 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHui Yuan
Gradient Guidance for Diffusion Models: An Optimization Perspective
Apr 23, 2024
Diffusion models have demonstrated empirical successes in various applications and can be adapted to task-specific needs via guidance. This paper introduces a form of gradient guidance for adapting or fine-tuning diffusion models towards user-specified optimization objectives. We study the theoretic aspects of a guided score-based sampling process, linking the gradient-guided diffusion model to first-order optimization. We show that adding gradient guidance to the sampling process of a pre-trained diffusion model is essentially equivalent to solving a regularized optimization problem, where the regularization term acts as a prior determined by the pre-training data. Diffusion models are able to learn data's latent subspace, however, explicitly adding the gradient of an external objective function to the sample process would jeopardize the structure in generated samples. To remedy this issue, we consider a modified form of gradient guidance based on a forward prediction loss, which leverages the pre-trained score function to preserve the latent structure in generated samples. We further consider an iteratively fine-tuned version of gradient-guided diffusion where one can query gradients at newly generated data points and update the score network using new samples. This process mimics a first-order optimization iteration in expectation, for which we proved O(1/K) convergence rate to the global optimum when the objective function is concave.
Physics-based reward driven image analysis in microscopy
Apr 23, 2024The rise of electron microscopy has expanded our ability to acquire nanometer and atomically resolved images of complex materials. The resulting vast datasets are typically analyzed by human operators, an intrinsically challenging process due to the multiple possible analysis steps and the corresponding need to build and optimize complex analysis workflows. We present a methodology based on the concept of a Reward Function coupled with Bayesian Optimization, to optimize image analysis workflows dynamically. The Reward Function is engineered to closely align with the experimental objectives and broader context and is quantifiable upon completion of the analysis. Here, cross-section, high-angle annular dark field (HAADF) images of ion-irradiated $(Y, Dy)Ba_2Cu_3O_{7-\delta}$ thin-films were used as a model system. The reward functions were formed based on the expected materials density and atomic spacings and used to drive multi-objective optimization of the classical Laplacian-of-Gaussian (LoG) method. These results can be benchmarked against the DCNN segmentation. This optimized LoG* compares favorably against DCNN in the presence of the additional noise. We further extend the reward function approach towards the identification of partially-disordered regions, creating a physics-driven reward function and action space of high-dimensional clustering. We pose that with correct definition, the reward function approach allows real-time optimization of complex analysis workflows at much higher speeds and lower computational costs than classical DCNN-based inference, ensuring the attainment of results that are both precise and aligned with the human-defined objectives.
Diffusion Model for Data-Driven Black-Box Optimization
Mar 20, 2024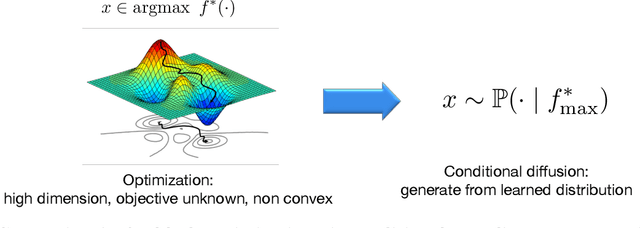

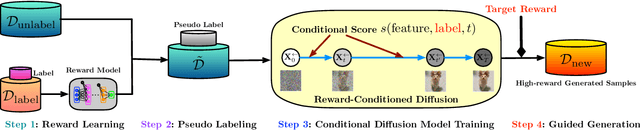
Generative AI has redefined artificial intelligence, enabling the creation of innovative content and customized solutions that drive business practices into a new era of efficiency and creativity. In this paper, we focus on diffusion models, a powerful generative AI technology, and investigate their potential for black-box optimization over complex structured variables. Consider the practical scenario where one wants to optimize some structured design in a high-dimensional space, based on massive unlabeled data (representing design variables) and a small labeled dataset. We study two practical types of labels: 1) noisy measurements of a real-valued reward function and 2) human preference based on pairwise comparisons. The goal is to generate new designs that are near-optimal and preserve the designed latent structures. Our proposed method reformulates the design optimization problem into a conditional sampling problem, which allows us to leverage the power of diffusion models for modeling complex distributions. In particular, we propose a reward-directed conditional diffusion model, to be trained on the mixed data, for sampling a near-optimal solution conditioned on high predicted rewards. Theoretically, we establish sub-optimality error bounds for the generated designs. The sub-optimality gap nearly matches the optimal guarantee in off-policy bandits, demonstrating the efficiency of reward-directed diffusion models for black-box optimization. Moreover, when the data admits a low-dimensional latent subspace structure, our model efficiently generates high-fidelity designs that closely respect the latent structure. We provide empirical experiments validating our model in decision-making and content-creation tasks.
MaxMin-RLHF: Towards Equitable Alignment of Large Language Models with Diverse Human Preferences
Feb 14, 2024Reinforcement Learning from Human Feedback (RLHF) aligns language models to human preferences by employing a singular reward model derived from preference data. However, such an approach overlooks the rich diversity of human preferences inherent in data collected from multiple users. In this work, we first derive an impossibility result of alignment with single reward RLHF, thereby highlighting its insufficiency in representing diverse human preferences. To provide an equitable solution to the problem, we learn a mixture of preference distributions via an expectation-maximization algorithm and propose a MaxMin alignment objective for policy learning inspired by the Egalitarian principle in social choice theory to better represent diverse human preferences. We elucidate the connection of our proposed approach to distributionally robust optimization and general utility RL, thereby highlighting the generality and robustness of our proposed solution. We present comprehensive experimental results on small-scale (GPT-2) and large-scale language models (with Tulu2-7B) and show the efficacy of the proposed approach in the presence of diversity among human preferences. Our algorithm achieves an average improvement of more than 16% in win-rates over conventional RLHF algorithms and improves the win-rate (accuracy) for minority groups by over 33% without compromising the performance of majority groups, showcasing the robustness and fairness of our approach. We remark that our findings in this work are not only limited to language models but also extend to reinforcement learning in general.
Tree Search-Based Evolutionary Bandits for Protein Sequence Optimization
Jan 08, 2024While modern biotechnologies allow synthesizing new proteins and function measurements at scale, efficiently exploring a protein sequence space and engineering it remains a daunting task due to the vast sequence space of any given protein. Protein engineering is typically conducted through an iterative process of adding mutations to the wild-type or lead sequences, recombination of mutations, and running new rounds of screening. To enhance the efficiency of such a process, we propose a tree search-based bandit learning method, which expands a tree starting from the initial sequence with the guidance of a bandit machine learning model. Under simplified assumptions and a Gaussian Process prior, we provide theoretical analysis and a Bayesian regret bound, demonstrating that the combination of local search and bandit learning method can efficiently discover a near-optimal design. The full algorithm is compatible with a suite of randomized tree search heuristics, machine learning models, pre-trained embeddings, and bandit techniques. We test various instances of the algorithm across benchmark protein datasets using simulated screens. Experiment results demonstrate that the algorithm is both sample-efficient and able to find top designs using reasonably small mutation counts.
Global Structure-Aware Diffusion Process for Low-Light Image Enhancement
Oct 27, 2023This paper studies a diffusion-based framework to address the low-light image enhancement problem. To harness the capabilities of diffusion models, we delve into this intricate process and advocate for the regularization of its inherent ODE-trajectory. To be specific, inspired by the recent research that low curvature ODE-trajectory results in a stable and effective diffusion process, we formulate a curvature regularization term anchored in the intrinsic non-local structures of image data, i.e., global structure-aware regularization, which gradually facilitates the preservation of complicated details and the augmentation of contrast during the diffusion process. This incorporation mitigates the adverse effects of noise and artifacts resulting from the diffusion process, leading to a more precise and flexible enhancement. To additionally promote learning in challenging regions, we introduce an uncertainty-guided regularization technique, which wisely relaxes constraints on the most extreme regions of the image. Experimental evaluations reveal that the proposed diffusion-based framework, complemented by rank-informed regularization, attains distinguished performance in low-light enhancement. The outcomes indicate substantial advancements in image quality, noise suppression, and contrast amplification in comparison with state-of-the-art methods. We believe this innovative approach will stimulate further exploration and advancement in low-light image processing, with potential implications for other applications of diffusion models. The code is publicly available at https://github.com/jinnh/GSAD.
Spatial-Temporal Transformer based Video Compression Framework
Sep 21, 2023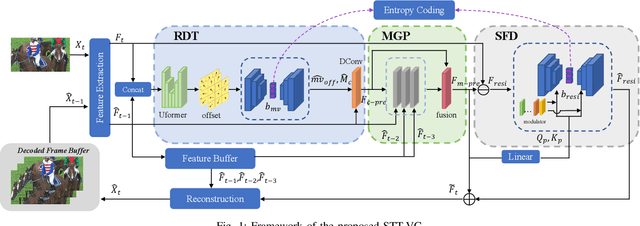
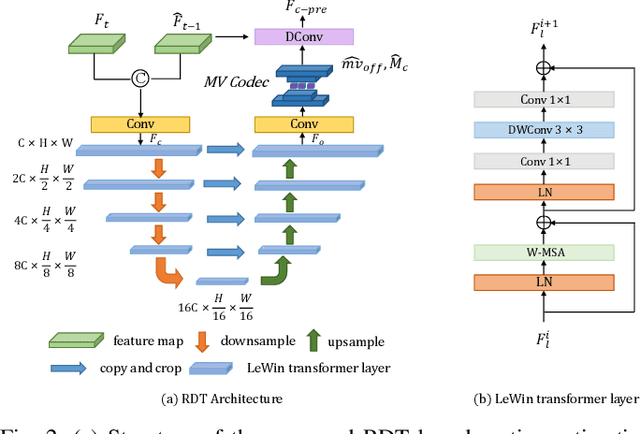

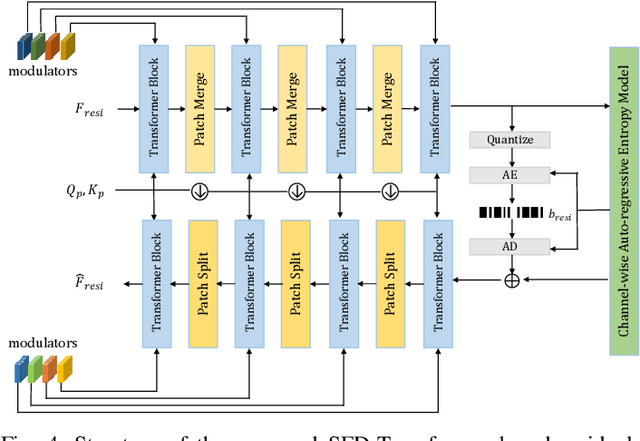
Learned video compression (LVC) has witnessed remarkable advancements in recent years. Similar as the traditional video coding, LVC inherits motion estimation/compensation, residual coding and other modules, all of which are implemented with neural networks (NNs). However, within the framework of NNs and its training mechanism using gradient backpropagation, most existing works often struggle to consistently generate stable motion information, which is in the form of geometric features, from the input color features. Moreover, the modules such as the inter-prediction and residual coding are independent from each other, making it inefficient to fully reduce the spatial-temporal redundancy. To address the above problems, in this paper, we propose a novel Spatial-Temporal Transformer based Video Compression (STT-VC) framework. It contains a Relaxed Deformable Transformer (RDT) with Uformer based offsets estimation for motion estimation and compensation, a Multi-Granularity Prediction (MGP) module based on multi-reference frames for prediction refinement, and a Spatial Feature Distribution prior based Transformer (SFD-T) for efficient temporal-spatial joint residual compression. Specifically, RDT is developed to stably estimate the motion information between frames by thoroughly investigating the relationship between the similarity based geometric motion feature extraction and self-attention. MGP is designed to fuse the multi-reference frame information by effectively exploring the coarse-grained prediction feature generated with the coded motion information. SFD-T is to compress the residual information by jointly exploring the spatial feature distributions in both residual and temporal prediction to further reduce the spatial-temporal redundancy. Experimental results demonstrate that our method achieves the best result with 13.5% BD-Rate saving over VTM.
Reward-Directed Conditional Diffusion: Provable Distribution Estimation and Reward Improvement
Jul 13, 2023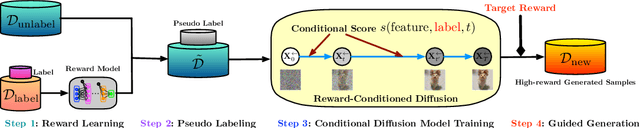
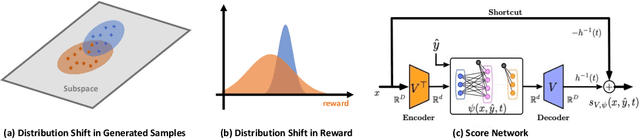
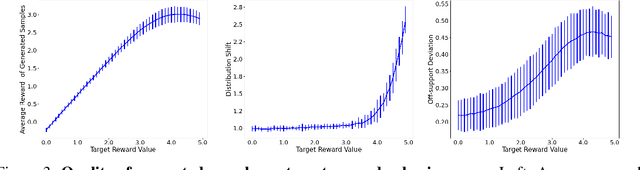
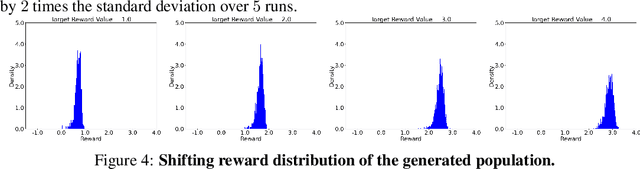
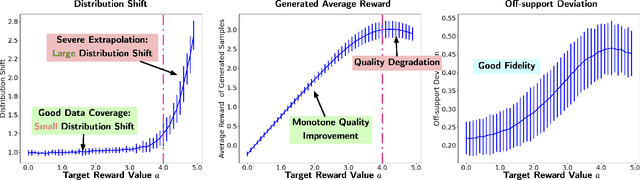
We explore the methodology and theory of reward-directed generation via conditional diffusion models. Directed generation aims to generate samples with desired properties as measured by a reward function, which has broad applications in generative AI, reinforcement learning, and computational biology. We consider the common learning scenario where the data set consists of unlabeled data along with a smaller set of data with noisy reward labels. Our approach leverages a learned reward function on the smaller data set as a pseudolabeler. From a theoretical standpoint, we show that this directed generator can effectively learn and sample from the reward-conditioned data distribution. Additionally, our model is capable of recovering the latent subspace representation of data. Moreover, we establish that the model generates a new population that moves closer to a user-specified target reward value, where the optimality gap aligns with the off-policy bandit regret in the feature subspace. The improvement in rewards obtained is influenced by the interplay between the strength of the reward signal, the distribution shift, and the cost of off-support extrapolation. We provide empirical results to validate our theory and highlight the relationship between the strength of extrapolation and the quality of generated samples.
Unified Off-Policy Learning to Rank: a Reinforcement Learning Perspective
Jun 13, 2023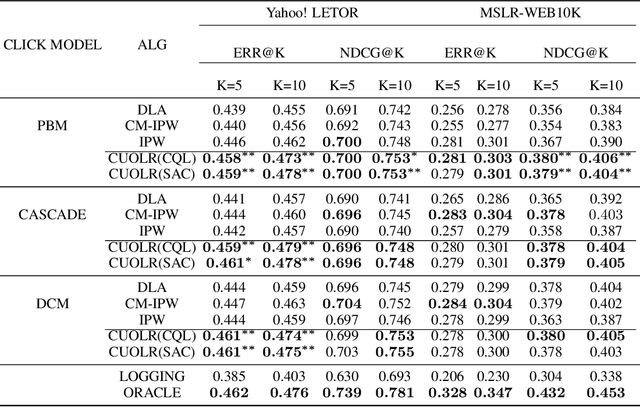
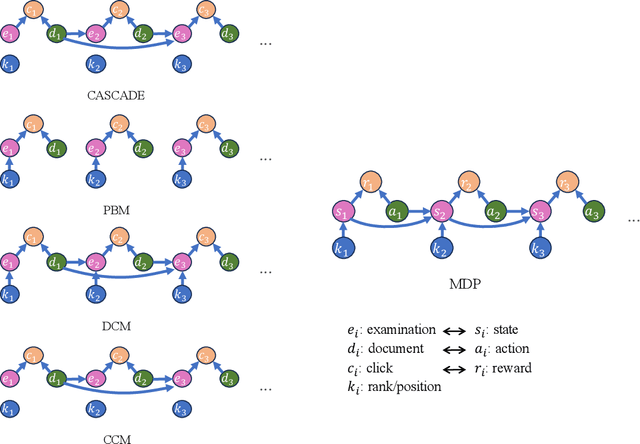
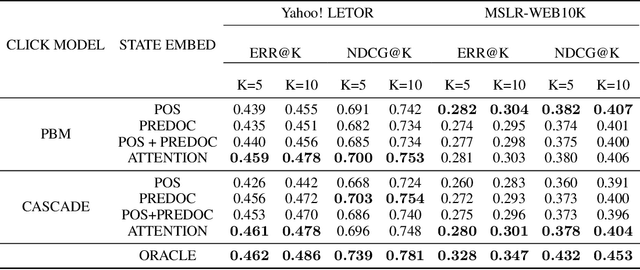
Off-policy Learning to Rank (LTR) aims to optimize a ranker from data collected by a deployed logging policy. However, existing off-policy learning to rank methods often make strong assumptions about how users generate the click data, i.e., the click model, and hence need to tailor their methods specifically under different click models. In this paper, we unified the ranking process under general stochastic click models as a Markov Decision Process (MDP), and the optimal ranking could be learned with offline reinforcement learning (RL) directly. Building upon this, we leverage offline RL techniques for off-policy LTR and propose the Click Model-Agnostic Unified Off-policy Learning to Rank (CUOLR) method, which could be easily applied to a wide range of click models. Through a dedicated formulation of the MDP, we show that offline RL algorithms can adapt to various click models without complex debiasing techniques and prior knowledge of the model. Results on various large-scale datasets demonstrate that CUOLR consistently outperforms the state-of-the-art off-policy learning to rank algorithms while maintaining consistency and robustness under different click models.
Adversarial Attacks on Online Learning to Rank with Stochastic Click Models
May 30, 2023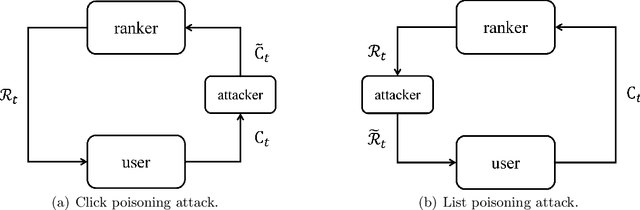
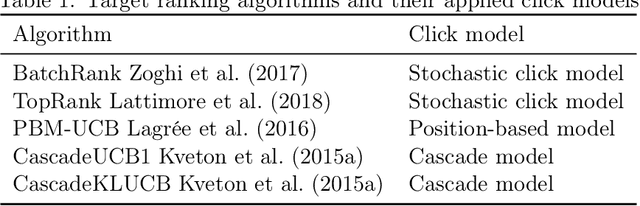
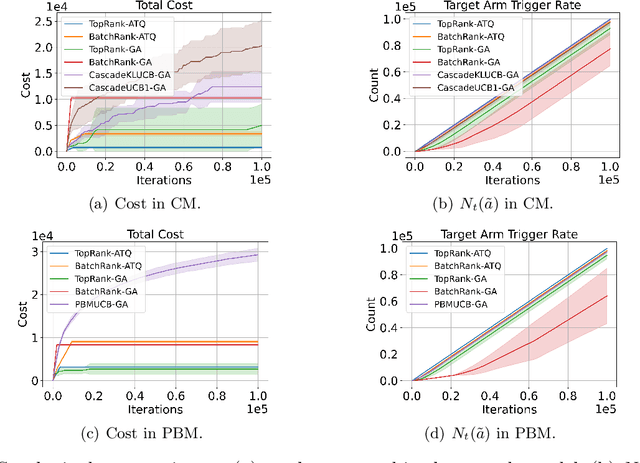
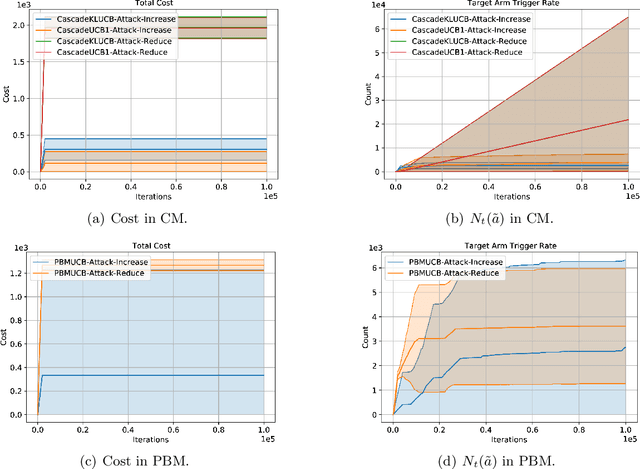
We propose the first study of adversarial attacks on online learning to rank. The goal of the adversary is to misguide the online learning to rank algorithm to place the target item on top of the ranking list linear times to time horizon $T$ with a sublinear attack cost. We propose generalized list poisoning attacks that perturb the ranking list presented to the user. This strategy can efficiently attack any no-regret ranker in general stochastic click models. Furthermore, we propose a click poisoning-based strategy named attack-then-quit that can efficiently attack two representative OLTR algorithms for stochastic click models. We theoretically analyze the success and cost upper bound of the two proposed methods. Experimental results based on synthetic and real-world data further validate the effectiveness and cost-efficiency of the proposed attack strategies.