 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuangyi Chen
Narrative Action Evaluation with Prompt-Guided Multimodal Interaction
Apr 26, 2024
In this paper, we investigate a new problem called narrative action evaluation (NAE). NAE aims to generate professional commentary that evaluates the execution of an action. Unlike traditional tasks such as score-based action quality assessment and video captioning involving superficial sentences, NAE focuses on creating detailed narratives in natural language. These narratives provide intricate descriptions of actions along with objective evaluations. NAE is a more challenging task because it requires both narrative flexibility and evaluation rigor. One existing possible solution is to use multi-task learning, where narrative language and evaluative information are predicted separately. However, this approach results in reduced performance for individual tasks because of variations between tasks and differences in modality between language information and evaluation information. To address this, we propose a prompt-guided multimodal interaction framework. This framework utilizes a pair of transformers to facilitate the interaction between different modalities of information. It also uses prompts to transform the score regression task into a video-text matching task, thus enabling task interactivity. To support further research in this field, we re-annotate the MTL-AQA and FineGym datasets with high-quality and comprehensive action narration. Additionally, we establish benchmarks for NAE. Extensive experiment results prove that our method outperforms separate learning methods and naive multi-task learning methods. Data and code are released at https://github.com/shiyi-zh0408/NAE_CVPR2024.
Federated Causal Discovery from Heterogeneous Data
Feb 27, 2024Conventional causal discovery methods rely on centralized data, which is inconsistent with the decentralized nature of data in many real-world situations. This discrepancy has motivated the development of federated causal discovery (FCD) approaches. However, existing FCD methods may be limited by their potentially restrictive assumptions of identifiable functional causal models or homogeneous data distributions, narrowing their applicability in diverse scenarios. In this paper, we propose a novel FCD method attempting to accommodate arbitrary causal models and heterogeneous data. We first utilize a surrogate variable corresponding to the client index to account for the data heterogeneity across different clients. We then develop a federated conditional independence test (FCIT) for causal skeleton discovery and establish a federated independent change principle (FICP) to determine causal directions. These approaches involve constructing summary statistics as a proxy of the raw data to protect data privacy. Owing to the nonparametric properties, FCIT and FICP make no assumption about particular functional forms, thereby facilitating the handling of arbitrary causal models. We conduct extensive experiments on synthetic and real datasets to show the efficacy of our method. The code is available at https://github.com/lokali/FedCDH.git.
Confidence Matters: Revisiting Intrinsic Self-Correction Capabilities of Large Language Models
Feb 27, 2024



The recent success of Large Language Models (LLMs) has catalyzed an increasing interest in their self-correction capabilities. This paper presents a comprehensive investigation into the intrinsic self-correction of LLMs, attempting to address the ongoing debate about its feasibility. Our research has identified an important latent factor - the "confidence" of LLMs - during the self-correction process. Overlooking this factor may cause the models to over-criticize themselves, resulting in unreliable conclusions regarding the efficacy of self-correction. We have experimentally observed that LLMs possess the capability to understand the "confidence" in their own responses. It motivates us to develop an "If-or-Else" (IoE) prompting framework, designed to guide LLMs in assessing their own "confidence", facilitating intrinsic self-corrections. We conduct extensive experiments and demonstrate that our IoE-based Prompt can achieve a consistent improvement regarding the accuracy of self-corrected responses over the initial answers. Our study not only sheds light on the underlying factors affecting self-correction in LLMs, but also introduces a practical framework that utilizes the IoE prompting principle to efficiently improve self-correction capabilities with "confidence". The code is available at https://github.com/MBZUAI-CLeaR/IoE-Prompting.git.
Learning Domain-Invariant Temporal Dynamics for Few-Shot Action Recognition
Feb 20, 2024Few-shot action recognition aims at quickly adapting a pre-trained model to the novel data with a distribution shift using only a limited number of samples. Key challenges include how to identify and leverage the transferable knowledge learned by the pre-trained model. Our central hypothesis is that temporal invariance in the dynamic system between latent variables lends itself to transferability (domain-invariance). We therefore propose DITeD, or Domain-Invariant Temporal Dynamics for knowledge transfer. To detect the temporal invariance part, we propose a generative framework with a two-stage training strategy during pre-training. Specifically, we explicitly model invariant dynamics including temporal dynamic generation and transitions, and the variant visual and domain encoders. Then we pre-train the model with the self-supervised signals to learn the representation. After that, we fix the whole representation model and tune the classifier. During adaptation, we fix the transferable temporal dynamics and update the image encoder. The efficacy of our approach is revealed by the superior accuracy of DITeD over leading alternatives across standard few-shot action recognition datasets. Moreover, we validate that the learned temporal dynamic transition and temporal dynamic generation modules possess transferable qualities.
When and How: Learning Identifiable Latent States for Nonstationary Time Series Forecasting
Feb 20, 2024Temporal distribution shifts are ubiquitous in time series data. One of the most popular methods assumes that the temporal distribution shift occurs uniformly to disentangle the stationary and nonstationary dependencies. But this assumption is difficult to meet, as we do not know when the distribution shifts occur. To solve this problem, we propose to learn IDentifiable latEnt stAtes (IDEA) to detect when the distribution shifts occur. Beyond that, we further disentangle the stationary and nonstationary latent states via sufficient observation assumption to learn how the latent states change. Specifically, we formalize the causal process with environment-irrelated stationary and environment-related nonstationary variables. Under mild conditions, we show that latent environments and stationary/nonstationary variables are identifiable. Based on these theories, we devise the IDEA model, which incorporates an autoregressive hidden Markov model to estimate latent environments and modular prior networks to identify latent states. The IDEA model outperforms several latest nonstationary forecasting methods on various benchmark datasets, highlighting its advantages in real-world scenarios.
CaRiNG: Learning Temporal Causal Representation under Non-Invertible Generation Process
Jan 25, 2024Identifying the underlying time-delayed latent causal processes in sequential data is vital for grasping temporal dynamics and making downstream reasoning. While some recent methods can robustly identify these latent causal variables, they rely on strict assumptions about the invertible generation process from latent variables to observed data. However, these assumptions are often hard to satisfy in real-world applications containing information loss. For instance, the visual perception process translates a 3D space into 2D images, or the phenomenon of persistence of vision incorporates historical data into current perceptions. To address this challenge, we establish an identifiability theory that allows for the recovery of independent latent components even when they come from a nonlinear and non-invertible mix. Using this theory as a foundation, we propose a principled approach, CaRiNG, to learn the CAusal RepresentatIon of Non-invertible Generative temporal data with identifiability guarantees. Specifically, we utilize temporal context to recover lost latent information and apply the conditions in our theory to guide the training process. Through experiments conducted on synthetic datasets, we validate that our CaRiNG method reliably identifies the causal process, even when the generation process is non-invertible. Moreover, we demonstrate that our approach considerably improves temporal understanding and reasoning in practical applications.
Learning Socio-Temporal Graphs for Multi-Agent Trajectory Prediction
Dec 22, 2023In order to predict a pedestrian's trajectory in a crowd accurately, one has to take into account her/his underlying socio-temporal interactions with other pedestrians consistently. Unlike existing work that represents the relevant information separately, partially, or implicitly, we propose a complete representation for it to be fully and explicitly captured and analyzed. In particular, we introduce a Directed Acyclic Graph-based structure, which we term Socio-Temporal Graph (STG), to explicitly capture pair-wise socio-temporal interactions among a group of people across both space and time. Our model is built on a time-varying generative process, whose latent variables determine the structure of the STGs. We design an attention-based model named STGformer that affords an end-to-end pipeline to learn the structure of the STGs for trajectory prediction. Our solution achieves overall state-of-the-art prediction accuracy in two large-scale benchmark datasets. Our analysis shows that a person's past trajectory is critical for predicting another person's future path. Our model learns this relationship with a strong notion of socio-temporal localities. Statistics show that utilizing this information explicitly for prediction yields a noticeable performance gain with respect to the trajectory-only approaches.
Identifying Semantic Component for Robust Molecular Property Prediction
Nov 08, 2023


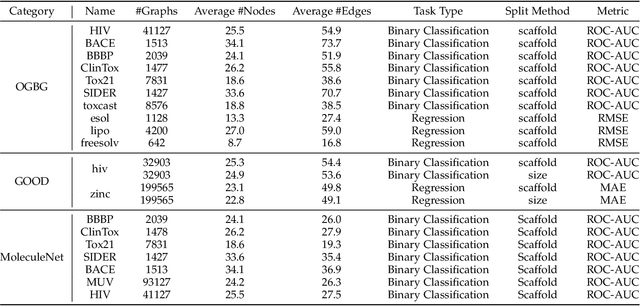
Although graph neural networks have achieved great success in the task of molecular property prediction in recent years, their generalization ability under out-of-distribution (OOD) settings is still under-explored. Different from existing methods that learn discriminative representations for prediction, we propose a generative model with semantic-components identifiability, named SCI. We demonstrate that the latent variables in this generative model can be explicitly identified into semantic-relevant (SR) and semantic-irrelevant (SI) components, which contributes to better OOD generalization by involving minimal change properties of causal mechanisms. Specifically, we first formulate the data generation process from the atom level to the molecular level, where the latent space is split into SI substructures, SR substructures, and SR atom variables. Sequentially, to reduce misidentification, we restrict the minimal changes of the SR atom variables and add a semantic latent substructure regularization to mitigate the variance of the SR substructure under augmented domain changes. Under mild assumptions, we prove the block-wise identifiability of the SR substructure and the comment-wise identifiability of SR atom variables. Experimental studies achieve state-of-the-art performance and show general improvement on 21 datasets in 3 mainstream benchmarks. Moreover, the visualization results of the proposed SCI method provide insightful case studies and explanations for the prediction results. The code is available at: https://github.com/DMIRLAB-Group/SCI.
Temporally Disentangled Representation Learning under Unknown Nonstationarity
Oct 28, 2023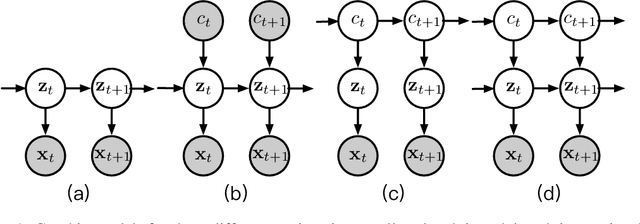
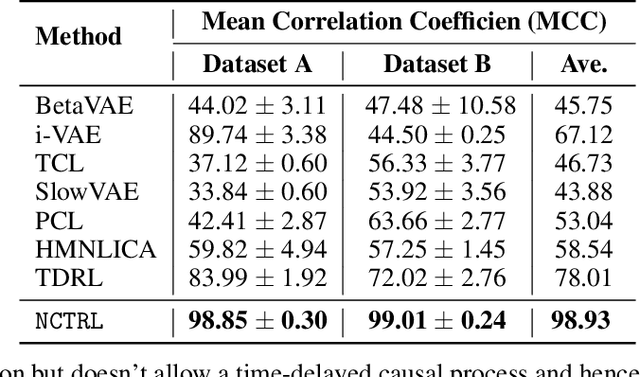
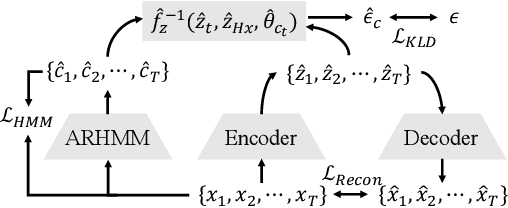
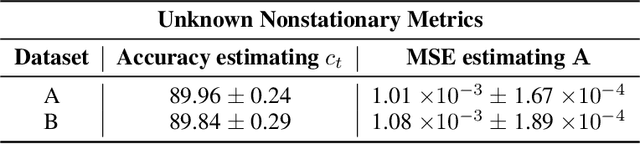
In unsupervised causal representation learning for sequential data with time-delayed latent causal influences, strong identifiability results for the disentanglement of causally-related latent variables have been established in stationary settings by leveraging temporal structure. However, in nonstationary setting, existing work only partially addressed the problem by either utilizing observed auxiliary variables (e.g., class labels and/or domain indexes) as side information or assuming simplified latent causal dynamics. Both constrain the method to a limited range of scenarios. In this study, we further explored the Markov Assumption under time-delayed causally related process in nonstationary setting and showed that under mild conditions, the independent latent components can be recovered from their nonlinear mixture up to a permutation and a component-wise transformation, without the observation of auxiliary variables. We then introduce NCTRL, a principled estimation framework, to reconstruct time-delayed latent causal variables and identify their relations from measured sequential data only. Empirical evaluations demonstrated the reliable identification of time-delayed latent causal influences, with our methodology substantially outperforming existing baselines that fail to exploit the nonstationarity adequately and then, consequently, cannot distinguish distribution shifts.
Subspace Identification for Multi-Source Domain Adaptation
Oct 07, 2023Multi-source domain adaptation (MSDA) methods aim to transfer knowledge from multiple labeled source domains to an unlabeled target domain. Although current methods achieve target joint distribution identifiability by enforcing minimal changes across domains, they often necessitate stringent conditions, such as an adequate number of domains, monotonic transformation of latent variables, and invariant label distributions. These requirements are challenging to satisfy in real-world applications. To mitigate the need for these strict assumptions, we propose a subspace identification theory that guarantees the disentanglement of domain-invariant and domain-specific variables under less restrictive constraints regarding domain numbers and transformation properties, thereby facilitating domain adaptation by minimizing the impact of domain shifts on invariant variables. Based on this theory, we develop a Subspace Identification Guarantee (SIG) model that leverages variational inference. Furthermore, the SIG model incorporates class-aware conditional alignment to accommodate target shifts where label distributions change with the domains. Experimental results demonstrate that our SIG model outperforms existing MSDA techniques on various benchmark datasets, highlighting its effectiveness in real-world applications.