 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMauricio Reyes
A Robust Ensemble Algorithm for Ischemic Stroke Lesion Segmentation: Generalizability and Clinical Utility Beyond the ISLES Challenge
Apr 03, 2024
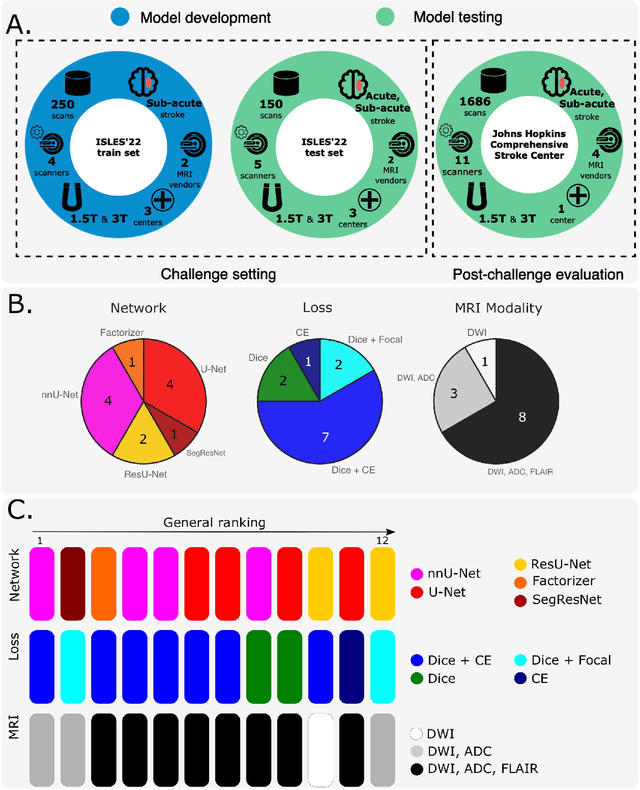
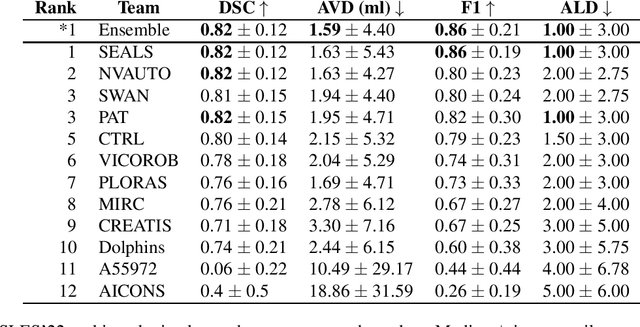
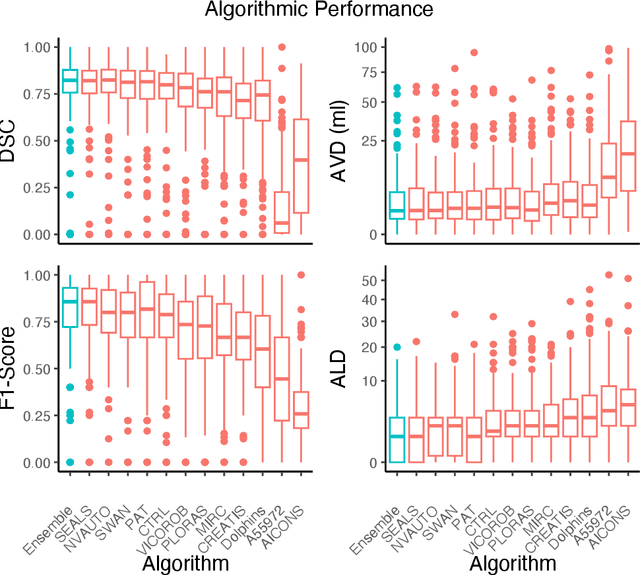
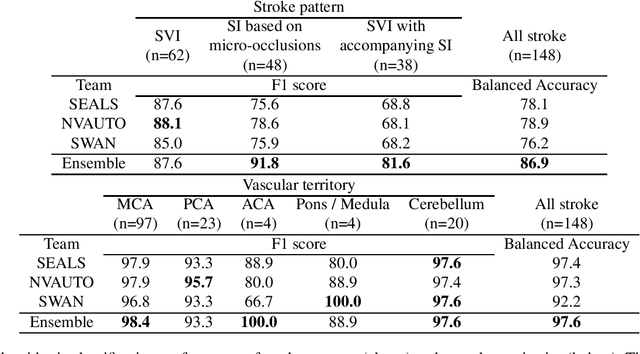
Diffusion-weighted MRI (DWI) is essential for stroke diagnosis, treatment decisions, and prognosis. However, image and disease variability hinder the development of generalizable AI algorithms with clinical value. We address this gap by presenting a novel ensemble algorithm derived from the 2022 Ischemic Stroke Lesion Segmentation (ISLES) challenge. ISLES'22 provided 400 patient scans with ischemic stroke from various medical centers, facilitating the development of a wide range of cutting-edge segmentation algorithms by the research community. Through collaboration with leading teams, we combined top-performing algorithms into an ensemble model that overcomes the limitations of individual solutions. Our ensemble model achieved superior ischemic lesion detection and segmentation accuracy on our internal test set compared to individual algorithms. This accuracy generalized well across diverse image and disease variables. Furthermore, the model excelled in extracting clinical biomarkers. Notably, in a Turing-like test, neuroradiologists consistently preferred the algorithm's segmentations over manual expert efforts, highlighting increased comprehensiveness and precision. Validation using a real-world external dataset (N=1686) confirmed the model's generalizability. The algorithm's outputs also demonstrated strong correlations with clinical scores (admission NIHSS and 90-day mRS) on par with or exceeding expert-derived results, underlining its clinical relevance. This study offers two key findings. First, we present an ensemble algorithm (https://github.com/Tabrisrei/ISLES22_Ensemble) that detects and segments ischemic stroke lesions on DWI across diverse scenarios on par with expert (neuro)radiologists. Second, we show the potential for biomedical challenge outputs to extend beyond the challenge's initial objectives, demonstrating their real-world clinical applicability.
MedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023


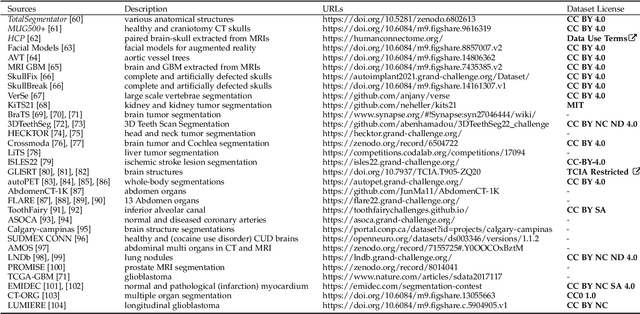
We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
Understanding metric-related pitfalls in image analysis validation
Feb 09, 2023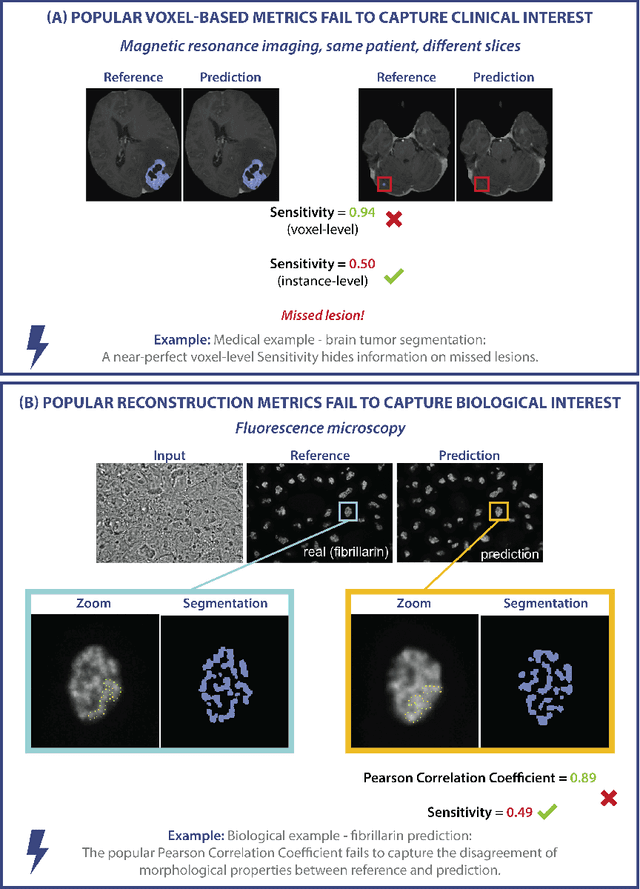
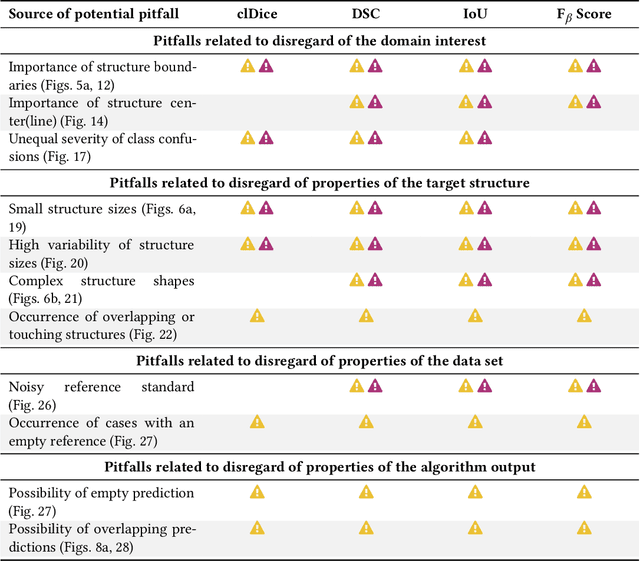

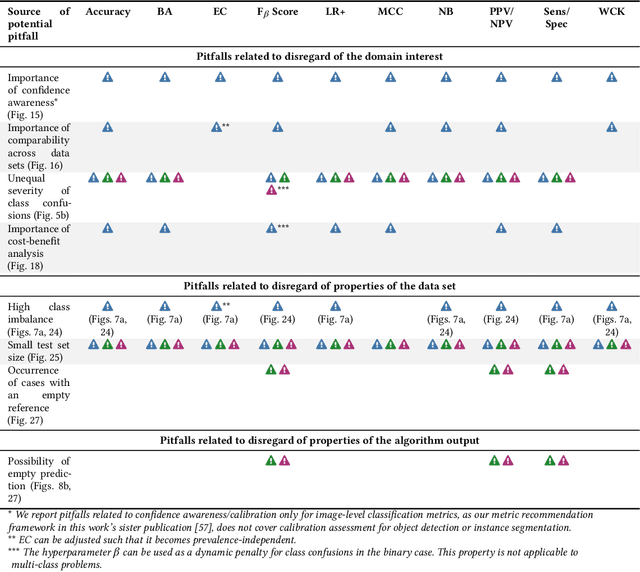
Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
ISLES 2022: A multi-center magnetic resonance imaging stroke lesion segmentation dataset
Jun 14, 2022
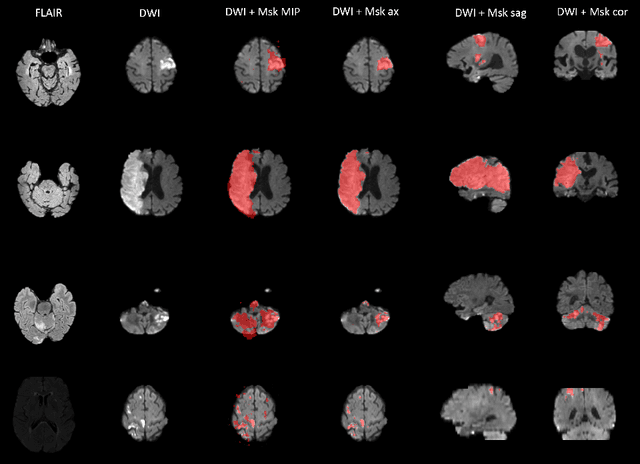

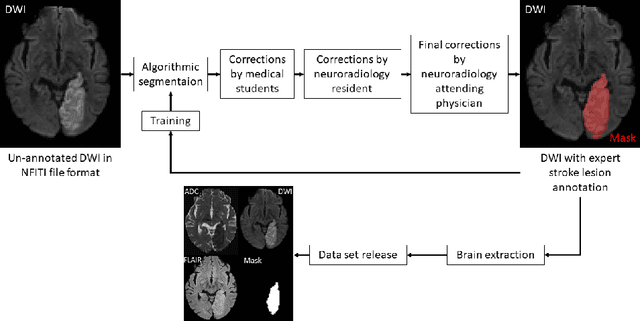
Magnetic resonance imaging (MRI) is a central modality for stroke imaging. It is used upon patient admission to make treatment decisions such as selecting patients for intravenous thrombolysis or endovascular therapy. MRI is later used in the duration of hospital stay to predict outcome by visualizing infarct core size and location. Furthermore, it may be used to characterize stroke etiology, e.g. differentiation between (cardio)-embolic and non-embolic stroke. Computer based automated medical image processing is increasingly finding its way into clinical routine. Previous iterations of the Ischemic Stroke Lesion Segmentation (ISLES) challenge have aided in the generation of identifying benchmark methods for acute and sub-acute ischemic stroke lesion segmentation. Here we introduce an expert-annotated, multicenter MRI dataset for segmentation of acute to subacute stroke lesions. This dataset comprises 400 multi-vendor MRI cases with high variability in stroke lesion size, quantity and location. It is split into a training dataset of n=250 and a test dataset of n=150. All training data will be made publicly available. The test dataset will be used for model validation only and will not be released to the public. This dataset serves as the foundation of the ISLES 2022 challenge with the goal of finding algorithmic methods to enable the development and benchmarking of robust and accurate segmentation algorithms for ischemic stroke.
Metrics reloaded: Pitfalls and recommendations for image analysis validation
Jun 03, 2022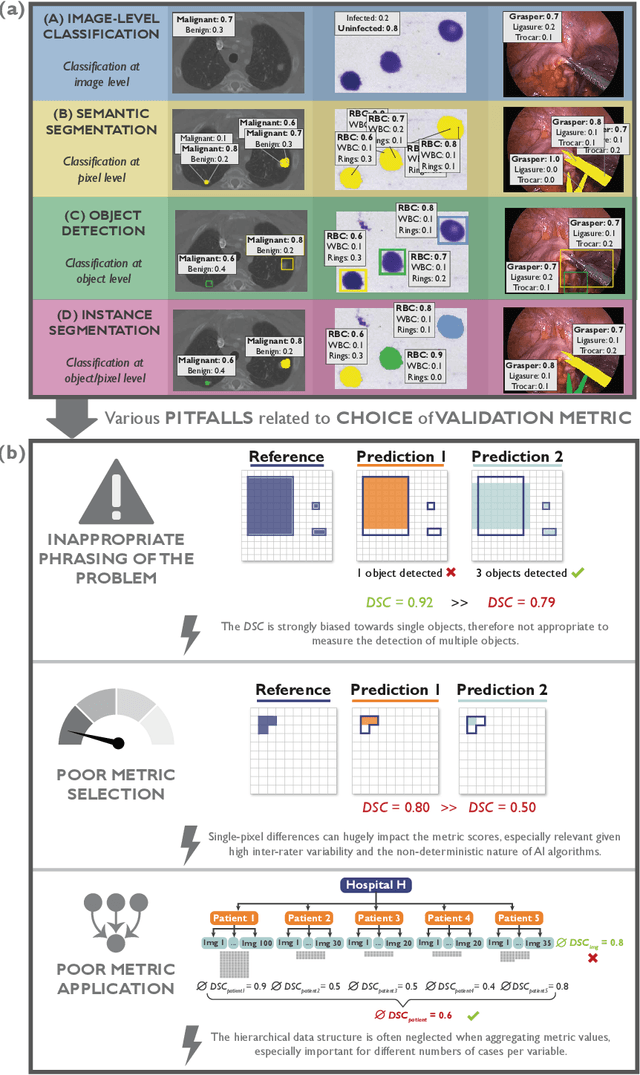
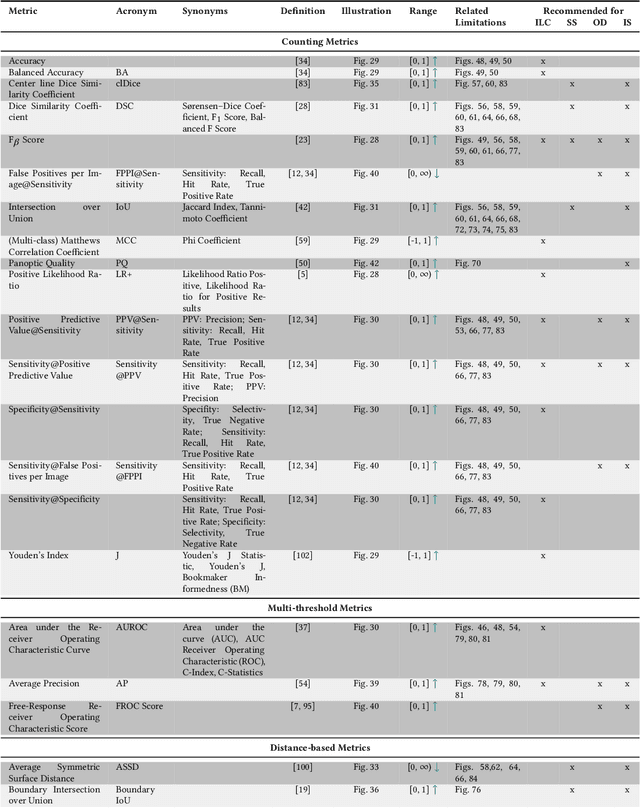
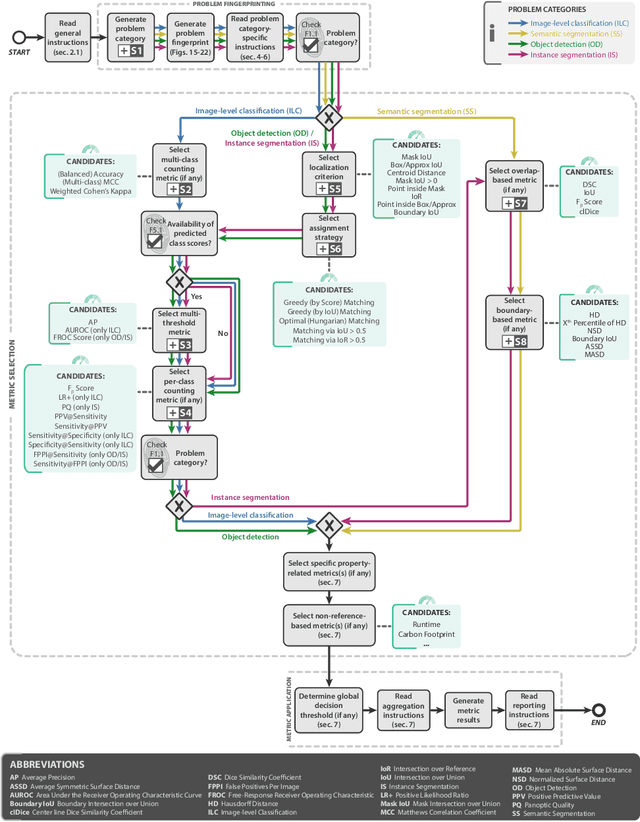
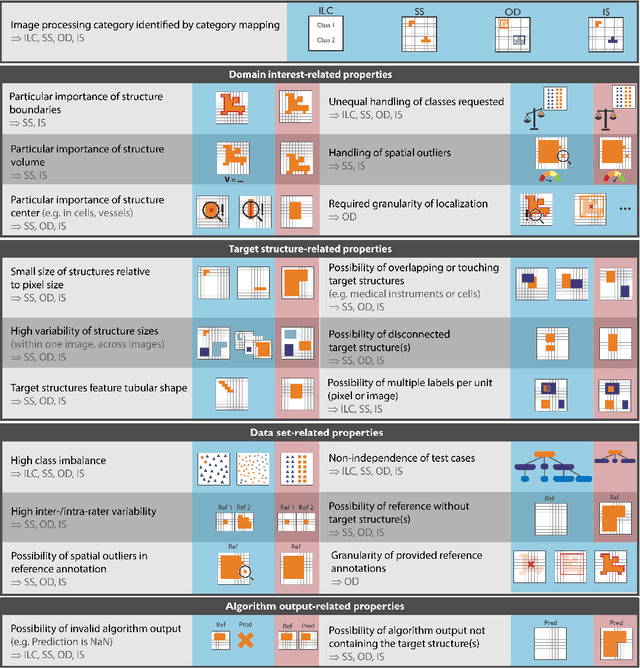
The field of automatic biomedical image analysis crucially depends on robust and meaningful performance metrics for algorithm validation. Current metric usage, however, is often ill-informed and does not reflect the underlying domain interest. Here, we present a comprehensive framework that guides researchers towards choosing performance metrics in a problem-aware manner. Specifically, we focus on biomedical image analysis problems that can be interpreted as a classification task at image, object or pixel level. The framework first compiles domain interest-, target structure-, data set- and algorithm output-related properties of a given problem into a problem fingerprint, while also mapping it to the appropriate problem category, namely image-level classification, semantic segmentation, instance segmentation, or object detection. It then guides users through the process of selecting and applying a set of appropriate validation metrics while making them aware of potential pitfalls related to individual choices. In this paper, we describe the current status of the Metrics Reloaded recommendation framework, with the goal of obtaining constructive feedback from the image analysis community. The current version has been developed within an international consortium of more than 60 image analysis experts and will be made openly available as a user-friendly toolkit after community-driven optimization.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
Deep Learning-based Type Identification of Volumetric MRI Sequences
Jun 06, 2021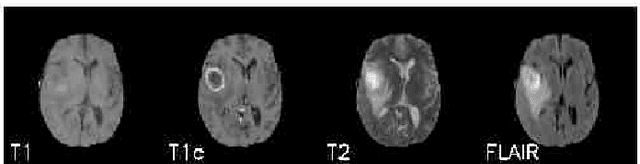
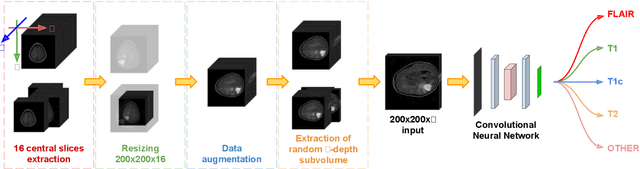
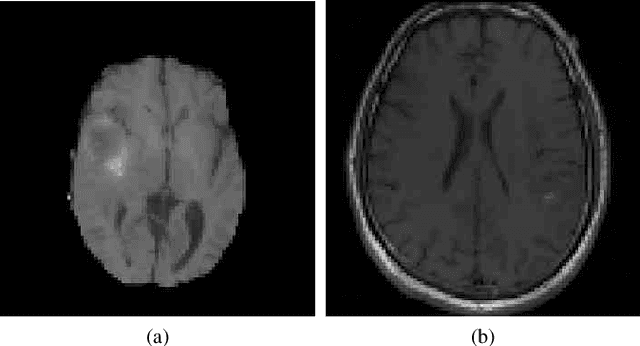
The analysis of Magnetic Resonance Imaging (MRI) sequences enables clinical professionals to monitor the progression of a brain tumor. As the interest for automatizing brain volume MRI analysis increases, it becomes convenient to have each sequence well identified. However, the unstandardized naming of MRI sequences makes their identification difficult for automated systems, as well as makes it difficult for researches to generate or use datasets for machine learning research. In the face of that, we propose a system for identifying types of brain MRI sequences based on deep learning. By training a Convolutional Neural Network (CNN) based on 18-layer ResNet architecture, our system can classify a volumetric brain MRI as a FLAIR, T1, T1c or T2 sequence, or whether it does not belong to any of these classes. The network was evaluated on publicly available datasets comprising both, pre-processed (BraTS dataset) and non-pre-processed (TCGA-GBM dataset), image types with diverse acquisition protocols, requiring only a few slices of the volume for training. Our system can classify among sequence types with an accuracy of 96.81%.
Common Limitations of Image Processing Metrics: A Picture Story
Apr 13, 2021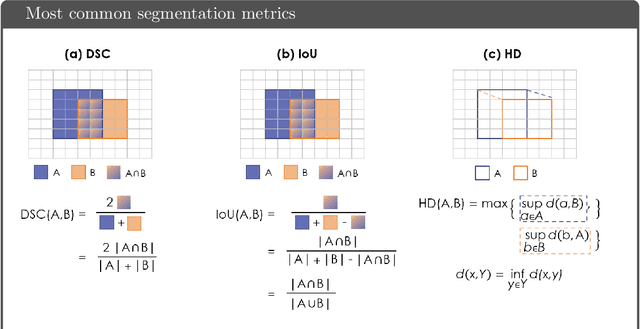
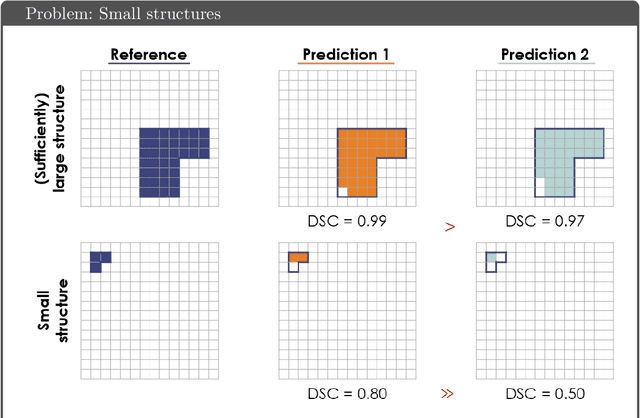
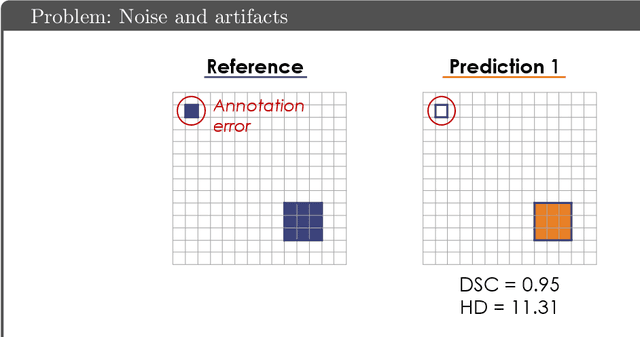
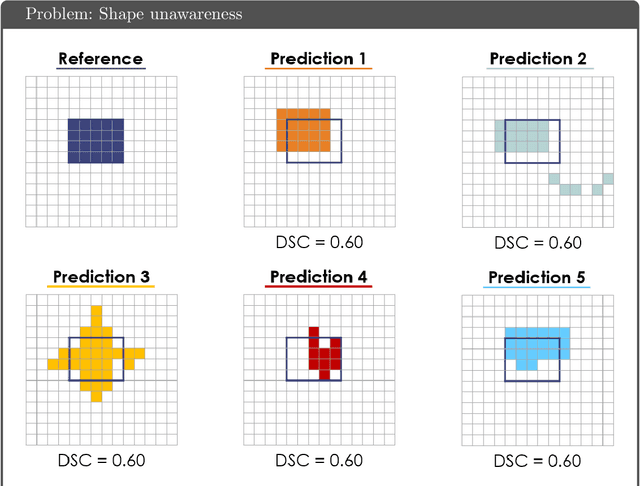
While the importance of automatic image analysis is increasing at an enormous pace, recent meta-research revealed major flaws with respect to algorithm validation. Specifically, performance metrics are key for objective, transparent and comparative performance assessment, but relatively little attention has been given to the practical pitfalls when using specific metrics for a given image analysis task. A common mission of several international initiatives is therefore to provide researchers with guidelines and tools to choose the performance metrics in a problem-aware manner. This dynamically updated document has the purpose to illustrate important limitations of performance metrics commonly applied in the field of image analysis. The current version is based on a Delphi process on metrics conducted by an international consortium of image analysis experts.
Combining unsupervised and supervised learning for predicting the final stroke lesion
Jan 02, 2021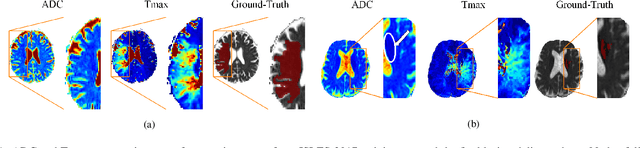

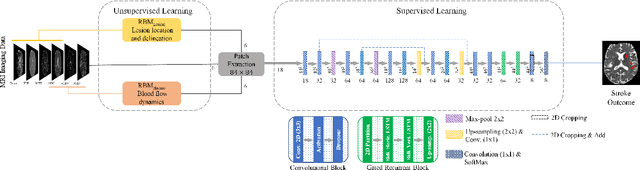

Predicting the final ischaemic stroke lesion provides crucial information regarding the volume of salvageable hypoperfused tissue, which helps physicians in the difficult decision-making process of treatment planning and intervention. Treatment selection is influenced by clinical diagnosis, which requires delineating the stroke lesion, as well as characterising cerebral blood flow dynamics using neuroimaging acquisitions. Nonetheless, predicting the final stroke lesion is an intricate task, due to the variability in lesion size, shape, location and the underlying cerebral haemodynamic processes that occur after the ischaemic stroke takes place. Moreover, since elapsed time between stroke and treatment is related to the loss of brain tissue, assessing and predicting the final stroke lesion needs to be performed in a short period of time, which makes the task even more complex. Therefore, there is a need for automatic methods that predict the final stroke lesion and support physicians in the treatment decision process. We propose a fully automatic deep learning method based on unsupervised and supervised learning to predict the final stroke lesion after 90 days. Our aim is to predict the final stroke lesion location and extent, taking into account the underlying cerebral blood flow dynamics that can influence the prediction. To achieve this, we propose a two-branch Restricted Boltzmann Machine, which provides specialized data-driven features from different sets of standard parametric Magnetic Resonance Imaging maps. These data-driven feature maps are then combined with the parametric Magnetic Resonance Imaging maps, and fed to a Convolutional and Recurrent Neural Network architecture. We evaluated our proposal on the publicly available ISLES 2017 testing dataset, reaching a Dice score of 0.38, Hausdorff Distance of 29.21 mm, and Average Symmetric Surface Distance of 5.52 mm.
pymia: A Python package for data handling and evaluation in deep learning-based medical image analysis
Oct 07, 2020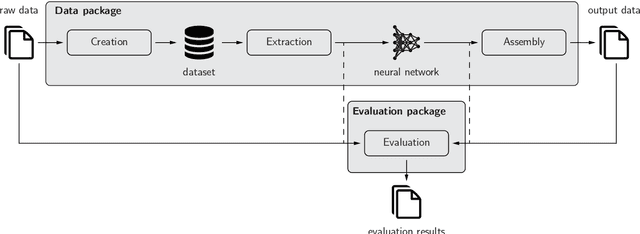

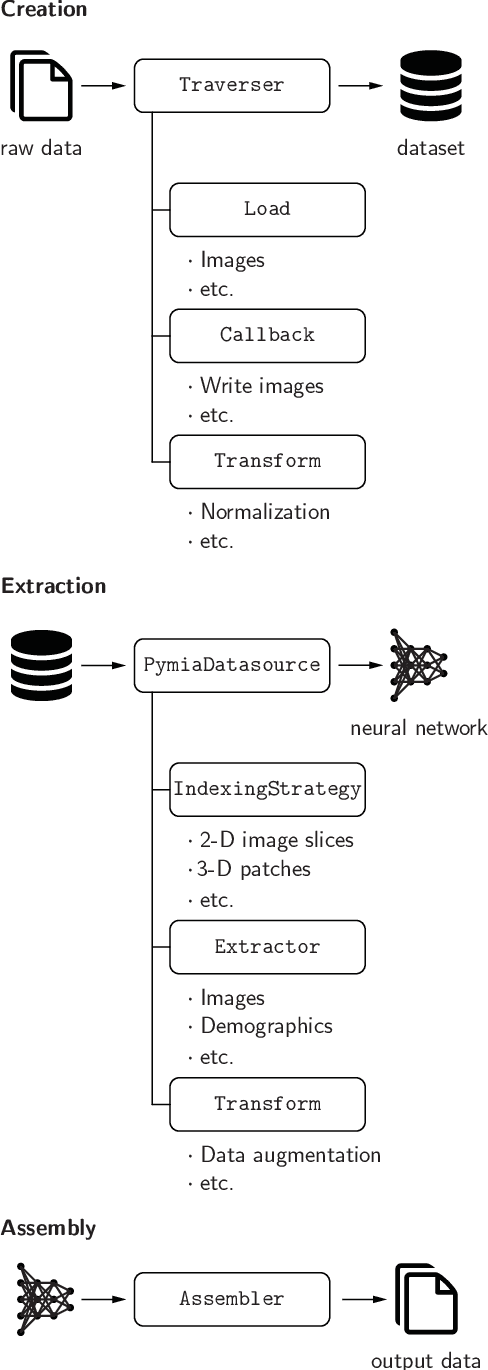
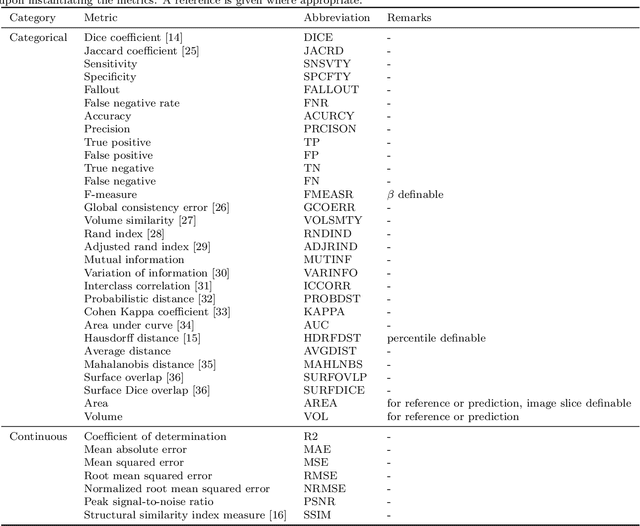
Background and Objective: Deep learning enables tremendous progress in medical image analysis. One driving force of this progress are open-source frameworks like TensorFlow and PyTorch. However, these frameworks rarely address issues specific to the domain of medical image analysis, such as 3-D data handling and distance metrics for evaluation. pymia, an open-source Python package, tries to address these issues by providing flexible data handling and evaluation independent of the deep learning framework. Methods: The pymia package provides data handling and evaluation functionalities. The data handling allows flexible medical image handling in every commonly used format (e.g., 2-D, 2.5-D, and 3-D; full- or patch-wise). Even data beyond images like demographics or clinical reports can easily be integrated into deep learning pipelines. The evaluation allows stand-alone result calculation and reporting, as well as performance monitoring during training using a vast amount of domain-specific metrics for segmentation, reconstruction, and regression. Results: The pymia package is highly flexible, allows for fast prototyping, and reduces the burden of implementing data handling routines and evaluation methods. While data handling and evaluation are independent of the deep learning framework used, they can easily be integrated into TensorFlow and PyTorch pipelines. The developed package was successfully used in a variety of research projects for segmentation, reconstruction, and regression. Conclusions: The pymia package fills the gap of current deep learning frameworks regarding data handling and evaluation in medical image analysis. It is available at https://github.com/rundherum/pymia and can directly be installed from the Python Package Index using pip install pymia.