 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuqing Zhang
SDR-Former: A Siamese Dual-Resolution Transformer for Liver Lesion Classification Using 3D Multi-Phase Imaging
Feb 27, 2024
Automated classification of liver lesions in multi-phase CT and MR scans is of clinical significance but challenging. This study proposes a novel Siamese Dual-Resolution Transformer (SDR-Former) framework, specifically designed for liver lesion classification in 3D multi-phase CT and MR imaging with varying phase counts. The proposed SDR-Former utilizes a streamlined Siamese Neural Network (SNN) to process multi-phase imaging inputs, possessing robust feature representations while maintaining computational efficiency. The weight-sharing feature of the SNN is further enriched by a hybrid Dual-Resolution Transformer (DR-Former), comprising a 3D Convolutional Neural Network (CNN) and a tailored 3D Transformer for processing high- and low-resolution images, respectively. This hybrid sub-architecture excels in capturing detailed local features and understanding global contextual information, thereby, boosting the SNN's feature extraction capabilities. Additionally, a novel Adaptive Phase Selection Module (APSM) is introduced, promoting phase-specific intercommunication and dynamically adjusting each phase's influence on the diagnostic outcome. The proposed SDR-Former framework has been validated through comprehensive experiments on two clinical datasets: a three-phase CT dataset and an eight-phase MR dataset. The experimental results affirm the efficacy of the proposed framework. To support the scientific community, we are releasing our extensive multi-phase MR dataset for liver lesion analysis to the public. This pioneering dataset, being the first publicly available multi-phase MR dataset in this field, also underpins the MICCAI LLD-MMRI Challenge. The dataset is accessible at:https://bit.ly/3IyYlgN.
Communication-Efficient Personalized Federated Learning for Speech-to-Text Tasks
Jan 18, 2024To protect privacy and meet legal regulations, federated learning (FL) has gained significant attention for training speech-to-text (S2T) systems, including automatic speech recognition (ASR) and speech translation (ST). However, the commonly used FL approach (i.e., \textsc{FedAvg}) in S2T tasks typically suffers from extensive communication overhead due to multi-round interactions based on the whole model and performance degradation caused by data heterogeneity among clients.To address these issues, we propose a personalized federated S2T framework that introduces \textsc{FedLoRA}, a lightweight LoRA module for client-side tuning and interaction with the server to minimize communication overhead, and \textsc{FedMem}, a global model equipped with a $k$-nearest-neighbor ($k$NN) classifier that captures client-specific distributional shifts to achieve personalization and overcome data heterogeneity. Extensive experiments based on Conformer and Whisper backbone models on CoVoST and GigaSpeech benchmarks show that our approach significantly reduces the communication overhead on all S2T tasks and effectively personalizes the global model to overcome data heterogeneity.
Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction
Sep 22, 2023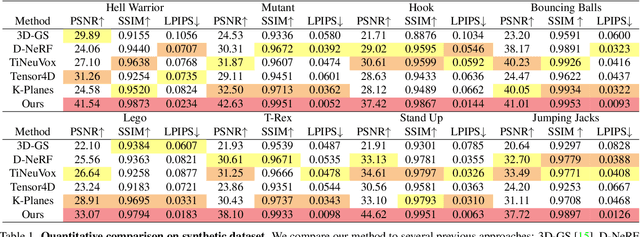
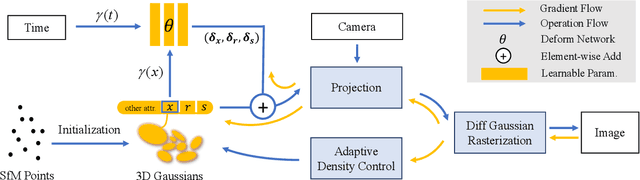
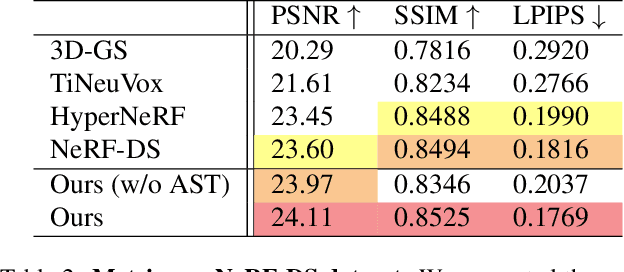

Implicit neural representation has opened up new avenues for dynamic scene reconstruction and rendering. Nonetheless, state-of-the-art methods of dynamic neural rendering rely heavily on these implicit representations, which frequently struggle with accurately capturing the intricate details of objects in the scene. Furthermore, implicit methods struggle to achieve real-time rendering in general dynamic scenes, limiting their use in a wide range of tasks. To address the issues, we propose a deformable 3D Gaussians Splatting method that reconstructs scenes using explicit 3D Gaussians and learns Gaussians in canonical space with a deformation field to model monocular dynamic scenes. We also introduced a smoothing training mechanism with no extra overhead to mitigate the impact of inaccurate poses in real datasets on the smoothness of time interpolation tasks. Through differential gaussian rasterization, the deformable 3D Gaussians not only achieve higher rendering quality but also real-time rendering speed. Experiments show that our method outperforms existing methods significantly in terms of both rendering quality and speed, making it well-suited for tasks such as novel-view synthesis, time synthesis, and real-time rendering.
SoK: Comparing Different Membership Inference Attacks with a Comprehensive Benchmark
Jul 12, 2023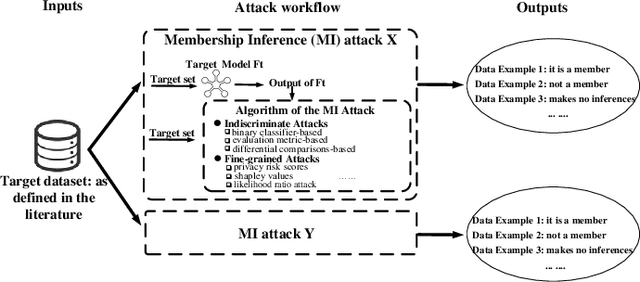
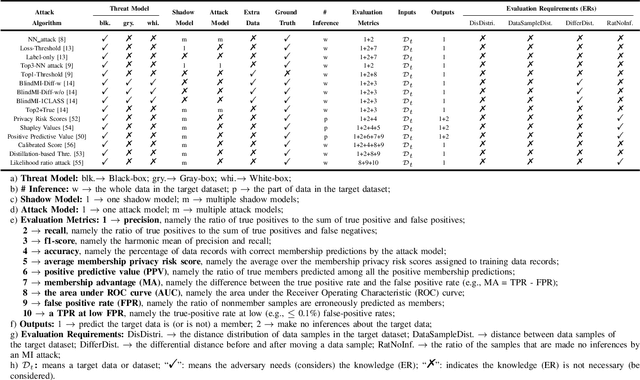

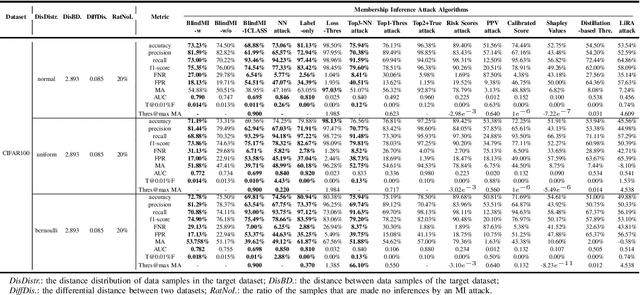
Membership inference (MI) attacks threaten user privacy through determining if a given data example has been used to train a target model. However, it has been increasingly recognized that the "comparing different MI attacks" methodology used in the existing works has serious limitations. Due to these limitations, we found (through the experiments in this work) that some comparison results reported in the literature are quite misleading. In this paper, we seek to develop a comprehensive benchmark for comparing different MI attacks, called MIBench, which consists not only the evaluation metrics, but also the evaluation scenarios. And we design the evaluation scenarios from four perspectives: the distance distribution of data samples in the target dataset, the distance between data samples of the target dataset, the differential distance between two datasets (i.e., the target dataset and a generated dataset with only nonmembers), and the ratio of the samples that are made no inferences by an MI attack. The evaluation metrics consist of ten typical evaluation metrics. We have identified three principles for the proposed "comparing different MI attacks" methodology, and we have designed and implemented the MIBench benchmark with 84 evaluation scenarios for each dataset. In total, we have used our benchmark to fairly and systematically compare 15 state-of-the-art MI attack algorithms across 588 evaluation scenarios, and these evaluation scenarios cover 7 widely used datasets and 7 representative types of models. All codes and evaluations of MIBench are publicly available at https://github.com/MIBench/MIBench.github.io/blob/main/README.md.
CSL: A Large-scale Chinese Scientific Literature Dataset
Sep 12, 2022
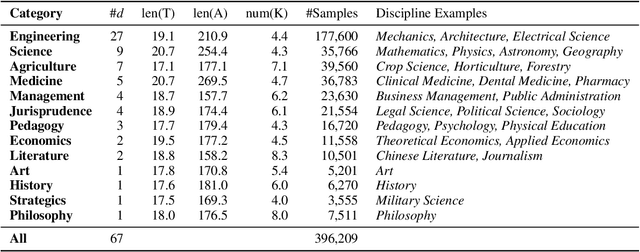
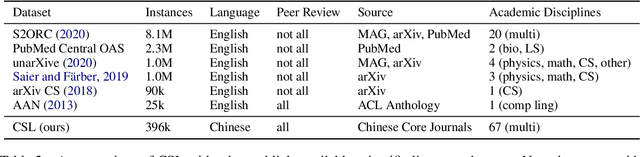
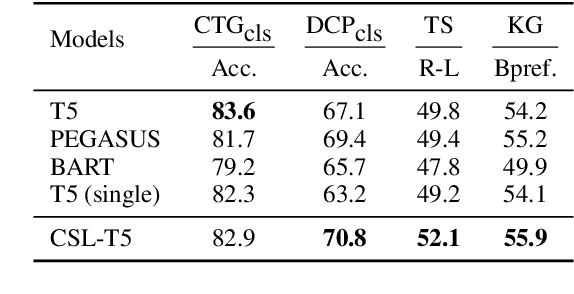
Scientific literature serves as a high-quality corpus, supporting a lot of Natural Language Processing (NLP) research. However, existing datasets are centered around the English language, which restricts the development of Chinese scientific NLP. In this work, we present CSL, a large-scale Chinese Scientific Literature dataset, which contains the titles, abstracts, keywords and academic fields of 396k papers. To our knowledge, CSL is the first scientific document dataset in Chinese. The CSL can serve as a Chinese corpus. Also, this semi-structured data is a natural annotation that can constitute many supervised NLP tasks. Based on CSL, we present a benchmark to evaluate the performance of models across scientific domain tasks, i.e., summarization, keyword generation and text classification. We analyze the behavior of existing text-to-text models on the evaluation tasks and reveal the challenges for Chinese scientific NLP tasks, which provides a valuable reference for future research. Data and code are available at https://github.com/ydli-ai/CSL
A Secure Data Sharing Framework for Robot Operating Systems Leveraging Ethereum
Aug 30, 2022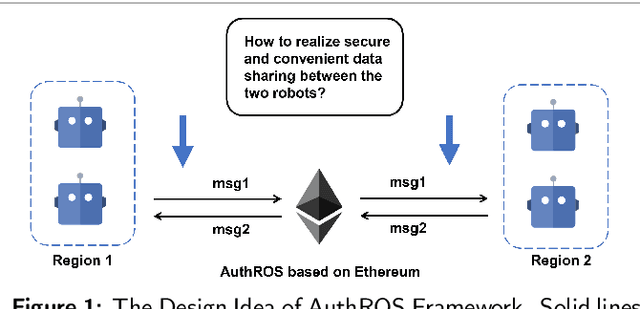
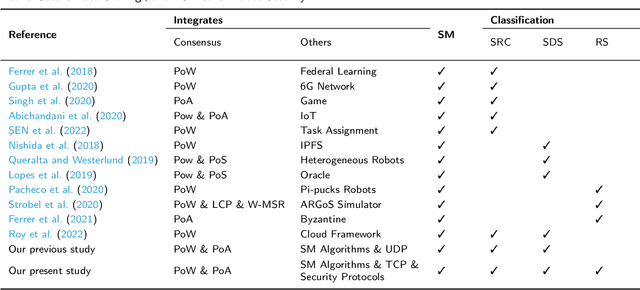
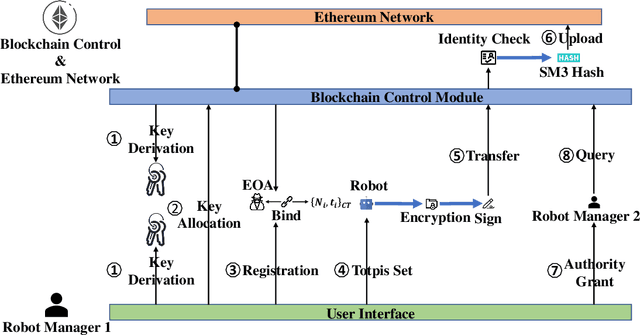

Robot Operating System (ROS) has brought the excellent potential for automation in various fields involving production tasks, productivity enhancement, and the simplification of human operations. However, ROS highly relies on communication but lacks secure data sharing mechanisms. Securing confidential data exchange between multi-robots presents significant challenges in multi-robot interactions. In this paper, we introduce AuthROS, a secure and convenient authorization framework for ROS nodes with absolute security and high availability based on a private Ethereum network and SM algorithms. To our best knowledge, AuthROS is the first secure data-sharing framework for robots loaded with ROS. This framework can meet the requirements for immutability and security of confidential data exchanged between ROS nodes. In addition, an authority-granting and identity-verification mechanism are proposed to execute atomically to ensure trustworthy data exchange without third-party. Both an SM2 key exchange and an SM4 plaintext encryption mechanism are proposed for data transmission security. A data digest uploading scheme is also implemented to improve the efficiency of data querying and uploading on the Ethereum network. Experimental results demonstrate that it can generate a digest from 800KB encrypted data in 6.34ms. Through security analysis, AuthROS achieves secure data exchange, data operations detection, and Node Forging attack protection.
CASSOCK: Viable Backdoor Attacks against DNN in The Wall of Source-Specific Backdoor Defences
May 31, 2022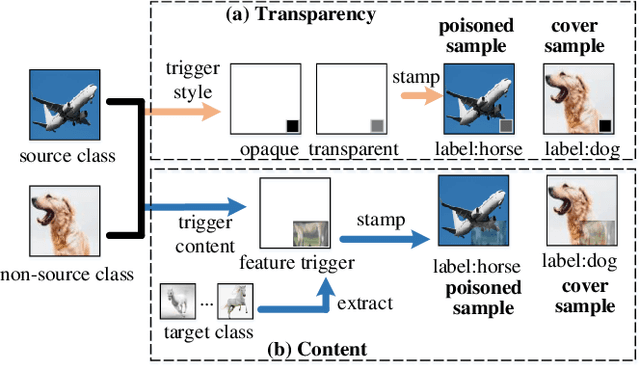

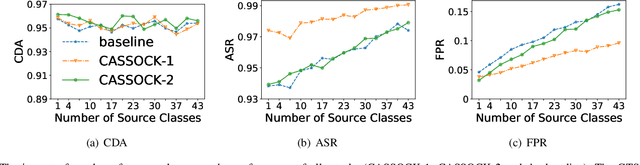
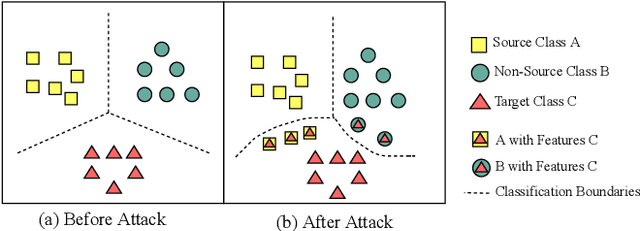
Backdoor attacks have been a critical threat to deep neural network (DNN). However, most existing countermeasures focus on source-agnostic backdoor attacks (SABAs) and fail to defeat source-specific backdoor attacks (SSBAs). Compared to an SABA, an SSBA activates a backdoor when an input from attacker-chosen class(es) is stamped with an attacker-specified trigger, making itself stealthier and thus evade most existing backdoor mitigation. Nonetheless, existing SSBAs have trade-offs on attack success rate (ASR, a backdoor is activated by a trigger input from a source class as expected) and false positive rate (FPR, a backdoor is activated unexpectedly by a trigger input from a non-source class). Significantly, they can still be effectively detected by the state-of-the-art (SOTA) countermeasures targeting SSBAs. This work overcomes efficiency and effectiveness deficiencies of existing SSBAs, thus bypassing the SOTA defences. The key insight is to construct desired poisoned and cover data during backdoor training by characterising SSBAs in-depth. Both data are samples with triggers: the cover/poisoned data from non-source/source class(es) holds ground-truth/target labels. Therefore, two cover/poisoned data enhancements are developed from trigger style and content, respectively, coined CASSOCK. First, we leverage trigger patterns with discrepant transparency to craft cover/poisoned data, enforcing triggers with heterogeneous sensitivity on different classes. The second enhancement chooses the target class features as triggers to craft these samples, entangling trigger features with the target class heavily. Compared with existing SSBAs, CASSOCK-based attacks have higher ASR and low FPR on four popular tasks: MNIST, CIFAR10, GTSRB, and LFW. More importantly, CASSOCK has effectively evaded three defences (SCAn, Februus and extended Neural Cleanse) already defeat existing SSBAs effectively.
PPA: Preference Profiling Attack Against Federated Learning
Feb 10, 2022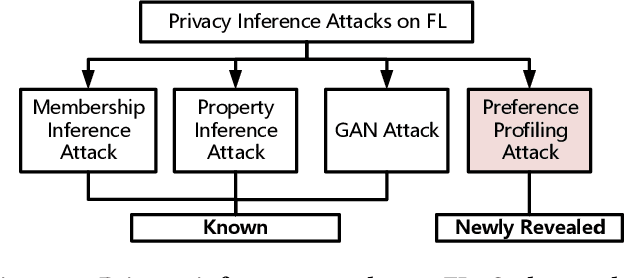
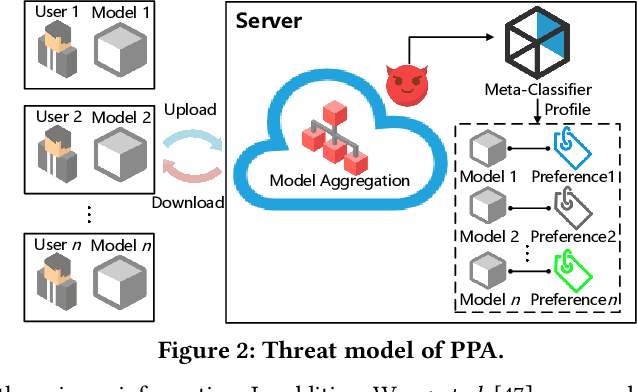

Federated learning (FL) trains a global model across a number of decentralized participants, each with a local dataset. Compared to traditional centralized learning, FL does not require direct local datasets access and thus mitigates data security and privacy concerns. However, data privacy concerns for FL still exist due to inference attacks, including known membership inference, property inference, and data inversion. In this work, we reveal a new type of privacy inference attack, coined Preference Profiling Attack (PPA), that accurately profiles private preferences of a local user. In general, the PPA can profile top-k, especially for top-1, preferences contingent on the local user's characteristics. Our key insight is that the gradient variation of a local user's model has a distinguishable sensitivity to the sample proportion of a given class, especially the majority/minority class. By observing a user model's gradient sensitivity to a class, the PPA can profile the sample proportion of the class in the user's local dataset and thus the user's preference of the class is exposed. The inherent statistical heterogeneity of FL further facilitates the PPA. We have extensively evaluated the PPA's effectiveness using four datasets from the image domains of MNIST, CIFAR10, Products-10K and RAF-DB. Our results show that the PPA achieves 90% and 98% top-1 attack accuracy to the MNIST and CIFAR10, respectively. More importantly, in the real-world commercial scenarios of shopping (i.e., Products-10K) and the social network (i.e., RAF-DB), the PPA gains a top-1 attack accuracy of 78% in the former case to infer the most ordered items, and 88% in the latter case to infer a victim user's emotions. Although existing countermeasures such as dropout and differential privacy protection can lower the PPA's accuracy to some extent, they unavoidably incur notable global model deterioration.
Improving Prosody for Unseen Texts in Speech Synthesis by Utilizing Linguistic Information and Noisy Data
Nov 15, 2021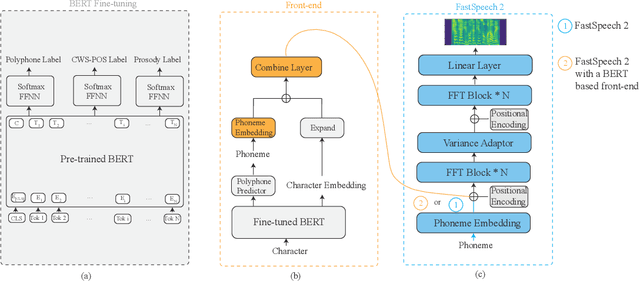

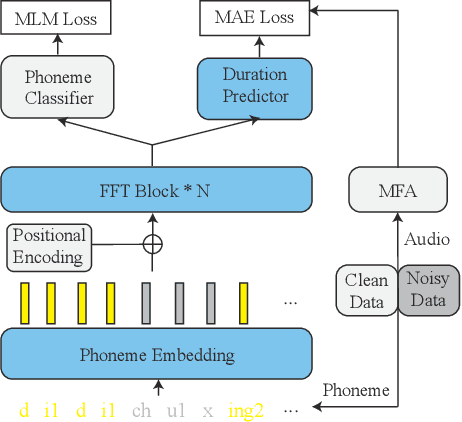

Recent advancements in end-to-end speech synthesis have made it possible to generate highly natural speech. However, training these models typically requires a large amount of high-fidelity speech data, and for unseen texts, the prosody of synthesized speech is relatively unnatural. To address these issues, we propose to combine a fine-tuned BERT-based front-end with a pre-trained FastSpeech2-based acoustic model to improve prosody modeling. The pre-trained BERT is fine-tuned on the polyphone disambiguation task, the joint Chinese word segmentation (CWS) and part-of-speech (POS) tagging task, and the prosody structure prediction (PSP) task in a multi-task learning framework. FastSpeech 2 is pre-trained on large-scale external data that are noisy but easier to obtain. Experimental results show that both the fine-tuned BERT model and the pre-trained FastSpeech 2 can improve prosody, especially for those structurally complex sentences.
Adaptive Pricing in Insurance: Generalized Linear Models and Gaussian Process Regression Approaches
Jul 02, 2019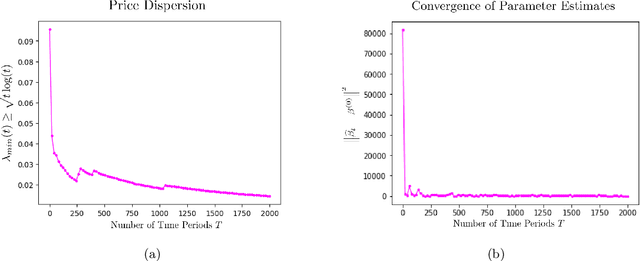
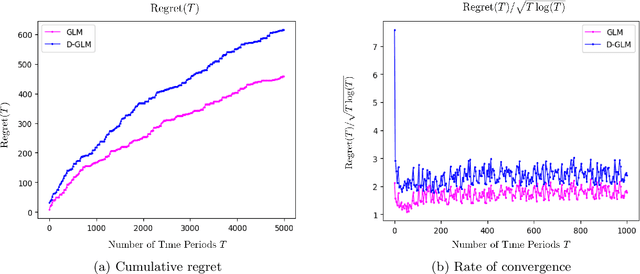
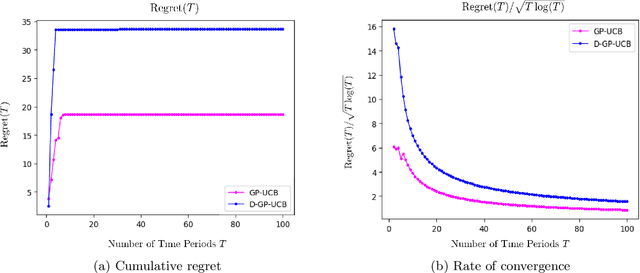
We study the application of dynamic pricing to insurance. We view this as an online revenue management problem where the insurance company looks to set prices to optimize the long-run revenue from selling a new insurance product. We develop two pricing models: an adaptive Generalized Linear Model (GLM) and an adaptive Gaussian Process (GP) regression model. Both balance between exploration, where we choose prices in order to learn the distribution of demands & claims for the insurance product, and exploitation, where we myopically choose the best price from the information gathered so far. The performance of the pricing policies is measured in terms of regret: the expected revenue loss caused by not using the optimal price. As is commonplace in insurance, we model demand and claims by GLMs. In our adaptive GLM design, we use the maximum quasi-likelihood estimation (MQLE) to estimate the unknown parameters. We show that, if prices are chosen with suitably decreasing variability, the MQLE parameters eventually exist and converge to the correct values, which in turn implies that the sequence of chosen prices will also converge to the optimal price. In the adaptive GP regression model, we sample demand and claims from Gaussian Processes and then choose selling prices by the upper confidence bound rule. We also analyze these GLM and GP pricing algorithms with delayed claims. Although similar results exist in other domains, this is among the first works to consider dynamic pricing problems in the field of insurance. We also believe this is the first work to consider Gaussian Process regression in the context of insurance pricing. These initial findings suggest that online machine learning algorithms could be a fruitful area of future investigation and application in insurance.