 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuankai Qi
Generating Content for HDR Deghosting from Frequency View
Apr 01, 2024
Recovering ghost-free High Dynamic Range (HDR) images from multiple Low Dynamic Range (LDR) images becomes challenging when the LDR images exhibit saturation and significant motion. Recent Diffusion Models (DMs) have been introduced in HDR imaging field, demonstrating promising performance, particularly in achieving visually perceptible results compared to previous DNN-based methods. However, DMs require extensive iterations with large models to estimate entire images, resulting in inefficiency that hinders their practical application. To address this challenge, we propose the Low-Frequency aware Diffusion (LF-Diff) model for ghost-free HDR imaging. The key idea of LF-Diff is implementing the DMs in a highly compacted latent space and integrating it into a regression-based model to enhance the details of reconstructed images. Specifically, as low-frequency information is closely related to human visual perception we propose to utilize DMs to create compact low-frequency priors for the reconstruction process. In addition, to take full advantage of the above low-frequency priors, the Dynamic HDR Reconstruction Network (DHRNet) is carried out in a regression-based manner to obtain final HDR images. Extensive experiments conducted on synthetic and real-world benchmark datasets demonstrate that our LF-Diff performs favorably against several state-of-the-art methods and is 10$\times$ faster than previous DM-based methods.
Decomposing Disease Descriptions for Enhanced Pathology Detection: A Multi-Aspect Vision-Language Matching Framework
Mar 12, 2024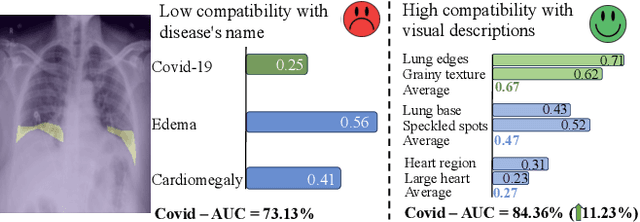
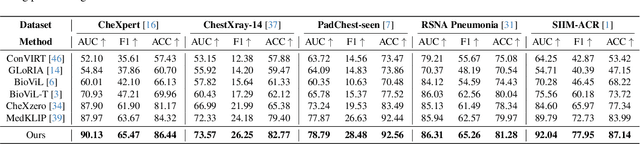

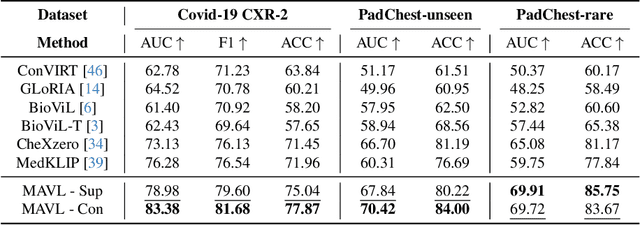
Medical vision language pre-training (VLP) has emerged as a frontier of research, enabling zero-shot pathological recognition by comparing the query image with the textual descriptions for each disease. Due to the complex semantics of biomedical texts, current methods struggle to align medical images with key pathological findings in unstructured reports. This leads to the misalignment with the target disease's textual representation. In this paper, we introduce a novel VLP framework designed to dissect disease descriptions into their fundamental aspects, leveraging prior knowledge about the visual manifestations of pathologies. This is achieved by consulting a large language model and medical experts. Integrating a Transformer module, our approach aligns an input image with the diverse elements of a disease, generating aspect-centric image representations. By consolidating the matches from each aspect, we improve the compatibility between an image and its associated disease. Additionally, capitalizing on the aspect-oriented representations, we present a dual-head Transformer tailored to process known and unknown diseases, optimizing the comprehensive detection efficacy. Conducting experiments on seven downstream datasets, ours outperforms recent methods by up to 8.07% and 11.23% in AUC scores for seen and novel categories, respectively. Our code is released at \href{https://github.com/HieuPhan33/MAVL}{https://github.com/HieuPhan33/MAVL}.
StyleDubber: Towards Multi-Scale Style Learning for Movie Dubbing
Feb 21, 2024Given a script, the challenge in Movie Dubbing (Visual Voice Cloning, V2C) is to generate speech that aligns well with the video in both time and emotion, based on the tone of a reference audio track. Existing state-of-the-art V2C models break the phonemes in the script according to the divisions between video frames, which solves the temporal alignment problem but leads to incomplete phoneme pronunciation and poor identity stability. To address this problem, we propose StyleDubber, which switches dubbing learning from the frame level to phoneme level. It contains three main components: (1) A multimodal style adaptor operating at the phoneme level to learn pronunciation style from the reference audio, and generate intermediate representations informed by the facial emotion presented in the video; (2) An utterance-level style learning module, which guides both the mel-spectrogram decoding and the refining processes from the intermediate embeddings to improve the overall style expression; And (3) a phoneme-guided lip aligner to maintain lip sync. Extensive experiments on two of the primary benchmarks, V2C and Grid, demonstrate the favorable performance of the proposed method as compared to the current state-of-the-art. The source code and trained models will be released to the public.
Subject-Oriented Video Captioning
Dec 20, 2023Describing video content according to users' needs is a long-held goal. Although existing video captioning methods have made significant progress, the generated captions may not focus on the entity that users are particularly interested in. To address this problem, we propose a new video captioning task, subject-oriented video captioning, which allows users to specify the describing target via a bounding box. To support this task, we construct two subject-oriented video captioning datasets based on two widely used video captioning datasets: MSVD and MSRVTT, by annotating subjects in each video for each caption. These datasets pave the way for future technique development. As the first attempt, we evaluate four state-of-the-art general video captioning models, and have observed a large performance drop. We then explore several strategies to enable them to describe the desired target. Experimental results show obvious improvement, but there is still a large room for further exploration in this field.
Weakly Supervised Video Individual CountingWeakly Supervised Video Individual Counting
Dec 10, 2023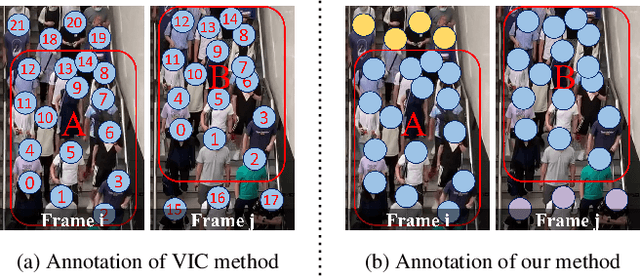
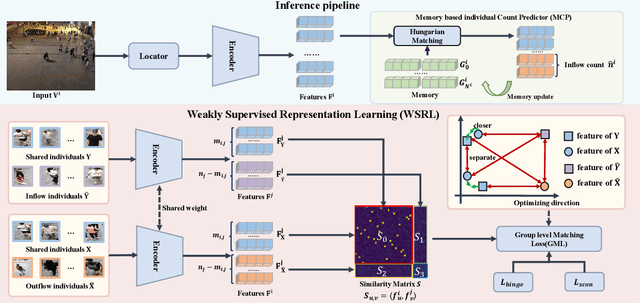
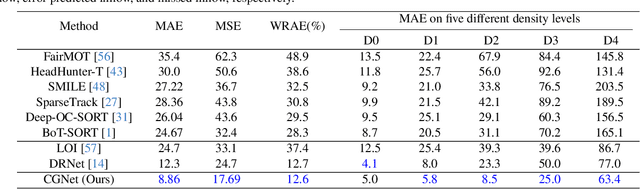
Video Individual Counting (VIC) aims to predict the number of unique individuals in a single video. % Existing methods learn representations based on trajectory labels for individuals, which are annotation-expensive. % To provide a more realistic reflection of the underlying practical challenge, we introduce a weakly supervised VIC task, wherein trajectory labels are not provided. Instead, two types of labels are provided to indicate traffic entering the field of view (inflow) and leaving the field view (outflow). % We also propose the first solution as a baseline that formulates the task as a weakly supervised contrastive learning problem under group-level matching. In doing so, we devise an end-to-end trainable soft contrastive loss to drive the network to distinguish inflow, outflow, and the remaining. % To facilitate future study in this direction, we generate annotations from the existing VIC datasets SenseCrowd and CroHD and also build a new dataset, UAVVIC. % Extensive results show that our baseline weakly supervised method outperforms supervised methods, and thus, little information is lost in the transition to the more practically relevant weakly supervised task. The code and trained model will be public at \href{https://github.com/streamer-AP/CGNet}{CGNet}
Dynamic Erasing Network Based on Multi-Scale Temporal Features for Weakly Supervised Video Anomaly Detection
Dec 04, 2023The goal of weakly supervised video anomaly detection is to learn a detection model using only video-level labeled data. However, prior studies typically divide videos into fixed-length segments without considering the complexity or duration of anomalies. Moreover, these studies usually just detect the most abnormal segments, potentially overlooking the completeness of anomalies. To address these limitations, we propose a Dynamic Erasing Network (DE-Net) for weakly supervised video anomaly detection, which learns multi-scale temporal features. Specifically, to handle duration variations of abnormal events, we first propose a multi-scale temporal modeling module, capable of extracting features from segments of varying lengths and capturing both local and global visual information across different temporal scales. Then, we design a dynamic erasing strategy, which dynamically assesses the completeness of the detected anomalies and erases prominent abnormal segments in order to encourage the model to discover gentle abnormal segments in a video. The proposed method obtains favorable performance compared to several state-of-the-art approaches on three datasets: XD-Violence, TAD, and UCF-Crime. Code will be made available at https://github.com/ArielZc/DE-Net.
March in Chat: Interactive Prompting for Remote Embodied Referring Expression
Aug 20, 2023
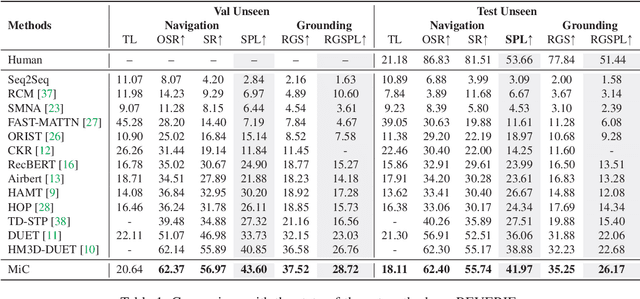
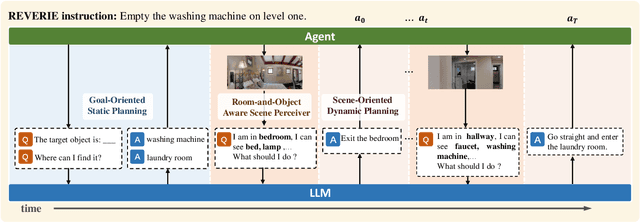
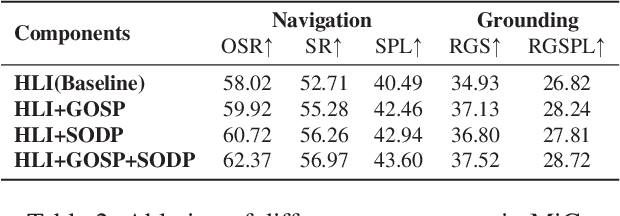
Many Vision-and-Language Navigation (VLN) tasks have been proposed in recent years, from room-based to object-based and indoor to outdoor. The REVERIE (Remote Embodied Referring Expression) is interesting since it only provides high-level instructions to the agent, which are closer to human commands in practice. Nevertheless, this poses more challenges than other VLN tasks since it requires agents to infer a navigation plan only based on a short instruction. Large Language Models (LLMs) show great potential in robot action planning by providing proper prompts. Still, this strategy has not been explored under the REVERIE settings. There are several new challenges. For example, the LLM should be environment-aware so that the navigation plan can be adjusted based on the current visual observation. Moreover, the LLM planned actions should be adaptable to the much larger and more complex REVERIE environment. This paper proposes a March-in-Chat (MiC) model that can talk to the LLM on the fly and plan dynamically based on a newly proposed Room-and-Object Aware Scene Perceiver (ROASP). Our MiC model outperforms the previous state-of-the-art by large margins by SPL and RGSPL metrics on the REVERIE benchmark.
AerialVLN: Vision-and-Language Navigation for UAVs
Aug 13, 2023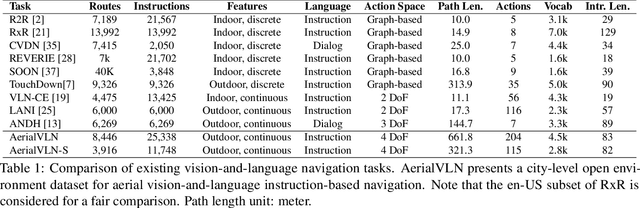

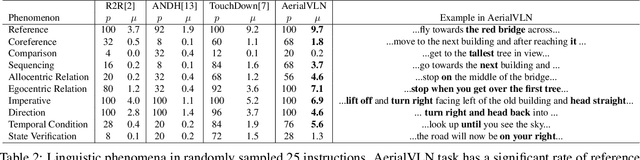
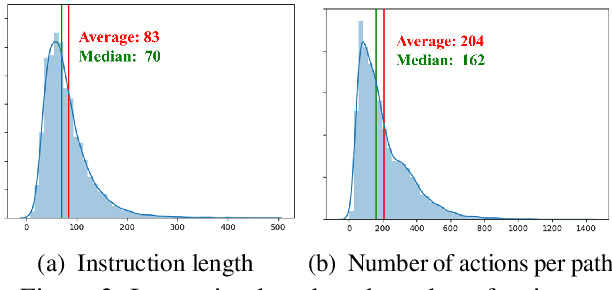
Recently emerged Vision-and-Language Navigation (VLN) tasks have drawn significant attention in both computer vision and natural language processing communities. Existing VLN tasks are built for agents that navigate on the ground, either indoors or outdoors. However, many tasks require intelligent agents to carry out in the sky, such as UAV-based goods delivery, traffic/security patrol, and scenery tour, to name a few. Navigating in the sky is more complicated than on the ground because agents need to consider the flying height and more complex spatial relationship reasoning. To fill this gap and facilitate research in this field, we propose a new task named AerialVLN, which is UAV-based and towards outdoor environments. We develop a 3D simulator rendered by near-realistic pictures of 25 city-level scenarios. Our simulator supports continuous navigation, environment extension and configuration. We also proposed an extended baseline model based on the widely-used cross-modal-alignment (CMA) navigation methods. We find that there is still a significant gap between the baseline model and human performance, which suggests AerialVLN is a new challenging task. Dataset and code is available at https://github.com/AirVLN/AirVLN.
Mind the Gap: Improving Success Rate of Vision-and-Language Navigation by Revisiting Oracle Success Routes
Aug 07, 2023Vision-and-Language Navigation (VLN) aims to navigate to the target location by following a given instruction. Unlike existing methods focused on predicting a more accurate action at each step in navigation, in this paper, we make the first attempt to tackle a long-ignored problem in VLN: narrowing the gap between Success Rate (SR) and Oracle Success Rate (OSR). We observe a consistently large gap (up to 9%) on four state-of-the-art VLN methods across two benchmark datasets: R2R and REVERIE. The high OSR indicates the robot agent passes the target location, while the low SR suggests the agent actually fails to stop at the target location at last. Instead of predicting actions directly, we propose to mine the target location from a trajectory given by off-the-shelf VLN models. Specially, we design a multi-module transformer-based model for learning compact discriminative trajectory viewpoint representation, which is used to predict the confidence of being a target location as described in the instruction. The proposed method is evaluated on three widely-adopted datasets: R2R, REVERIE and NDH, and shows promising results, demonstrating the potential for more future research.
Teacher Agent: A Non-Knowledge Distillation Method for Rehearsal-based Video Incremental Learning
Jun 01, 2023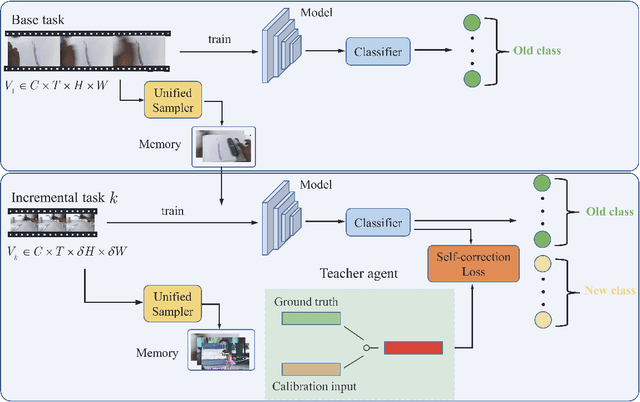
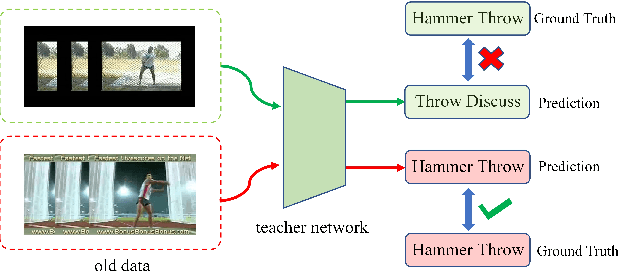
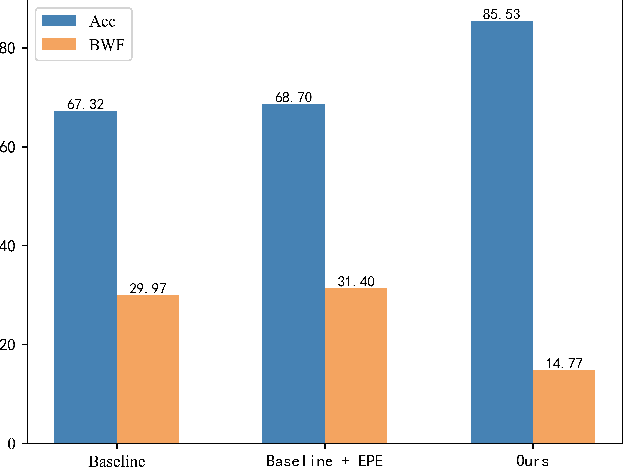
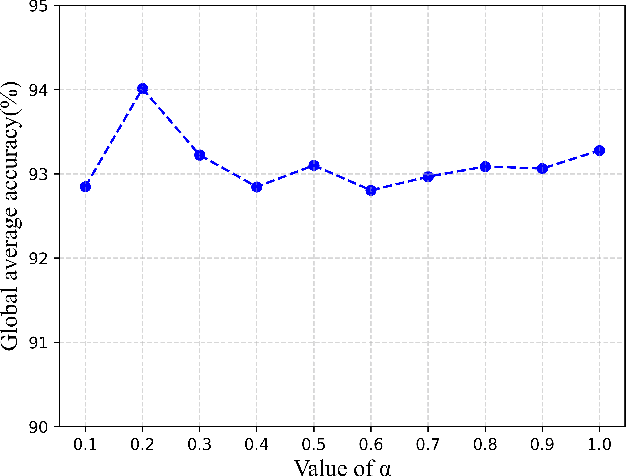
With the rise in popularity of video-based social media, new categories of videos are constantly being generated, creating an urgent need for robust incremental learning techniques for video understanding. One of the biggest challenges in this task is catastrophic forgetting, where the network tends to forget previously learned data while learning new categories. To overcome this issue, knowledge distillation is a widely used technique for rehearsal-based video incremental learning that involves transferring important information on similarities among different categories to enhance the student model. Therefore, it is preferable to have a strong teacher model to guide the students. However, the limited performance of the network itself and the occurrence of catastrophic forgetting can result in the teacher network making inaccurate predictions for some memory exemplars, ultimately limiting the student network's performance. Based on these observations, we propose a teacher agent capable of generating stable and accurate soft labels to replace the output of the teacher model. This method circumvents the problem of knowledge misleading caused by inaccurate predictions of the teacher model and avoids the computational overhead of loading the teacher model for knowledge distillation. Extensive experiments demonstrate the advantages of our method, yielding significant performance improvements while utilizing only half the resolution of video clips in the incremental phases as input compared to recent state-of-the-art methods. Moreover, our method surpasses the performance of joint training when employing four times the number of samples in episodic memory.