 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinyi Wang
STAR-RIS Aided Secure MIMO Communication Systems
Apr 01, 2024
This paper investigates simultaneous transmission and reflection reconfigurable intelligent surface (STAR-RIS) aided physical layer security (PLS) in multiple-input multiple-output (MIMO) systems, where the base station (BS) transmits secrecy information with the aid of STAR-RIS against multiple eavesdroppers equipped with multiple antennas. We aim to maximize the secrecy rate by jointly optimizing the active beamforming at the BS and passive beamforming at the STAR-RIS, subject to the hardware constraint for STAR-RIS. To handle the coupling variables, a minimum mean-square error (MMSE) based alternating optimization (AO) algorithm is applied. In particular, the amplitudes and phases of STAR-RIS are divided into two blocks to simplify the algorithm design. Besides, by applying the Majorization-Minimization (MM) method, we derive a closed-form expression of the STAR-RIS's phase shifts. Numerical results show that the proposed scheme significantly outperforms various benchmark schemes, especially as the number of STAR-RIS elements increases.
Grid Monitoring and Protection with Continuous Point-on-Wave Measurements and Generative AI
Mar 11, 2024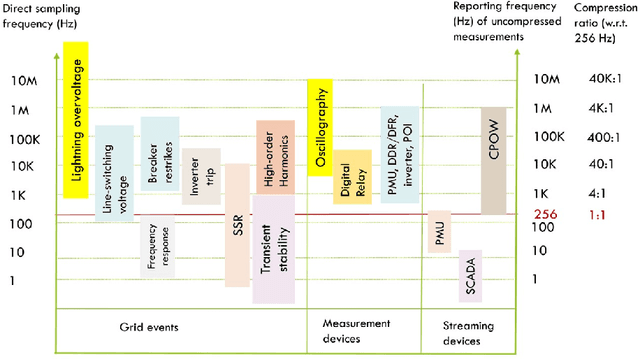
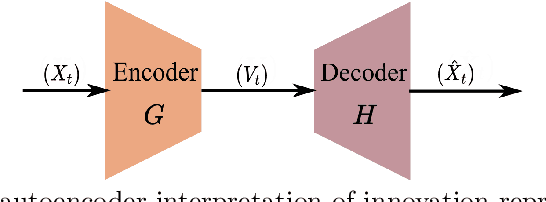
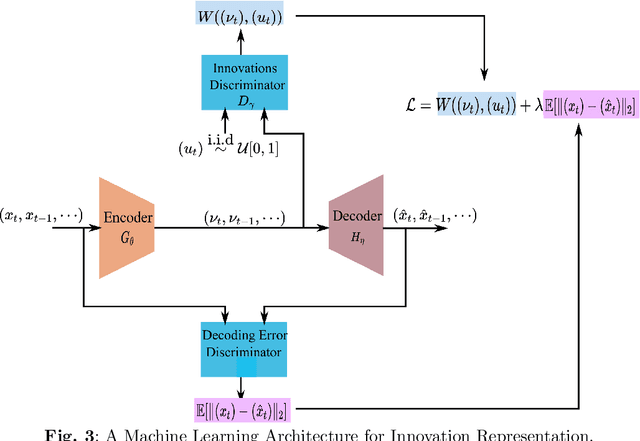
Purpose This article presents a case for a next-generation grid monitoring and control system, leveraging recent advances in generative artificial intelligence (AI), machine learning, and statistical inference. Advancing beyond earlier generations of wide-area monitoring systems built upon supervisory control and data acquisition (SCADA) and synchrophasor technologies, we argue for a monitoring and control framework based on the streaming of continuous point-on-wave (CPOW) measurements with AI-powered data compression and fault detection. Methods and Results: The architecture of the proposed design originates from the Wiener-Kallianpur innovation representation of a random process that transforms causally a stationary random process into an innovation sequence with independent and identically distributed random variables. This work presents a generative AI approach that (i) learns an innovation autoencoder that extracts innovation sequence from CPOW time series, (ii) compresses the CPOW streaming data with innovation autoencoder and subband coding, and (iii) detects unknown faults and novel trends via nonparametric sequential hypothesis testing. Conclusion: This work argues that conventional monitoring using SCADA and phasor measurement unit (PMU) technologies is ill-suited for a future grid with deep penetration of inverter-based renewable generations and distributed energy resources. A monitoring system based on CPOW data streaming and AI data analytics should be the basic building blocks for situational awareness of a highly dynamic future grid.
Generative Probabilistic Forecasting with Applications in Market Operations
Mar 09, 2024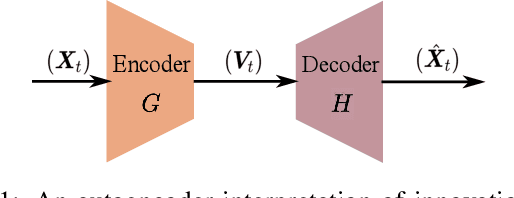
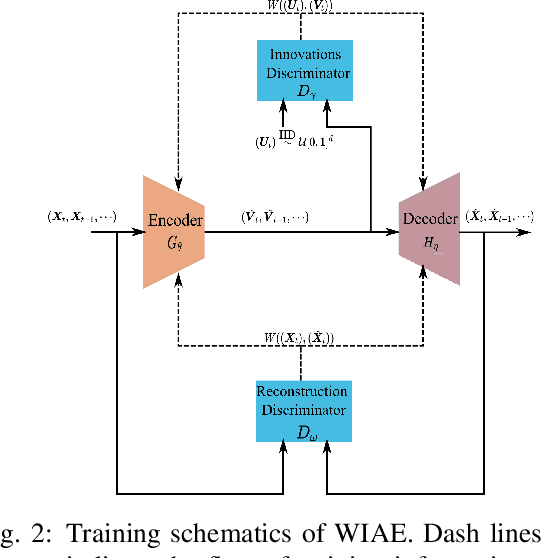
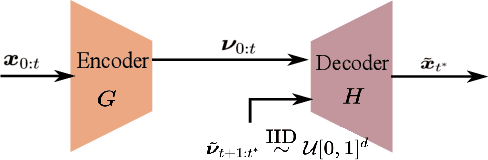
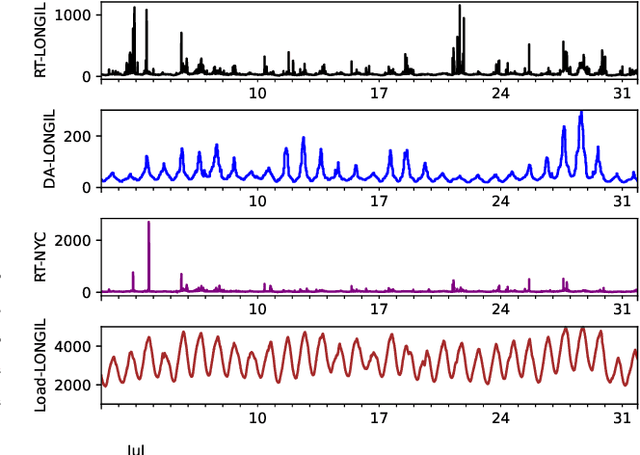
This paper presents a novel generative probabilistic forecasting approach derived from the Wiener-Kallianpur innovation representation of nonparametric time series. Under the paradigm of generative artificial intelligence, the proposed forecasting architecture includes an autoencoder that transforms nonparametric multivariate random processes into canonical innovation sequences, from which future time series samples are generated according to their probability distributions conditioned on past samples. A novel deep-learning algorithm is proposed that constrains the latent process to be an independent and identically distributed sequence with matching autoencoder input-output conditional probability distributions. Asymptotic optimality and structural convergence properties of the proposed generative forecasting approach are established. Three applications involving highly dynamic and volatile time series in real-time market operations are considered: (i) locational marginal price forecasting for merchant storage participants, {(ii) interregional price spread forecasting for interchange markets,} and (iii) area control error forecasting for frequency regulations. Numerical studies based on market data from multiple independent system operators demonstrate superior performance against leading traditional and machine learning-based forecasting techniques under both probabilistic and point forecast metrics.
A Survey on Data Selection for Language Models
Mar 08, 2024A major factor in the recent success of large language models is the use of enormous and ever-growing text datasets for unsupervised pre-training. However, naively training a model on all available data may not be optimal (or feasible), as the quality of available text data can vary. Filtering out data can also decrease the carbon footprint and financial costs of training models by reducing the amount of training required. Data selection methods aim to determine which candidate data points to include in the training dataset and how to appropriately sample from the selected data points. The promise of improved data selection methods has caused the volume of research in the area to rapidly expand. However, because deep learning is mostly driven by empirical evidence and experimentation on large-scale data is expensive, few organizations have the resources for extensive data selection research. Consequently, knowledge of effective data selection practices has become concentrated within a few organizations, many of which do not openly share their findings and methodologies. To narrow this gap in knowledge, we present a comprehensive review of existing literature on data selection methods and related research areas, providing a taxonomy of existing approaches. By describing the current landscape of research, this work aims to accelerate progress in data selection by establishing an entry point for new and established researchers. Additionally, throughout this review we draw attention to noticeable holes in the literature and conclude the paper by proposing promising avenues for future research.
Sensor-based Multi-Robot Search and Coverage with Spatial Separation in Unstructured Environments
Mar 04, 2024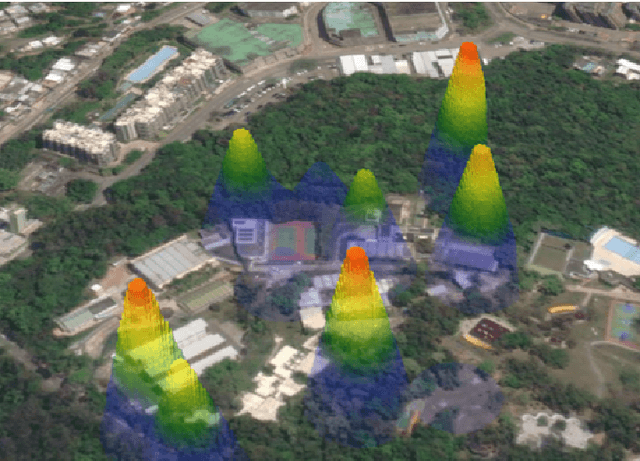
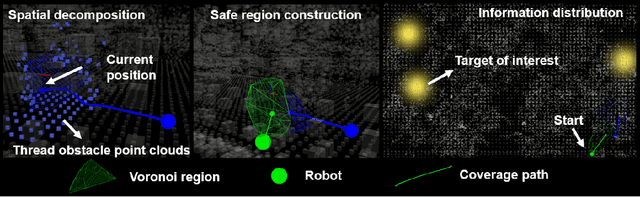
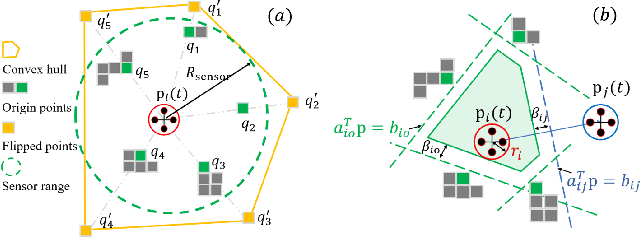

Multi-robot systems have increasingly become instrumental in tackling search and coverage problems. However, the challenge of optimizing task efficiency without compromising task success still persists, particularly in expansive, unstructured environments with dense obstacles. This paper presents an innovative, decentralized Voronoi-based approach for search and coverage to reactively navigate these complexities while maintaining safety. This approach leverages the active sensing capabilities of multi-robot systems to supplement GIS (Geographic Information System), offering a more comprehensive and real-time understanding of the environment. Based on point cloud data, which is inherently non-convex and unstructured, this method efficiently generates collision-free Voronoi regions using only local sensing information through spatial decomposition and spherical mirroring techniques. Then, deadlock-aware guided map integrated with a gradient-optimized, centroid Voronoi-based coverage control policy, is constructed to improve efficiency by avoiding exhaustive searches and local sensing pitfalls. The effectiveness of our algorithm has been validated through extensive numerical simulations in high-fidelity environments, demonstrating significant improvements in both task success rate, coverage ratio, and task execution time compared with others.
Multitask Multilingual Model Adaptation with Featurized Low-Rank Mixtures
Feb 27, 2024Adapting pretrained large language models (LLMs) to various downstream tasks in tens or hundreds of human languages is computationally expensive. Parameter-efficient fine-tuning (PEFT) significantly reduces the adaptation cost, by tuning only a small amount of parameters. However, directly applying PEFT methods such as LoRA (Hu et al., 2022) on diverse dataset mixtures could lead to suboptimal performance due to limited parameter capacity and negative interference among different datasets. In this work, we propose Featurized Low-rank Mixtures (FLix), a novel PEFT method designed for effective multitask multilingual tuning. FLix associates each unique dataset feature, such as the dataset's language or task, with its own low-rank weight update parameters. By composing feature-specific parameters for each dataset, FLix can accommodate diverse dataset mixtures and generalize better to unseen datasets. Our experiments show that FLix leads to significant improvements over a variety of tasks for both supervised learning and zero-shot settings using different training data mixtures.
Generative Probabilistic Time Series Forecasting and Applications in Grid Operations
Feb 21, 2024Generative probabilistic forecasting produces future time series samples according to the conditional probability distribution given past time series observations. Such techniques are essential in risk-based decision-making and planning under uncertainty with broad applications in grid operations, including electricity price forecasting, risk-based economic dispatch, and stochastic optimizations. Inspired by Wiener and Kallianpur's innovation representation, we propose a weak innovation autoencoder architecture and a learning algorithm to extract independent and identically distributed innovation sequences from nonparametric stationary time series. We show that the weak innovation sequence is Bayesian sufficient, which makes the proposed weak innovation autoencoder a canonical architecture for generative probabilistic forecasting. The proposed technique is applied to forecasting highly volatile real-time electricity prices, demonstrating superior performance across multiple forecasting measures over leading probabilistic and point forecasting techniques.
Rate-Quality or Energy-Quality Pareto Fronts for Adaptive Video Streaming?
Feb 10, 2024Adaptive video streaming is a key enabler for optimising the delivery of offline encoded video content. The research focus to date has been on optimisation, based solely on rate-quality curves. This paper adds an additional dimension, the energy expenditure, and explores construction of bitrate ladders based on decoding energy-quality curves rather than the conventional rate-quality curves. Pareto fronts are extracted from the rate-quality and energy-quality spaces to select optimal points. Bitrate ladders are constructed from these points using conventional rate-based rules together with a novel quality-based approach. Evaluation on a subset of YouTube-UGC videos encoded with x.265 shows that the energy-quality ladders reduce energy requirements by 28-31% on average at the cost of slightly higher bitrates. The results indicate that optimising based on energy-quality curves rather than rate-quality curves and using quality levels to create the rungs could potentially improve energy efficiency for a comparable quality of experience.
Understanding the Reasoning Ability of Language Models From the Perspective of Reasoning Paths Aggregation
Feb 05, 2024Pre-trained language models (LMs) are able to perform complex reasoning without explicit fine-tuning. To understand how pre-training with a next-token prediction objective contributes to the emergence of such reasoning capability, we propose that we can view an LM as deriving new conclusions by aggregating indirect reasoning paths seen at pre-training time. We found this perspective effective in two important cases of reasoning: logic reasoning with knowledge graphs (KGs) and math reasoning with math word problems (MWPs). More specifically, we formalize the reasoning paths as random walk paths on the knowledge/reasoning graphs. Analyses of learned LM distributions suggest that a weighted sum of relevant random walk path probabilities is a reasonable way to explain how LMs reason. Experiments and analysis on multiple KG and MWP datasets reveal the effect of training on random walk paths and suggest that augmenting unlabeled random walk reasoning paths can improve real-world multi-step reasoning performance.
GE-AdvGAN: Improving the transferability of adversarial samples by gradient editing-based adversarial generative model
Jan 30, 2024Adversarial generative models, such as Generative Adversarial Networks (GANs), are widely applied for generating various types of data, i.e., images, text, and audio. Accordingly, its promising performance has led to the GAN-based adversarial attack methods in the white-box and black-box attack scenarios. The importance of transferable black-box attacks lies in their ability to be effective across different models and settings, more closely aligning with real-world applications. However, it remains challenging to retain the performance in terms of transferable adversarial examples for such methods. Meanwhile, we observe that some enhanced gradient-based transferable adversarial attack algorithms require prolonged time for adversarial sample generation. Thus, in this work, we propose a novel algorithm named GE-AdvGAN to enhance the transferability of adversarial samples whilst improving the algorithm's efficiency. The main approach is via optimising the training process of the generator parameters. With the functional and characteristic similarity analysis, we introduce a novel gradient editing (GE) mechanism and verify its feasibility in generating transferable samples on various models. Moreover, by exploring the frequency domain information to determine the gradient editing direction, GE-AdvGAN can generate highly transferable adversarial samples while minimizing the execution time in comparison to the state-of-the-art transferable adversarial attack algorithms. The performance of GE-AdvGAN is comprehensively evaluated by large-scale experiments on different datasets, which results demonstrate the superiority of our algorithm. The code for our algorithm is available at: https://github.com/LMBTough/GE-advGAN