 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHang Dong
A Language Model based Framework for New Concept Placement in Ontologies
Mar 04, 2024
We investigate the task of inserting new concepts extracted from texts into an ontology using language models. We explore an approach with three steps: edge search which is to find a set of candidate locations to insert (i.e., subsumptions between concepts), edge formation and enrichment which leverages the ontological structure to produce and enhance the edge candidates, and edge selection which eventually locates the edge to be placed into. In all steps, we propose to leverage neural methods, where we apply embedding-based methods and contrastive learning with Pre-trained Language Models (PLMs) such as BERT for edge search, and adapt a BERT fine-tuning-based multi-label Edge-Cross-encoder, and Large Language Models (LLMs) such as GPT series, FLAN-T5, and Llama 2, for edge selection. We evaluate the methods on recent datasets created using the SNOMED CT ontology and the MedMentions entity linking benchmark. The best settings in our framework use fine-tuned PLM for search and a multi-label Cross-encoder for selection. Zero-shot prompting of LLMs is still not adequate for the task, and we propose explainable instruction tuning of LLMs for improved performance. Our study shows the advantages of PLMs and highlights the encouraging performance of LLMs that motivates future studies.
Can GPT-3.5 Generate and Code Discharge Summaries?
Jan 24, 2024Objective: To investigate GPT-3.5 in generating and coding medical documents with ICD-10 codes for data augmentation on low-resources labels. Materials and Methods: Employing GPT-3.5 we generated and coded 9,606 discharge summaries based on lists of ICD-10 code descriptions of patients with infrequent (generation) codes within the MIMIC-IV dataset. Combined with the baseline training set, this formed an augmented training set. Neural coding models were trained on baseline and augmented data and evaluated on a MIMIC-IV test set. We report micro- and macro-F1 scores on the full codeset, generation codes, and their families. Weak Hierarchical Confusion Matrices were employed to determine within-family and outside-of-family coding errors in the latter codesets. The coding performance of GPT-3.5 was evaluated both on prompt-guided self-generated data and real MIMIC-IV data. Clinical professionals evaluated the clinical acceptability of the generated documents. Results: Augmentation slightly hinders the overall performance of the models but improves performance for the generation candidate codes and their families, including one unseen in the baseline training data. Augmented models display lower out-of-family error rates. GPT-3.5 can identify ICD-10 codes by the prompted descriptions, but performs poorly on real data. Evaluators note the correctness of generated concepts while suffering in variety, supporting information, and narrative. Discussion and Conclusion: GPT-3.5 alone is unsuitable for ICD-10 coding. Augmentation positively affects generation code families but mainly benefits codes with existing examples. Augmentation reduces out-of-family errors. Discharge summaries generated by GPT-3.5 state prompted concepts correctly but lack variety, and authenticity in narratives. They are unsuitable for clinical practice.
COIN: Chance-Constrained Imitation Learning for Uncertainty-aware Adaptive Resource Oversubscription Policy
Jan 13, 2024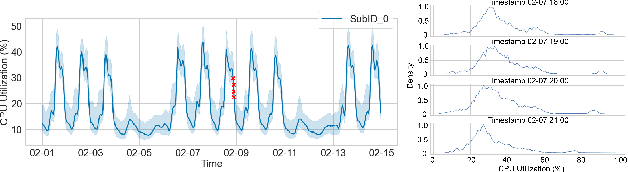
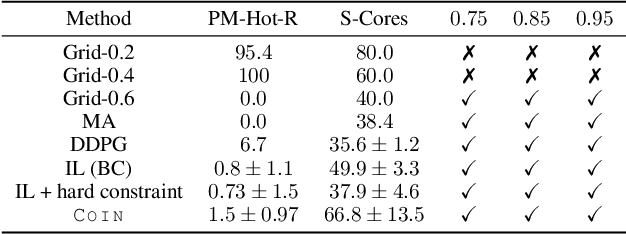
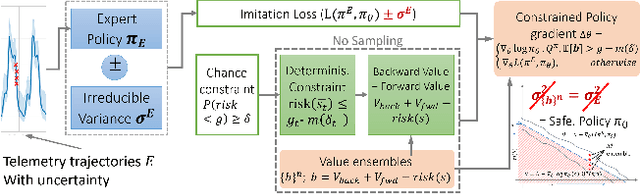
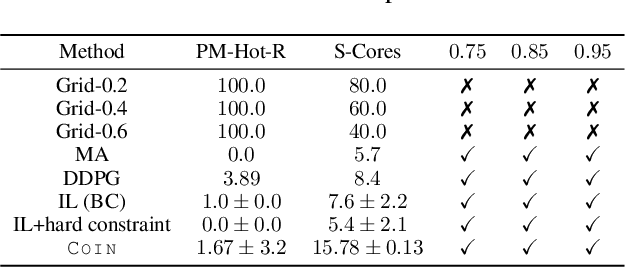
We address the challenge of learning safe and robust decision policies in presence of uncertainty in context of the real scientific problem of adaptive resource oversubscription to enhance resource efficiency while ensuring safety against resource congestion risk. Traditional supervised prediction or forecasting models are ineffective in learning adaptive policies whereas standard online optimization or reinforcement learning is difficult to deploy on real systems. Offline methods such as imitation learning (IL) are ideal since we can directly leverage historical resource usage telemetry. But, the underlying aleatoric uncertainty in such telemetry is a critical bottleneck. We solve this with our proposed novel chance-constrained imitation learning framework, which ensures implicit safety against uncertainty in a principled manner via a combination of stochastic (chance) constraints on resource congestion risk and ensemble value functions. This leads to substantial ($\approx 3-4\times$) improvement in resource efficiency and safety in many oversubscription scenarios, including resource management in cloud services.
TaskWeaver: A Code-First Agent Framework
Dec 01, 2023
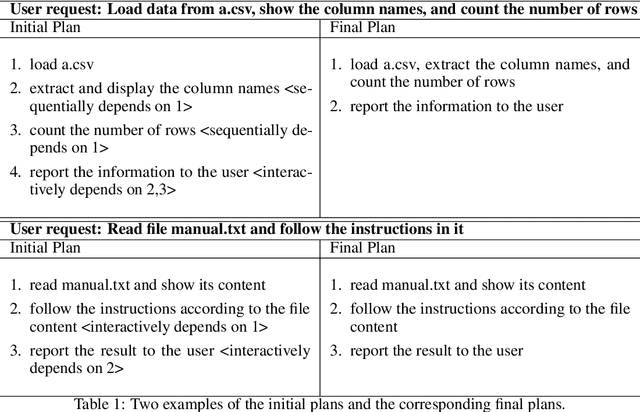
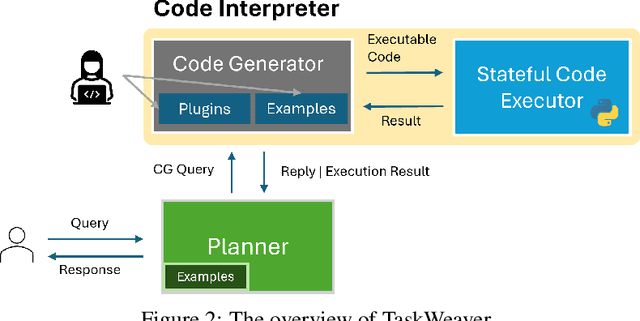
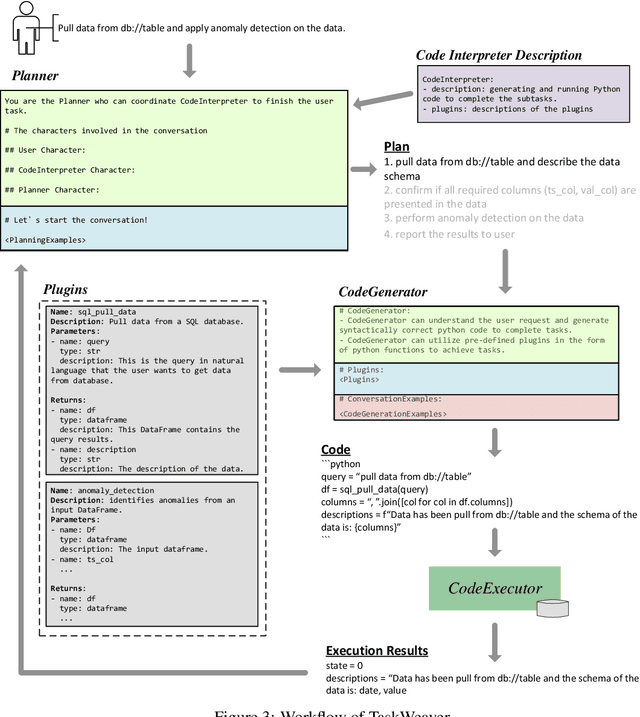
Large Language Models (LLMs) have shown impressive abilities in natural language understanding and generation, leading to their use in applications such as chatbots and virtual assistants. However, existing LLM frameworks face limitations in handling domain-specific data analytics tasks with rich data structures. Moreover, they struggle with flexibility to meet diverse user requirements. To address these issues, TaskWeaver is proposed as a code-first framework for building LLM-powered autonomous agents. It converts user requests into executable code and treats user-defined plugins as callable functions. TaskWeaver provides support for rich data structures, flexible plugin usage, and dynamic plugin selection, and leverages LLM coding capabilities for complex logic. It also incorporates domain-specific knowledge through examples and ensures the secure execution of generated code. TaskWeaver offers a powerful and flexible framework for creating intelligent conversational agents that can handle complex tasks and adapt to domain-specific scenarios. The code is open-sourced at https://github.com/microsoft/TaskWeaver/.
Counter-Empirical Attacking based on Adversarial Reinforcement Learning for Time-Relevant Scoring System
Nov 09, 2023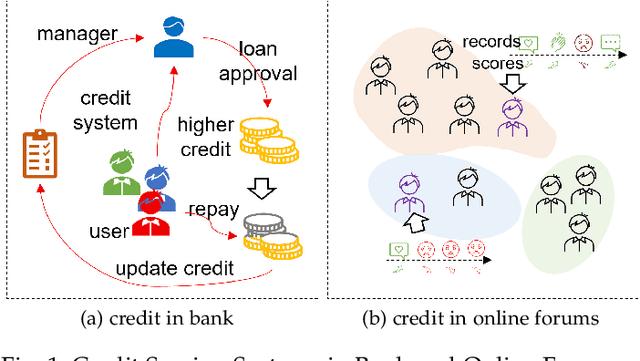
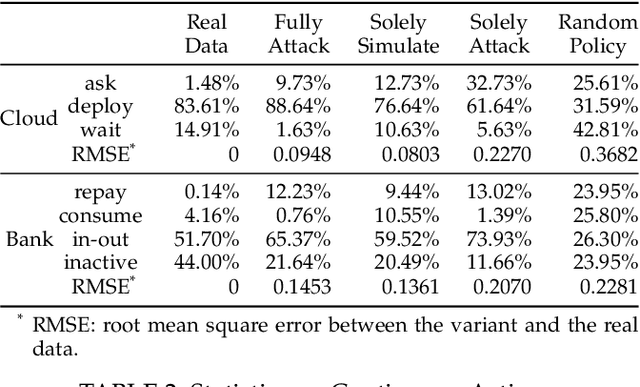
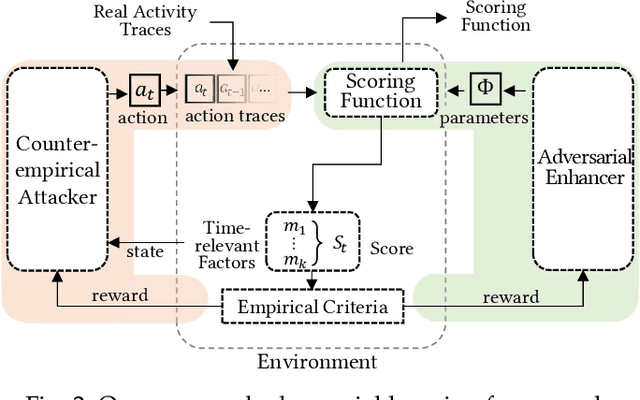
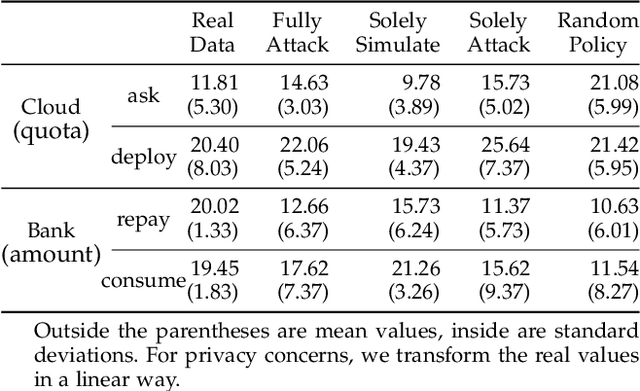
Scoring systems are commonly seen for platforms in the era of big data. From credit scoring systems in financial services to membership scores in E-commerce shopping platforms, platform managers use such systems to guide users towards the encouraged activity pattern, and manage resources more effectively and more efficiently thereby. To establish such scoring systems, several "empirical criteria" are firstly determined, followed by dedicated top-down design for each factor of the score, which usually requires enormous effort to adjust and tune the scoring function in the new application scenario. What's worse, many fresh projects usually have no ground-truth or any experience to evaluate a reasonable scoring system, making the designing even harder. To reduce the effort of manual adjustment of the scoring function in every new scoring system, we innovatively study the scoring system from the preset empirical criteria without any ground truth, and propose a novel framework to improve the system from scratch. In this paper, we propose a "counter-empirical attacking" mechanism that can generate "attacking" behavior traces and try to break the empirical rules of the scoring system. Then an adversarial "enhancer" is applied to evaluate the scoring system and find the improvement strategy. By training the adversarial learning problem, a proper scoring function can be learned to be robust to the attacking activity traces that are trying to violate the empirical criteria. Extensive experiments have been conducted on two scoring systems including a shared computing resource platform and a financial credit system. The experimental results have validated the effectiveness of our proposed framework.
Knowledge Graphs for the Life Sciences: Recent Developments, Challenges and Opportunities
Oct 06, 2023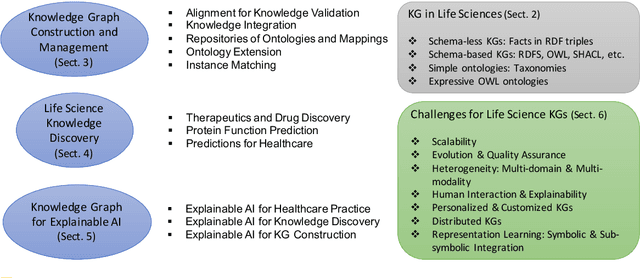
The term life sciences refers to the disciplines that study living organisms and life processes, and include chemistry, biology, medicine, and a range of other related disciplines. Research efforts in life sciences are heavily data-driven, as they produce and consume vast amounts of scientific data, much of which is intrinsically relational and graph-structured. The volume of data and the complexity of scientific concepts and relations referred to therein promote the application of advanced knowledge-driven technologies for managing and interpreting data, with the ultimate aim to advance scientific discovery. In this survey and position paper, we discuss recent developments and advances in the use of graph-based technologies in life sciences and set out a vision for how these technologies will impact these fields into the future. We focus on three broad topics: the construction and management of Knowledge Graphs (KGs), the use of KGs and associated technologies in the discovery of new knowledge, and the use of KGs in artificial intelligence applications to support explanations (explainable AI). We select a few exemplary use cases for each topic, discuss the challenges and open research questions within these topics, and conclude with a perspective and outlook that summarizes the overarching challenges and their potential solutions as a guide for future research.
Exploring Large Language Models for Ontology Alignment
Sep 12, 2023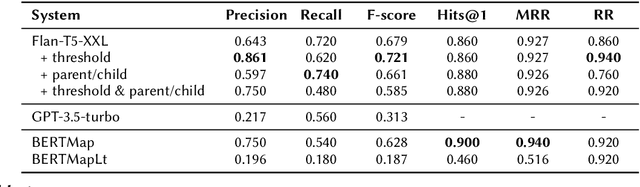
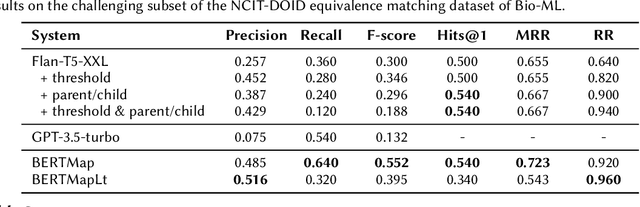
This work investigates the applicability of recent generative Large Language Models (LLMs), such as the GPT series and Flan-T5, to ontology alignment for identifying concept equivalence mappings across ontologies. To test the zero-shot performance of Flan-T5-XXL and GPT-3.5-turbo, we leverage challenging subsets from two equivalence matching datasets of the OAEI Bio-ML track, taking into account concept labels and structural contexts. Preliminary findings suggest that LLMs have the potential to outperform existing ontology alignment systems like BERTMap, given careful framework and prompt design.
Large Language Models Vote: Prompting for Rare Disease Identification
Aug 28, 2023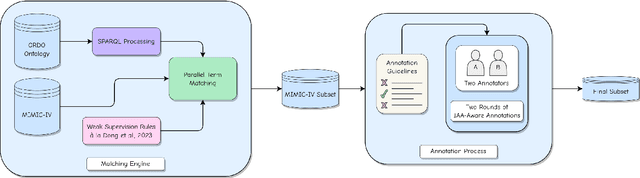
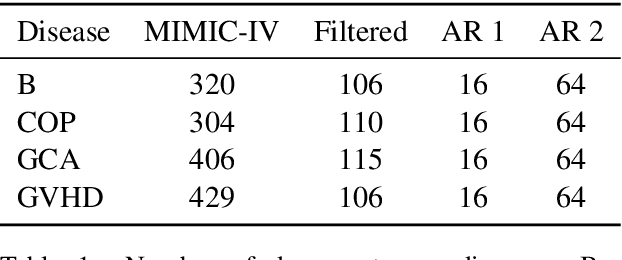

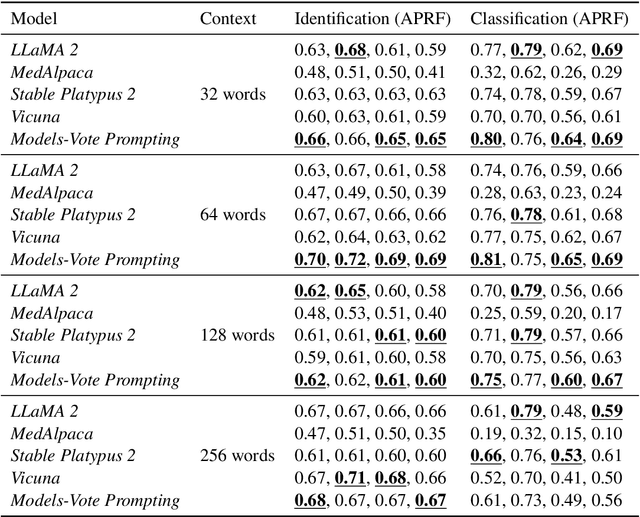
The emergence of generative Large Language Models (LLMs) emphasizes the need for accurate and efficient prompting approaches. LLMs are often applied in Few-Shot Learning (FSL) contexts, where tasks are executed with minimal training data. FSL has become popular in many Artificial Intelligence (AI) subdomains, including AI for health. Rare diseases affect a small fraction of the population. Rare disease identification from clinical notes inherently requires FSL techniques due to limited data availability. Manual data collection and annotation is both expensive and time-consuming. In this paper, we propose Models-Vote Prompting (MVP), a flexible prompting approach for improving the performance of LLM queries in FSL settings. MVP works by prompting numerous LLMs to perform the same tasks and then conducting a majority vote on the resulting outputs. This method achieves improved results to any one model in the ensemble on one-shot rare disease identification and classification tasks. We also release a novel rare disease dataset for FSL, available to those who signed the MIMIC-IV Data Use Agreement (DUA). Furthermore, in using MVP, each model is prompted multiple times, substantially increasing the time needed for manual annotation, and to address this, we assess the feasibility of using JSON for automating generative LLM evaluation.
Unfolding Once is Enough: A Deployment-Friendly Transformer Unit for Super-Resolution
Aug 05, 2023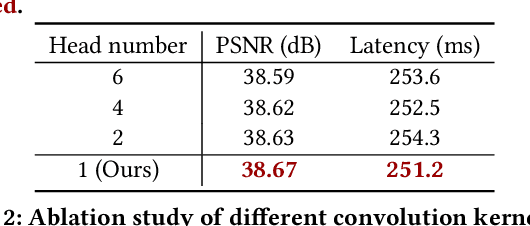



Recent years have witnessed a few attempts of vision transformers for single image super-resolution (SISR). Since the high resolution of intermediate features in SISR models increases memory and computational requirements, efficient SISR transformers are more favored. Based on some popular transformer backbone, many methods have explored reasonable schemes to reduce the computational complexity of the self-attention module while achieving impressive performance. However, these methods only focus on the performance on the training platform (e.g., Pytorch/Tensorflow) without further optimization for the deployment platform (e.g., TensorRT). Therefore, they inevitably contain some redundant operators, posing challenges for subsequent deployment in real-world applications. In this paper, we propose a deployment-friendly transformer unit, namely UFONE (i.e., UnFolding ONce is Enough), to alleviate these problems. In each UFONE, we introduce an Inner-patch Transformer Layer (ITL) to efficiently reconstruct the local structural information from patches and a Spatial-Aware Layer (SAL) to exploit the long-range dependencies between patches. Based on UFONE, we propose a Deployment-friendly Inner-patch Transformer Network (DITN) for the SISR task, which can achieve favorable performance with low latency and memory usage on both training and deployment platforms. Furthermore, to further boost the deployment efficiency of the proposed DITN on TensorRT, we also provide an efficient substitution for layer normalization and propose a fusion optimization strategy for specific operators. Extensive experiments show that our models can achieve competitive results in terms of qualitative and quantitative performance with high deployment efficiency. Code is available at \url{https://github.com/yongliuy/DITN}.
Robust Positive-Unlabeled Learning via Noise Negative Sample Self-correction
Aug 01, 2023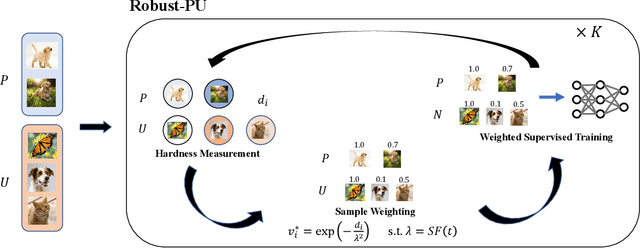

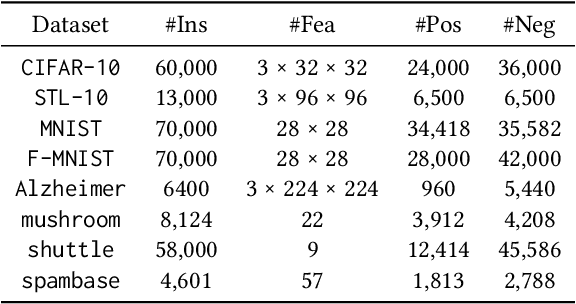
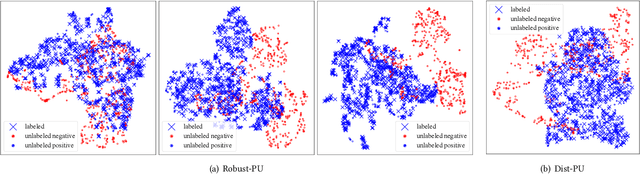
Learning from positive and unlabeled data is known as positive-unlabeled (PU) learning in literature and has attracted much attention in recent years. One common approach in PU learning is to sample a set of pseudo-negatives from the unlabeled data using ad-hoc thresholds so that conventional supervised methods can be applied with both positive and negative samples. Owing to the label uncertainty among the unlabeled data, errors of misclassifying unlabeled positive samples as negative samples inevitably appear and may even accumulate during the training processes. Those errors often lead to performance degradation and model instability. To mitigate the impact of label uncertainty and improve the robustness of learning with positive and unlabeled data, we propose a new robust PU learning method with a training strategy motivated by the nature of human learning: easy cases should be learned first. Similar intuition has been utilized in curriculum learning to only use easier cases in the early stage of training before introducing more complex cases. Specifically, we utilize a novel ``hardness'' measure to distinguish unlabeled samples with a high chance of being negative from unlabeled samples with large label noise. An iterative training strategy is then implemented to fine-tune the selection of negative samples during the training process in an iterative manner to include more ``easy'' samples in the early stage of training. Extensive experimental validations over a wide range of learning tasks show that this approach can effectively improve the accuracy and stability of learning with positive and unlabeled data. Our code is available at https://github.com/woriazzc/Robust-PU