 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinhui Xue
LocalStyleFool: Regional Video Style Transfer Attack Using Segment Anything Model
Mar 27, 2024
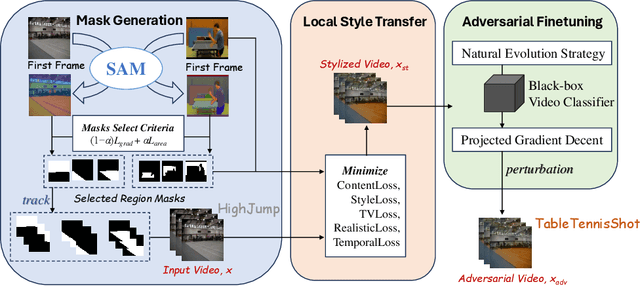
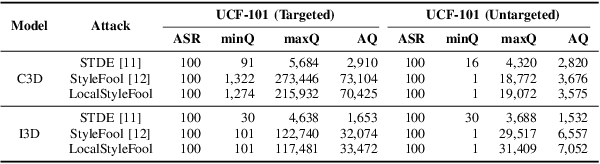
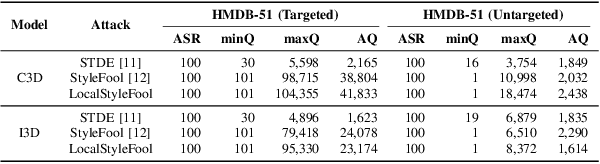

Previous work has shown that well-crafted adversarial perturbations can threaten the security of video recognition systems. Attackers can invade such models with a low query budget when the perturbations are semantic-invariant, such as StyleFool. Despite the query efficiency, the naturalness of the minutia areas still requires amelioration, since StyleFool leverages style transfer to all pixels in each frame. To close the gap, we propose LocalStyleFool, an improved black-box video adversarial attack that superimposes regional style-transfer-based perturbations on videos. Benefiting from the popularity and scalably usability of Segment Anything Model (SAM), we first extract different regions according to semantic information and then track them through the video stream to maintain the temporal consistency. Then, we add style-transfer-based perturbations to several regions selected based on the associative criterion of transfer-based gradient information and regional area. Perturbation fine adjustment is followed to make stylized videos adversarial. We demonstrate that LocalStyleFool can improve both intra-frame and inter-frame naturalness through a human-assessed survey, while maintaining competitive fooling rate and query efficiency. Successful experiments on the high-resolution dataset also showcase that scrupulous segmentation of SAM helps to improve the scalability of adversarial attacks under high-resolution data.
Efficient Constrained $k$-Center Clustering with Background Knowledge
Jan 23, 2024Center-based clustering has attracted significant research interest from both theory and practice. In many practical applications, input data often contain background knowledge that can be used to improve clustering results. In this work, we build on widely adopted $k$-center clustering and model its input background knowledge as must-link (ML) and cannot-link (CL) constraint sets. However, most clustering problems including $k$-center are inherently $\mathcal{NP}$-hard, while the more complex constrained variants are known to suffer severer approximation and computation barriers that significantly limit their applicability. By employing a suite of techniques including reverse dominating sets, linear programming (LP) integral polyhedron, and LP duality, we arrive at the first efficient approximation algorithm for constrained $k$-center with the best possible ratio of 2. We also construct competitive baseline algorithms and empirically evaluate our approximation algorithm against them on a variety of real datasets. The results validate our theoretical findings and demonstrate the great advantages of our algorithm in terms of clustering cost, clustering quality, and running time.
MFABA: A More Faithful and Accelerated Boundary-based Attribution Method for Deep Neural Networks
Dec 21, 2023To better understand the output of deep neural networks (DNN), attribution based methods have been an important approach for model interpretability, which assign a score for each input dimension to indicate its importance towards the model outcome. Notably, the attribution methods use the axioms of sensitivity and implementation invariance to ensure the validity and reliability of attribution results. Yet, the existing attribution methods present challenges for effective interpretation and efficient computation. In this work, we introduce MFABA, an attribution algorithm that adheres to axioms, as a novel method for interpreting DNN. Additionally, we provide the theoretical proof and in-depth analysis for MFABA algorithm, and conduct a large scale experiment. The results demonstrate its superiority by achieving over 101.5142 times faster speed than the state-of-the-art attribution algorithms. The effectiveness of MFABA is thoroughly evaluated through the statistical analysis in comparison to other methods, and the full implementation package is open-source at: https://github.com/LMBTough/MFABA
LogoStyleFool: Vitiating Video Recognition Systems via Logo Style Transfer
Dec 15, 2023Video recognition systems are vulnerable to adversarial examples. Recent studies show that style transfer-based and patch-based unrestricted perturbations can effectively improve attack efficiency. These attacks, however, face two main challenges: 1) Adding large stylized perturbations to all pixels reduces the naturalness of the video and such perturbations can be easily detected. 2) Patch-based video attacks are not extensible to targeted attacks due to the limited search space of reinforcement learning that has been widely used in video attacks recently. In this paper, we focus on the video black-box setting and propose a novel attack framework named LogoStyleFool by adding a stylized logo to the clean video. We separate the attack into three stages: style reference selection, reinforcement-learning-based logo style transfer, and perturbation optimization. We solve the first challenge by scaling down the perturbation range to a regional logo, while the second challenge is addressed by complementing an optimization stage after reinforcement learning. Experimental results substantiate the overall superiority of LogoStyleFool over three state-of-the-art patch-based attacks in terms of attack performance and semantic preservation. Meanwhile, LogoStyleFool still maintains its performance against two existing patch-based defense methods. We believe that our research is beneficial in increasing the attention of the security community to such subregional style transfer attacks.
GraphGuard: Detecting and Counteracting Training Data Misuse in Graph Neural Networks
Dec 13, 2023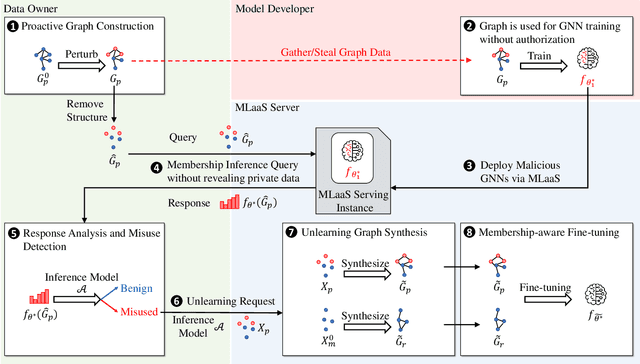
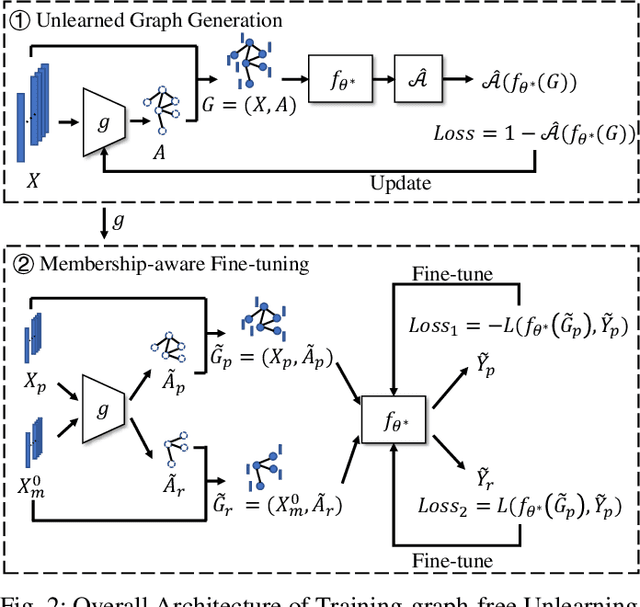
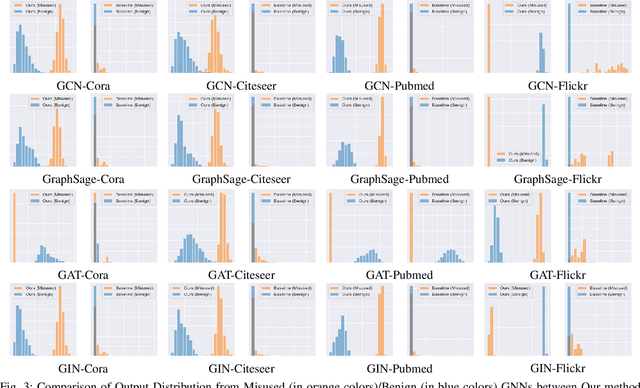

The emergence of Graph Neural Networks (GNNs) in graph data analysis and their deployment on Machine Learning as a Service platforms have raised critical concerns about data misuse during model training. This situation is further exacerbated due to the lack of transparency in local training processes, potentially leading to the unauthorized accumulation of large volumes of graph data, thereby infringing on the intellectual property rights of data owners. Existing methodologies often address either data misuse detection or mitigation, and are primarily designed for local GNN models rather than cloud-based MLaaS platforms. These limitations call for an effective and comprehensive solution that detects and mitigates data misuse without requiring exact training data while respecting the proprietary nature of such data. This paper introduces a pioneering approach called GraphGuard, to tackle these challenges. We propose a training-data-free method that not only detects graph data misuse but also mitigates its impact via targeted unlearning, all without relying on the original training data. Our innovative misuse detection technique employs membership inference with radioactive data, enhancing the distinguishability between member and non-member data distributions. For mitigation, we utilize synthetic graphs that emulate the characteristics previously learned by the target model, enabling effective unlearning even in the absence of exact graph data. We conduct comprehensive experiments utilizing four real-world graph datasets to demonstrate the efficacy of GraphGuard in both detection and unlearning. We show that GraphGuard attains a near-perfect detection rate of approximately 100% across these datasets with various GNN models. In addition, it performs unlearning by eliminating the impact of the unlearned graph with a marginal decrease in accuracy (less than 5%).
Flow-Attention-based Spatio-Temporal Aggregation Network for 3D Mask Detection
Oct 25, 2023Anti-spoofing detection has become a necessity for face recognition systems due to the security threat posed by spoofing attacks. Despite great success in traditional attacks, most deep-learning-based methods perform poorly in 3D masks, which can highly simulate real faces in appearance and structure, suffering generalizability insufficiency while focusing only on the spatial domain with single frame input. This has been mitigated by the recent introduction of a biomedical technology called rPPG (remote photoplethysmography). However, rPPG-based methods are sensitive to noisy interference and require at least one second (> 25 frames) of observation time, which induces high computational overhead. To address these challenges, we propose a novel 3D mask detection framework, called FASTEN (Flow-Attention-based Spatio-Temporal aggrEgation Network). We tailor the network for focusing more on fine-grained details in large movements, which can eliminate redundant spatio-temporal feature interference and quickly capture splicing traces of 3D masks in fewer frames. Our proposed network contains three key modules: 1) a facial optical flow network to obtain non-RGB inter-frame flow information; 2) flow attention to assign different significance to each frame; 3) spatio-temporal aggregation to aggregate high-level spatial features and temporal transition features. Through extensive experiments, FASTEN only requires five frames of input and outperforms eight competitors for both intra-dataset and cross-dataset evaluations in terms of multiple detection metrics. Moreover, FASTEN has been deployed in real-world mobile devices for practical 3D mask detection.
RAI4IoE: Responsible AI for Enabling the Internet of Energy
Sep 20, 2023This paper plans to develop an Equitable and Responsible AI framework with enabling techniques and algorithms for the Internet of Energy (IoE), in short, RAI4IoE. The energy sector is going through substantial changes fueled by two key drivers: building a zero-carbon energy sector and the digital transformation of the energy infrastructure. We expect to see the convergence of these two drivers resulting in the IoE, where renewable distributed energy resources (DERs), such as electric cars, storage batteries, wind turbines and photovoltaics (PV), can be connected and integrated for reliable energy distribution by leveraging advanced 5G-6G networks and AI technology. This allows DER owners as prosumers to participate in the energy market and derive economic incentives. DERs are inherently asset-driven and face equitable challenges (i.e., fair, diverse and inclusive). Without equitable access, privileged individuals, groups and organizations can participate and benefit at the cost of disadvantaged groups. The real-time management of DER resources not only brings out the equity problem to the IoE, it also collects highly sensitive location, time, activity dependent data, which requires to be handled responsibly (e.g., privacy, security and safety), for AI-enhanced predictions, optimization and prioritization services, and automated management of flexible resources. The vision of our project is to ensure equitable participation of the community members and responsible use of their data in IoE so that it could reap the benefits of advances in AI to provide safe, reliable and sustainable energy services.
Copyright Protection and Accountability of Generative AI:Attack, Watermarking and Attribution
Mar 15, 2023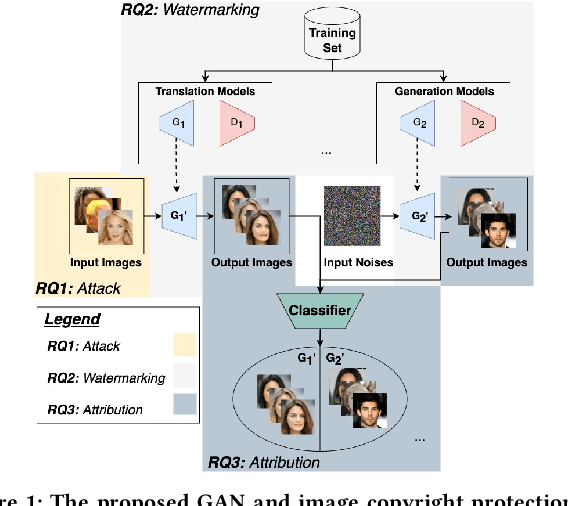
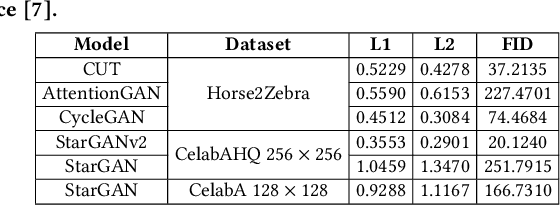

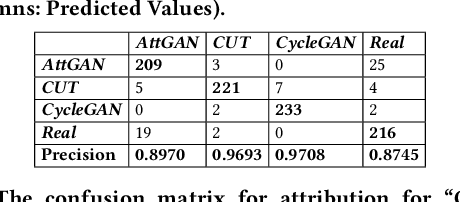
Generative AI (e.g., Generative Adversarial Networks - GANs) has become increasingly popular in recent years. However, Generative AI introduces significant concerns regarding the protection of Intellectual Property Rights (IPR) (resp. model accountability) pertaining to images (resp. toxic images) and models (resp. poisoned models) generated. In this paper, we propose an evaluation framework to provide a comprehensive overview of the current state of the copyright protection measures for GANs, evaluate their performance across a diverse range of GAN architectures, and identify the factors that affect their performance and future research directions. Our findings indicate that the current IPR protection methods for input images, model watermarking, and attribution networks are largely satisfactory for a wide range of GANs. We highlight that further attention must be directed towards protecting training sets, as the current approaches fail to provide robust IPR protection and provenance tracing on training sets.
The "Beatrix'' Resurrections: Robust Backdoor Detection via Gram Matrices
Sep 26, 2022Deep Neural Networks (DNNs) are susceptible to backdoor attacks during training. The model corrupted in this way functions normally, but when triggered by certain patterns in the input, produces a predefined target label. Existing defenses usually rely on the assumption of the universal backdoor setting in which poisoned samples share the same uniform trigger. However, recent advanced backdoor attacks show that this assumption is no longer valid in dynamic backdoors where the triggers vary from input to input, thereby defeating the existing defenses. In this work, we propose a novel technique, Beatrix (backdoor detection via Gram matrix). Beatrix utilizes Gram matrix to capture not only the feature correlations but also the appropriately high-order information of the representations. By learning class-conditional statistics from activation patterns of normal samples, Beatrix can identify poisoned samples by capturing the anomalies in activation patterns. To further improve the performance in identifying target labels, Beatrix leverages kernel-based testing without making any prior assumptions on representation distribution. We demonstrate the effectiveness of our method through extensive evaluation and comparison with state-of-the-art defensive techniques. The experimental results show that our approach achieves an F1 score of 91.1% in detecting dynamic backdoors, while the state of the art can only reach 36.9%.