 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianqi Wang
DriveCoT: Integrating Chain-of-Thought Reasoning with End-to-End Driving
Mar 25, 2024
End-to-end driving has made significant progress in recent years, demonstrating benefits such as system simplicity and competitive driving performance under both open-loop and closed-loop settings. Nevertheless, the lack of interpretability and controllability in its driving decisions hinders real-world deployment for end-to-end driving systems. In this paper, we collect a comprehensive end-to-end driving dataset named DriveCoT, leveraging the CARLA simulator. It contains sensor data, control decisions, and chain-of-thought labels to indicate the reasoning process. We utilize the challenging driving scenarios from the CARLA leaderboard 2.0, which involve high-speed driving and lane-changing, and propose a rule-based expert policy to control the vehicle and generate ground truth labels for its reasoning process across different driving aspects and the final decisions. This dataset can serve as an open-loop end-to-end driving benchmark, enabling the evaluation of accuracy in various chain-of-thought aspects and the final decision. In addition, we propose a baseline model called DriveCoT-Agent, trained on our dataset, to generate chain-of-thought predictions and final decisions. The trained model exhibits strong performance in both open-loop and closed-loop evaluations, demonstrating the effectiveness of our proposed dataset.
LiMAML: Personalization of Deep Recommender Models via Meta Learning
Feb 23, 2024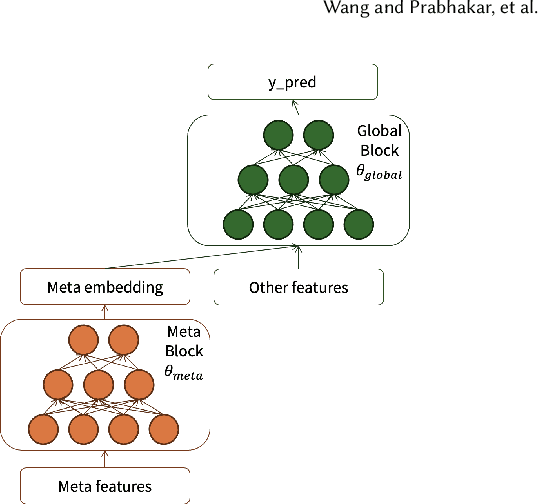

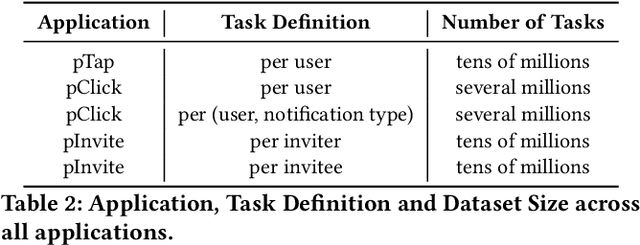

In the realm of recommender systems, the ubiquitous adoption of deep neural networks has emerged as a dominant paradigm for modeling diverse business objectives. As user bases continue to expand, the necessity of personalization and frequent model updates have assumed paramount significance to ensure the delivery of relevant and refreshed experiences to a diverse array of members. In this work, we introduce an innovative meta-learning solution tailored to the personalization of models for individual members and other entities, coupled with the frequent updates based on the latest user interaction signals. Specifically, we leverage the Model-Agnostic Meta Learning (MAML) algorithm to adapt per-task sub-networks using recent user interaction data. Given the near infeasibility of productionizing original MAML-based models in online recommendation systems, we propose an efficient strategy to operationalize meta-learned sub-networks in production, which involves transforming them into fixed-sized vectors, termed meta embeddings, thereby enabling the seamless deployment of models with hundreds of billions of parameters for online serving. Through extensive experimentation on production data drawn from various applications at LinkedIn, we demonstrate that the proposed solution consistently outperforms the baseline models of those applications, including strong baselines such as using wide-and-deep ID based personalization approach. Our approach has enabled the deployment of a range of highly personalized AI models across diverse LinkedIn applications, leading to substantial improvements in business metrics as well as refreshed experience for our members.
Towards Continual Learning Desiderata via HSIC-Bottleneck Orthogonalization and Equiangular Embedding
Jan 17, 2024Deep neural networks are susceptible to catastrophic forgetting when trained on sequential tasks. Various continual learning (CL) methods often rely on exemplar buffers or/and network expansion for balancing model stability and plasticity, which, however, compromises their practical value due to privacy and memory concerns. Instead, this paper considers a strict yet realistic setting, where the training data from previous tasks is unavailable and the model size remains relatively constant during sequential training. To achieve such desiderata, we propose a conceptually simple yet effective method that attributes forgetting to layer-wise parameter overwriting and the resulting decision boundary distortion. This is achieved by the synergy between two key components: HSIC-Bottleneck Orthogonalization (HBO) implements non-overwritten parameter updates mediated by Hilbert-Schmidt independence criterion in an orthogonal space and EquiAngular Embedding (EAE) enhances decision boundary adaptation between old and new tasks with predefined basis vectors. Extensive experiments demonstrate that our method achieves competitive accuracy performance, even with absolute superiority of zero exemplar buffer and 1.02x the base model.
AccidentGPT: Accident Analysis and Prevention from V2X Environmental Perception with Multi-modal Large Model
Dec 29, 2023Traffic accidents, being a significant contributor to both human casualties and property damage, have long been a focal point of research for many scholars in the field of traffic safety. However, previous studies, whether focusing on static environmental assessments or dynamic driving analyses, as well as pre-accident predictions or post-accident rule analyses, have typically been conducted in isolation. There has been a lack of an effective framework for developing a comprehensive understanding and application of traffic safety. To address this gap, this paper introduces AccidentGPT, a comprehensive accident analysis and prevention multi-modal large model. AccidentGPT establishes a multi-modal information interaction framework grounded in multi-sensor perception, thereby enabling a holistic approach to accident analysis and prevention in the field of traffic safety. Specifically, our capabilities can be categorized as follows: for autonomous driving vehicles, we provide comprehensive environmental perception and understanding to control the vehicle and avoid collisions. For human-driven vehicles, we offer proactive long-range safety warnings and blind-spot alerts while also providing safety driving recommendations and behavioral norms through human-machine dialogue and interaction. Additionally, for traffic police and management agencies, our framework supports intelligent and real-time analysis of traffic safety, encompassing pedestrian, vehicles, roads, and the environment through collaborative perception from multiple vehicles and road testing devices. The system is also capable of providing a thorough analysis of accident causes and liability after vehicle collisions. Our framework stands as the first large model to integrate comprehensive scene understanding into traffic safety studies. Project page: https://accidentgpt.github.io
IF2Net: Innately Forgetting-Free Networks for Continual Learning
Jun 18, 2023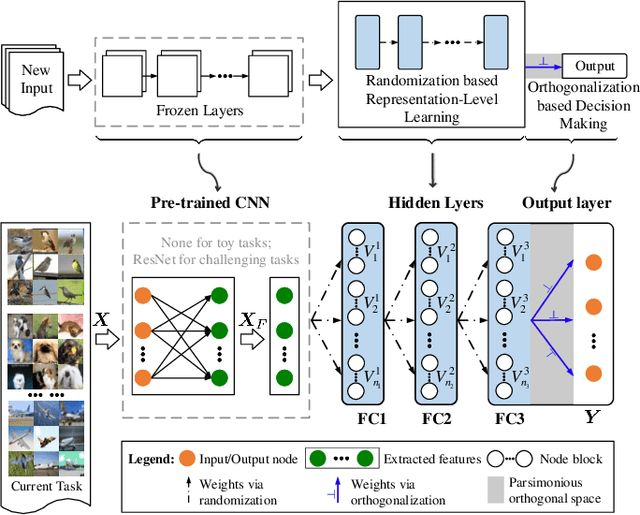
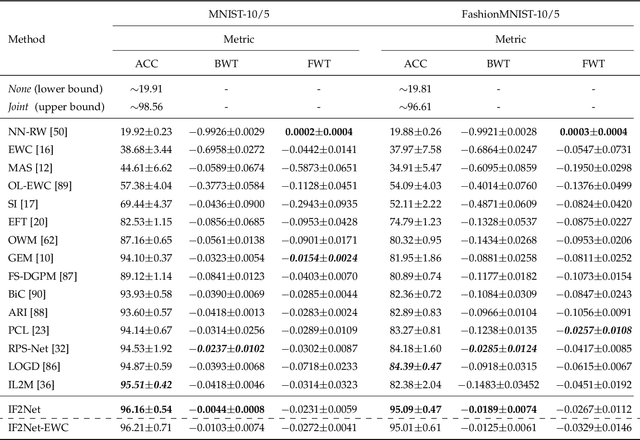
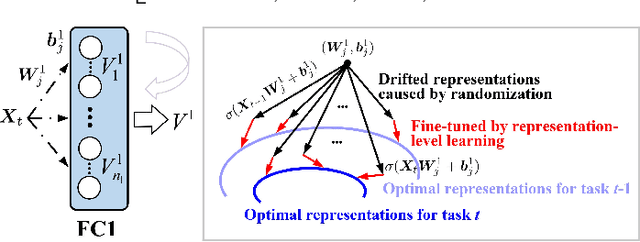
Continual learning can incrementally absorb new concepts without interfering with previously learned knowledge. Motivated by the characteristics of neural networks, in which information is stored in weights on connections, we investigated how to design an Innately Forgetting-Free Network (IF2Net) for continual learning context. This study proposed a straightforward yet effective learning paradigm by ingeniously keeping the weights relative to each seen task untouched before and after learning a new task. We first presented the novel representation-level learning on task sequences with random weights. This technique refers to tweaking the drifted representations caused by randomization back to their separate task-optimal working states, but the involved weights are frozen and reused (opposite to well-known layer-wise updates of weights). Then, sequential decision-making without forgetting can be achieved by projecting the output weight updates into the parsimonious orthogonal space, making the adaptations not disturb old knowledge while maintaining model plasticity. IF2Net allows a single network to inherently learn unlimited mapping rules without telling task identities at test time by integrating the respective strengths of randomization and orthogonalization. We validated the effectiveness of our approach in the extensive theoretical analysis and empirical study.
Multi-View Class Incremental Learning
Jun 16, 2023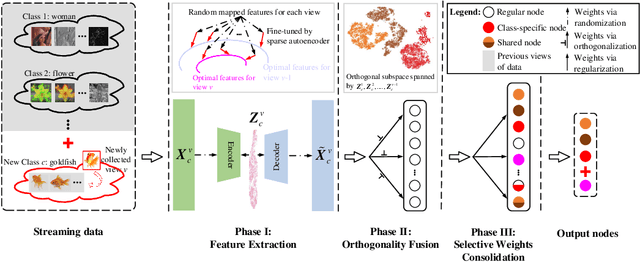
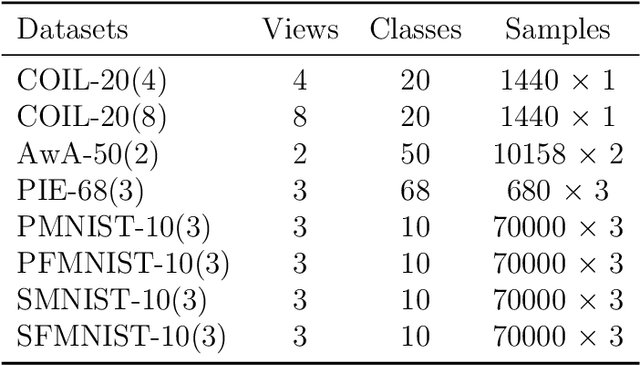
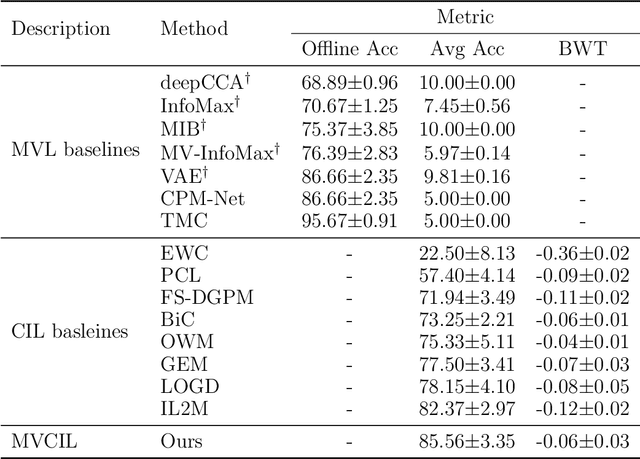
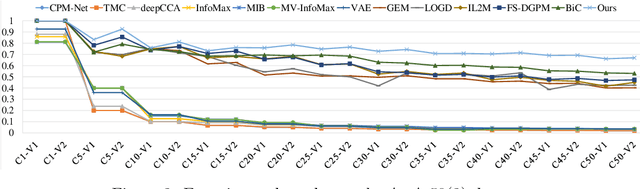
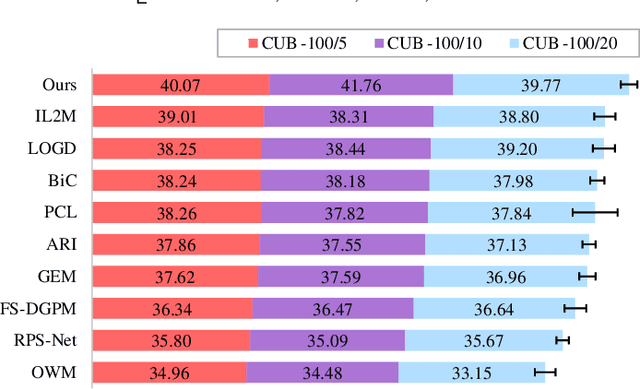
Multi-view learning (MVL) has gained great success in integrating information from multiple perspectives of a dataset to improve downstream task performance. To make MVL methods more practical in an open-ended environment, this paper investigates a novel paradigm called multi-view class incremental learning (MVCIL), where a single model incrementally classifies new classes from a continual stream of views, requiring no access to earlier views of data. However, MVCIL is challenged by the catastrophic forgetting of old information and the interference with learning new concepts. To address this, we first develop a randomization-based representation learning technique serving for feature extraction to guarantee their separate view-optimal working states, during which multiple views belonging to a class are presented sequentially; Then, we integrate them one by one in the orthogonality fusion subspace spanned by the extracted features; Finally, we introduce selective weight consolidation for learning-without-forgetting decision-making while encountering new classes. Extensive experiments on synthetic and real-world datasets validate the effectiveness of our approach.
DeepAccident: A Motion and Accident Prediction Benchmark for V2X Autonomous Driving
Apr 10, 2023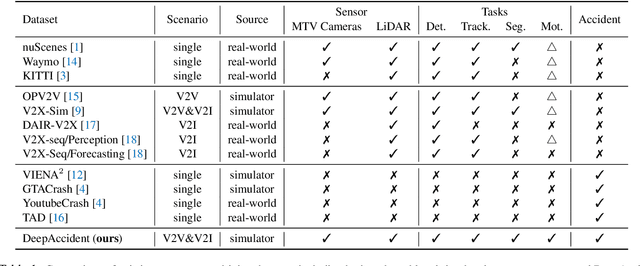



Safety is the primary priority of autonomous driving. Nevertheless, no published dataset currently supports the direct and explainable safety evaluation for autonomous driving. In this work, we propose DeepAccident, a large-scale dataset generated via a realistic simulator containing diverse accident scenarios that frequently occur in real-world driving. The proposed DeepAccident dataset contains 57K annotated frames and 285K annotated samples, approximately 7 times more than the large-scale nuScenes dataset with 40k annotated samples. In addition, we propose a new task, end-to-end motion and accident prediction, based on the proposed dataset, which can be used to directly evaluate the accident prediction ability for different autonomous driving algorithms. Furthermore, for each scenario, we set four vehicles along with one infrastructure to record data, thus providing diverse viewpoints for accident scenarios and enabling V2X (vehicle-to-everything) research on perception and prediction tasks. Finally, we present a baseline V2X model named V2XFormer that demonstrates superior performance for motion and accident prediction and 3D object detection compared to the single-vehicle model.
Fast-BEV: Towards Real-time On-vehicle Bird's-Eye View Perception
Jan 19, 2023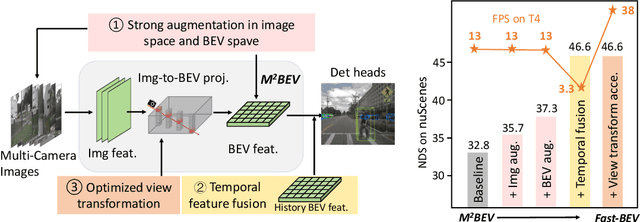
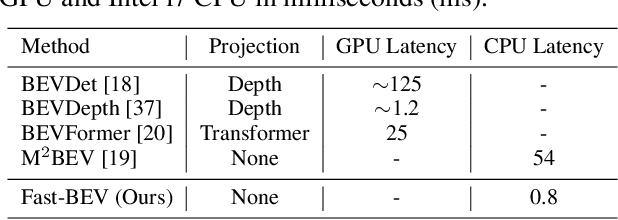
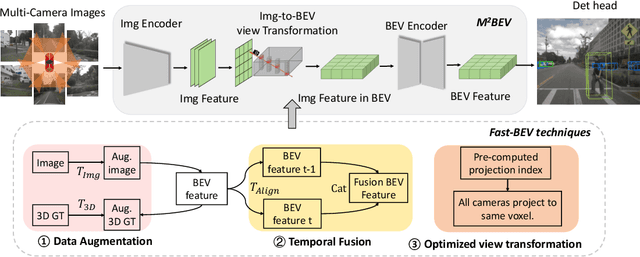
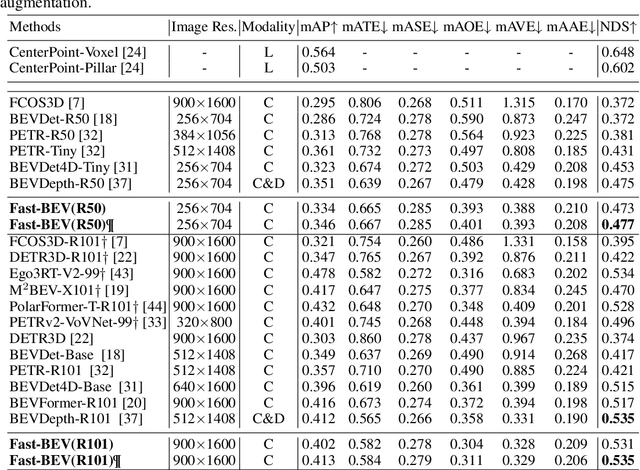
Recently, the pure camera-based Bird's-Eye-View (BEV) perception removes expensive Lidar sensors, making it a feasible solution for economical autonomous driving. However, most existing BEV solutions either suffer from modest performance or require considerable resources to execute on-vehicle inference. This paper proposes a simple yet effective framework, termed Fast-BEV, which is capable of performing real-time BEV perception on the on-vehicle chips. Towards this goal, we first empirically find that the BEV representation can be sufficiently powerful without expensive view transformation or depth representation. Starting from M2BEV baseline, we further introduce (1) a strong data augmentation strategy for both image and BEV space to avoid over-fitting (2) a multi-frame feature fusion mechanism to leverage the temporal information (3) an optimized deployment-friendly view transformation to speed up the inference. Through experiments, we show Fast-BEV model family achieves considerable accuracy and efficiency on edge. In particular, our M1 model (R18@256x704) can run over 50FPS on the Tesla T4 platform, with 47.0% NDS on the nuScenes validation set. Our largest model (R101@900x1600) establishes a new state-of-the-art 53.5% NDS on the nuScenes validation set. The code is released at: https://github.com/Sense-GVT/Fast-BEV.
* Accepted by NeurIPS2022_ML4AD on October 22, 2022
Scale-Equivalent Distillation for Semi-Supervised Object Detection
Mar 26, 2022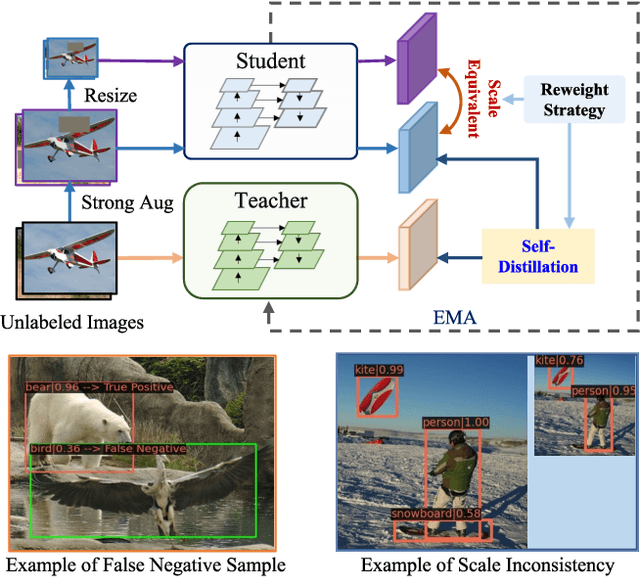
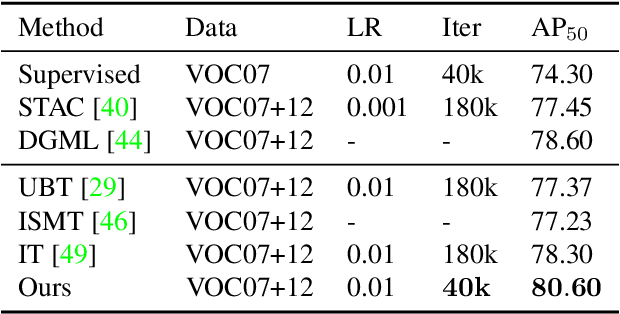
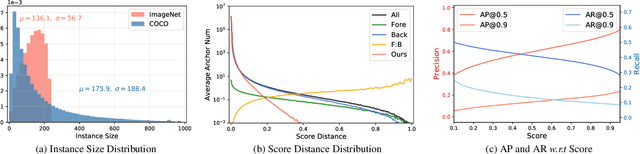
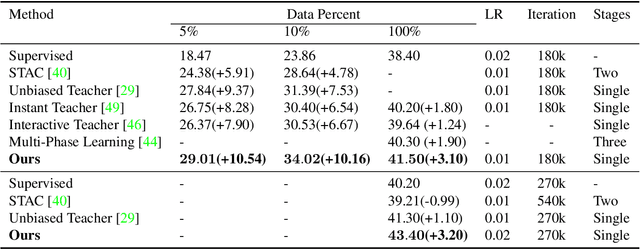
Recent Semi-Supervised Object Detection (SS-OD) methods are mainly based on self-training, i.e., generating hard pseudo-labels by a teacher model on unlabeled data as supervisory signals. Although they achieved certain success, the limited labeled data in semi-supervised learning scales up the challenges of object detection. We analyze the challenges these methods meet with the empirical experiment results. We find that the massive False Negative samples and inferior localization precision lack consideration. Besides, the large variance of object sizes and class imbalance (i.e., the extreme ratio between background and object) hinder the performance of prior arts. Further, we overcome these challenges by introducing a novel approach, Scale-Equivalent Distillation (SED), which is a simple yet effective end-to-end knowledge distillation framework robust to large object size variance and class imbalance. SED has several appealing benefits compared to the previous works. (1) SED imposes a consistency regularization to handle the large scale variance problem. (2) SED alleviates the noise problem from the False Negative samples and inferior localization precision. (3) A re-weighting strategy can implicitly screen the potential foreground regions of the unlabeled data to reduce the effect of class imbalance. Extensive experiments show that SED consistently outperforms the recent state-of-the-art methods on different datasets with significant margins. For example, it surpasses the supervised counterpart by more than 10 mAP when using 5% and 10% labeled data on MS-COCO.
Clutter Edges Detection Algorithms for Structured Clutter Covariance Matrices
Feb 03, 2022
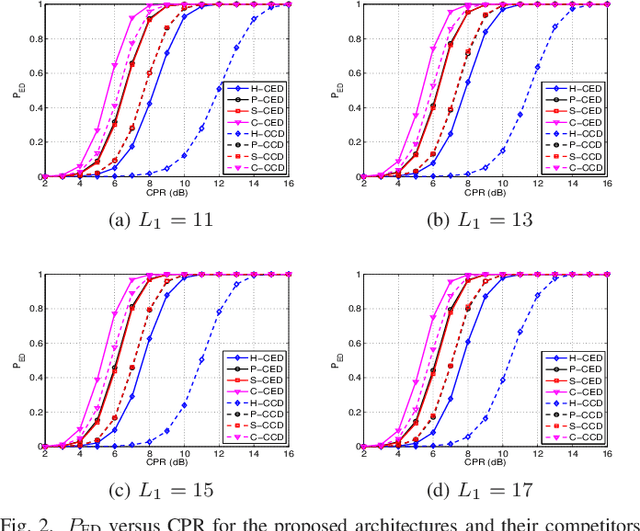
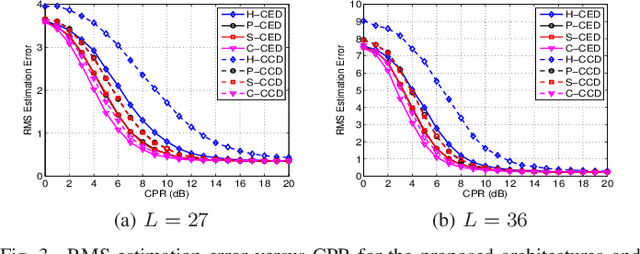
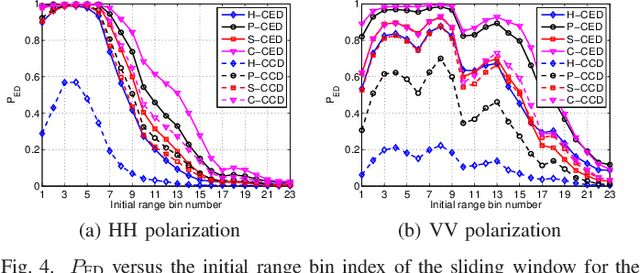
This letter deals with the problem of clutter edge detection and localization in training data. To this end, the problem is formulated as a binary hypothesis test assuming that the ranks of the clutter covariance matrix are known, and adaptive architectures are designed based on the generalized likelihood ratio test to decide whether the training data within a sliding window contains a homogeneous set or two heterogeneous subsets. In the design stage, we utilize four different covariance matrix structures (i.e., Hermitian, persymmetric, symmetric, and centrosymmetric) to exploit the a priori information. Then, for the case of unknown ranks, the architectures are extended by devising a preliminary estimation stage resorting to the model order selection rules. Numerical examples based on both synthetic and real data highlight that the proposed solutions possess superior detection and localization performance with respect to the competitors that do not use any a priori information.