 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinyu Gao
Spec-Gaussian: Anisotropic View-Dependent Appearance for 3D Gaussian Splatting
Feb 24, 2024
The recent advancements in 3D Gaussian splatting (3D-GS) have not only facilitated real-time rendering through modern GPU rasterization pipelines but have also attained state-of-the-art rendering quality. Nevertheless, despite its exceptional rendering quality and performance on standard datasets, 3D-GS frequently encounters difficulties in accurately modeling specular and anisotropic components. This issue stems from the limited ability of spherical harmonics (SH) to represent high-frequency information. To overcome this challenge, we introduce Spec-Gaussian, an approach that utilizes an anisotropic spherical Gaussian (ASG) appearance field instead of SH for modeling the view-dependent appearance of each 3D Gaussian. Additionally, we have developed a coarse-to-fine training strategy to improve learning efficiency and eliminate floaters caused by overfitting in real-world scenes. Our experimental results demonstrate that our method surpasses existing approaches in terms of rendering quality. Thanks to ASG, we have significantly improved the ability of 3D-GS to model scenes with specular and anisotropic components without increasing the number of 3D Gaussians. This improvement extends the applicability of 3D GS to handle intricate scenarios with specular and anisotropic surfaces.
Retrieval-Augmented Generation for Large Language Models: A Survey
Jan 03, 2024Large Language Models (LLMs) demonstrate significant capabilities but face challenges such as hallucination, outdated knowledge, and non-transparent, untraceable reasoning processes. Retrieval-Augmented Generation (RAG) has emerged as a promising solution by incorporating knowledge from external databases. This enhances the accuracy and credibility of the models, particularly for knowledge-intensive tasks, and allows for continuous knowledge updates and integration of domain-specific information. RAG synergistically merges LLMs' intrinsic knowledge with the vast, dynamic repositories of external databases. This comprehensive review paper offers a detailed examination of the progression of RAG paradigms, encompassing the Naive RAG, the Advanced RAG, and the Modular RAG. It meticulously scrutinizes the tripartite foundation of RAG frameworks, which includes the retrieval , the generation and the augmentation techniques. The paper highlights the state-of-the-art technologies embedded in each of these critical components, providing a profound understanding of the advancements in RAG systems. Furthermore, this paper introduces the metrics and benchmarks for assessing RAG models, along with the most up-to-date evaluation framework. In conclusion, the paper delineates prospective avenues for research, including the identification of challenges, the expansion of multi-modalities, and the progression of the RAG infrastructure and its ecosystem.
Ziya-Visual: Bilingual Large Vision-Language Model via Multi-Task Instruction Tuning
Oct 29, 2023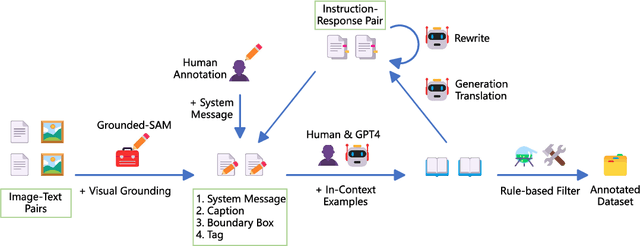
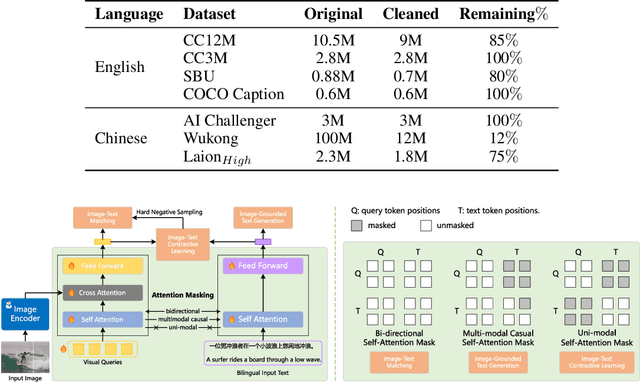

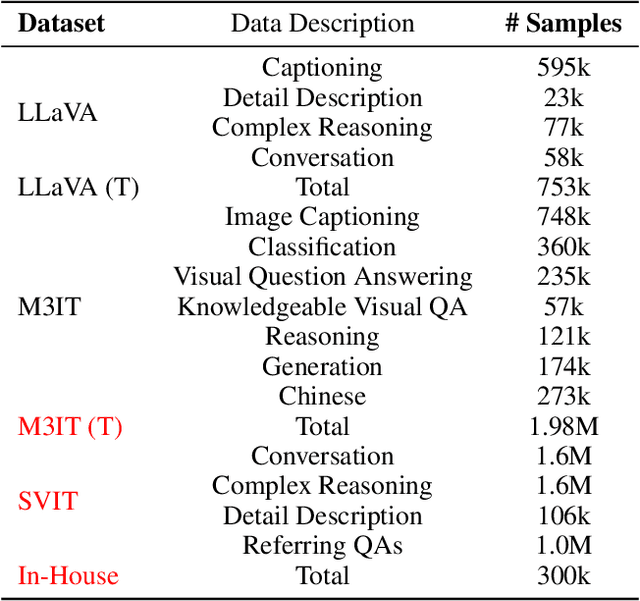
Recent advancements enlarge the capabilities of large language models (LLMs) in zero-shot image-to-text generation and understanding by integrating multi-modal inputs. However, such success is typically limited to English scenarios due to the lack of large-scale and high-quality non-English multi-modal resources, making it extremely difficult to establish competitive counterparts in other languages. In this paper, we introduce the Ziya-Visual series, a set of bilingual large-scale vision-language models (LVLMs) designed to incorporate visual semantics into LLM for multi-modal dialogue. Composed of Ziya-Visual-Base and Ziya-Visual-Chat, our models adopt the Querying Transformer from BLIP-2, further exploring the assistance of optimization schemes such as instruction tuning, multi-stage training and low-rank adaptation module for visual-language alignment. In addition, we stimulate the understanding ability of GPT-4 in multi-modal scenarios, translating our gathered English image-text datasets into Chinese and generating instruction-response through the in-context learning method. The experiment results demonstrate that compared to the existing LVLMs, Ziya-Visual achieves competitive performance across a wide range of English-only tasks including zero-shot image-text retrieval, image captioning, and visual question answering. The evaluation leaderboard accessed by GPT-4 also indicates that our models possess satisfactory image-text understanding and generation capabilities in Chinese multi-modal scenario dialogues. Code, demo and models are available at ~\url{https://huggingface.co/IDEA-CCNL/Ziya-BLIP2-14B-Visual-v1}.
SIRe-IR: Inverse Rendering for BRDF Reconstruction with Shadow and Illumination Removal in High-Illuminance Scenes
Oct 19, 2023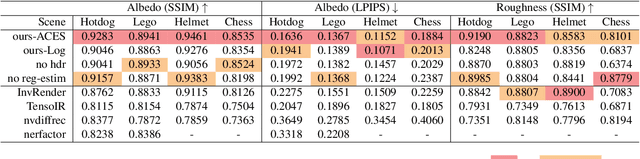
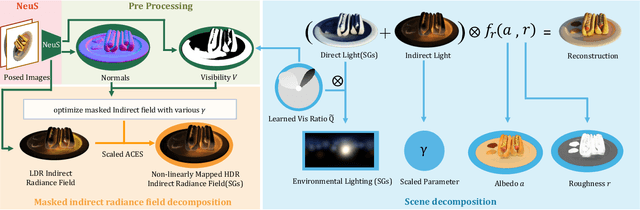


Implicit neural representation has opened up new possibilities for inverse rendering. However, existing implicit neural inverse rendering methods struggle to handle strongly illuminated scenes with significant shadows and indirect illumination. The existence of shadows and reflections can lead to an inaccurate understanding of scene geometry, making precise factorization difficult. To this end, we present SIRe-IR, an implicit neural inverse rendering approach that uses non-linear mapping and regularized visibility estimation to decompose the scene into environment map, albedo, and roughness. By accurately modeling the indirect radiance field, normal, visibility, and direct light simultaneously, we are able to remove both shadows and indirect illumination in materials without imposing strict constraints on the scene. Even in the presence of intense illumination, our method recovers high-quality albedo and roughness with no shadow interference. SIRe-IR outperforms existing methods in both quantitative and qualitative evaluations.
Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction
Sep 22, 2023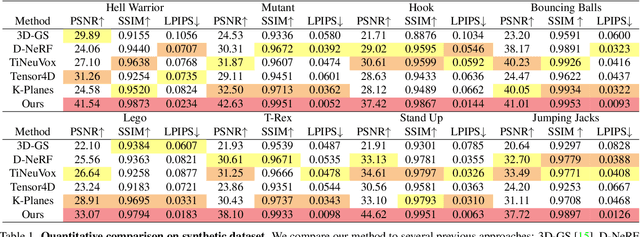
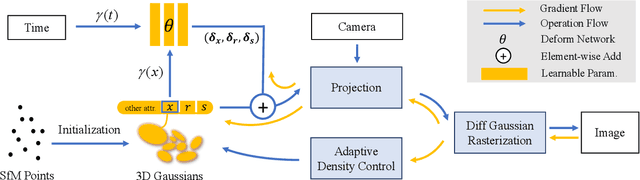
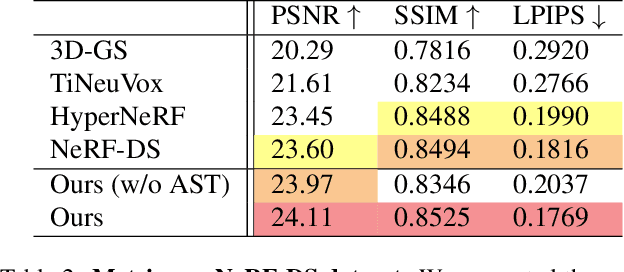

Implicit neural representation has opened up new avenues for dynamic scene reconstruction and rendering. Nonetheless, state-of-the-art methods of dynamic neural rendering rely heavily on these implicit representations, which frequently struggle with accurately capturing the intricate details of objects in the scene. Furthermore, implicit methods struggle to achieve real-time rendering in general dynamic scenes, limiting their use in a wide range of tasks. To address the issues, we propose a deformable 3D Gaussians Splatting method that reconstructs scenes using explicit 3D Gaussians and learns Gaussians in canonical space with a deformation field to model monocular dynamic scenes. We also introduced a smoothing training mechanism with no extra overhead to mitigate the impact of inaccurate poses in real datasets on the smoothness of time interpolation tasks. Through differential gaussian rasterization, the deformable 3D Gaussians not only achieve higher rendering quality but also real-time rendering speed. Experiments show that our method outperforms existing methods significantly in terms of both rendering quality and speed, making it well-suited for tasks such as novel-view synthesis, time synthesis, and real-time rendering.
A General Implicit Framework for Fast NeRF Composition and Rendering
Aug 14, 2023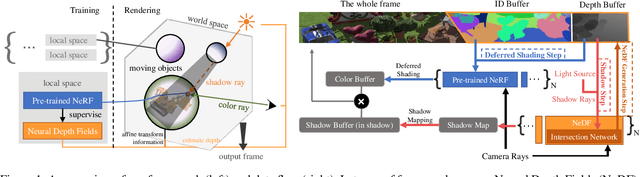

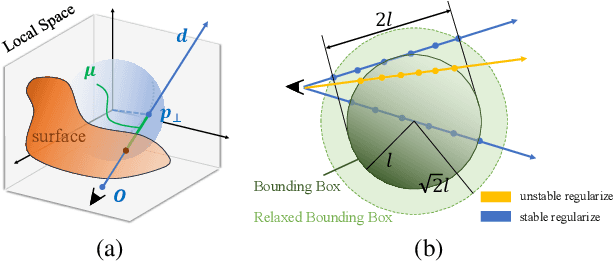
A variety of Neural Radiance Fields (NeRF) methods have recently achieved remarkable success in high render speed. However, current accelerating methods are specialized and incompatible with various implicit methods, preventing real-time composition over various types of NeRF works. Because NeRF relies on sampling along rays, it is possible to provide general guidance for acceleration. To that end, we propose a general implicit pipeline for composing NeRF objects quickly. Our method enables the casting of dynamic shadows within or between objects using analytical light sources while allowing multiple NeRF objects to be seamlessly placed and rendered together with any arbitrary rigid transformations. Mainly, our work introduces a new surface representation known as Neural Depth Fields (NeDF) that quickly determines the spatial relationship between objects by allowing direct intersection computation between rays and implicit surfaces. It leverages an intersection neural network to query NeRF for acceleration instead of depending on an explicit spatial structure.Our proposed method is the first to enable both the progressive and interactive composition of NeRF objects. Additionally, it also serves as a previewing plugin for a range of existing NeRF works.
Multi-Objective Optimisation of URLLC-Based Metaverse Services
Jul 25, 2023



Metaverse aims for building a fully immersive virtual shared space, where the users are able to engage in various activities. To successfully deploy the service for each user, the Metaverse service provider and network service provider generally localise the user first and then support the communication between the base station (BS) and the user. A reconfigurable intelligent surface (RIS) is capable of creating a reflected link between the BS and the user to enhance line-of-sight. Furthermore, the new key performance indicators (KPIs) in Metaverse, such as its energy-consumption-dependent total service cost and transmission latency, are often overlooked in ultra-reliable low latency communication (URLLC) designs, which have to be carefully considered in next-generation URLLC (xURLLC) regimes. In this paper, our design objective is to jointly optimise the transmit power, the RIS phase shifts, and the decoding error probability to simultaneously minimise the total service cost and transmission latency and approach the Pareto Front (PF). We conceive a twin-stage central controller, which aims for localising the users first and then supports the communication between the BS and users. In the first stage, we localise the Metaverse users, where the stochastic gradient descent (SGD) algorithm is invoked for accurate user localisation. In the second stage, a meta-learning-based position-dependent multi-objective soft actor and critic (MO-SAC) algorithm is proposed to approach the PF between the total service cost and transmission latency and to further optimise the latency-dependent reliability. Our numerical results demonstrate that ...
Benchmarking Robustness of AI-enabled Multi-sensor Fusion Systems: Challenges and Opportunities
Jun 06, 2023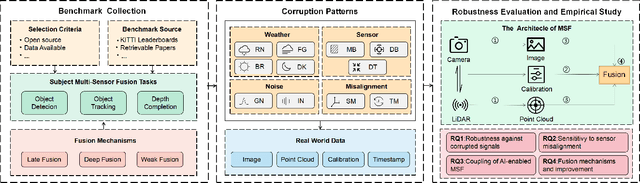
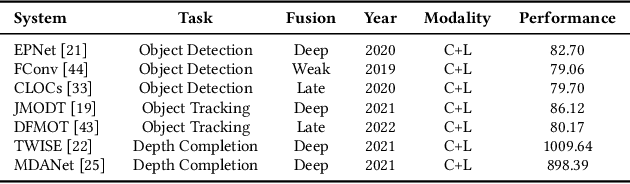
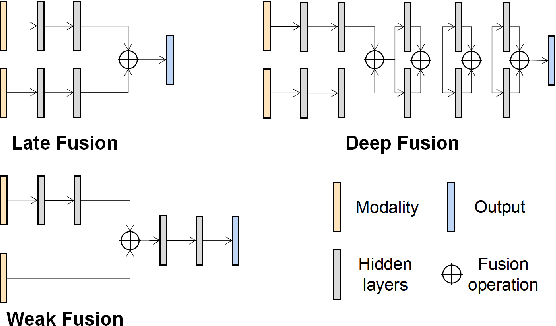
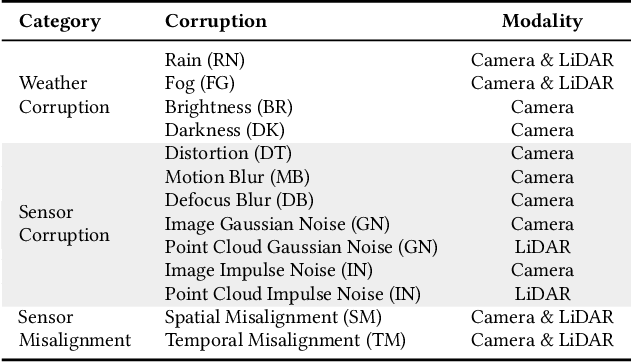
Multi-Sensor Fusion (MSF) based perception systems have been the foundation in supporting many industrial applications and domains, such as self-driving cars, robotic arms, and unmanned aerial vehicles. Over the past few years, the fast progress in data-driven artificial intelligence (AI) has brought a fast-increasing trend to empower MSF systems by deep learning techniques to further improve performance, especially on intelligent systems and their perception systems. Although quite a few AI-enabled MSF perception systems and techniques have been proposed, up to the present, limited benchmarks that focus on MSF perception are publicly available. Given that many intelligent systems such as self-driving cars are operated in safety-critical contexts where perception systems play an important role, there comes an urgent need for a more in-depth understanding of the performance and reliability of these MSF systems. To bridge this gap, we initiate an early step in this direction and construct a public benchmark of AI-enabled MSF-based perception systems including three commonly adopted tasks (i.e., object detection, object tracking, and depth completion). Based on this, to comprehensively understand MSF systems' robustness and reliability, we design 14 common and realistic corruption patterns to synthesize large-scale corrupted datasets. We further perform a systematic evaluation of these systems through our large-scale evaluation. Our results reveal the vulnerability of the current AI-enabled MSF perception systems, calling for researchers and practitioners to take robustness and reliability into account when designing AI-enabled MSF.
Reconfigurable Massive MIMO: Harnessing the Power of the Electromagnetic Domain for Enhanced Information Transfer
Feb 22, 2023


The capacity of commercial massive multiple-input multiple-output (mMIMO) systems is constrained by the limited array aperture at the base station, and cannot meet the ever-increasing traffic demands of wireless networks. Given the array aperture, holographic MIMO with infinitesimal antenna spacing can maximize the capacity, but is physically unrealizable. As a promising alternative, reconfigurable mMIMO is proposed to harness the unexploited power of the electromagnetic (EM) domain for enhanced information transfer. Specifically, the reconfigurable pixel antenna technology provides each antenna with an adjustable EM radiation (EMR) pattern, introducing extra degrees of freedom for information transfer in the EM domain. In this article, we present the concept and benefits of availing the EMR domain for mMIMO transmission. Moreover, we propose a viable architecture for reconfigurable mMIMO systems, and the associated system model and downlink precoding are also discussed. In particular, a three-level precoding scheme is proposed, and simulation results verify its considerable spectral and energy efficiency advantages compared to traditional mMIMO systems. Finally, we further discuss the challenges, insights, and prospects of deploying reconfigurable mMIMO, along with the associated hardware, algorithms, and fundamental theory.
TCBERT: A Technical Report for Chinese Topic Classification BERT
Nov 21, 2022



Bidirectional Encoder Representations from Transformers or BERT~\cite{devlin-etal-2019-bert} has been one of the base models for various NLP tasks due to its remarkable performance. Variants customized for different languages and tasks are proposed to further improve the performance. In this work, we investigate supervised continued pre-training~\cite{gururangan-etal-2020-dont} on BERT for Chinese topic classification task. Specifically, we incorporate prompt-based learning and contrastive learning into the pre-training. To adapt to the task of Chinese topic classification, we collect around 2.1M Chinese data spanning various topics. The pre-trained Chinese Topic Classification BERTs (TCBERTs) with different parameter sizes are open-sourced at \url{https://huggingface.co/IDEA-CCNL}.