 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiyu Zhu
Denoising Distillation Makes Event-Frame Transformers as Accurate Gaze Trackers
Mar 31, 2024
This paper tackles the problem of passive gaze estimation using both event and frame data. Considering inherently different physiological structures, it's intractable to accurately estimate purely based on a given state. Thus, we reformulate the gaze estimation as the quantification of state transitions from the current state to several prior registered anchor states. Technically, we propose a two-stage learning-based gaze estimation framework to divide the whole gaze estimation process into a coarse-to-fine process of anchor state selection and final gaze location. Moreover, to improve generalization ability, we align a group of local experts with a student network, where a novel denoising distillation algorithm is introduced to utilize denoising diffusion technique to iteratively remove inherent noise of event data. Extensive experiments demonstrate the effectiveness of the proposed method, which greatly surpasses state-of-the-art methods by a large extent of 15$\%$. The code will be publicly available at https://github.com/jdjdli/Denoise_distill_EF_gazetracker.
Benchmarking Transferable Adversarial Attacks
Feb 08, 2024The robustness of deep learning models against adversarial attacks remains a pivotal concern. This study presents, for the first time, an exhaustive review of the transferability aspect of adversarial attacks. It systematically categorizes and critically evaluates various methodologies developed to augment the transferability of adversarial attacks. This study encompasses a spectrum of techniques, including Generative Structure, Semantic Similarity, Gradient Editing, Target Modification, and Ensemble Approach. Concurrently, this paper introduces a benchmark framework \textit{TAA-Bench}, integrating ten leading methodologies for adversarial attack transferability, thereby providing a standardized and systematic platform for comparative analysis across diverse model architectures. Through comprehensive scrutiny, we delineate the efficacy and constraints of each method, shedding light on their underlying operational principles and practical utility. This review endeavors to be a quintessential resource for both scholars and practitioners in the field, charting the complex terrain of adversarial transferability and setting a foundation for future explorations in this vital sector. The associated codebase is accessible at: https://github.com/KxPlaug/TAA-Bench
GE-AdvGAN: Improving the transferability of adversarial samples by gradient editing-based adversarial generative model
Jan 30, 2024Adversarial generative models, such as Generative Adversarial Networks (GANs), are widely applied for generating various types of data, i.e., images, text, and audio. Accordingly, its promising performance has led to the GAN-based adversarial attack methods in the white-box and black-box attack scenarios. The importance of transferable black-box attacks lies in their ability to be effective across different models and settings, more closely aligning with real-world applications. However, it remains challenging to retain the performance in terms of transferable adversarial examples for such methods. Meanwhile, we observe that some enhanced gradient-based transferable adversarial attack algorithms require prolonged time for adversarial sample generation. Thus, in this work, we propose a novel algorithm named GE-AdvGAN to enhance the transferability of adversarial samples whilst improving the algorithm's efficiency. The main approach is via optimising the training process of the generator parameters. With the functional and characteristic similarity analysis, we introduce a novel gradient editing (GE) mechanism and verify its feasibility in generating transferable samples on various models. Moreover, by exploring the frequency domain information to determine the gradient editing direction, GE-AdvGAN can generate highly transferable adversarial samples while minimizing the execution time in comparison to the state-of-the-art transferable adversarial attack algorithms. The performance of GE-AdvGAN is comprehensively evaluated by large-scale experiments on different datasets, which results demonstrate the superiority of our algorithm. The code for our algorithm is available at: https://github.com/LMBTough/GE-advGAN
A Survey on Indoor Visible Light Positioning Systems: Fundamentals, Applications, and Challenges
Jan 25, 2024The growing demand for location-based services in areas like virtual reality, robot control, and navigation has intensified the focus on indoor localization. Visible light positioning (VLP), leveraging visible light communications (VLC), becomes a promising indoor positioning technology due to its high accuracy and low cost. This paper provides a comprehensive survey of VLP systems. In particular, since VLC lays the foundation for VLP, we first present a detailed overview of the principles of VLC. The performance of each positioning algorithm is also compared in terms of various metrics such as accuracy, coverage, and orientation limitation. Beyond the physical layer studies, the network design for a VLP system is also investigated, including multi-access technologies resource allocation, and light-emitting diode (LED) placements. Next, the applications of the VLP systems are overviewed. Finally, this paper outlines open issues, challenges, and future research directions for the research field. In a nutshell, this paper constitutes the first holistic survey on VLP from state-of-the-art studies to practical uses.
Segment Any Events via Weighted Adaptation of Pivotal Tokens
Dec 24, 2023In this paper, we delve into the nuanced challenge of tailoring the Segment Anything Models (SAMs) for integration with event data, with the overarching objective of attaining robust and universal object segmentation within the event-centric domain. One pivotal issue at the heart of this endeavor is the precise alignment and calibration of embeddings derived from event-centric data such that they harmoniously coincide with those originating from RGB imagery. Capitalizing on the vast repositories of datasets with paired events and RGB images, our proposition is to harness and extrapolate the profound knowledge encapsulated within the pre-trained SAM framework. As a cornerstone to achieving this, we introduce a multi-scale feature distillation methodology. This methodology rigorously optimizes the alignment of token embeddings originating from event data with their RGB image counterparts, thereby preserving and enhancing the robustness of the overall architecture. Considering the distinct significance that token embeddings from intermediate layers hold for higher-level embeddings, our strategy is centered on accurately calibrating the pivotal token embeddings. This targeted calibration is aimed at effectively managing the discrepancies in high-level embeddings originating from both the event and image domains. Extensive experiments on different datasets demonstrate the effectiveness of the proposed distillation method. Code in http://github.com/happychenpipi/EventSAM.
MFABA: A More Faithful and Accelerated Boundary-based Attribution Method for Deep Neural Networks
Dec 21, 2023To better understand the output of deep neural networks (DNN), attribution based methods have been an important approach for model interpretability, which assign a score for each input dimension to indicate its importance towards the model outcome. Notably, the attribution methods use the axioms of sensitivity and implementation invariance to ensure the validity and reliability of attribution results. Yet, the existing attribution methods present challenges for effective interpretation and efficient computation. In this work, we introduce MFABA, an attribution algorithm that adheres to axioms, as a novel method for interpreting DNN. Additionally, we provide the theoretical proof and in-depth analysis for MFABA algorithm, and conduct a large scale experiment. The results demonstrate its superiority by achieving over 101.5142 times faster speed than the state-of-the-art attribution algorithms. The effectiveness of MFABA is thoroughly evaluated through the statistical analysis in comparison to other methods, and the full implementation package is open-source at: https://github.com/LMBTough/MFABA
Global Structure-Aware Diffusion Process for Low-Light Image Enhancement
Oct 27, 2023This paper studies a diffusion-based framework to address the low-light image enhancement problem. To harness the capabilities of diffusion models, we delve into this intricate process and advocate for the regularization of its inherent ODE-trajectory. To be specific, inspired by the recent research that low curvature ODE-trajectory results in a stable and effective diffusion process, we formulate a curvature regularization term anchored in the intrinsic non-local structures of image data, i.e., global structure-aware regularization, which gradually facilitates the preservation of complicated details and the augmentation of contrast during the diffusion process. This incorporation mitigates the adverse effects of noise and artifacts resulting from the diffusion process, leading to a more precise and flexible enhancement. To additionally promote learning in challenging regions, we introduce an uncertainty-guided regularization technique, which wisely relaxes constraints on the most extreme regions of the image. Experimental evaluations reveal that the proposed diffusion-based framework, complemented by rank-informed regularization, attains distinguished performance in low-light enhancement. The outcomes indicate substantial advancements in image quality, noise suppression, and contrast amplification in comparison with state-of-the-art methods. We believe this innovative approach will stimulate further exploration and advancement in low-light image processing, with potential implications for other applications of diffusion models. The code is publicly available at https://github.com/jinnh/GSAD.
DANAA: Towards transferable attacks with double adversarial neuron attribution
Oct 22, 2023While deep neural networks have excellent results in many fields, they are susceptible to interference from attacking samples resulting in erroneous judgments. Feature-level attacks are one of the effective attack types, which targets the learnt features in the hidden layers to improve its transferability across different models. Yet it is observed that the transferability has been largely impacted by the neuron importance estimation results. In this paper, a double adversarial neuron attribution attack method, termed `DANAA', is proposed to obtain more accurate feature importance estimation. In our method, the model outputs are attributed to the middle layer based on an adversarial non-linear path. The goal is to measure the weight of individual neurons and retain the features that are more important towards transferability. We have conducted extensive experiments on the benchmark datasets to demonstrate the state-of-the-art performance of our method. Our code is available at: https://github.com/Davidjinzb/DANAA
Cross-modal Orthogonal High-rank Augmentation for RGB-Event Transformer-trackers
Jul 09, 2023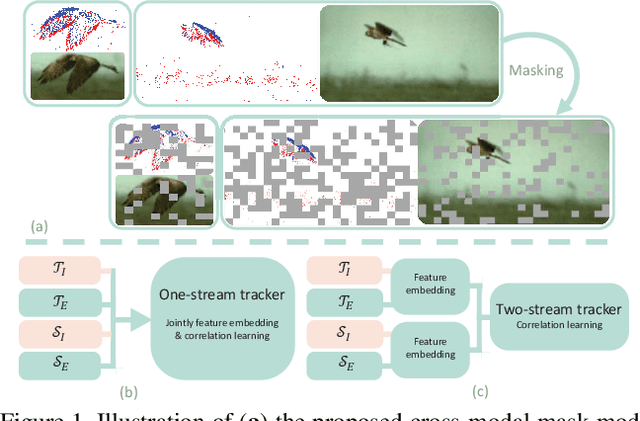
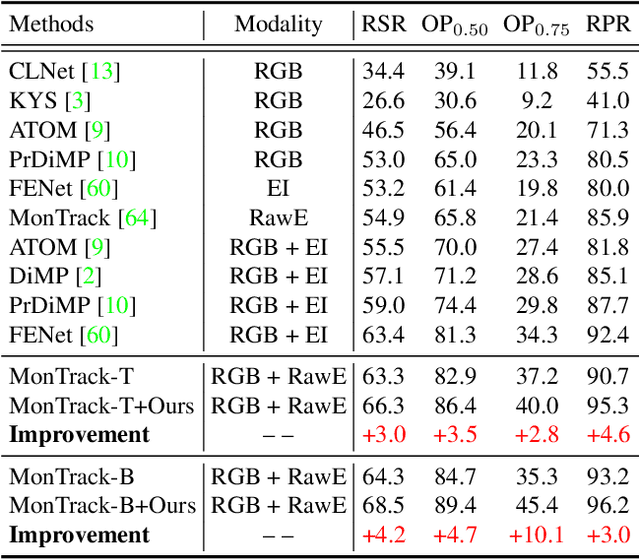

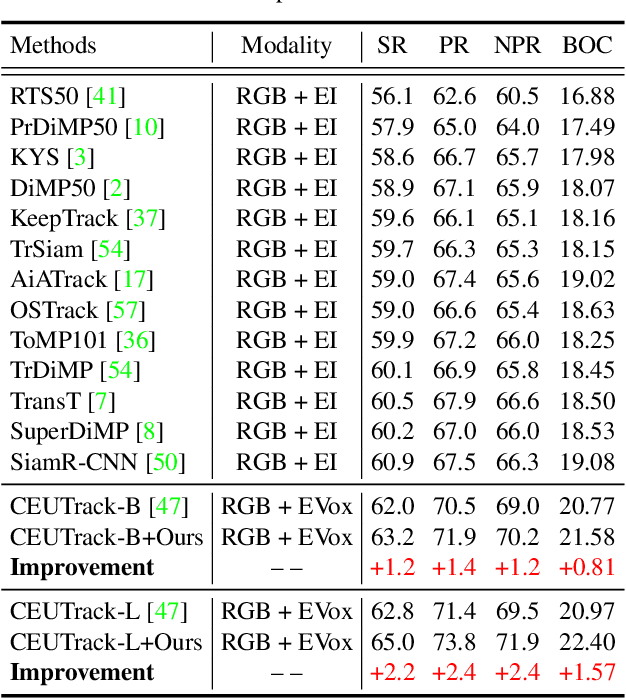
This paper addresses the problem of cross-modal object tracking from RGB videos and event data. Rather than constructing a complex cross-modal fusion network, we explore the great potential of a pre-trained vision Transformer (ViT). Particularly, we delicately investigate plug-and-play training augmentations that encourage the ViT to bridge the vast distribution gap between the two modalities, enabling comprehensive cross-modal information interaction and thus enhancing its ability. Specifically, we propose a mask modeling strategy that randomly masks a specific modality of some tokens to enforce the interaction between tokens from different modalities interacting proactively. To mitigate network oscillations resulting from the masking strategy and further amplify its positive effect, we then theoretically propose an orthogonal high-rank loss to regularize the attention matrix. Extensive experiments demonstrate that our plug-and-play training augmentation techniques can significantly boost state-of-the-art one-stream and twostream trackers to a large extent in terms of both tracking precision and success rate. Our new perspective and findings will potentially bring insights to the field of leveraging powerful pre-trained ViTs to model cross-modal data. The code will be publicly available.
Spatial-Temporal Enhanced Transformer Towards Multi-Frame 3D Object Detection
Jul 01, 2023



The Detection Transformer (DETR) has revolutionized the design of CNN-based object detection systems, showcasing impressive performance. However, its potential in the domain of multi-frame 3D object detection remains largely unexplored. In this paper, we present STEMD, a novel end-to-end framework for multi-frame 3D object detection based on the DETR-like paradigm. Our approach treats multi-frame 3D object detection as a sequence-to-sequence task and effectively captures spatial-temporal dependencies at both the feature and query levels. To model the inter-object spatial interaction and complex temporal dependencies, we introduce the spatial-temporal graph attention network. This network represents queries as nodes in a graph and enables effective modeling of object interactions within a social context. In addition, to solve the problem of missing hard cases in the proposed output of the encoder in the current frame, we incorporate the output of the previous frame to initialize the query input of the decoder. Moreover, we tackle the issue of redundant detection results, where the model generates numerous overlapping boxes from similar queries. To mitigate this, we introduce an IoU regularization term in the loss function. This term aids in distinguishing between queries matched with the ground-truth box and queries that are similar but unmatched during the refinement process, leading to reduced redundancy and more accurate detections. Through extensive experiments, we demonstrate the effectiveness of our approach in handling challenging scenarios, while incurring only a minor additional computational overhead. The code will be available at \url{https://github.com/Eaphan/STEMD}.