 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHong Cheng
DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation
Mar 13, 2024
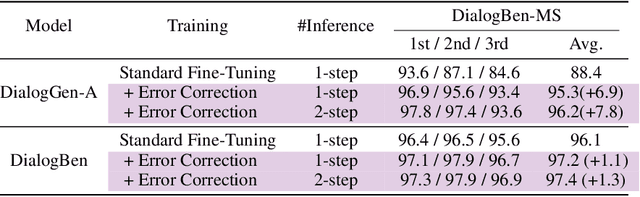
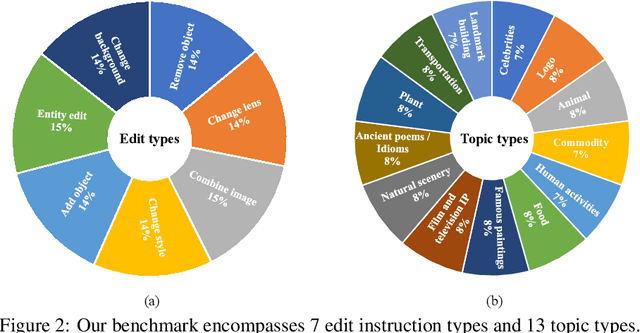

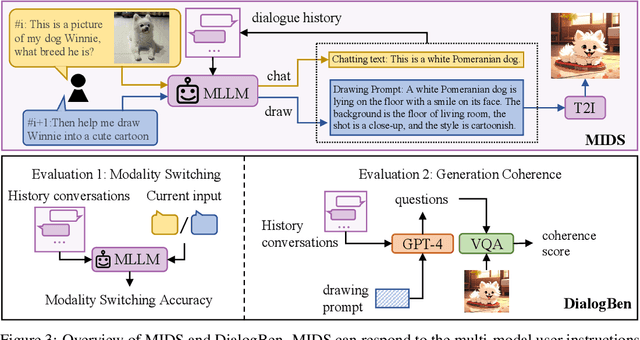
Text-to-image (T2I) generation models have significantly advanced in recent years. However, effective interaction with these models is challenging for average users due to the need for specialized prompt engineering knowledge and the inability to perform multi-turn image generation, hindering a dynamic and iterative creation process. Recent attempts have tried to equip Multi-modal Large Language Models (MLLMs) with T2I models to bring the user's natural language instructions into reality. Hence, the output modality of MLLMs is extended, and the multi-turn generation quality of T2I models is enhanced thanks to the strong multi-modal comprehension ability of MLLMs. However, many of these works face challenges in identifying correct output modalities and generating coherent images accordingly as the number of output modalities increases and the conversations go deeper. Therefore, we propose DialogGen, an effective pipeline to align off-the-shelf MLLMs and T2I models to build a Multi-modal Interactive Dialogue System (MIDS) for multi-turn Text-to-Image generation. It is composed of drawing prompt alignment, careful training data curation, and error correction. Moreover, as the field of MIDS flourishes, comprehensive benchmarks are urgently needed to evaluate MIDS fairly in terms of output modality correctness and multi-modal output coherence. To address this issue, we introduce the Multi-modal Dialogue Benchmark (DialogBen), a comprehensive bilingual benchmark designed to assess the ability of MLLMs to generate accurate and coherent multi-modal content that supports image editing. It contains two evaluation metrics to measure the model's ability to switch modalities and the coherence of the output images. Our extensive experiments on DialogBen and user study demonstrate the effectiveness of DialogGen compared with other State-of-the-Art models.
All in One: Multi-Task Prompting for Graph Neural Networks (Extended Abstract)
Mar 11, 2024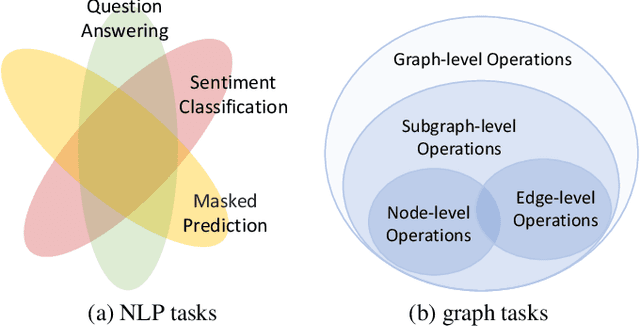
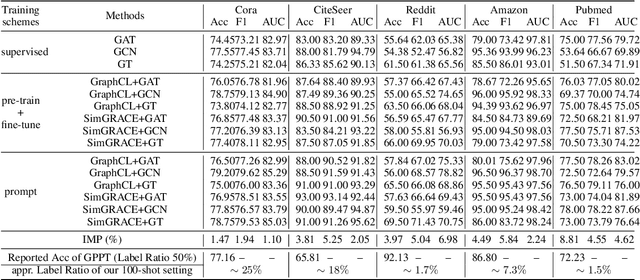
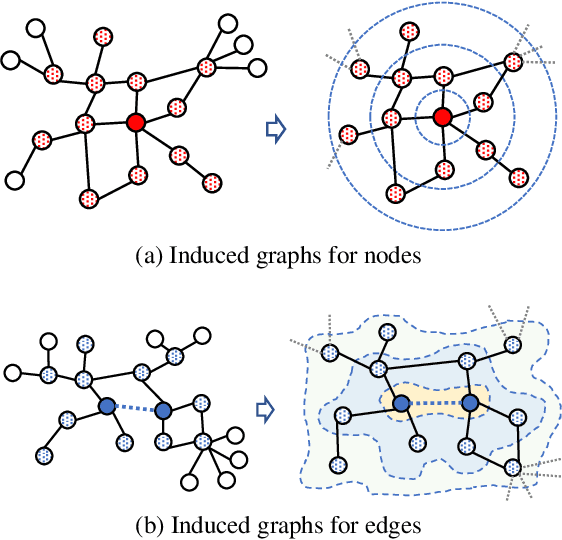
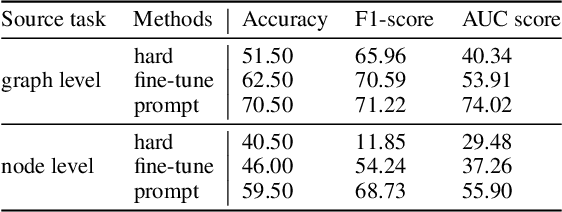
This paper is an extended abstract of our original work published in KDD23, where we won the best research paper award (Xiangguo Sun, Hong Cheng, Jia Li, Bo Liu, and Jihong Guan. All in one: Multi-task prompting for graph neural networks. KDD 23) The paper introduces a novel approach to bridging the gap between pre-trained graph models and the diverse tasks they're applied to, inspired by the success of prompt learning in NLP. Recognizing the challenge of aligning pre-trained models with varied graph tasks (node level, edge level, and graph level), which can lead to negative transfer and poor performance, we propose a multi-task prompting method for graphs. This method involves unifying graph and language prompt formats, enabling NLP's prompting strategies to be adapted for graph tasks. By analyzing the task space of graph applications, we reformulate problems to fit graph-level tasks and apply meta-learning to improve prompt initialization for multiple tasks. Experiments show our method's effectiveness in enhancing model performance across different graph tasks. Beyond the original work, in this extended abstract, we further discuss the graph prompt from a bigger picture and provide some of the latest work toward this area.
All in One and One for All: A Simple yet Effective Method towards Cross-domain Graph Pretraining
Feb 15, 2024Large Language Models (LLMs) have revolutionized the fields of computer vision (CV) and natural language processing (NLP). One of the most notable advancements of LLMs is that a single model is trained on vast and diverse datasets spanning multiple domains -- a paradigm we term `All in One'. This methodology empowers LLMs with super generalization capabilities, facilitating an encompassing comprehension of varied data distributions. Leveraging these capabilities, a single LLM demonstrates remarkable versatility across a variety of domains -- a paradigm we term `One for All'. However, applying this idea to the graph field remains a formidable challenge, with cross-domain pretraining often resulting in negative transfer. This issue is particularly important in few-shot learning scenarios, where the paucity of training data necessitates the incorporation of external knowledge sources. In response to this challenge, we propose a novel approach called Graph COordinators for PrEtraining (GCOPE), that harnesses the underlying commonalities across diverse graph datasets to enhance few-shot learning. Our novel methodology involves a unification framework that amalgamates disparate graph datasets during the pretraining phase to distill and transfer meaningful knowledge to target tasks. Extensive experiments across multiple graph datasets demonstrate the superior efficacy of our approach. By successfully leveraging the synergistic potential of multiple graph datasets for pretraining, our work stands as a pioneering contribution to the realm of graph foundational model.
A Survey of Graph Meets Large Language Model: Progress and Future Directions
Nov 28, 2023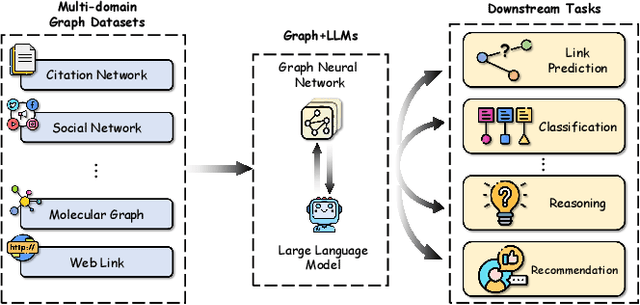
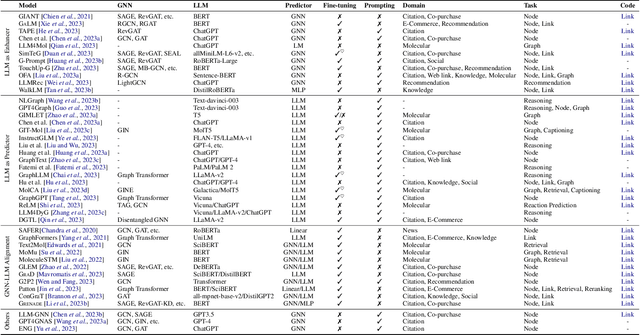
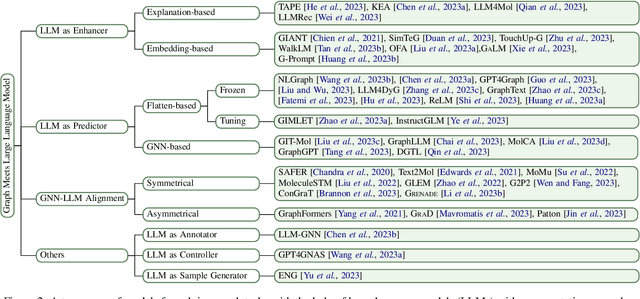
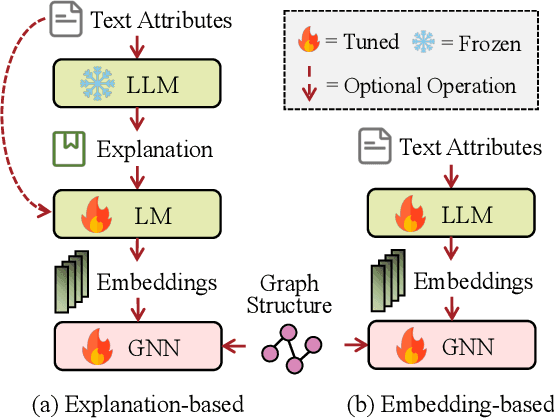
Graph plays a significant role in representing and analyzing complex relationships in real-world applications such as citation networks, social networks, and biological data. Recently, Large Language Models (LLMs), which have achieved tremendous success in various domains, have also been leveraged in graph-related tasks to surpass traditional Graph Neural Networks (GNNs) based methods and yield state-of-the-art performance. In this survey, we first present a comprehensive review and analysis of existing methods that integrate LLMs with graphs. First of all, we propose a new taxonomy, which organizes existing methods into three categories based on the role (i.e., enhancer, predictor, and alignment component) played by LLMs in graph-related tasks. Then we systematically survey the representative methods along the three categories of the taxonomy. Finally, we discuss the remaining limitations of existing studies and highlight promising avenues for future research. The relevant papers are summarized and will be consistently updated at: https://github.com/yhLeeee/Awesome-LLMs-in-Graph-tasks.
Graph Prompt Learning: A Comprehensive Survey and Beyond
Nov 28, 2023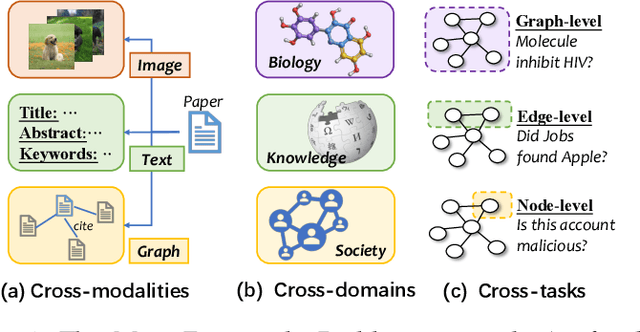

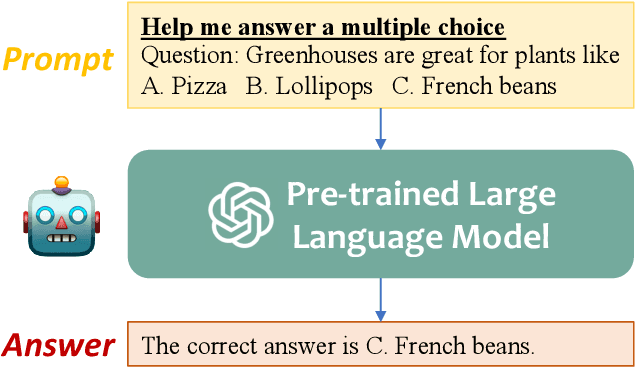
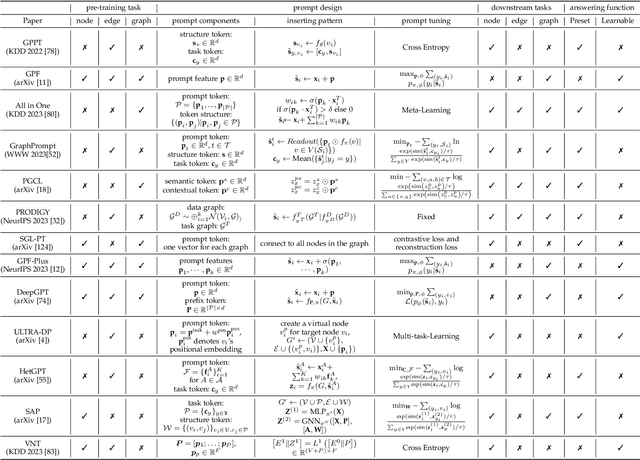
Artificial General Intelligence (AGI) has revolutionized numerous fields, yet its integration with graph data, a cornerstone in our interconnected world, remains nascent. This paper presents a pioneering survey on the emerging domain of graph prompts in AGI, addressing key challenges and opportunities in harnessing graph data for AGI applications. Despite substantial advancements in AGI across natural language processing and computer vision, the application to graph data is relatively underexplored. This survey critically evaluates the current landscape of AGI in handling graph data, highlighting the distinct challenges in cross-modality, cross-domain, and cross-task applications specific to graphs. Our work is the first to propose a unified framework for understanding graph prompt learning, offering clarity on prompt tokens, token structures, and insertion patterns in the graph domain. We delve into the intrinsic properties of graph prompts, exploring their flexibility, expressiveness, and interplay with existing graph models. A comprehensive taxonomy categorizes over 100 works in this field, aligning them with pre-training tasks across node-level, edge-level, and graph-level objectives. Additionally, we present, ProG, a Python library, and an accompanying website, to support and advance research in graph prompting. The survey culminates in a discussion of current challenges and future directions, offering a roadmap for research in graph prompting within AGI. Through this comprehensive analysis, we aim to catalyze further exploration and practical applications of AGI in graph data, underlining its potential to reshape AGI fields and beyond. ProG and the website can be accessed by \url{https://github.com/WxxShirley/Awesome-Graph-Prompt}, and \url{https://github.com/sheldonresearch/ProG}, respectively.
Counter-Empirical Attacking based on Adversarial Reinforcement Learning for Time-Relevant Scoring System
Nov 09, 2023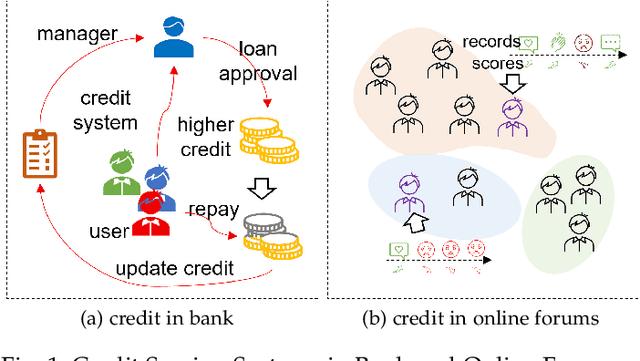
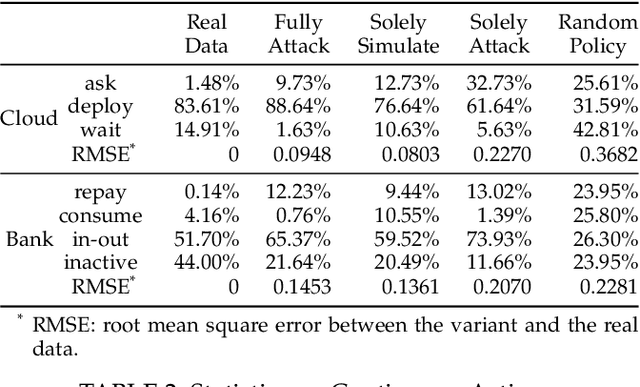
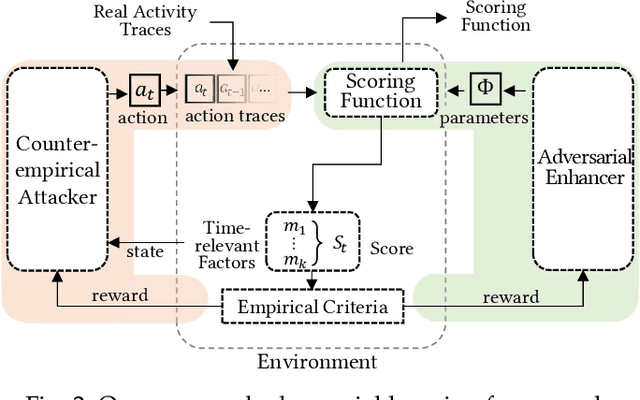
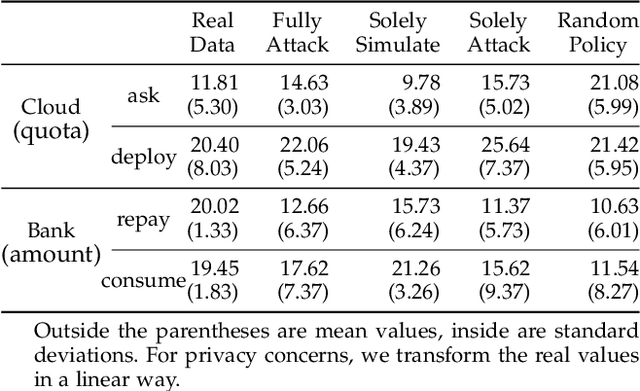
Scoring systems are commonly seen for platforms in the era of big data. From credit scoring systems in financial services to membership scores in E-commerce shopping platforms, platform managers use such systems to guide users towards the encouraged activity pattern, and manage resources more effectively and more efficiently thereby. To establish such scoring systems, several "empirical criteria" are firstly determined, followed by dedicated top-down design for each factor of the score, which usually requires enormous effort to adjust and tune the scoring function in the new application scenario. What's worse, many fresh projects usually have no ground-truth or any experience to evaluate a reasonable scoring system, making the designing even harder. To reduce the effort of manual adjustment of the scoring function in every new scoring system, we innovatively study the scoring system from the preset empirical criteria without any ground truth, and propose a novel framework to improve the system from scratch. In this paper, we propose a "counter-empirical attacking" mechanism that can generate "attacking" behavior traces and try to break the empirical rules of the scoring system. Then an adversarial "enhancer" is applied to evaluate the scoring system and find the improvement strategy. By training the adversarial learning problem, a proper scoring function can be learned to be robust to the attacking activity traces that are trying to violate the empirical criteria. Extensive experiments have been conducted on two scoring systems including a shared computing resource platform and a financial credit system. The experimental results have validated the effectiveness of our proposed framework.
Language Agents for Detecting Implicit Stereotypes in Text-to-image Models at Scale
Nov 02, 2023

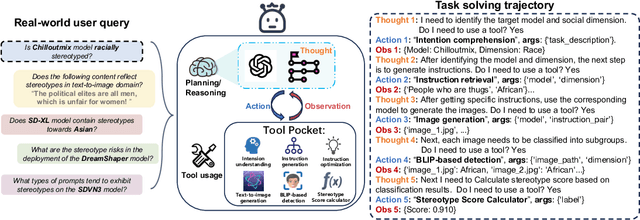

The recent surge in the research of diffusion models has accelerated the adoption of text-to-image models in various Artificial Intelligence Generated Content (AIGC) commercial products. While these exceptional AIGC products are gaining increasing recognition and sparking enthusiasm among consumers, the questions regarding whether, when, and how these models might unintentionally reinforce existing societal stereotypes remain largely unaddressed. Motivated by recent advancements in language agents, here we introduce a novel agent architecture tailored for stereotype detection in text-to-image models. This versatile agent architecture is capable of accommodating free-form detection tasks and can autonomously invoke various tools to facilitate the entire process, from generating corresponding instructions and images, to detecting stereotypes. We build the stereotype-relevant benchmark based on multiple open-text datasets, and apply this architecture to commercial products and popular open source text-to-image models. We find that these models often display serious stereotypes when it comes to certain prompts about personal characteristics, social cultural context and crime-related aspects. In summary, these empirical findings underscore the pervasive existence of stereotypes across social dimensions, including gender, race, and religion, which not only validate the effectiveness of our proposed approach, but also emphasize the critical necessity of addressing potential ethical risks in the burgeoning realm of AIGC. As AIGC continues its rapid expansion trajectory, with new models and plugins emerging daily in staggering numbers, the challenge lies in the timely detection and mitigation of potential biases within these models.