 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAldo Pacchiano
Provable Interactive Learning with Hindsight Instruction Feedback
Apr 14, 2024
We study interactive learning in a setting where the agent has to generate a response (e.g., an action or trajectory) given a context and an instruction. In contrast, to typical approaches that train the system using reward or expert supervision on response, we study learning with hindsight instruction where a teacher provides an instruction that is most suitable for the agent's generated response. This hindsight labeling of instruction is often easier to provide than providing expert supervision of the optimal response which may require expert knowledge or can be impractical to elicit. We initiate the theoretical analysis of interactive learning with hindsight labeling. We first provide a lower bound showing that in general, the regret of any algorithm must scale with the size of the agent's response space. We then study a specialized setting where the underlying instruction-response distribution can be decomposed as a low-rank matrix. We introduce an algorithm called LORIL for this setting and show that its regret scales as $\sqrt{T}$ where $T$ is the number of rounds and depends on the intrinsic rank but does not depend on the size of the agent's response space. We provide experiments in two domains showing that LORIL outperforms baselines even when the low-rank assumption is violated.
Multiple-policy Evaluation via Density Estimation
Mar 29, 2024In this work, we focus on the multiple-policy evaluation problem where we are given a set of $K$ target policies and the goal is to evaluate their performance (the expected total rewards) to an accuracy $\epsilon$ with probability at least $1-\delta$. We propose an algorithm named $\mathrm{CAESAR}$ to address this problem. Our approach is based on computing an approximate optimal offline sampling distribution and using the data sampled from it to perform the simultaneous estimation of the policy values. $\mathrm{CAESAR}$ consists of two phases. In the first one we produce coarse estimates of the vistation distributions of the target policies at a low order sample complexity rate that scales with $\tilde{O}(\frac{1}{\epsilon})$. In the second phase, we approximate the optimal offline sampling distribution and compute the importance weighting ratios for all target policies by minimizing a step-wise quadratic loss function inspired by the objective in DualDICE. Up to low order and logarithm terms $\mathrm{CAESAR}$ achieves a sample complexity $\tilde{O}\left(\frac{H^4}{\epsilon^2}\sum_{h=1}^H\max_{k\in[K]}\sum_{s,a}\frac{(d_h^{\pi^k}(s,a))^2}{\mu^*_h(s,a)}\right)$, where $d^{\pi}$ is the visitation distribution of policy $\pi$ and $\mu^*$ is the optimal sampling distribution.
Provably Sample Efficient RLHF via Active Preference Optimization
Feb 16, 2024Reinforcement Learning from Human Feedback (RLHF) is pivotal in aligning Large Language Models (LLMs) with human preferences. While these aligned generative models have demonstrated impressive capabilities across various tasks, the dependence on high-quality human preference data poses a costly bottleneck in practical implementation of RLHF. Hence better and adaptive strategies for data collection is needed. To this end, we frame RLHF as a contextual preference bandit problem with prompts as contexts and show that the naive way of collecting preference data by choosing prompts uniformly at random leads to a policy that suffers an $\Omega(1)$ suboptimality gap in rewards. Then we propose $\textit{Active Preference Optimization}$ ($\texttt{APO}$), an algorithm that actively selects prompts to collect preference data. Under the Bradley-Terry-Luce (BTL) preference model, \texttt{APO} achieves sample efficiency without compromising on policy performance. We show that given a sample budget of $T$, the suboptimality gap of a policy learned via $\texttt{APO}$ scales as $O(1/\sqrt{T})$. Next, we propose a compute-efficient batch version of $\texttt{APO}$ with minor modification and evaluate its performance in practice. Experimental evaluations on a human preference dataset validate \texttt{APO}'s efficacy as a sample-efficient and practical solution to data collection for RLHF, facilitating alignment of LLMs with human preferences in a cost-effective and scalable manner.
A Framework for Partially Observed Reward-States in RLHF
Feb 05, 2024The study of reinforcement learning from human feedback (RLHF) has gained prominence in recent years due to its role in the development of LLMs. Neuroscience research shows that human responses to stimuli are known to depend on partially-observed "internal states." Unfortunately current models of RLHF do not take take this into consideration. Moreover most RLHF models do not account for intermediate feedback, which is gaining importance in empirical work and can help improve both sample complexity and alignment. To address these limitations, we model RLHF as reinforcement learning with partially observed reward-states (PORRL). We show reductions from the the two dominant forms of human feedback in RLHF - cardinal and dueling feedback to PORRL. For cardinal feedback, we develop generic statistically efficient algorithms and instantiate them to present POR-UCRL and POR-UCBVI. For dueling feedback, we show that a naive reduction to cardinal feedback fails to achieve sublinear dueling regret. We then present the first explicit reduction that converts guarantees for cardinal regret to dueling regret. We show that our models and guarantees in both settings generalize and extend existing ones. Finally, we identify a recursive structure on our model that could improve the statistical and computational tractability of PORRL, giving examples from past work on RLHF as well as learning perfect reward machines, which PORRL subsumes.
Contextual Bandits with Stage-wise Constraints
Jan 15, 2024We study contextual bandits in the presence of a stage-wise constraint (a constraint at each round), when the constraint must be satisfied both with high probability and in expectation. Obviously the setting where the constraint is in expectation is a relaxation of the one with high probability. We start with the linear case where both the contextual bandit problem (reward function) and the stage-wise constraint (cost function) are linear. In each of the high probability and in expectation settings, we propose an upper-confidence bound algorithm for the problem and prove a $T$-round regret bound for it. Our algorithms balance exploration and constraint satisfaction using a novel idea that scales the radii of the reward and cost confidence sets with different scaling factors. We also prove a lower-bound for this constrained problem, show how our algorithms and analyses can be extended to multiple constraints, and provide simulations to validate our theoretical results. In the high probability setting, we describe the minimum requirements for the action set in order for our algorithm to be tractable. In the setting that the constraint is in expectation, we further specialize our results to multi-armed bandits and propose a computationally efficient algorithm for this setting with regret analysis. Finally, we extend our results to the case where the reward and cost functions are both non-linear. We propose an algorithm for this case and prove a regret bound for it that characterize the function class complexity by the eluder dimension.
Experiment Planning with Function Approximation
Jan 10, 2024We study the problem of experiment planning with function approximation in contextual bandit problems. In settings where there is a significant overhead to deploying adaptive algorithms -- for example, when the execution of the data collection policies is required to be distributed, or a human in the loop is needed to implement these policies -- producing in advance a set of policies for data collection is paramount. We study the setting where a large dataset of contexts but not rewards is available and may be used by the learner to design an effective data collection strategy. Although when rewards are linear this problem has been well studied, results are still missing for more complex reward models. In this work we propose two experiment planning strategies compatible with function approximation. The first is an eluder planning and sampling procedure that can recover optimality guarantees depending on the eluder dimension of the reward function class. For the second, we show that a uniform sampler achieves competitive optimality rates in the setting where the number of actions is small. We finalize our results introducing a statistical gap fleshing out the fundamental differences between planning and adaptive learning and provide results for planning with model selection.
Unbiased Decisions Reduce Regret: Adversarial Domain Adaptation for the Bank Loan Problem
Aug 15, 2023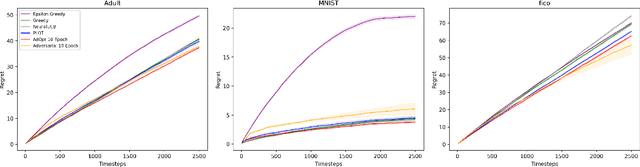

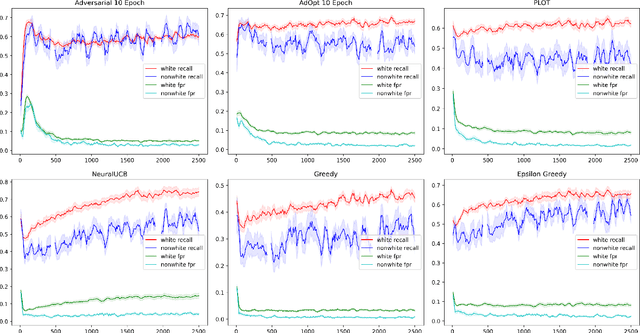

In many real world settings binary classification decisions are made based on limited data in near real-time, e.g. when assessing a loan application. We focus on a class of these problems that share a common feature: the true label is only observed when a data point is assigned a positive label by the principal, e.g. we only find out whether an applicant defaults if we accepted their loan application. As a consequence, the false rejections become self-reinforcing and cause the labelled training set, that is being continuously updated by the model decisions, to accumulate bias. Prior work mitigates this effect by injecting optimism into the model, however this comes at the cost of increased false acceptance rate. We introduce adversarial optimism (AdOpt) to directly address bias in the training set using adversarial domain adaptation. The goal of AdOpt is to learn an unbiased but informative representation of past data, by reducing the distributional shift between the set of accepted data points and all data points seen thus far. AdOpt significantly exceeds state-of-the-art performance on a set of challenging benchmark problems. Our experiments also provide initial evidence that the introduction of adversarial domain adaptation improves fairness in this setting.
Anytime Model Selection in Linear Bandits
Jul 24, 2023
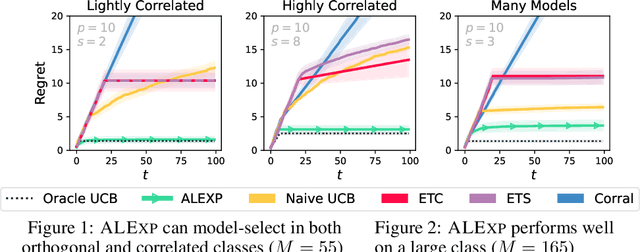
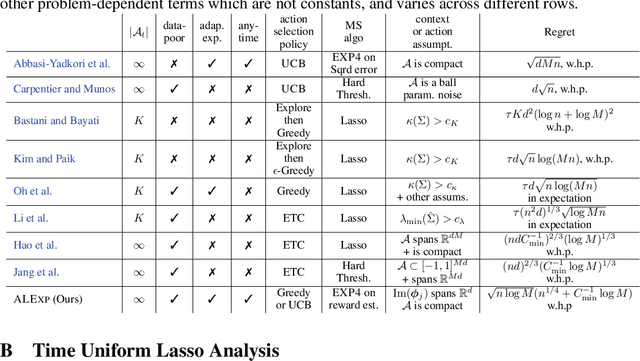
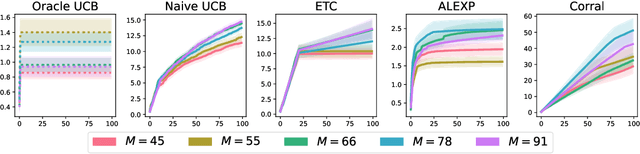
Model selection in the context of bandit optimization is a challenging problem, as it requires balancing exploration and exploitation not only for action selection, but also for model selection. One natural approach is to rely on online learning algorithms that treat different models as experts. Existing methods, however, scale poorly ($\text{poly}M$) with the number of models $M$ in terms of their regret. Our key insight is that, for model selection in linear bandits, we can emulate full-information feedback to the online learner with a favorable bias-variance trade-off. This allows us to develop ALEXP, which has an exponentially improved ($\log M$) dependence on $M$ for its regret. ALEXP has anytime guarantees on its regret, and neither requires knowledge of the horizon $n$, nor relies on an initial purely exploratory stage. Our approach utilizes a novel time-uniform analysis of the Lasso, establishing a new connection between online learning and high-dimensional statistics.
Supervised Pretraining Can Learn In-Context Reinforcement Learning
Jun 26, 2023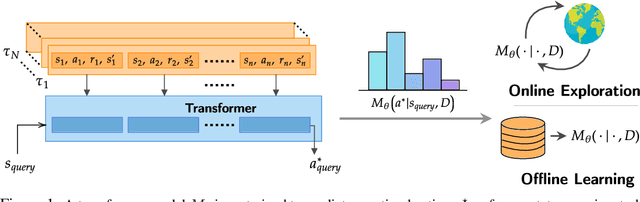
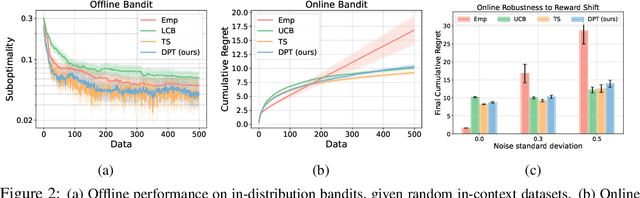
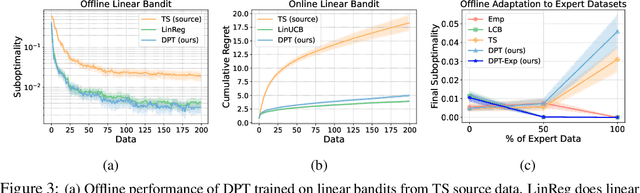
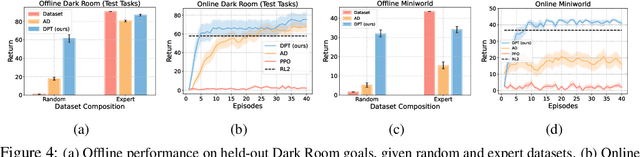
Large transformer models trained on diverse datasets have shown a remarkable ability to learn in-context, achieving high few-shot performance on tasks they were not explicitly trained to solve. In this paper, we study the in-context learning capabilities of transformers in decision-making problems, i.e., reinforcement learning (RL) for bandits and Markov decision processes. To do so, we introduce and study Decision-Pretrained Transformer (DPT), a supervised pretraining method where the transformer predicts an optimal action given a query state and an in-context dataset of interactions, across a diverse set of tasks. This procedure, while simple, produces a model with several surprising capabilities. We find that the pretrained transformer can be used to solve a range of RL problems in-context, exhibiting both exploration online and conservatism offline, despite not being explicitly trained to do so. The model also generalizes beyond the pretraining distribution to new tasks and automatically adapts its decision-making strategies to unknown structure. Theoretically, we show DPT can be viewed as an efficient implementation of Bayesian posterior sampling, a provably sample-efficient RL algorithm. We further leverage this connection to provide guarantees on the regret of the in-context algorithm yielded by DPT, and prove that it can learn faster than algorithms used to generate the pretraining data. These results suggest a promising yet simple path towards instilling strong in-context decision-making abilities in transformers.
A Unified Model and Dimension for Interactive Estimation
Jun 09, 2023
We study an abstract framework for interactive learning called interactive estimation in which the goal is to estimate a target from its "similarity'' to points queried by the learner. We introduce a combinatorial measure called dissimilarity dimension which largely captures learnability in our model. We present a simple, general, and broadly-applicable algorithm, for which we obtain both regret and PAC generalization bounds that are polynomial in the new dimension. We show that our framework subsumes and thereby unifies two classic learning models: statistical-query learning and structured bandits. We also delineate how the dissimilarity dimension is related to well-known parameters for both frameworks, in some cases yielding significantly improved analyses.