 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSouradip Chakraborty
On the Safety Concerns of Deploying LLMs/VLMs in Robotics: Highlighting the Risks and Vulnerabilities
Feb 24, 2024
In this paper, we highlight the critical issues of robustness and safety associated with integrating large language models (LLMs) and vision-language models (VLMs) into robotics applications. Recent works have focused on using LLMs and VLMs to improve the performance of robotics tasks, such as manipulation, navigation, etc. However, such integration can introduce significant vulnerabilities, in terms of their susceptibility to adversarial attacks due to the language models, potentially leading to catastrophic consequences. By examining recent works at the interface of LLMs/VLMs and robotics, we show that it is easy to manipulate or misguide the robot's actions, leading to safety hazards. We define and provide examples of several plausible adversarial attacks, and conduct experiments on three prominent robot frameworks integrated with a language model, including KnowNo VIMA, and Instruct2Act, to assess their susceptibility to these attacks. Our empirical findings reveal a striking vulnerability of LLM/VLM-robot integrated systems: simple adversarial attacks can significantly undermine the effectiveness of LLM/VLM-robot integrated systems. Specifically, our data demonstrate an average performance deterioration of 21.2% under prompt attacks and a more alarming 30.2% under perception attacks. These results underscore the critical need for robust countermeasures to ensure the safe and reliable deployment of the advanced LLM/VLM-based robotic systems.
Provably Sample Efficient RLHF via Active Preference Optimization
Feb 16, 2024Reinforcement Learning from Human Feedback (RLHF) is pivotal in aligning Large Language Models (LLMs) with human preferences. While these aligned generative models have demonstrated impressive capabilities across various tasks, the dependence on high-quality human preference data poses a costly bottleneck in practical implementation of RLHF. Hence better and adaptive strategies for data collection is needed. To this end, we frame RLHF as a contextual preference bandit problem with prompts as contexts and show that the naive way of collecting preference data by choosing prompts uniformly at random leads to a policy that suffers an $\Omega(1)$ suboptimality gap in rewards. Then we propose $\textit{Active Preference Optimization}$ ($\texttt{APO}$), an algorithm that actively selects prompts to collect preference data. Under the Bradley-Terry-Luce (BTL) preference model, \texttt{APO} achieves sample efficiency without compromising on policy performance. We show that given a sample budget of $T$, the suboptimality gap of a policy learned via $\texttt{APO}$ scales as $O(1/\sqrt{T})$. Next, we propose a compute-efficient batch version of $\texttt{APO}$ with minor modification and evaluate its performance in practice. Experimental evaluations on a human preference dataset validate \texttt{APO}'s efficacy as a sample-efficient and practical solution to data collection for RLHF, facilitating alignment of LLMs with human preferences in a cost-effective and scalable manner.
MaxMin-RLHF: Towards Equitable Alignment of Large Language Models with Diverse Human Preferences
Feb 14, 2024Reinforcement Learning from Human Feedback (RLHF) aligns language models to human preferences by employing a singular reward model derived from preference data. However, such an approach overlooks the rich diversity of human preferences inherent in data collected from multiple users. In this work, we first derive an impossibility result of alignment with single reward RLHF, thereby highlighting its insufficiency in representing diverse human preferences. To provide an equitable solution to the problem, we learn a mixture of preference distributions via an expectation-maximization algorithm and propose a MaxMin alignment objective for policy learning inspired by the Egalitarian principle in social choice theory to better represent diverse human preferences. We elucidate the connection of our proposed approach to distributionally robust optimization and general utility RL, thereby highlighting the generality and robustness of our proposed solution. We present comprehensive experimental results on small-scale (GPT-2) and large-scale language models (with Tulu2-7B) and show the efficacy of the proposed approach in the presence of diversity among human preferences. Our algorithm achieves an average improvement of more than 16% in win-rates over conventional RLHF algorithms and improves the win-rate (accuracy) for minority groups by over 33% without compromising the performance of majority groups, showcasing the robustness and fairness of our approach. We remark that our findings in this work are not only limited to language models but also extend to reinforcement learning in general.
Beyond Text: Improving LLM's Decision Making for Robot Navigation via Vocal Cues
Feb 05, 2024This work highlights a critical shortcoming in text-based Large Language Models (LLMs) used for human-robot interaction, demonstrating that text alone as a conversation modality falls short in such applications. While LLMs excel in processing text in these human conversations, they struggle with the nuances of verbal instructions in scenarios like social navigation, where ambiguity and uncertainty can erode trust in robotic and other AI systems. We can address this shortcoming by moving beyond text and additionally focusing on the paralinguistic features of these audio responses. These features are the aspects of spoken communication that do not involve the literal wording (lexical content) but convey meaning and nuance through how something is said. We present "Beyond Text"; an approach that improves LLM decision-making by integrating audio transcription along with a subsection of these features, which focus on the affect and more relevant in human-robot conversations. This approach not only achieves a 70.26% winning rate, outperforming existing LLMs by 48.30%, but also enhances robustness against token manipulation adversarial attacks, highlighted by a 22.44% less decrease ratio than the text-only language model in winning rate. "Beyond Text" marks an advancement in social robot navigation and broader Human-Robot interactions, seamlessly integrating text-based guidance with human-audio-informed language models.
REBEL: A Regularization-Based Solution for Reward Overoptimization in Reinforcement Learning from Human Feedback
Dec 22, 2023In this work, we propose REBEL, an algorithm for sample efficient reward regularization based robotic reinforcement learning from human feedback (RRLHF). Reinforcement learning (RL) performance for continuous control robotics tasks is sensitive to the underlying reward function. In practice, the reward function often ends up misaligned with human intent, values, social norms, etc., leading to catastrophic failures in the real world. We leverage human preferences to learn regularized reward functions and eventually align the agents with the true intended behavior. We introduce a novel notion of reward regularization to the existing RRLHF framework, which is termed as agent preferences. So, we not only consider human feedback in terms of preferences, we also propose to take into account the preference of the underlying RL agent while learning the reward function. We show that this helps to improve the over-optimization associated with the design of reward functions in RL. We experimentally show that REBEL exhibits up to 70% improvement in sample efficiency to achieve a similar level of episodic reward returns as compared to the state-of-the-art methods such as PEBBLE and PEBBLE+SURF.
Towards Possibilities & Impossibilities of AI-generated Text Detection: A Survey
Oct 23, 2023

Large Language Models (LLMs) have revolutionized the domain of natural language processing (NLP) with remarkable capabilities of generating human-like text responses. However, despite these advancements, several works in the existing literature have raised serious concerns about the potential misuse of LLMs such as spreading misinformation, generating fake news, plagiarism in academia, and contaminating the web. To address these concerns, a consensus among the research community is to develop algorithmic solutions to detect AI-generated text. The basic idea is that whenever we can tell if the given text is either written by a human or an AI, we can utilize this information to address the above-mentioned concerns. To that end, a plethora of detection frameworks have been proposed, highlighting the possibilities of AI-generated text detection. But in parallel to the development of detection frameworks, researchers have also concentrated on designing strategies to elude detection, i.e., focusing on the impossibilities of AI-generated text detection. This is a crucial step in order to make sure the detection frameworks are robust enough and it is not too easy to fool a detector. Despite the huge interest and the flurry of research in this domain, the community currently lacks a comprehensive analysis of recent developments. In this survey, we aim to provide a concise categorization and overview of current work encompassing both the prospects and the limitations of AI-generated text detection. To enrich the collective knowledge, we engage in an exhaustive discussion on critical and challenging open questions related to ongoing research on AI-generated text detection.
Aligning Agent Policy with Externalities: Reward Design via Bilevel RL
Aug 03, 2023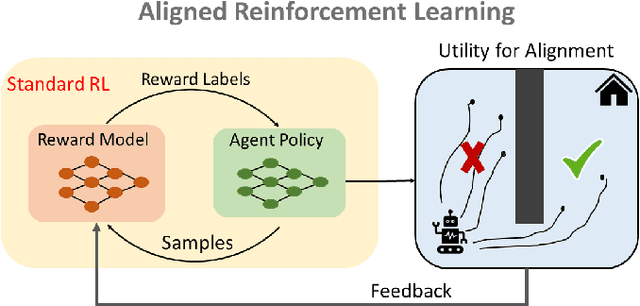
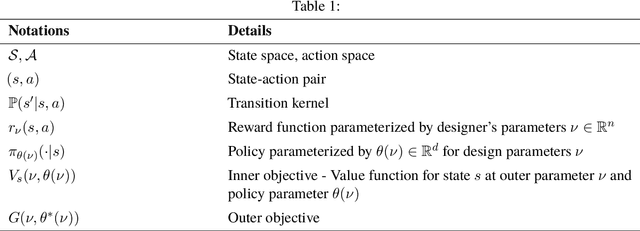
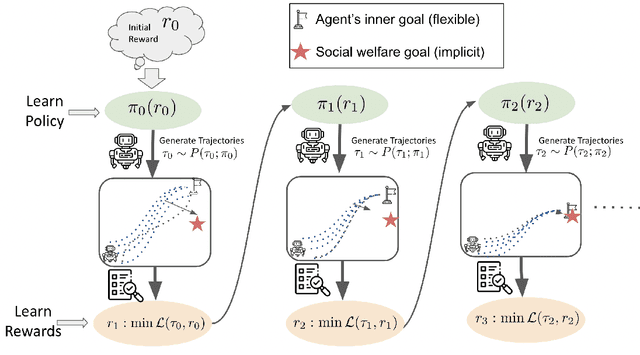
In reinforcement learning (RL), a reward function is often assumed at the outset of a policy optimization procedure. Learning in such a fixed reward paradigm in RL can neglect important policy optimization considerations, such as state space coverage and safety. Moreover, it can fail to encompass broader impacts in terms of social welfare, sustainability, or market stability, potentially leading to undesirable emergent behavior and potentially misaligned policy. To mathematically encapsulate the problem of aligning RL policy optimization with such externalities, we consider a bilevel optimization problem and connect it to a principal-agent framework, where the principal specifies the broader goals and constraints of the system at the upper level and the agent solves a Markov Decision Process (MDP) at the lower level. The upper-level deals with learning a suitable reward parametrization corresponding to the broader goals and the lower-level deals with learning the policy for the agent. We propose Principal driven Policy Alignment via Bilevel RL (PPA-BRL), which efficiently aligns the policy of the agent with the principal's goals. We explicitly analyzed the dependence of the principal's trajectory on the lower-level policy, prove the convergence of PPA-BRL to the stationary point of the problem. We illuminate the merits of this framework in view of alignment with several examples spanning energy-efficient manipulation tasks, social welfare-based tax design, and cost-effective robotic navigation.
Rethinking Adversarial Policies: A Generalized Attack Formulation and Provable Defense in Multi-Agent RL
May 27, 2023



Most existing works consider direct perturbations of victim's state/action or the underlying transition dynamics to show vulnerability of reinforcement learning agents under adversarial attacks. However, such direct manipulation may not always be feasible in practice. In this paper, we consider another common and realistic attack setup: in a multi-agent RL setting with well-trained agents, during deployment time, the victim agent $\nu$ is exploited by an attacker who controls another agent $\alpha$ to act adversarially against the victim using an \textit{adversarial policy}. Prior attack models under such setup do not consider that the attacker can confront resistance and thus can only take partial control of the agent $\alpha$, as well as introducing perceivable ``abnormal'' behaviors that are easily detectable. A provable defense against these adversarial policies is also lacking. To resolve these issues, we introduce a more general attack formulation that models to what extent the adversary is able to control the agent to produce the adversarial policy. Based on such a generalized attack framework, the attacker can also regulate the state distribution shift caused by the attack through an attack budget, and thus produce stealthy adversarial policies that can exploit the victim agent. Furthermore, we provide the first provably robust defenses with convergence guarantee to the most robust victim policy via adversarial training with timescale separation, in sharp contrast to adversarial training in supervised learning which may only provide {\it empirical} defenses.
On the Possibilities of AI-Generated Text Detection
Apr 10, 2023



Our work focuses on the challenge of detecting outputs generated by Large Language Models (LLMs) from those generated by humans. The ability to distinguish between the two is of utmost importance in numerous applications. However, the possibility and impossibility of such discernment have been subjects of debate within the community. Therefore, a central question is whether we can detect AI-generated text and, if so, when. In this work, we provide evidence that it should almost always be possible to detect the AI-generated text unless the distributions of human and machine generated texts are exactly the same over the entire support. This observation follows from the standard results in information theory and relies on the fact that if the machine text is becoming more like a human, we need more samples to detect it. We derive a precise sample complexity bound of AI-generated text detection, which tells how many samples are needed to detect. This gives rise to additional challenges of designing more complicated detectors that take in n samples to detect than just one, which is the scope of future research on this topic. Our empirical evaluations support our claim about the existence of better detectors demonstrating that AI-Generated text detection should be achievable in the majority of scenarios. Our results emphasize the importance of continued research in this area
RE-MOVE: An Adaptive Policy Design Approach for Dynamic Environments via Language-Based Feedback
Mar 14, 2023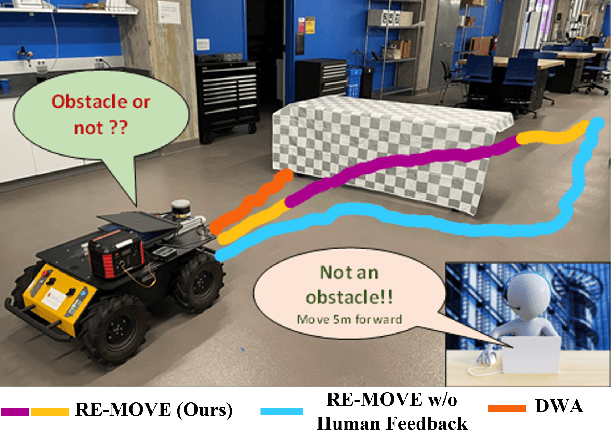


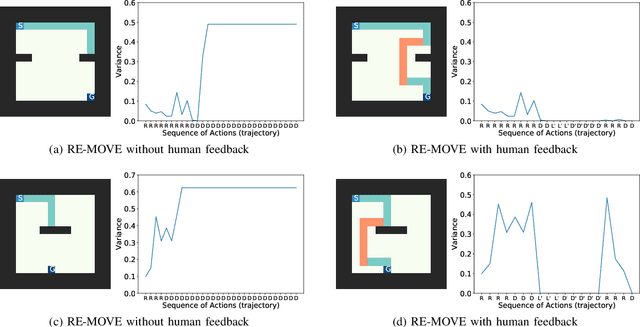
Reinforcement learning-based policies for continuous control robotic navigation tasks often fail to adapt to changes in the environment during real-time deployment, which may result in catastrophic failures. To address this limitation, we propose a novel approach called RE-MOVE (\textbf{RE}quest help and \textbf{MOVE} on), which uses language-based feedback to adjust trained policies to real-time changes in the environment. In this work, we enable the trained policy to decide \emph{when to ask for feedback} and \emph{how to incorporate feedback into trained policies}. RE-MOVE incorporates epistemic uncertainty to determine the optimal time to request feedback from humans and uses language-based feedback for real-time adaptation. We perform extensive synthetic and real-world evaluations to demonstrate the benefits of our proposed approach in several test-time dynamic navigation scenarios. Our approach enable robots to learn from human feedback and adapt to previously unseen adversarial situations.