 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuofan Wang
LiMAML: Personalization of Deep Recommender Models via Meta Learning
Feb 23, 2024
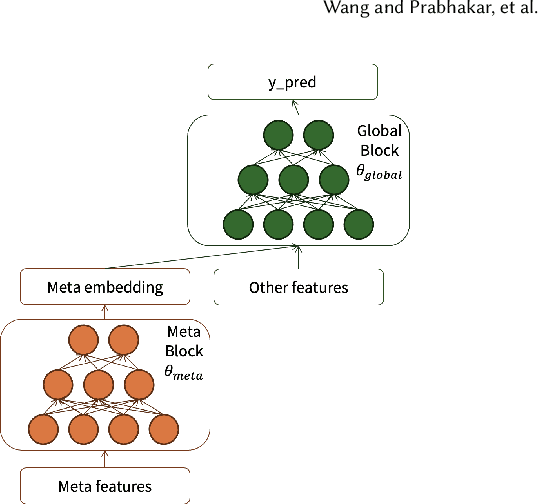

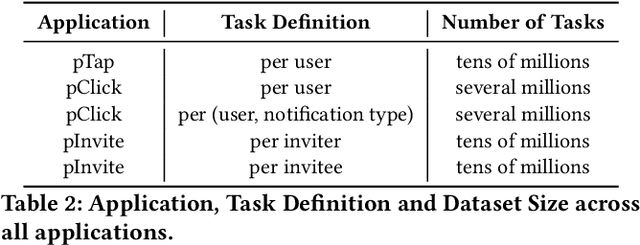

In the realm of recommender systems, the ubiquitous adoption of deep neural networks has emerged as a dominant paradigm for modeling diverse business objectives. As user bases continue to expand, the necessity of personalization and frequent model updates have assumed paramount significance to ensure the delivery of relevant and refreshed experiences to a diverse array of members. In this work, we introduce an innovative meta-learning solution tailored to the personalization of models for individual members and other entities, coupled with the frequent updates based on the latest user interaction signals. Specifically, we leverage the Model-Agnostic Meta Learning (MAML) algorithm to adapt per-task sub-networks using recent user interaction data. Given the near infeasibility of productionizing original MAML-based models in online recommendation systems, we propose an efficient strategy to operationalize meta-learned sub-networks in production, which involves transforming them into fixed-sized vectors, termed meta embeddings, thereby enabling the seamless deployment of models with hundreds of billions of parameters for online serving. Through extensive experimentation on production data drawn from various applications at LinkedIn, we demonstrate that the proposed solution consistently outperforms the baseline models of those applications, including strong baselines such as using wide-and-deep ID based personalization approach. Our approach has enabled the deployment of a range of highly personalized AI models across diverse LinkedIn applications, leading to substantial improvements in business metrics as well as refreshed experience for our members.
Understanding Time Series Anomaly State Detection through One-Class Classification
Feb 03, 2024For a long time, research on time series anomaly detection has mainly focused on finding outliers within a given time series. Admittedly, this is consistent with some practical problems, but in other practical application scenarios, people are concerned about: assuming a standard time series is given, how to judge whether another test time series deviates from the standard time series, which is more similar to the problem discussed in one-class classification (OCC). Therefore, in this article, we try to re-understand and define the time series anomaly detection problem through OCC, which we call 'time series anomaly state detection problem'. We first use stochastic processes and hypothesis testing to strictly define the 'time series anomaly state detection problem', and its corresponding anomalies. Then, we use the time series classification dataset to construct an artificial dataset corresponding to the problem. We compile 38 anomaly detection algorithms and correct some of the algorithms to adapt to handle this problem. Finally, through a large number of experiments, we fairly compare the actual performance of various time series anomaly detection algorithms, providing insights and directions for future research by researchers.