 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnze Xie
DriveCoT: Integrating Chain-of-Thought Reasoning with End-to-End Driving
Mar 25, 2024
End-to-end driving has made significant progress in recent years, demonstrating benefits such as system simplicity and competitive driving performance under both open-loop and closed-loop settings. Nevertheless, the lack of interpretability and controllability in its driving decisions hinders real-world deployment for end-to-end driving systems. In this paper, we collect a comprehensive end-to-end driving dataset named DriveCoT, leveraging the CARLA simulator. It contains sensor data, control decisions, and chain-of-thought labels to indicate the reasoning process. We utilize the challenging driving scenarios from the CARLA leaderboard 2.0, which involve high-speed driving and lane-changing, and propose a rule-based expert policy to control the vehicle and generate ground truth labels for its reasoning process across different driving aspects and the final decisions. This dataset can serve as an open-loop end-to-end driving benchmark, enabling the evaluation of accuracy in various chain-of-thought aspects and the final decision. In addition, we propose a baseline model called DriveCoT-Agent, trained on our dataset, to generate chain-of-thought predictions and final decisions. The trained model exhibits strong performance in both open-loop and closed-loop evaluations, demonstrating the effectiveness of our proposed dataset.
Editing Massive Concepts in Text-to-Image Diffusion Models
Mar 20, 2024

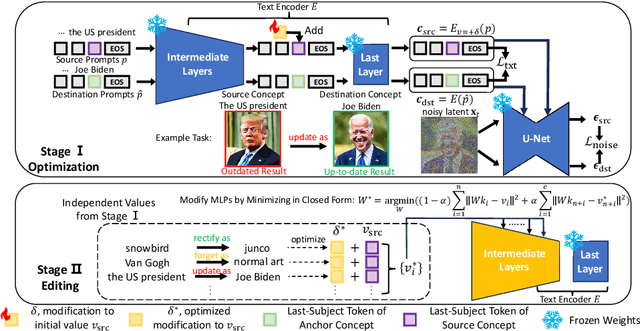
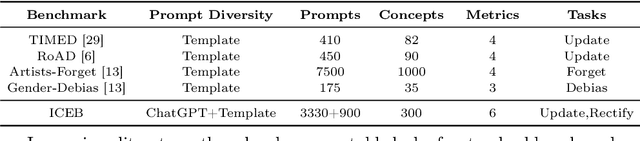
Text-to-image diffusion models suffer from the risk of generating outdated, copyrighted, incorrect, and biased content. While previous methods have mitigated the issues on a small scale, it is essential to handle them simultaneously in larger-scale real-world scenarios. We propose a two-stage method, Editing Massive Concepts In Diffusion Models (EMCID). The first stage performs memory optimization for each individual concept with dual self-distillation from text alignment loss and diffusion noise prediction loss. The second stage conducts massive concept editing with multi-layer, closed form model editing. We further propose a comprehensive benchmark, named ImageNet Concept Editing Benchmark (ICEB), for evaluating massive concept editing for T2I models with two subtasks, free-form prompts, massive concept categories, and extensive evaluation metrics. Extensive experiments conducted on our proposed benchmark and previous benchmarks demonstrate the superior scalability of EMCID for editing up to 1,000 concepts, providing a practical approach for fast adjustment and re-deployment of T2I diffusion models in real-world applications.
TextBlockV2: Towards Precise-Detection-Free Scene Text Spotting with Pre-trained Language Model
Mar 15, 2024
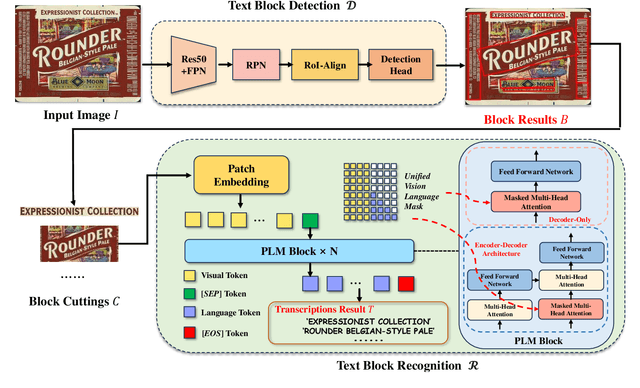
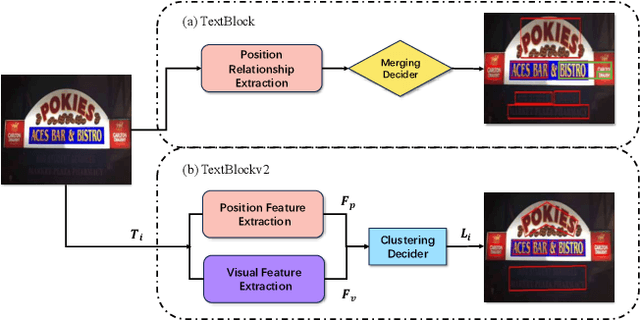
Existing scene text spotters are designed to locate and transcribe texts from images. However, it is challenging for a spotter to achieve precise detection and recognition of scene texts simultaneously. Inspired by the glimpse-focus spotting pipeline of human beings and impressive performances of Pre-trained Language Models (PLMs) on visual tasks, we ask: 1) "Can machines spot texts without precise detection just like human beings?", and if yes, 2) "Is text block another alternative for scene text spotting other than word or character?" To this end, our proposed scene text spotter leverages advanced PLMs to enhance performance without fine-grained detection. Specifically, we first use a simple detector for block-level text detection to obtain rough positional information. Then, we finetune a PLM using a large-scale OCR dataset to achieve accurate recognition. Benefiting from the comprehensive language knowledge gained during the pre-training phase, the PLM-based recognition module effectively handles complex scenarios, including multi-line, reversed, occluded, and incomplete-detection texts. Taking advantage of the fine-tuned language model on scene recognition benchmarks and the paradigm of text block detection, extensive experiments demonstrate the superior performance of our scene text spotter across multiple public benchmarks. Additionally, we attempt to spot texts directly from an entire scene image to demonstrate the potential of PLMs, even Large Language Models (LLMs).
PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
Mar 07, 2024
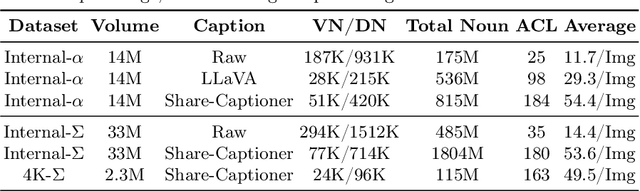


In this paper, we introduce PixArt-\Sigma, a Diffusion Transformer model~(DiT) capable of directly generating images at 4K resolution. PixArt-\Sigma represents a significant advancement over its predecessor, PixArt-\alpha, offering images of markedly higher fidelity and improved alignment with text prompts. A key feature of PixArt-\Sigma is its training efficiency. Leveraging the foundational pre-training of PixArt-\alpha, it evolves from the `weaker' baseline to a `stronger' model via incorporating higher quality data, a process we term "weak-to-strong training". The advancements in PixArt-\Sigma are twofold: (1) High-Quality Training Data: PixArt-\Sigma incorporates superior-quality image data, paired with more precise and detailed image captions. (2) Efficient Token Compression: we propose a novel attention module within the DiT framework that compresses both keys and values, significantly improving efficiency and facilitating ultra-high-resolution image generation. Thanks to these improvements, PixArt-\Sigma achieves superior image quality and user prompt adherence capabilities with significantly smaller model size (0.6B parameters) than existing text-to-image diffusion models, such as SDXL (2.6B parameters) and SD Cascade (5.1B parameters). Moreover, PixArt-\Sigma's capability to generate 4K images supports the creation of high-resolution posters and wallpapers, efficiently bolstering the production of high-quality visual content in industries such as film and gaming.
Accelerating Diffusion Sampling with Optimized Time Steps
Feb 27, 2024Diffusion probabilistic models (DPMs) have shown remarkable performance in high-resolution image synthesis, but their sampling efficiency is still to be desired due to the typically large number of sampling steps. Recent advancements in high-order numerical ODE solvers for DPMs have enabled the generation of high-quality images with much fewer sampling steps. While this is a significant development, most sampling methods still employ uniform time steps, which is not optimal when using a small number of steps. To address this issue, we propose a general framework for designing an optimization problem that seeks more appropriate time steps for a specific numerical ODE solver for DPMs. This optimization problem aims to minimize the distance between the ground-truth solution to the ODE and an approximate solution corresponding to the numerical solver. It can be efficiently solved using the constrained trust region method, taking less than $15$ seconds. Our extensive experiments on both unconditional and conditional sampling using pixel- and latent-space DPMs demonstrate that, when combined with the state-of-the-art sampling method UniPC, our optimized time steps significantly improve image generation performance in terms of FID scores for datasets such as CIFAR-10 and ImageNet, compared to using uniform time steps.
On the Expressive Power of a Variant of the Looped Transformer
Feb 21, 2024Besides natural language processing, transformers exhibit extraordinary performance in solving broader applications, including scientific computing and computer vision. Previous works try to explain this from the expressive power and capability perspectives that standard transformers are capable of performing some algorithms. To empower transformers with algorithmic capabilities and motivated by the recently proposed looped transformer (Yang et al., 2024; Giannou et al., 2023), we design a novel transformer block, dubbed Algorithm Transformer (abbreviated as AlgoFormer). Compared with the standard transformer and vanilla looped transformer, the proposed AlgoFormer can achieve significantly higher expressiveness in algorithm representation when using the same number of parameters. In particular, inspired by the structure of human-designed learning algorithms, our transformer block consists of a pre-transformer that is responsible for task pre-processing, a looped transformer for iterative optimization algorithms, and a post-transformer for producing the desired results after post-processing. We provide theoretical evidence of the expressive power of the AlgoFormer in solving some challenging problems, mirroring human-designed algorithms. Furthermore, some theoretical and empirical results are presented to show that the designed transformer has the potential to be smarter than human-designed algorithms. Experimental results demonstrate the empirical superiority of the proposed transformer in that it outperforms the standard transformer and vanilla looped transformer in some challenging tasks.
Divide and Conquer: Language Models can Plan and Self-Correct for Compositional Text-to-Image Generation
Jan 30, 2024Despite significant advancements in text-to-image models for generating high-quality images, these methods still struggle to ensure the controllability of text prompts over images in the context of complex text prompts, especially when it comes to retaining object attributes and relationships. In this paper, we propose CompAgent, a training-free approach for compositional text-to-image generation, with a large language model (LLM) agent as its core. The fundamental idea underlying CompAgent is premised on a divide-and-conquer methodology. Given a complex text prompt containing multiple concepts including objects, attributes, and relationships, the LLM agent initially decomposes it, which entails the extraction of individual objects, their associated attributes, and the prediction of a coherent scene layout. These individual objects can then be independently conquered. Subsequently, the agent performs reasoning by analyzing the text, plans and employs the tools to compose these isolated objects. The verification and human feedback mechanism is finally incorporated into our agent to further correct the potential attribute errors and refine the generated images. Guided by the LLM agent, we propose a tuning-free multi-concept customization model and a layout-to-image generation model as the tools for concept composition, and a local image editing method as the tool to interact with the agent for verification. The scene layout controls the image generation process among these tools to prevent confusion among multiple objects. Extensive experiments demonstrate the superiority of our approach for compositional text-to-image generation: CompAgent achieves more than 10\% improvement on T2I-CompBench, a comprehensive benchmark for open-world compositional T2I generation. The extension to various related tasks also illustrates the flexibility of our CompAgent for potential applications.
CustomVideo: Customizing Text-to-Video Generation with Multiple Subjects
Jan 18, 2024Customized text-to-video generation aims to generate high-quality videos guided by text prompts and subject references. Current approaches designed for single subjects suffer from tackling multiple subjects, which is a more challenging and practical scenario. In this work, we aim to promote multi-subject guided text-to-video customization. We propose CustomVideo, a novel framework that can generate identity-preserving videos with the guidance of multiple subjects. To be specific, firstly, we encourage the co-occurrence of multiple subjects via composing them in a single image. Further, upon a basic text-to-video diffusion model, we design a simple yet effective attention control strategy to disentangle different subjects in the latent space of diffusion model. Moreover, to help the model focus on the specific object area, we segment the object from given reference images and provide a corresponding object mask for attention learning. Also, we collect a multi-subject text-to-video generation dataset as a comprehensive benchmark, with 69 individual subjects and 57 meaningful pairs. Extensive qualitative, quantitative, and user study results demonstrate the superiority of our method, compared with the previous state-of-the-art approaches.
PIXART-δ: Fast and Controllable Image Generation with Latent Consistency Models
Jan 10, 2024This technical report introduces PIXART-{\delta}, a text-to-image synthesis framework that integrates the Latent Consistency Model (LCM) and ControlNet into the advanced PIXART-{\alpha} model. PIXART-{\alpha} is recognized for its ability to generate high-quality images of 1024px resolution through a remarkably efficient training process. The integration of LCM in PIXART-{\delta} significantly accelerates the inference speed, enabling the production of high-quality images in just 2-4 steps. Notably, PIXART-{\delta} achieves a breakthrough 0.5 seconds for generating 1024x1024 pixel images, marking a 7x improvement over the PIXART-{\alpha}. Additionally, PIXART-{\delta} is designed to be efficiently trainable on 32GB V100 GPUs within a single day. With its 8-bit inference capability (von Platen et al., 2023), PIXART-{\delta} can synthesize 1024px images within 8GB GPU memory constraints, greatly enhancing its usability and accessibility. Furthermore, incorporating a ControlNet-like module enables fine-grained control over text-to-image diffusion models. We introduce a novel ControlNet-Transformer architecture, specifically tailored for Transformers, achieving explicit controllability alongside high-quality image generation. As a state-of-the-art, open-source image generation model, PIXART-{\delta} offers a promising alternative to the Stable Diffusion family of models, contributing significantly to text-to-image synthesis.
A Survey of Reasoning with Foundation Models
Dec 26, 2023Reasoning, a crucial ability for complex problem-solving, plays a pivotal role in various real-world settings such as negotiation, medical diagnosis, and criminal investigation. It serves as a fundamental methodology in the field of Artificial General Intelligence (AGI). With the ongoing development of foundation models, there is a growing interest in exploring their abilities in reasoning tasks. In this paper, we introduce seminal foundation models proposed or adaptable for reasoning, highlighting the latest advancements in various reasoning tasks, methods, and benchmarks. We then delve into the potential future directions behind the emergence of reasoning abilities within foundation models. We also discuss the relevance of multimodal learning, autonomous agents, and super alignment in the context of reasoning. By discussing these future research directions, we hope to inspire researchers in their exploration of this field, stimulate further advancements in reasoning with foundation models, and contribute to the development of AGI.