTG significantly outperforms existing baselines.
Self-supervised Heterogeneous Graph Variational Autoencoders
Nov 14, 2023Heterogeneous Information Networks (HINs), which consist of various types of nodes and edges, have recently demonstrated excellent performance in graph mining. However, most existing heterogeneous graph neural networks (HGNNs) ignore the problems of missing attributes, inaccurate attributes and scarce labels for nodes, which limits their expressiveness. In this paper, we propose a generative self-supervised model SHAVA to address these issues simultaneously. Specifically, SHAVA first initializes all the nodes in the graph with a low-dimensional representation matrix. After that, based on the variational graph autoencoder framework, SHAVA learns both node-level and attribute-level embeddings in the encoder, which can provide fine-grained semantic information to construct node attributes. In the decoder, SHAVA reconstructs both links and attributes. Instead of directly reconstructing raw features for attributed nodes, SHAVA generates the initial low-dimensional representation matrix for all the nodes, based on which raw features of attributed nodes are further reconstructed to leverage accurate attributes. In this way, SHAVA can not only complete informative features for non-attributed nodes, but rectify inaccurate ones for attributed nodes. Finally, we conduct extensive experiments to show the superiority of SHAVA in tackling HINs with missing and inaccurate attributes.
Exploiting Latent Attribute Interaction with Transformer on Heterogeneous Information Networks
Nov 06, 2023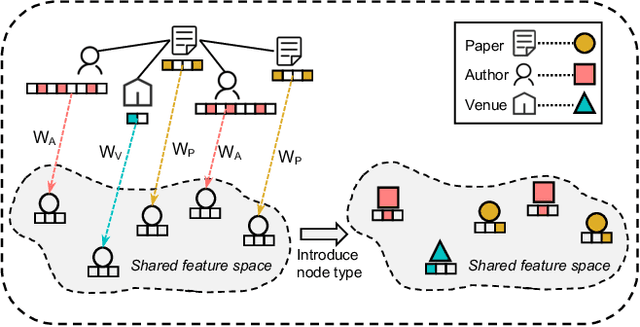
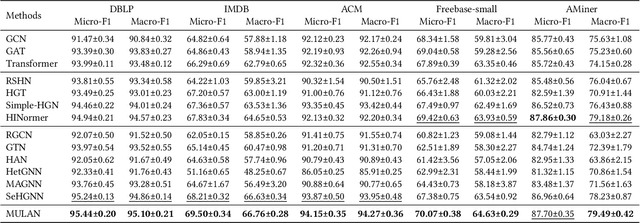
Heterogeneous graph neural networks (HGNNs) have recently shown impressive capability in modeling heterogeneous graphs that are ubiquitous in real-world applications. Due to the diversity of attributes of nodes in different types, most existing models first align nodes by mapping them into the same low-dimensional space. However, in this way, they lose the type information of nodes. In addition, most of them only consider the interactions between nodes while neglecting the high-order information behind the latent interactions among different node features. To address these problems, in this paper, we propose a novel heterogeneous graph model MULAN, including two major components, i.e., a type-aware encoder and a dimension-aware encoder. Specifically, the type-aware encoder compensates for the loss of node type information and better leverages graph heterogeneity in learning node representations. Built upon transformer architecture, the dimension-aware encoder is capable of capturing the latent interactions among the diverse node features. With these components, the information of graph heterogeneity, node features and graph structure can be comprehensively encoded in node representations. We conduct extensive experiments on six heterogeneous benchmark datasets, which demonstrates the superiority of MULAN over other state-of-the-art competitors and also shows that MULAN is efficient.
Instruction Distillation Makes Large Language Models Efficient Zero-shot Rankers
Nov 02, 2023Recent studies have demonstrated the great potential of Large Language Models (LLMs) serving as zero-shot relevance rankers. The typical approach involves making comparisons between pairs or lists of documents. Although effective, these listwise and pairwise methods are not efficient and also heavily rely on intricate prompt engineering. To tackle this problem, we introduce a novel instruction distillation method. The key idea is to distill the pairwise ranking ability of open-sourced LLMs to a simpler but more efficient pointwise ranking. Specifically, given the same LLM, we first rank documents using the effective pairwise approach with complex instructions, and then distill the teacher predictions to the pointwise approach with simpler instructions. Evaluation results on the BEIR, TREC, and ReDial datasets demonstrate that instruction distillation can improve efficiency by 10 to 100x and also enhance the ranking performance of LLMs. Furthermore, our approach surpasses the performance of existing supervised methods like monoT5 and is on par with the state-of-the-art zero-shot methods. The code to reproduce our results is available at www.github.com/sunnweiwei/RankGPT.
MILL: Mutual Verification with Large Language Models for Zero-Shot Query Expansion
Oct 29, 2023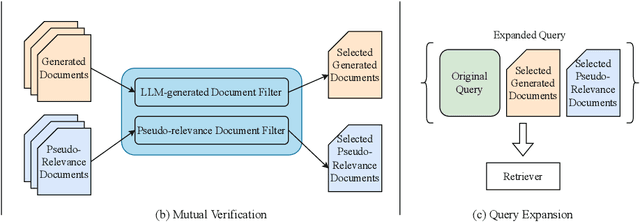
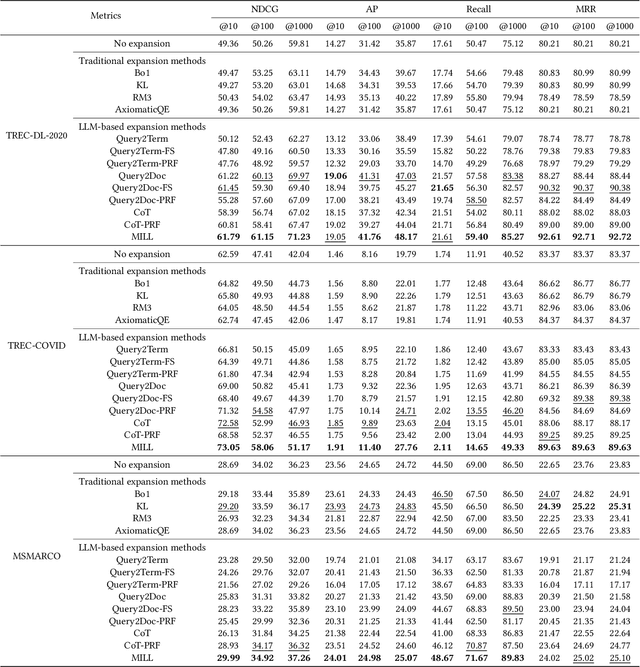

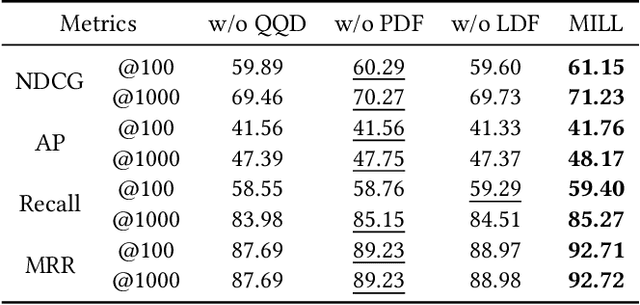
Query expansion is a commonly-used technique in many search systems to better represent users' information needs with additional query terms. Existing studies for this task usually propose to expand a query with retrieved or generated contextual documents. However, both types of methods have clear limitations. For retrieval-based methods, the documents retrieved with the original query might not be accurate enough to reveal the search intent, especially when the query is brief or ambiguous. For generation-based methods, existing models can hardly be trained or aligned on a particular corpus, due to the lack of corpus-specific labeled data. In this paper, we propose a novel Large Language Model (LLM) based mutual verification framework for query expansion, which alleviates the aforementioned limitations. Specifically, we first design a query-query-document generation pipeline, which can effectively leverage the contextual knowledge encoded in LLMs to generate sub-queries and corresponding documents from multiple perspectives. Next, we employ a mutual verification method for both generated and retrieved contextual documents, where 1) retrieved documents are filtered with the external contextual knowledge in generated documents, and 2) generated documents are filtered with the corpus-specific knowledge in retrieved documents. Overall, the proposed method allows retrieved and generated documents to complement each other to finalize a better query expansion. We conduct extensive experiments on three information retrieval datasets, i.e., TREC-DL-2020, TREC-COVID, and MSMARCO. The results demonstrate that our method outperforms other baselines significantly.
Knowing What LLMs DO NOT Know: A Simple Yet Effective Self-Detection Method
Oct 27, 2023Large Language Models (LLMs) have shown great potential in Natural Language Processing (NLP) tasks. However, recent literature reveals that LLMs generate nonfactual responses intermittently, which impedes the LLMs' reliability for further utilization. In this paper, we propose a novel self-detection method to detect which questions that a LLM does not know that are prone to generate nonfactual results. Specifically, we first diversify the textual expressions for a given question and collect the corresponding answers. Then we examine the divergencies between the generated answers to identify the questions that the model may generate falsehoods. All of the above steps can be accomplished by prompting the LLMs themselves without referring to any other external resources. We conduct comprehensive experiments and demonstrate the effectiveness of our method on recently released LLMs, e.g., Vicuna, ChatGPT, and GPT-4.