 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiangyu Liu
Do LLM Agents Have Regret? A Case Study in Online Learning and Games
Mar 25, 2024
Large language models (LLMs) have been increasingly employed for (interactive) decision-making, via the development of LLM-based autonomous agents. Despite their emerging successes, the performance of LLM agents in decision-making has not been fully investigated through quantitative metrics, especially in the multi-agent setting when they interact with each other, a typical scenario in real-world LLM-agent applications. To better understand the limits of LLM agents in these interactive environments, we propose to study their interactions in benchmark decision-making settings in online learning and game theory, through the performance metric of \emph{regret}. We first empirically study the {no-regret} behaviors of LLMs in canonical (non-stationary) online learning problems, as well as the emergence of equilibria when LLM agents interact through playing repeated games. We then provide some theoretical insights into the no-regret behaviors of LLM agents, under certain assumptions on the supervised pre-training and the rationality model of human decision-makers who generate the data. Notably, we also identify (simple) cases where advanced LLMs such as GPT-4 fail to be no-regret. To promote the no-regret behaviors, we propose a novel \emph{unsupervised} training loss of \emph{regret-loss}, which, in contrast to the supervised pre-training loss, does not require the labels of (optimal) actions. We then establish the statistical guarantee of generalization bound for regret-loss minimization, followed by the optimization guarantee that minimizing such a loss may automatically lead to known no-regret learning algorithms. Our further experiments demonstrate the effectiveness of our regret-loss, especially in addressing the above ``regrettable'' cases.
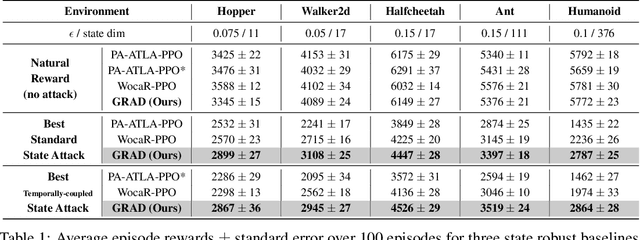
Beyond Worst-case Attacks: Robust RL with Adaptive Defense via Non-dominated Policies
Feb 20, 2024In light of the burgeoning success of reinforcement learning (RL) in diverse real-world applications, considerable focus has been directed towards ensuring RL policies are robust to adversarial attacks during test time. Current approaches largely revolve around solving a minimax problem to prepare for potential worst-case scenarios. While effective against strong attacks, these methods often compromise performance in the absence of attacks or the presence of only weak attacks. To address this, we study policy robustness under the well-accepted state-adversarial attack model, extending our focus beyond only worst-case attacks. We first formalize this task at test time as a regret minimization problem and establish its intrinsic hardness in achieving sublinear regret when the baseline policy is from a general continuous policy class, $\Pi$. This finding prompts us to \textit{refine} the baseline policy class $\Pi$ prior to test time, aiming for efficient adaptation within a finite policy class $\Tilde{\Pi}$, which can resort to an adversarial bandit subroutine. In light of the importance of a small, finite $\Tilde{\Pi}$, we propose a novel training-time algorithm to iteratively discover \textit{non-dominated policies}, forming a near-optimal and minimal $\Tilde{\Pi}$, thereby ensuring both robustness and test-time efficiency. Empirical validation on the Mujoco corroborates the superiority of our approach in terms of natural and robust performance, as well as adaptability to various attack scenarios.
Knowledge Graph Error Detection with Contrastive Confidence Adaption
Dec 19, 2023Knowledge graphs (KGs) often contain various errors. Previous works on detecting errors in KGs mainly rely on triplet embedding from graph structure. We conduct an empirical study and find that these works struggle to discriminate noise from semantically-similar correct triplets. In this paper, we propose a KG error detection model CCA to integrate both textual and graph structural information from triplet reconstruction for better distinguishing semantics. We design interactive contrastive learning to capture the differences between textual and structural patterns. Furthermore, we construct realistic datasets with semantically-similar noise and adversarial noise. Experimental results demonstrate that CCA outperforms state-of-the-art baselines, especially in detecting semantically-similar noise and adversarial noise.
Weathering Ongoing Uncertainty: Learning and Planning in a Time-Varying Partially Observable Environment
Dec 06, 2023Optimal decision-making presents a significant challenge for autonomous systems operating in uncertain, stochastic and time-varying environments. Environmental variability over time can significantly impact the system's optimal decision making strategy for mission completion. To model such environments, our work combines the previous notion of Time-Varying Markov Decision Processes (TVMDP) with partial observability and introduces Time-Varying Partially Observable Markov Decision Processes (TV-POMDP). We propose a two-pronged approach to accurately estimate and plan within the TV-POMDP: 1) Memory Prioritized State Estimation (MPSE), which leverages weighted memory to provide more accurate time-varying transition estimates; and 2) an MPSE-integrated planning strategy that optimizes long-term rewards while accounting for temporal constraint. We validate the proposed framework and algorithms using simulations and hardware, with robots exploring a partially observable, time-varying environments. Our results demonstrate superior performance over standard methods, highlighting the framework's effectiveness in stochastic, uncertain, time-varying domains.
Partially Observable Multi-agent RL with (Quasi-)Efficiency: The Blessing of Information Sharing
Aug 16, 2023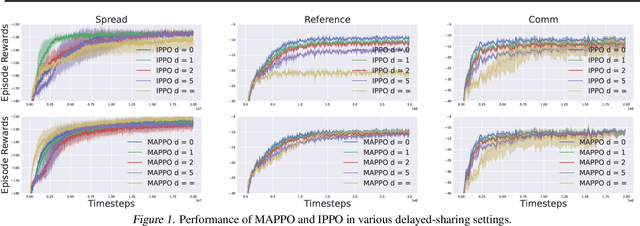

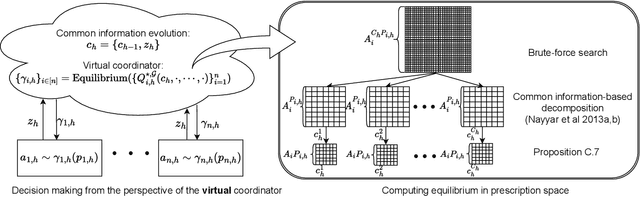
We study provable multi-agent reinforcement learning (MARL) in the general framework of partially observable stochastic games (POSGs). To circumvent the known hardness results and the use of computationally intractable oracles, we advocate leveraging the potential \emph{information-sharing} among agents, a common practice in empirical MARL, and a standard model for multi-agent control systems with communications. We first establish several computation complexity results to justify the necessity of information-sharing, as well as the observability assumption that has enabled quasi-efficient single-agent RL with partial observations, for computational efficiency in solving POSGs. We then propose to further \emph{approximate} the shared common information to construct an {approximate model} of the POSG, in which planning an approximate equilibrium (in terms of solving the original POSG) can be quasi-efficient, i.e., of quasi-polynomial-time, under the aforementioned assumptions. Furthermore, we develop a partially observable MARL algorithm that is both statistically and computationally quasi-efficient. We hope our study may open up the possibilities of leveraging and even designing different \emph{information structures}, for developing both sample- and computation-efficient partially observable MARL.
Game-Theoretic Robust Reinforcement Learning Handles Temporally-Coupled Perturbations
Jul 22, 2023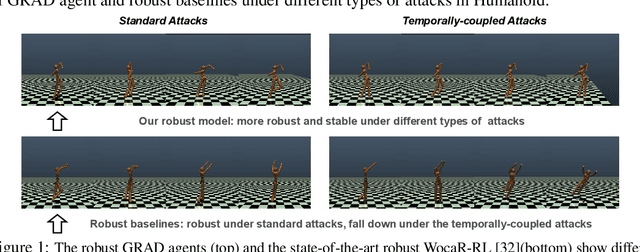


Robust reinforcement learning (RL) seeks to train policies that can perform well under environment perturbations or adversarial attacks. Existing approaches typically assume that the space of possible perturbations remains the same across timesteps. However, in many settings, the space of possible perturbations at a given timestep depends on past perturbations. We formally introduce temporally-coupled perturbations, presenting a novel challenge for existing robust RL methods. To tackle this challenge, we propose GRAD, a novel game-theoretic approach that treats the temporally-coupled robust RL problem as a partially-observable two-player zero-sum game. By finding an approximate equilibrium in this game, GRAD ensures the agent's robustness against temporally-coupled perturbations. Empirical experiments on a variety of continuous control tasks demonstrate that our proposed approach exhibits significant robustness advantages compared to baselines against both standard and temporally-coupled attacks, in both state and action spaces.
Rethinking Adversarial Policies: A Generalized Attack Formulation and Provable Defense in Multi-Agent RL
May 27, 2023



Most existing works consider direct perturbations of victim's state/action or the underlying transition dynamics to show vulnerability of reinforcement learning agents under adversarial attacks. However, such direct manipulation may not always be feasible in practice. In this paper, we consider another common and realistic attack setup: in a multi-agent RL setting with well-trained agents, during deployment time, the victim agent $\nu$ is exploited by an attacker who controls another agent $\alpha$ to act adversarially against the victim using an \textit{adversarial policy}. Prior attack models under such setup do not consider that the attacker can confront resistance and thus can only take partial control of the agent $\alpha$, as well as introducing perceivable ``abnormal'' behaviors that are easily detectable. A provable defense against these adversarial policies is also lacking. To resolve these issues, we introduce a more general attack formulation that models to what extent the adversary is able to control the agent to produce the adversarial policy. Based on such a generalized attack framework, the attacker can also regulate the state distribution shift caused by the attack through an attack budget, and thus produce stealthy adversarial policies that can exploit the victim agent. Furthermore, we provide the first provably robust defenses with convergence guarantee to the most robust victim policy via adversarial training with timescale separation, in sharp contrast to adversarial training in supervised learning which may only provide {\it empirical} defenses.
FairRec: Fairness Testing for Deep Recommender Systems
Apr 14, 2023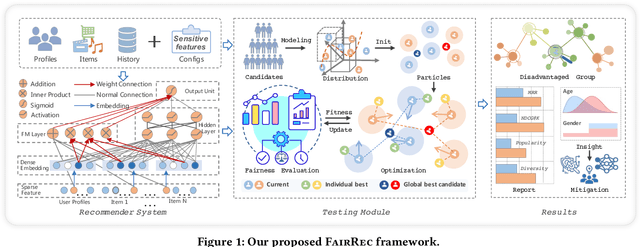
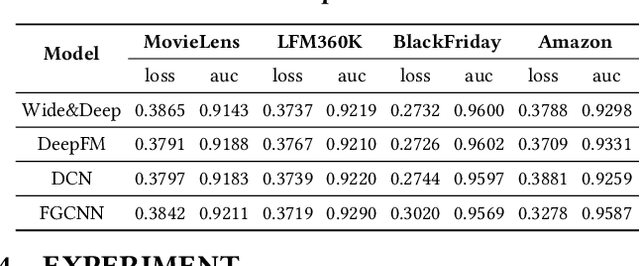
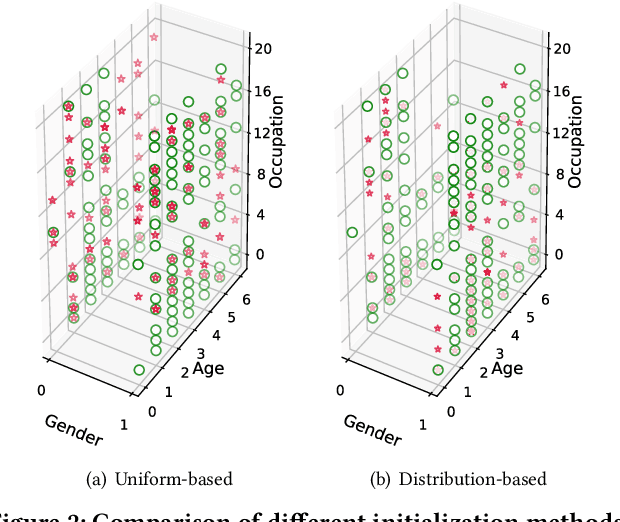
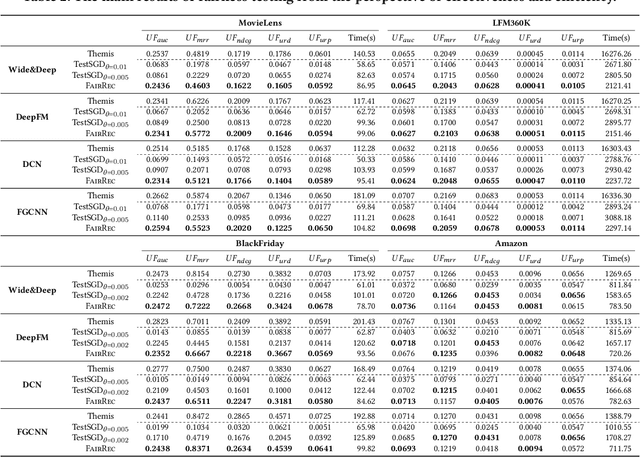
Deep learning-based recommender systems (DRSs) are increasingly and widely deployed in the industry, which brings significant convenience to people's daily life in different ways. However, recommender systems are also shown to suffer from multiple issues,e.g., the echo chamber and the Matthew effect, of which the notation of "fairness" plays a core role.While many fairness notations and corresponding fairness testing approaches have been developed for traditional deep classification models, they are essentially hardly applicable to DRSs. One major difficulty is that there still lacks a systematic understanding and mapping between the existing fairness notations and the diverse testing requirements for deep recommender systems, not to mention further testing or debugging activities. To address the gap, we propose FairRec, a unified framework that supports fairness testing of DRSs from multiple customized perspectives, e.g., model utility, item diversity, item popularity, etc. We also propose a novel, efficient search-based testing approach to tackle the new challenge, i.e., double-ended discrete particle swarm optimization (DPSO) algorithm, to effectively search for hidden fairness issues in the form of certain disadvantaged groups from a vast number of candidate groups. Given the testing report, by adopting a simple re-ranking mitigation strategy on these identified disadvantaged groups, we show that the fairness of DRSs can be significantly improved. We conducted extensive experiments on multiple industry-level DRSs adopted by leading companies. The results confirm that FairRec is effective and efficient in identifying the deeply hidden fairness issues, e.g., achieving 95% testing accuracy with half to 1/8 time.
Deep Reinforcement Learning for Localizability-Enhanced Navigation in Dynamic Human Environments
Mar 22, 2023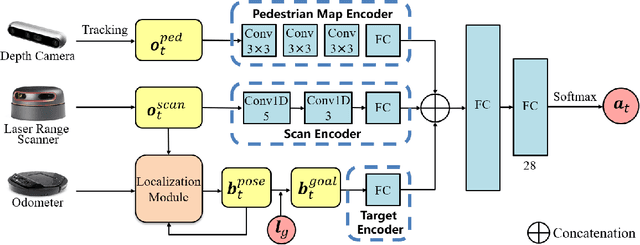

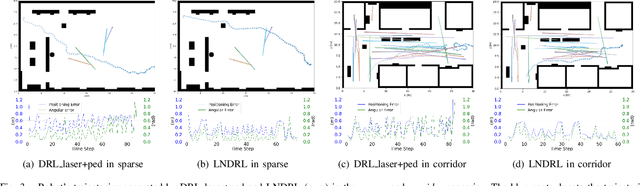
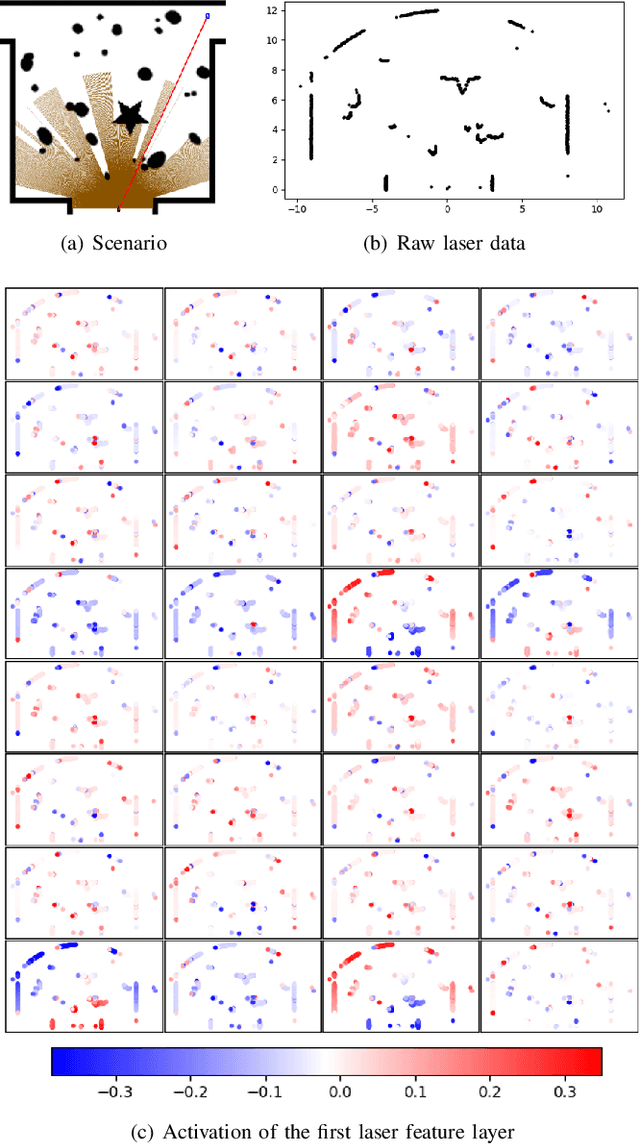
Reliable localization is crucial for autonomous robots to navigate efficiently and safely. Some navigation methods can plan paths with high localizability (which describes the capability of acquiring reliable localization). By following these paths, the robot can access the sensor streams that facilitate more accurate location estimation results by the localization algorithms. However, most of these methods require prior knowledge and struggle to adapt to unseen scenarios or dynamic changes. To overcome these limitations, we propose a novel approach for localizability-enhanced navigation via deep reinforcement learning in dynamic human environments. Our proposed planner automatically extracts geometric features from 2D laser data that are helpful for localization. The planner learns to assign different importance to the geometric features and encourages the robot to navigate through areas that are helpful for laser localization. To facilitate the learning of the planner, we suggest two techniques: (1) an augmented state representation that considers the dynamic changes and the confidence of the localization results, which provides more information and allows the robot to make better decisions, (2) a reward metric that is capable to offer both sparse and dense feedback on behaviors that affect localization accuracy. Our method exhibits significant improvements in lost rate and arrival rate when tested in previously unseen environments.
A Survey on Knowledge-Enhanced Pre-trained Language Models
Dec 27, 2022
Natural Language Processing (NLP) has been revolutionized by the use of Pre-trained Language Models (PLMs) such as BERT. Despite setting new records in nearly every NLP task, PLMs still face a number of challenges including poor interpretability, weak reasoning capability, and the need for a lot of expensive annotated data when applied to downstream tasks. By integrating external knowledge into PLMs, \textit{\underline{K}nowledge-\underline{E}nhanced \underline{P}re-trained \underline{L}anguage \underline{M}odels} (KEPLMs) have the potential to overcome the above-mentioned limitations. In this paper, we examine KEPLMs systematically through a series of studies. Specifically, we outline the common types and different formats of knowledge to be integrated into KEPLMs, detail the existing methods for building and evaluating KEPLMS, present the applications of KEPLMs in downstream tasks, and discuss the future research directions. Researchers will benefit from this survey by gaining a quick and comprehensive overview of the latest developments in this field.