 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinh-Son To
JointViT: Modeling Oxygen Saturation Levels with Joint Supervision on Long-Tailed OCTA
Apr 18, 2024



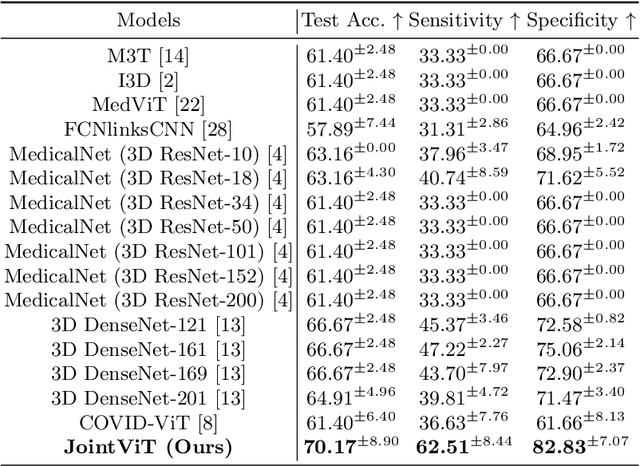
The oxygen saturation level in the blood (SaO2) is crucial for health, particularly in relation to sleep-related breathing disorders. However, continuous monitoring of SaO2 is time-consuming and highly variable depending on patients' conditions. Recently, optical coherence tomography angiography (OCTA) has shown promising development in rapidly and effectively screening eye-related lesions, offering the potential for diagnosing sleep-related disorders. To bridge this gap, our paper presents three key contributions. Firstly, we propose JointViT, a novel model based on the Vision Transformer architecture, incorporating a joint loss function for supervision. Secondly, we introduce a balancing augmentation technique during data preprocessing to improve the model's performance, particularly on the long-tail distribution within the OCTA dataset. Lastly, through comprehensive experiments on the OCTA dataset, our proposed method significantly outperforms other state-of-the-art methods, achieving improvements of up to 12.28% in overall accuracy. This advancement lays the groundwork for the future utilization of OCTA in diagnosing sleep-related disorders. See project website https://steve-zeyu-zhang.github.io/JointViT
PairAug: What Can Augmented Image-Text Pairs Do for Radiology?
Apr 07, 2024Current vision-language pre-training (VLP) methodologies predominantly depend on paired image-text datasets, a resource that is challenging to acquire in radiology due to privacy considerations and labelling complexities. Data augmentation provides a practical solution to overcome the issue of data scarcity, however, most augmentation methods exhibit a limited focus, prioritising either image or text augmentation exclusively. Acknowledging this limitation, our objective is to devise a framework capable of concurrently augmenting medical image and text data. We design a Pairwise Augmentation (PairAug) approach that contains an Inter-patient Augmentation (InterAug) branch and an Intra-patient Augmentation (IntraAug) branch. Specifically, the InterAug branch of our approach generates radiology images using synthesised yet plausible reports derived from a Large Language Model (LLM). The generated pairs can be considered a collection of new patient cases since they are artificially created and may not exist in the original dataset. In contrast, the IntraAug branch uses newly generated reports to manipulate images. This process allows us to create new paired data for each individual with diverse medical conditions. Our extensive experiments on various downstream tasks covering medical image classification zero-shot and fine-tuning analysis demonstrate that our PairAug, concurrently expanding both image and text data, substantially outperforms image-/text-only expansion baselines and advanced medical VLP baselines. Our code is released at \url{https://github.com/YtongXie/PairAug}.
CAPE: CAM as a Probabilistic Ensemble for Enhanced DNN Interpretation
Apr 04, 2024Deep Neural Networks (DNNs) are widely used for visual classification tasks, but their complex computation process and black-box nature hinder decision transparency and interpretability. Class activation maps (CAMs) and recent variants provide ways to visually explain the DNN decision-making process by displaying 'attention' heatmaps of the DNNs. Nevertheless, the CAM explanation only offers relative attention information, that is, on an attention heatmap, we can interpret which image region is more or less important than the others. However, these regions cannot be meaningfully compared across classes, and the contribution of each region to the model's class prediction is not revealed. To address these challenges that ultimately lead to better DNN Interpretation, in this paper, we propose CAPE, a novel reformulation of CAM that provides a unified and probabilistically meaningful assessment of the contributions of image regions. We quantitatively and qualitatively compare CAPE with state-of-the-art CAM methods on CUB and ImageNet benchmark datasets to demonstrate enhanced interpretability. We also test on a cytology imaging dataset depicting a challenging Chronic Myelomonocytic Leukemia (CMML) diagnosis problem. Code is available at: https://github.com/AIML-MED/CAPE.
Decomposing Disease Descriptions for Enhanced Pathology Detection: A Multi-Aspect Vision-Language Matching Framework
Mar 12, 2024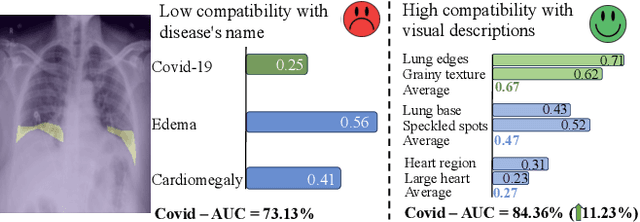
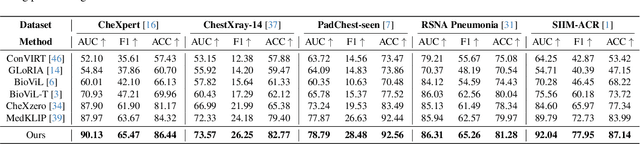

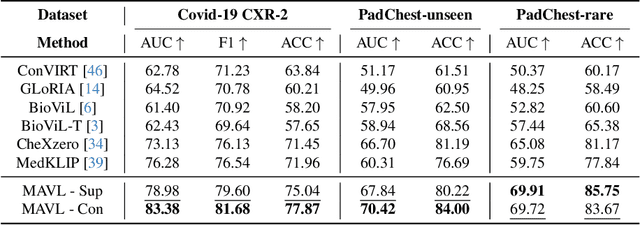
Medical vision language pre-training (VLP) has emerged as a frontier of research, enabling zero-shot pathological recognition by comparing the query image with the textual descriptions for each disease. Due to the complex semantics of biomedical texts, current methods struggle to align medical images with key pathological findings in unstructured reports. This leads to the misalignment with the target disease's textual representation. In this paper, we introduce a novel VLP framework designed to dissect disease descriptions into their fundamental aspects, leveraging prior knowledge about the visual manifestations of pathologies. This is achieved by consulting a large language model and medical experts. Integrating a Transformer module, our approach aligns an input image with the diverse elements of a disease, generating aspect-centric image representations. By consolidating the matches from each aspect, we improve the compatibility between an image and its associated disease. Additionally, capitalizing on the aspect-oriented representations, we present a dual-head Transformer tailored to process known and unknown diseases, optimizing the comprehensive detection efficacy. Conducting experiments on seven downstream datasets, ours outperforms recent methods by up to 8.07% and 11.23% in AUC scores for seen and novel categories, respectively. Our code is released at \href{https://github.com/HieuPhan33/MAVL}{https://github.com/HieuPhan33/MAVL}.
SegReg: Segmenting OARs by Registering MR Images and CT Annotations
Nov 12, 2023Organ at risk (OAR) segmentation is a critical process in radiotherapy treatment planning such as head and neck tumors. Nevertheless, in clinical practice, radiation oncologists predominantly perform OAR segmentations manually on CT scans. This manual process is highly time-consuming and expensive, limiting the number of patients who can receive timely radiotherapy. Additionally, CT scans offer lower soft-tissue contrast compared to MRI. Despite MRI providing superior soft-tissue visualization, its time-consuming nature makes it infeasible for real-time treatment planning. To address these challenges, we propose a method called SegReg, which utilizes Elastic Symmetric Normalization for registering MRI to perform OAR segmentation. SegReg outperforms the CT-only baseline by 16.78% in mDSC and 18.77% in mIoU, showing that it effectively combines the geometric accuracy of CT with the superior soft-tissue contrast of MRI, making accurate automated OAR segmentation for clinical practice become possible.
BHSD: A 3D Multi-Class Brain Hemorrhage Segmentation Dataset
Aug 23, 2023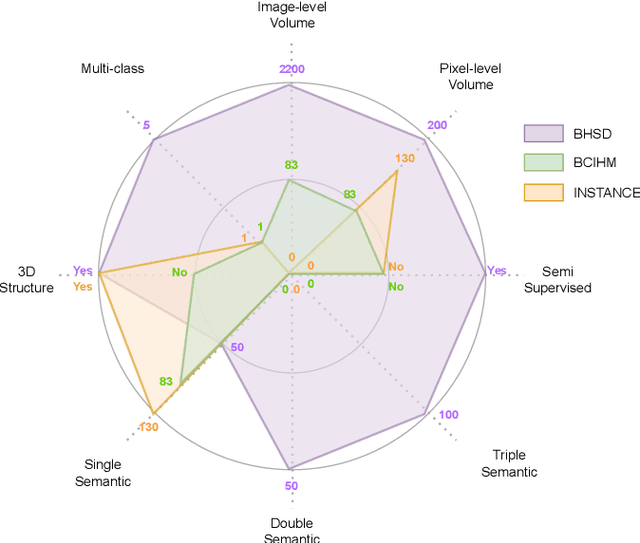
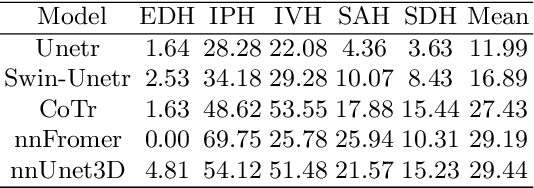
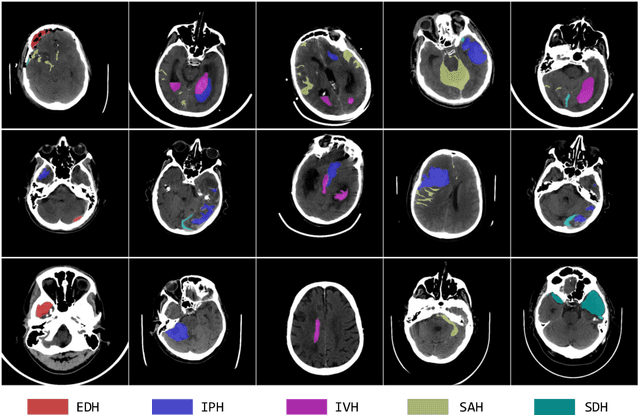
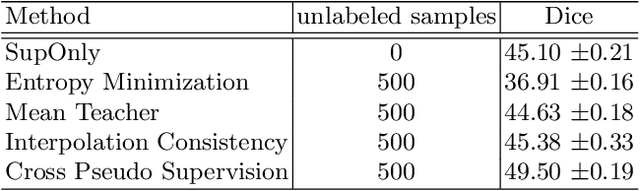
Intracranial hemorrhage (ICH) is a pathological condition characterized by bleeding inside the skull or brain, which can be attributed to various factors. Identifying, localizing and quantifying ICH has important clinical implications, in a bleed-dependent manner. While deep learning techniques are widely used in medical image segmentation and have been applied to the ICH segmentation task, existing public ICH datasets do not support the multi-class segmentation problem. To address this, we develop the Brain Hemorrhage Segmentation Dataset (BHSD), which provides a 3D multi-class ICH dataset containing 192 volumes with pixel-level annotations and 2200 volumes with slice-level annotations across five categories of ICH. To demonstrate the utility of the dataset, we formulate a series of supervised and semi-supervised ICH segmentation tasks. We provide experimental results with state-of-the-art models as reference benchmarks for further model developments and evaluations on this dataset.
Structure-Preserving Synthesis: MaskGAN for Unpaired MR-CT Translation
Aug 01, 2023Medical image synthesis is a challenging task due to the scarcity of paired data. Several methods have applied CycleGAN to leverage unpaired data, but they often generate inaccurate mappings that shift the anatomy. This problem is further exacerbated when the images from the source and target modalities are heavily misaligned. Recently, current methods have aimed to address this issue by incorporating a supplementary segmentation network. Unfortunately, this strategy requires costly and time-consuming pixel-level annotations. To overcome this problem, this paper proposes MaskGAN, a novel and cost-effective framework that enforces structural consistency by utilizing automatically extracted coarse masks. Our approach employs a mask generator to outline anatomical structures and a content generator to synthesize CT contents that align with these structures. Extensive experiments demonstrate that MaskGAN outperforms state-of-the-art synthesis methods on a challenging pediatric dataset, where MR and CT scans are heavily misaligned due to rapid growth in children. Specifically, MaskGAN excels in preserving anatomical structures without the need for expert annotations. The code for this paper can be found at https://github.com/HieuPhan33/MaskGAN.
* Accepted to MICCAI 2023
Distilling Missing Modality Knowledge from Ultrasound for Endometriosis Diagnosis with Magnetic Resonance Images
Jul 05, 2023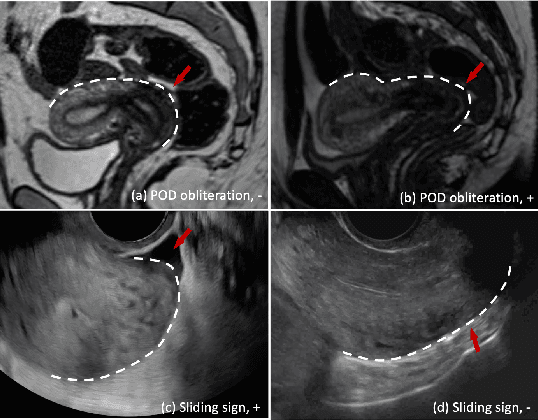
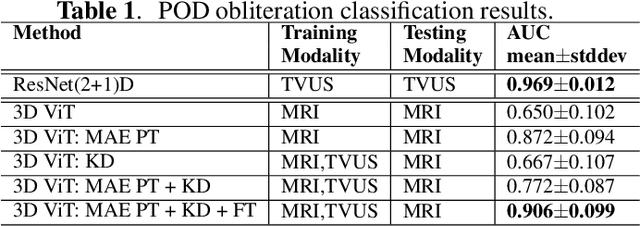
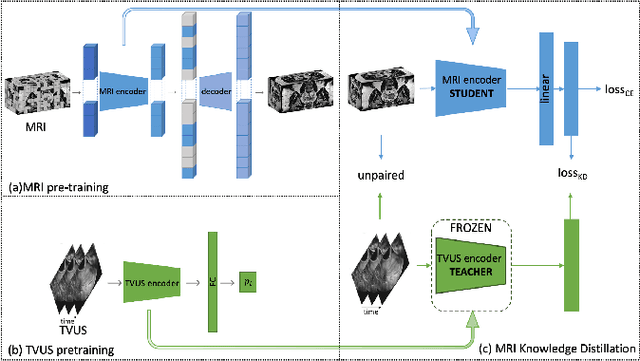
Endometriosis is a common chronic gynecological disorder that has many characteristics, including the pouch of Douglas (POD) obliteration, which can be diagnosed using Transvaginal gynecological ultrasound (TVUS) scans and magnetic resonance imaging (MRI). TVUS and MRI are complementary non-invasive endometriosis diagnosis imaging techniques, but patients are usually not scanned using both modalities and, it is generally more challenging to detect POD obliteration from MRI than TVUS. To mitigate this classification imbalance, we propose in this paper a knowledge distillation training algorithm to improve the POD obliteration detection from MRI by leveraging the detection results from unpaired TVUS data. More specifically, our algorithm pre-trains a teacher model to detect POD obliteration from TVUS data, and it also pre-trains a student model with 3D masked auto-encoder using a large amount of unlabelled pelvic 3D MRI volumes. Next, we distill the knowledge from the teacher TVUS POD obliteration detector to train the student MRI model by minimizing a regression loss that approximates the output of the student to the teacher using unpaired TVUS and MRI data. Experimental results on our endometriosis dataset containing TVUS and MRI data demonstrate the effectiveness of our method to improve the POD detection accuracy from MRI.
S4M: Generating Radiology Reports by A Single Model for Multiple Body Parts
May 26, 2023



In this paper, we seek to design a report generation model that is able to generate reasonable reports even given different images of various body parts. We start by directly merging multiple datasets and training a single report generation model on this one. We, however, observe that the reports generated in such a simple way only obtain comparable performance compared with that trained separately on each specific dataset. We suspect that this is caused by the dilemma between the diversity of body parts and the limited availability of medical data. To develop robust and generalizable models, it is important to consider a diverse range of body parts and medical conditions. However, collecting a sufficiently large dataset for each specific body part can be difficult due to various factors, such as data availability and privacy concerns. Thus, rather than striving for more data, we propose a single-for-multiple (S4M) framework, which seeks to facilitate the learning of the report generation model with two auxiliary priors: an explicit prior (\ie, feeding radiology-informed knowledge) and an implicit prior (\ie, guided by cross-modal features). Specifically, based on the conventional encoder-decoder report generation framework, we incorporate two extra branches: a Radiology-informed Knowledge Aggregation (RadKA) branch and an Implicit Prior Guidance (IPG) branch. We conduct the experiments on our merged dataset which consists of a public dataset (\ie, IU-Xray) and five private datasets, covering six body parts: chest, abdomen, knee, hip, wrist and shoulder. Our S4M model outperforms all the baselines, regardless of whether they are trained on separate or merged datasets. Code is available at: \url{https://github.com/YtongXie/S4M}.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.