 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiao Wu
Real-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024
This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.
I Learn Better If You Speak My Language: Enhancing Large Language Model Fine-Tuning with Style-Aligned Response Adjustments
Feb 17, 2024Fine-tuning large language models (LLMs) with a small data set for particular tasks is a widely encountered yet complex challenge. The potential for overfitting on a limited number of examples can negatively impact the model's ability to generalize and retain its original skills. Our research explores the impact of the style of ground-truth responses during the fine-tuning process. We found that matching the ground-truth response style with the LLM's inherent style results in better learning outcomes. Building on this insight, we developed a method that minimally alters the LLM's pre-existing responses to correct errors, using these adjusted responses as training targets. This technique enables precise corrections in line with the model's native response style, safeguarding the model's core capabilities and thus avoid overfitting. Our findings show that this approach not only improves the LLM's task-specific accuracy but also crucially maintains its original competencies and effectiveness.
SegReg: Segmenting OARs by Registering MR Images and CT Annotations
Nov 12, 2023Organ at risk (OAR) segmentation is a critical process in radiotherapy treatment planning such as head and neck tumors. Nevertheless, in clinical practice, radiation oncologists predominantly perform OAR segmentations manually on CT scans. This manual process is highly time-consuming and expensive, limiting the number of patients who can receive timely radiotherapy. Additionally, CT scans offer lower soft-tissue contrast compared to MRI. Despite MRI providing superior soft-tissue visualization, its time-consuming nature makes it infeasible for real-time treatment planning. To address these challenges, we propose a method called SegReg, which utilizes Elastic Symmetric Normalization for registering MRI to perform OAR segmentation. SegReg outperforms the CT-only baseline by 16.78% in mDSC and 18.77% in mIoU, showing that it effectively combines the geometric accuracy of CT with the superior soft-tissue contrast of MRI, making accurate automated OAR segmentation for clinical practice become possible.
IPMix: Label-Preserving Data Augmentation Method for Training Robust Classifiers
Oct 17, 2023
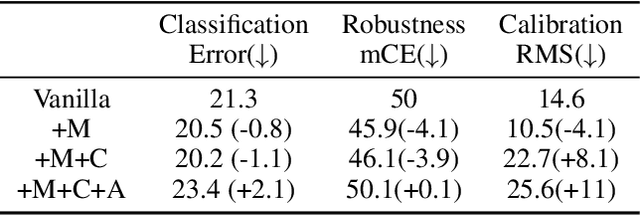
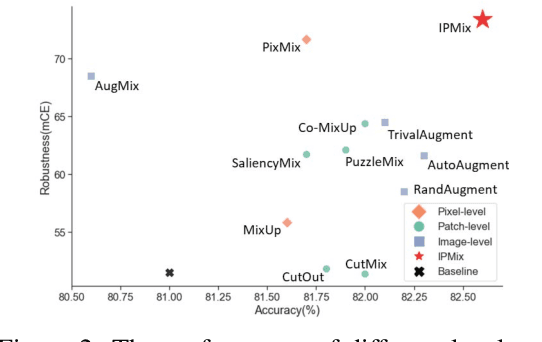
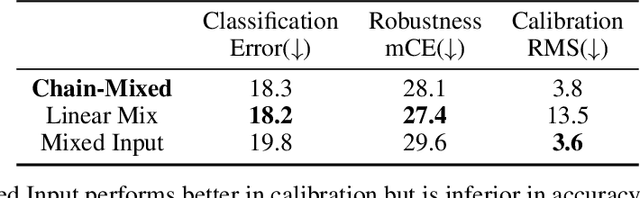
Data augmentation has been proven effective for training high-accuracy convolutional neural network classifiers by preventing overfitting. However, building deep neural networks in real-world scenarios requires not only high accuracy on clean data but also robustness when data distributions shift. While prior methods have proposed that there is a trade-off between accuracy and robustness, we propose IPMix, a simple data augmentation approach to improve robustness without hurting clean accuracy. IPMix integrates three levels of data augmentation (image-level, patch-level, and pixel-level) into a coherent and label-preserving technique to increase the diversity of training data with limited computational overhead. To further improve the robustness, IPMix introduces structural complexity at different levels to generate more diverse images and adopts the random mixing method for multi-scale information fusion. Experiments demonstrate that IPMix outperforms state-of-the-art corruption robustness on CIFAR-C and ImageNet-C. In addition, we show that IPMix also significantly improves the other safety measures, including robustness to adversarial perturbations, calibration, prediction consistency, and anomaly detection, achieving state-of-the-art or comparable results on several benchmarks, including ImageNet-R, ImageNet-A, and ImageNet-O.
From Zero to Hero: Detecting Leaked Data through Synthetic Data Injection and Model Querying
Oct 06, 2023



Safeguarding the Intellectual Property (IP) of data has become critically important as machine learning applications continue to proliferate, and their success heavily relies on the quality of training data. While various mechanisms exist to secure data during storage, transmission, and consumption, fewer studies have been developed to detect whether they are already leaked for model training without authorization. This issue is particularly challenging due to the absence of information and control over the training process conducted by potential attackers. In this paper, we concentrate on the domain of tabular data and introduce a novel methodology, Local Distribution Shifting Synthesis (\textsc{LDSS}), to detect leaked data that are used to train classification models. The core concept behind \textsc{LDSS} involves injecting a small volume of synthetic data--characterized by local shifts in class distribution--into the owner's dataset. This enables the effective identification of models trained on leaked data through model querying alone, as the synthetic data injection results in a pronounced disparity in the predictions of models trained on leaked and modified datasets. \textsc{LDSS} is \emph{model-oblivious} and hence compatible with a diverse range of classification models, such as Naive Bayes, Decision Tree, and Random Forest. We have conducted extensive experiments on seven types of classification models across five real-world datasets. The comprehensive results affirm the reliability, robustness, fidelity, security, and efficiency of \textsc{LDSS}.
BHSD: A 3D Multi-Class Brain Hemorrhage Segmentation Dataset
Aug 23, 2023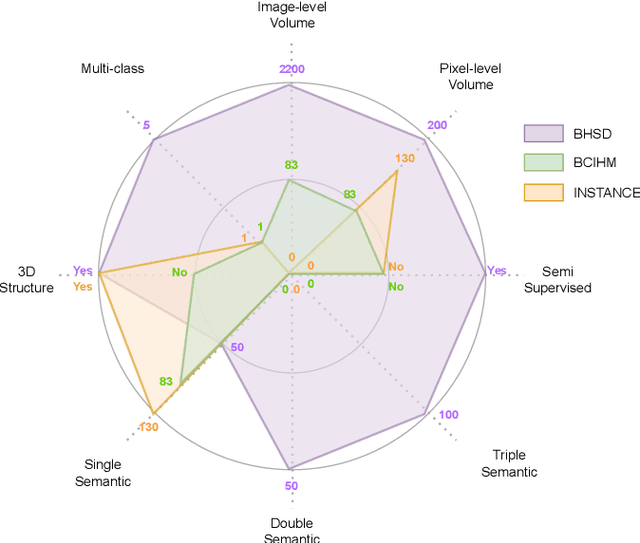
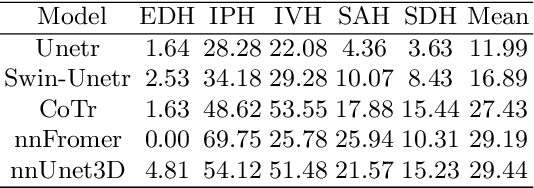
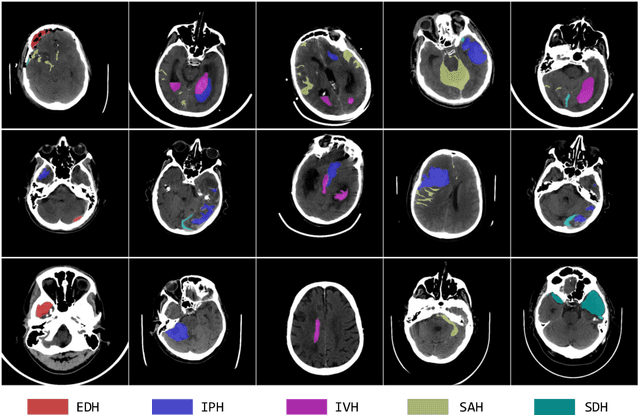
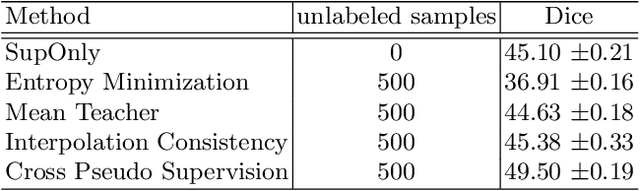
Intracranial hemorrhage (ICH) is a pathological condition characterized by bleeding inside the skull or brain, which can be attributed to various factors. Identifying, localizing and quantifying ICH has important clinical implications, in a bleed-dependent manner. While deep learning techniques are widely used in medical image segmentation and have been applied to the ICH segmentation task, existing public ICH datasets do not support the multi-class segmentation problem. To address this, we develop the Brain Hemorrhage Segmentation Dataset (BHSD), which provides a 3D multi-class ICH dataset containing 192 volumes with pixel-level annotations and 2200 volumes with slice-level annotations across five categories of ICH. To demonstrate the utility of the dataset, we formulate a series of supervised and semi-supervised ICH segmentation tasks. We provide experimental results with state-of-the-art models as reference benchmarks for further model developments and evaluations on this dataset.
Recyclable Semi-supervised Method Based on Multi-model Ensemble for Video Scene Parsing
Jun 05, 2023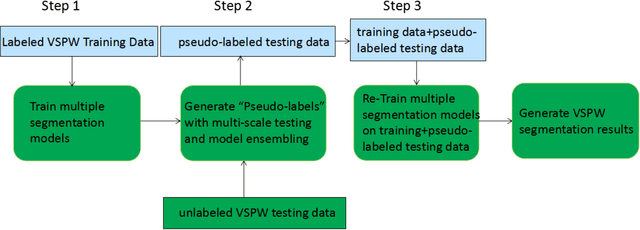

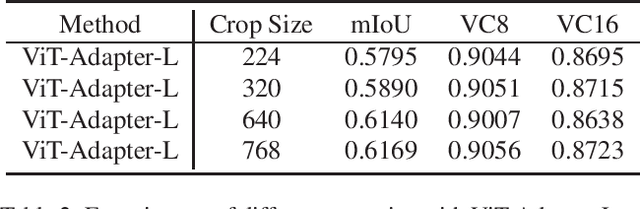

Pixel-level Scene Understanding is one of the fundamental problems in computer vision, which aims at recognizing object classes, masks and semantics of each pixel in the given image. Since the real-world is actually video-based rather than a static state, learning to perform video semantic segmentation is more reasonable and practical for realistic applications. In this paper, we adopt Mask2Former as architecture and ViT-Adapter as backbone. Then, we propose a recyclable semi-supervised training method based on multi-model ensemble. Our method achieves the mIoU scores of 62.97% and 65.83% on Development test and final test respectively. Finally, we obtain the 2nd place in the Video Scene Parsing in the Wild Challenge at CVPR 2023.
S4M: Generating Radiology Reports by A Single Model for Multiple Body Parts
May 26, 2023



In this paper, we seek to design a report generation model that is able to generate reasonable reports even given different images of various body parts. We start by directly merging multiple datasets and training a single report generation model on this one. We, however, observe that the reports generated in such a simple way only obtain comparable performance compared with that trained separately on each specific dataset. We suspect that this is caused by the dilemma between the diversity of body parts and the limited availability of medical data. To develop robust and generalizable models, it is important to consider a diverse range of body parts and medical conditions. However, collecting a sufficiently large dataset for each specific body part can be difficult due to various factors, such as data availability and privacy concerns. Thus, rather than striving for more data, we propose a single-for-multiple (S4M) framework, which seeks to facilitate the learning of the report generation model with two auxiliary priors: an explicit prior (\ie, feeding radiology-informed knowledge) and an implicit prior (\ie, guided by cross-modal features). Specifically, based on the conventional encoder-decoder report generation framework, we incorporate two extra branches: a Radiology-informed Knowledge Aggregation (RadKA) branch and an Implicit Prior Guidance (IPG) branch. We conduct the experiments on our merged dataset which consists of a public dataset (\ie, IU-Xray) and five private datasets, covering six body parts: chest, abdomen, knee, hip, wrist and shoulder. Our S4M model outperforms all the baselines, regardless of whether they are trained on separate or merged datasets. Code is available at: \url{https://github.com/YtongXie/S4M}.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
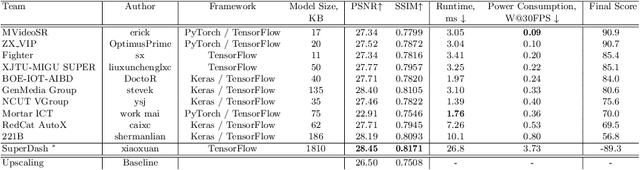
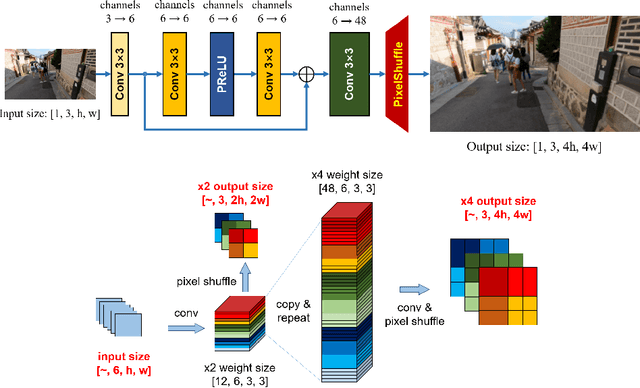
Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022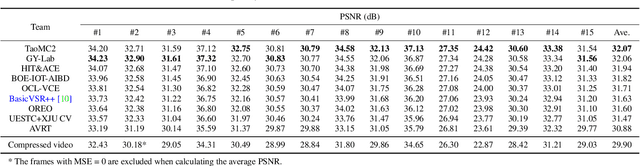
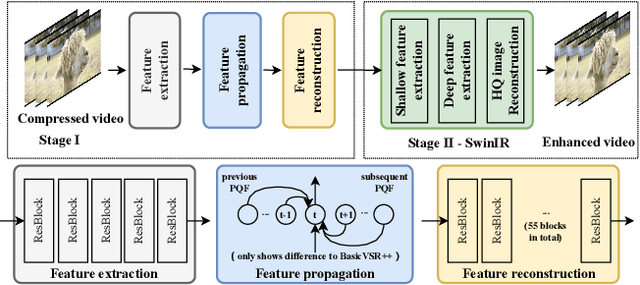
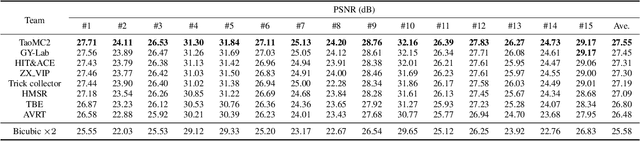

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.