 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYun Xiong
Beyond the Known: Novel Class Discovery for Open-world Graph Learning
Mar 29, 2024
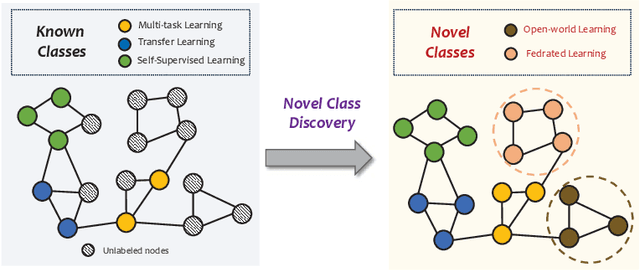
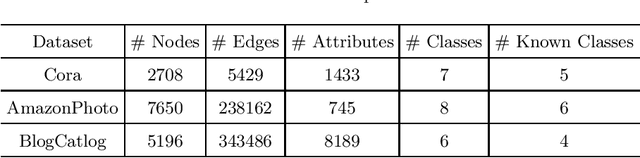


Node classification on graphs is of great importance in many applications. Due to the limited labeling capability and evolution in real-world open scenarios, novel classes can emerge on unlabeled testing nodes. However, little attention has been paid to novel class discovery on graphs. Discovering novel classes is challenging as novel and known class nodes are correlated by edges, which makes their representations indistinguishable when applying message passing GNNs. Furthermore, the novel classes lack labeling information to guide the learning process. In this paper, we propose a novel method Open-world gRAph neuraL network (ORAL) to tackle these challenges. ORAL first detects correlations between classes through semi-supervised prototypical learning. Inter-class correlations are subsequently eliminated by the prototypical attention network, leading to distinctive representations for different classes. Furthermore, to fully explore multi-scale graph features for alleviating label deficiencies, ORAL generates pseudo-labels by aligning and ensembling label estimations from multiple stacked prototypical attention networks. Extensive experiments on several benchmark datasets show the effectiveness of our proposed method.
DDIPrompt: Drug-Drug Interaction Event Prediction based on Graph Prompt Learning
Feb 18, 2024Recently, Graph Neural Networks have become increasingly prevalent in predicting adverse drug-drug interactions (DDI) due to their proficiency in modeling the intricate associations between atoms and functional groups within and across drug molecules. However, they are still hindered by two significant challenges: (1) the issue of highly imbalanced event distribution, which is a common but critical problem in medical datasets where certain interactions are vastly underrepresented. This imbalance poses a substantial barrier to achieving accurate and reliable DDI predictions. (2) the scarcity of labeled data for rare events, which is a pervasive issue in the medical field where rare yet potentially critical interactions are often overlooked or under-studied due to limited available data. In response, we offer DDIPrompt, an innovative panacea inspired by the recent advancements in graph prompting. Our framework aims to address these issues by leveraging the intrinsic knowledge from pre-trained models, which can be efficiently deployed with minimal downstream data. Specifically, to solve the first challenge, DDIPrompt employs augmented links between drugs, considering both structural and interactive proximity. It features a hierarchical pre-training strategy that comprehends intra-molecular structures and inter-molecular interactions, fostering a comprehensive and unbiased understanding of drug properties. For the second challenge, we implement a prototype-enhanced prompting mechanism during inference. This mechanism, refined by few-shot examples from each category, effectively harnesses the rich pre-training knowledge to enhance prediction accuracy, particularly for these rare but crucial interactions. Comprehensive evaluations on two benchmark datasets demonstrate the superiority of DDIPrompt, particularly in predicting rare DDI events.
DiffPoint: Single and Multi-view Point Cloud Reconstruction with ViT Based Diffusion Model
Feb 17, 2024As the task of 2D-to-3D reconstruction has gained significant attention in various real-world scenarios, it becomes crucial to be able to generate high-quality point clouds. Despite the recent success of deep learning models in generating point clouds, there are still challenges in producing high-fidelity results due to the disparities between images and point clouds. While vision transformers (ViT) and diffusion models have shown promise in various vision tasks, their benefits for reconstructing point clouds from images have not been demonstrated yet. In this paper, we first propose a neat and powerful architecture called DiffPoint that combines ViT and diffusion models for the task of point cloud reconstruction. At each diffusion step, we divide the noisy point clouds into irregular patches. Then, using a standard ViT backbone that treats all inputs as tokens (including time information, image embeddings, and noisy patches), we train our model to predict target points based on input images. We evaluate DiffPoint on both single-view and multi-view reconstruction tasks and achieve state-of-the-art results. Additionally, we introduce a unified and flexible feature fusion module for aggregating image features from single or multiple input images. Furthermore, our work demonstrates the feasibility of applying unified architectures across languages and images to improve 3D reconstruction tasks.
Prompt Learning on Temporal Interaction Graphs
Feb 09, 2024Temporal Interaction Graphs (TIGs) are widely utilized to represent real-world systems. To facilitate representation learning on TIGs, researchers have proposed a series of TIG models. However, these models are still facing two tough gaps between the pre-training and downstream predictions in their ``pre-train, predict'' training paradigm. First, the temporal discrepancy between the pre-training and inference data severely undermines the models' applicability in distant future predictions on the dynamically evolving data. Second, the semantic divergence between pretext and downstream tasks hinders their practical applications, as they struggle to align with their learning and prediction capabilities across application scenarios. Recently, the ``pre-train, prompt'' paradigm has emerged as a lightweight mechanism for model generalization. Applying this paradigm is a potential solution to solve the aforementioned challenges. However, the adaptation of this paradigm to TIGs is not straightforward. The application of prompting in static graph contexts falls short in temporal settings due to a lack of consideration for time-sensitive dynamics and a deficiency in expressive power. To address this issue, we introduce Temporal Interaction Graph Prompting (TIGPrompt), a versatile framework that seamlessly integrates with TIG models, bridging both the temporal and semantic gaps. In detail, we propose a temporal prompt generator to offer temporally-aware prompts for different tasks. These prompts stand out for their minimalistic design, relying solely on the tuning of the prompt generator with very little supervision data. To cater to varying computational resource demands, we propose an extended ``pre-train, prompt-based fine-tune'' paradigm, offering greater flexibility. Through extensive experiments, the TIGPrompt demonstrates the SOTA performance and remarkable efficiency advantages.
Retrieval-Augmented Generation for Large Language Models: A Survey
Jan 03, 2024Large Language Models (LLMs) demonstrate significant capabilities but face challenges such as hallucination, outdated knowledge, and non-transparent, untraceable reasoning processes. Retrieval-Augmented Generation (RAG) has emerged as a promising solution by incorporating knowledge from external databases. This enhances the accuracy and credibility of the models, particularly for knowledge-intensive tasks, and allows for continuous knowledge updates and integration of domain-specific information. RAG synergistically merges LLMs' intrinsic knowledge with the vast, dynamic repositories of external databases. This comprehensive review paper offers a detailed examination of the progression of RAG paradigms, encompassing the Naive RAG, the Advanced RAG, and the Modular RAG. It meticulously scrutinizes the tripartite foundation of RAG frameworks, which includes the retrieval , the generation and the augmentation techniques. The paper highlights the state-of-the-art technologies embedded in each of these critical components, providing a profound understanding of the advancements in RAG systems. Furthermore, this paper introduces the metrics and benchmarks for assessing RAG models, along with the most up-to-date evaluation framework. In conclusion, the paper delineates prospective avenues for research, including the identification of challenges, the expansion of multi-modalities, and the progression of the RAG infrastructure and its ecosystem.
Graph Prompt Learning: A Comprehensive Survey and Beyond
Nov 28, 2023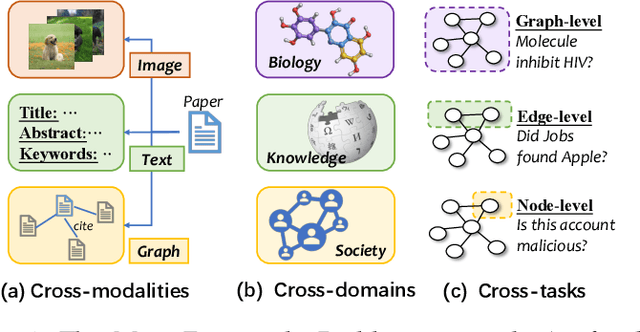

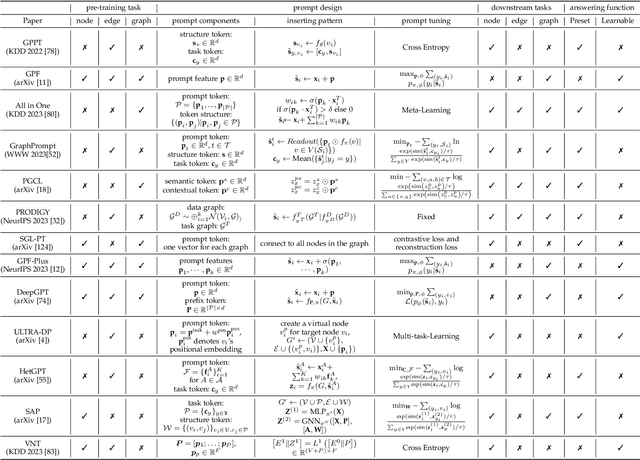
Artificial General Intelligence (AGI) has revolutionized numerous fields, yet its integration with graph data, a cornerstone in our interconnected world, remains nascent. This paper presents a pioneering survey on the emerging domain of graph prompts in AGI, addressing key challenges and opportunities in harnessing graph data for AGI applications. Despite substantial advancements in AGI across natural language processing and computer vision, the application to graph data is relatively underexplored. This survey critically evaluates the current landscape of AGI in handling graph data, highlighting the distinct challenges in cross-modality, cross-domain, and cross-task applications specific to graphs. Our work is the first to propose a unified framework for understanding graph prompt learning, offering clarity on prompt tokens, token structures, and insertion patterns in the graph domain. We delve into the intrinsic properties of graph prompts, exploring their flexibility, expressiveness, and interplay with existing graph models. A comprehensive taxonomy categorizes over 100 works in this field, aligning them with pre-training tasks across node-level, edge-level, and graph-level objectives. Additionally, we present, ProG, a Python library, and an accompanying website, to support and advance research in graph prompting. The survey culminates in a discussion of current challenges and future directions, offering a roadmap for research in graph prompting within AGI. Through this comprehensive analysis, we aim to catalyze further exploration and practical applications of AGI in graph data, underlining its potential to reshape AGI fields and beyond. ProG and the website can be accessed by \url{https://github.com/WxxShirley/Awesome-Graph-Prompt}, and \url{https://github.com/sheldonresearch/ProG}, respectively.
Joint Learning of Local and Global Features for Aspect-based Sentiment Classification
Nov 02, 2023Aspect-based sentiment classification (ASC) aims to judge the sentiment polarity conveyed by the given aspect term in a sentence. The sentiment polarity is not only determined by the local context but also related to the words far away from the given aspect term. Most recent efforts related to the attention-based models can not sufficiently distinguish which words they should pay more attention to in some cases. Meanwhile, graph-based models are coming into ASC to encode syntactic dependency tree information. But these models do not fully leverage syntactic dependency trees as they neglect to incorporate dependency relation tag information into representation learning effectively. In this paper, we address these problems by effectively modeling the local and global features. Firstly, we design a local encoder containing: a Gaussian mask layer and a covariance self-attention layer. The Gaussian mask layer tends to adjust the receptive field around aspect terms adaptively to deemphasize the effects of unrelated words and pay more attention to local information. The covariance self-attention layer can distinguish the attention weights of different words more obviously. Furthermore, we propose a dual-level graph attention network as a global encoder by fully employing dependency tag information to capture long-distance information effectively. Our model achieves state-of-the-art performance on both SemEval 2014 and Twitter datasets.
MAGIC: Detecting Advanced Persistent Threats via Masked Graph Representation Learning
Oct 15, 2023



Advance Persistent Threats (APTs), adopted by most delicate attackers, are becoming increasing common and pose great threat to various enterprises and institutions. Data provenance analysis on provenance graphs has emerged as a common approach in APT detection. However, previous works have exhibited several shortcomings: (1) requiring attack-containing data and a priori knowledge of APTs, (2) failing in extracting the rich contextual information buried within provenance graphs and (3) becoming impracticable due to their prohibitive computation overhead and memory consumption. In this paper, we introduce MAGIC, a novel and flexible self-supervised APT detection approach capable of performing multi-granularity detection under different level of supervision. MAGIC leverages masked graph representation learning to model benign system entities and behaviors, performing efficient deep feature extraction and structure abstraction on provenance graphs. By ferreting out anomalous system behaviors via outlier detection methods, MAGIC is able to perform both system entity level and batched log level APT detection. MAGIC is specially designed to handle concept drift with a model adaption mechanism and successfully applies to universal conditions and detection scenarios. We evaluate MAGIC on three widely-used datasets, including both real-world and simulated attacks. Evaluation results indicate that MAGIC achieves promising detection results in all scenarios and shows enormous advantage over state-of-the-art APT detection approaches in performance overhead.
SPEED: Streaming Partition and Parallel Acceleration for Temporal Interaction Graph Embedding
Sep 11, 2023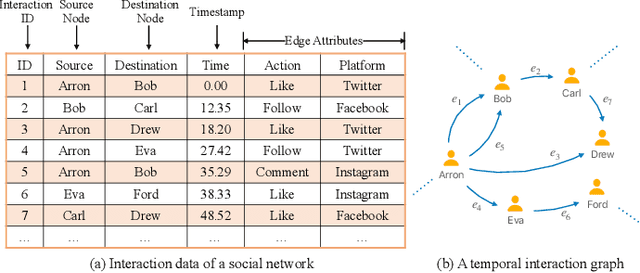
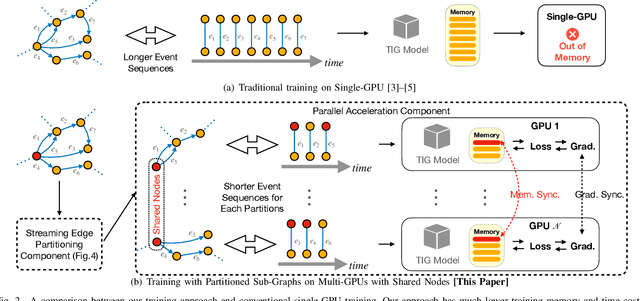
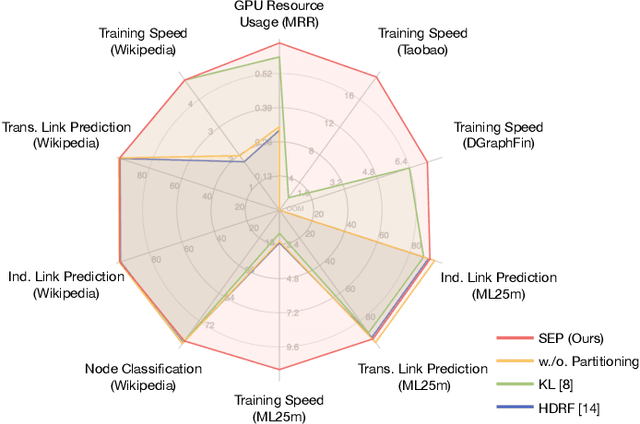
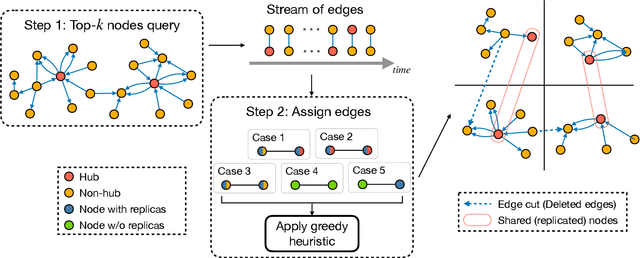
Temporal Interaction Graphs (TIGs) are widely employed to model intricate real-world systems such as financial systems and social networks. To capture the dynamism and interdependencies of nodes, existing TIG embedding models need to process edges sequentially and chronologically. However, this requirement prevents it from being processed in parallel and struggle to accommodate burgeoning data volumes to GPU. Consequently, many large-scale temporal interaction graphs are confined to CPU processing. Furthermore, a generalized GPU scaling and acceleration approach remains unavailable. To facilitate large-scale TIGs' implementation on GPUs for acceleration, we introduce a novel training approach namely Streaming Edge Partitioning and Parallel Acceleration for Temporal Interaction Graph Embedding (SPEED). The SPEED is comprised of a Streaming Edge Partitioning Component (SEP) which addresses space overhead issue by assigning fewer nodes to each GPU, and a Parallel Acceleration Component (PAC) which enables simultaneous training of different sub-graphs, addressing time overhead issue. Our method can achieve a good balance in computing resources, computing time, and downstream task performance. Empirical validation across 7 real-world datasets demonstrates the potential to expedite training speeds by a factor of up to 19.29x. Simultaneously, resource consumption of a single-GPU can be diminished by up to 69%, thus enabling the multiple GPU-based training and acceleration encompassing millions of nodes and billions of edges. Furthermore, our approach also maintains its competitiveness in downstream tasks.
RDGSL: Dynamic Graph Representation Learning with Structure Learning
Sep 05, 2023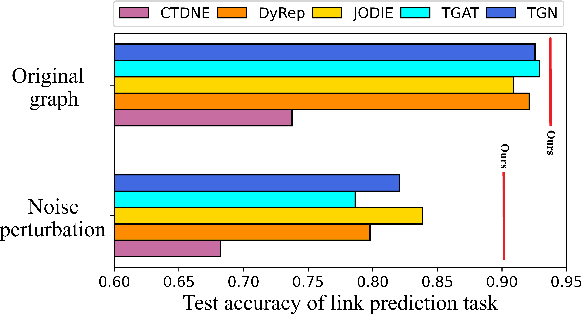

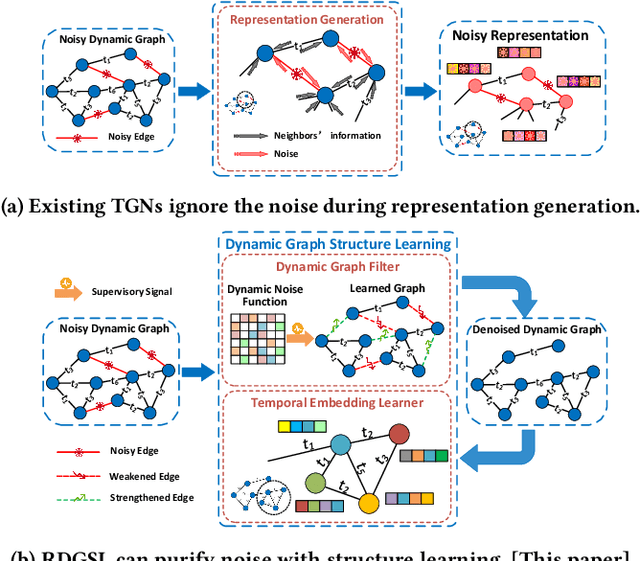
Temporal Graph Networks (TGNs) have shown remarkable performance in learning representation for continuous-time dynamic graphs. However, real-world dynamic graphs typically contain diverse and intricate noise. Noise can significantly degrade the quality of representation generation, impeding the effectiveness of TGNs in downstream tasks. Though structure learning is widely applied to mitigate noise in static graphs, its adaptation to dynamic graph settings poses two significant challenges. i) Noise dynamics. Existing structure learning methods are ill-equipped to address the temporal aspect of noise, hampering their effectiveness in such dynamic and ever-changing noise patterns. ii) More severe noise. Noise may be introduced along with multiple interactions between two nodes, leading to the re-pollution of these nodes and consequently causing more severe noise compared to static graphs. In this paper, we present RDGSL, a representation learning method in continuous-time dynamic graphs. Meanwhile, we propose dynamic graph structure learning, a novel supervisory signal that empowers RDGSL with the ability to effectively combat noise in dynamic graphs. To address the noise dynamics issue, we introduce the Dynamic Graph Filter, where we innovatively propose a dynamic noise function that dynamically captures both current and historical noise, enabling us to assess the temporal aspect of noise and generate a denoised graph. We further propose the Temporal Embedding Learner to tackle the challenge of more severe noise, which utilizes an attention mechanism to selectively turn a blind eye to noisy edges and hence focus on normal edges, enhancing the expressiveness for representation generation that remains resilient to noise. Our method demonstrates robustness towards downstream tasks, resulting in up to 5.1% absolute AUC improvement in evolving classification versus the second-best baseline.