 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsuman Ozdaglar
Do LLM Agents Have Regret? A Case Study in Online Learning and Games
Mar 25, 2024
Large language models (LLMs) have been increasingly employed for (interactive) decision-making, via the development of LLM-based autonomous agents. Despite their emerging successes, the performance of LLM agents in decision-making has not been fully investigated through quantitative metrics, especially in the multi-agent setting when they interact with each other, a typical scenario in real-world LLM-agent applications. To better understand the limits of LLM agents in these interactive environments, we propose to study their interactions in benchmark decision-making settings in online learning and game theory, through the performance metric of \emph{regret}. We first empirically study the {no-regret} behaviors of LLMs in canonical (non-stationary) online learning problems, as well as the emergence of equilibria when LLM agents interact through playing repeated games. We then provide some theoretical insights into the no-regret behaviors of LLM agents, under certain assumptions on the supervised pre-training and the rationality model of human decision-makers who generate the data. Notably, we also identify (simple) cases where advanced LLMs such as GPT-4 fail to be no-regret. To promote the no-regret behaviors, we propose a novel \emph{unsupervised} training loss of \emph{regret-loss}, which, in contrast to the supervised pre-training loss, does not require the labels of (optimal) actions. We then establish the statistical guarantee of generalization bound for regret-loss minimization, followed by the optimization guarantee that minimizing such a loss may automatically lead to known no-regret learning algorithms. Our further experiments demonstrate the effectiveness of our regret-loss, especially in addressing the above ``regrettable'' cases.
Matching of Users and Creators in Two-Sided Markets with Departures
Jan 17, 2024Many online platforms of today, including social media sites, are two-sided markets bridging content creators and users. Most of the existing literature on platform recommendation algorithms largely focuses on user preferences and decisions, and does not simultaneously address creator incentives. We propose a model of content recommendation that explicitly focuses on the dynamics of user-content matching, with the novel property that both users and creators may leave the platform permanently if they do not experience sufficient engagement. In our model, each player decides to participate at each time step based on utilities derived from the current match: users based on alignment of the recommended content with their preferences, and creators based on their audience size. We show that a user-centric greedy algorithm that does not consider creator departures can result in arbitrarily poor total engagement, relative to an algorithm that maximizes total engagement while accounting for two-sided departures. Moreover, in stark contrast to the case where only users or only creators leave the platform, we prove that with two-sided departures, approximating maximum total engagement within any constant factor is NP-hard. We present two practical algorithms, one with performance guarantees under mild assumptions on user preferences, and another that tends to outperform algorithms that ignore two-sided departures in practice.
Two-Timescale Q-Learning with Function Approximation in Zero-Sum Stochastic Games
Dec 08, 2023We consider two-player zero-sum stochastic games and propose a two-timescale $Q$-learning algorithm with function approximation that is payoff-based, convergent, rational, and symmetric between the two players. In two-timescale $Q$-learning, the fast-timescale iterates are updated in spirit to the stochastic gradient descent and the slow-timescale iterates (which we use to compute the policies) are updated by taking a convex combination between its previous iterate and the latest fast-timescale iterate. Introducing the slow timescale as well as its update equation marks as our main algorithmic novelty. In the special case of linear function approximation, we establish, to the best of our knowledge, the first last-iterate finite-sample bound for payoff-based independent learning dynamics of these types. The result implies a polynomial sample complexity to find a Nash equilibrium in such stochastic games. To establish the results, we model our proposed algorithm as a two-timescale stochastic approximation and derive the finite-sample bound through a Lyapunov-based approach. The key novelty lies in constructing a valid Lyapunov function to capture the evolution of the slow-timescale iterates. Specifically, through a change of variable, we show that the update equation of the slow-timescale iterates resembles the classical smoothed best-response dynamics, where the regularized Nash gap serves as a valid Lyapunov function. This insight enables us to construct a valid Lyapunov function via a generalized variant of the Moreau envelope of the regularized Nash gap. The construction of our Lyapunov function might be of broad independent interest in studying the behavior of stochastic approximation algorithms.
EM for Mixture of Linear Regression with Clustered Data
Aug 22, 2023Modern data-driven and distributed learning frameworks deal with diverse massive data generated by clients spread across heterogeneous environments. Indeed, data heterogeneity is a major bottleneck in scaling up many distributed learning paradigms. In many settings however, heterogeneous data may be generated in clusters with shared structures, as is the case in several applications such as federated learning where a common latent variable governs the distribution of all the samples generated by a client. It is therefore natural to ask how the underlying clustered structures in distributed data can be exploited to improve learning schemes. In this paper, we tackle this question in the special case of estimating $d$-dimensional parameters of a two-component mixture of linear regressions problem where each of $m$ nodes generates $n$ samples with a shared latent variable. We employ the well-known Expectation-Maximization (EM) method to estimate the maximum likelihood parameters from $m$ batches of dependent samples each containing $n$ measurements. Discarding the clustered structure in the mixture model, EM is known to require $O(\log(mn/d))$ iterations to reach the statistical accuracy of $O(\sqrt{d/(mn)})$. In contrast, we show that if initialized properly, EM on the structured data requires only $O(1)$ iterations to reach the same statistical accuracy, as long as $m$ grows up as $e^{o(n)}$. Our analysis establishes and combines novel asymptotic optimization and generalization guarantees for population and empirical EM with dependent samples, which may be of independent interest.
Multi-Player Zero-Sum Markov Games with Networked Separable Interactions
Jul 13, 2023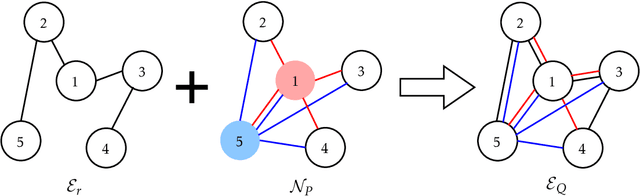
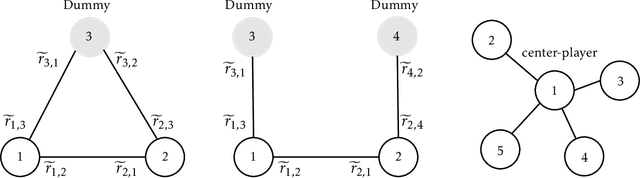

We study a new class of Markov games (MGs), \textit{Multi-player Zero-sum Markov Games} with {\it Networked separable interactions} (MZNMGs), to model the local interaction structure in non-cooperative multi-agent sequential decision-making. We define an MZNMG as a model where {the payoffs of the auxiliary games associated with each state are zero-sum and} have some separable (i.e., polymatrix) structure across the neighbors over some interaction network. We first identify the necessary and sufficient conditions under which an MG can be presented as an MZNMG, and show that the set of Markov coarse correlated equilibrium (CCE) collapses to the set of Markov Nash equilibrium (NE) in these games, in that the {product of} per-state marginalization of the former for all players yields the latter. Furthermore, we show that finding approximate Markov \emph{stationary} CCE in infinite-horizon discounted MZNMGs is \texttt{PPAD}-hard, unless the underlying network has a ``star topology''. Then, we propose fictitious-play-type dynamics, the classical learning dynamics in normal-form games, for MZNMGs, and establish convergence guarantees to Markov stationary NE under a star-shaped network structure. Finally, in light of the hardness result, we focus on computing a Markov \emph{non-stationary} NE and provide finite-iteration guarantees for a series of value-iteration-based algorithms. We also provide numerical experiments to corroborate our theoretical results.
A Finite-Sample Analysis of Payoff-Based Independent Learning in Zero-Sum Stochastic Games
Mar 03, 2023We study two-player zero-sum stochastic games, and propose a form of independent learning dynamics called Doubly Smoothed Best-Response dynamics, which integrates a discrete and doubly smoothed variant of the best-response dynamics into temporal-difference (TD)-learning and minimax value iteration. The resulting dynamics are payoff-based, convergent, rational, and symmetric among players. Our main results provide finite-sample guarantees. In particular, we prove the first-known $\tilde{\mathcal{O}}(1/\epsilon^2)$ sample complexity bound for payoff-based independent learning dynamics, up to a smoothing bias. In the special case where the stochastic game has only one state (i.e., matrix games), we provide a sharper $\tilde{\mathcal{O}}(1/\epsilon)$ sample complexity. Our analysis uses a novel coupled Lyapunov drift approach to capture the evolution of multiple sets of coupled and stochastic iterates, which might be of independent interest.
Revisiting the Linear-Programming Framework for Offline RL with General Function Approximation
Dec 28, 2022Offline reinforcement learning (RL) concerns pursuing an optimal policy for sequential decision-making from a pre-collected dataset, without further interaction with the environment. Recent theoretical progress has focused on developing sample-efficient offline RL algorithms with various relaxed assumptions on data coverage and function approximators, especially to handle the case with excessively large state-action spaces. Among them, the framework based on the linear-programming (LP) reformulation of Markov decision processes has shown promise: it enables sample-efficient offline RL with function approximation, under only partial data coverage and realizability assumptions on the function classes, with favorable computational tractability. In this work, we revisit the LP framework for offline RL, and advance the existing results in several aspects, relaxing certain assumptions and achieving optimal statistical rates in terms of sample size. Our key enabler is to introduce proper constraints in the reformulation, instead of using any regularization as in the literature, sometimes also with careful choices of the function classes and initial state distributions. We hope our insights further advocate the study of the LP framework, as well as the induced primal-dual minimax optimization, in offline RL.
Symmetric (Optimistic) Natural Policy Gradient for Multi-agent Learning with Parameter Convergence
Oct 23, 2022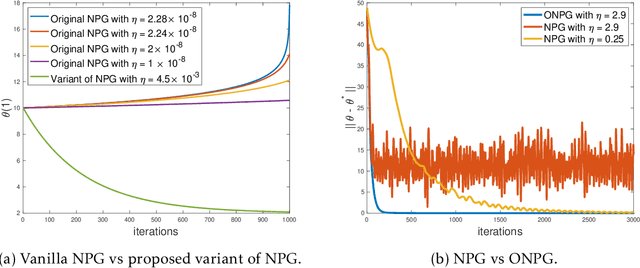

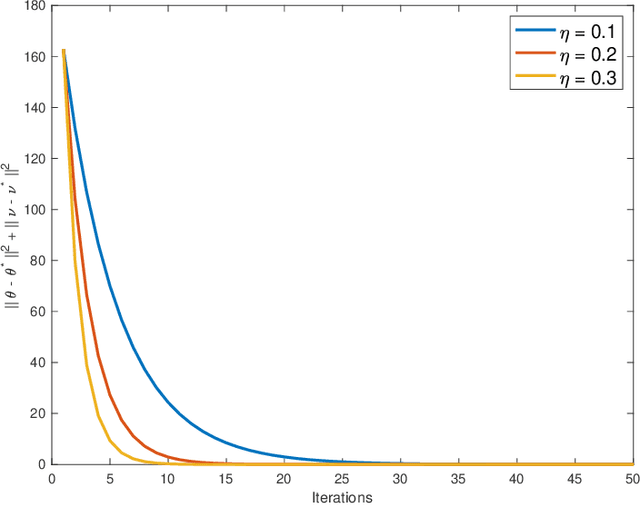
Multi-agent interactions are increasingly important in the context of reinforcement learning, and the theoretical foundations of policy gradient methods have attracted surging research interest. We investigate the global convergence of natural policy gradient (NPG) algorithms in multi-agent learning. We first show that vanilla NPG may not have parameter convergence, i.e., the convergence of the vector that parameterizes the policy, even when the costs are regularized (which enabled strong convergence guarantees in the policy space in the literature). This non-convergence of parameters leads to stability issues in learning, which becomes especially relevant in the function approximation setting, where we can only operate on low-dimensional parameters, instead of the high-dimensional policy. We then propose variants of the NPG algorithm, for several standard multi-agent learning scenarios: two-player zero-sum matrix and Markov games, and multi-player monotone games, with global last-iterate parameter convergence guarantees. We also generalize the results to certain function approximation settings. Note that in our algorithms, the agents take symmetric roles. Our results might also be of independent interest for solving nonconvex-nonconcave minimax optimization problems with certain structures. Simulations are also provided to corroborate our theoretical findings.
What is a Good Metric to Study Generalization of Minimax Learners?
Jun 20, 2022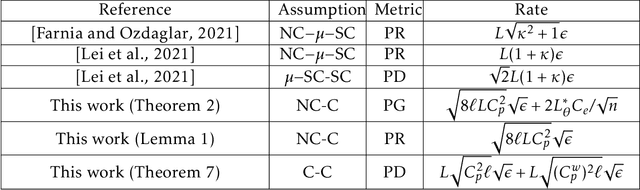

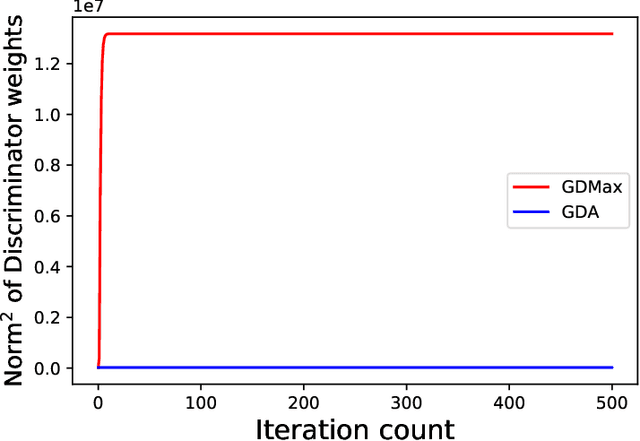
Minimax optimization has served as the backbone of many machine learning (ML) problems. Although the convergence behavior of optimization algorithms has been extensively studied in the minimax settings, their generalization guarantees in stochastic minimax optimization problems, i.e., how the solution trained on empirical data performs on unseen testing data, have been relatively underexplored. A fundamental question remains elusive: What is a good metric to study generalization of minimax learners? In this paper, we aim to answer this question by first showing that primal risk, a universal metric to study generalization in minimization problems, which has also been adopted recently to study generalization in minimax ones, fails in simple examples. We thus propose a new metric to study generalization of minimax learners: the primal gap, defined as the difference between the primal risk and its minimum over all models, to circumvent the issues. Next, we derive generalization error bounds for the primal gap in nonconvex-concave settings. As byproducts of our analysis, we also solve two open questions: establishing generalization error bounds for primal risk and primal-dual risk, another existing metric that is only well-defined when the global saddle-point exists, in the strong sense, i.e., without strong concavity or assuming that the maximization and expectation can be interchanged, while either of these assumptions was needed in the literature. Finally, we leverage this new metric to compare the generalization behavior of two popular algorithms -- gradient descent-ascent (GDA) and gradient descent-max (GDMax) in stochastic minimax optimization.
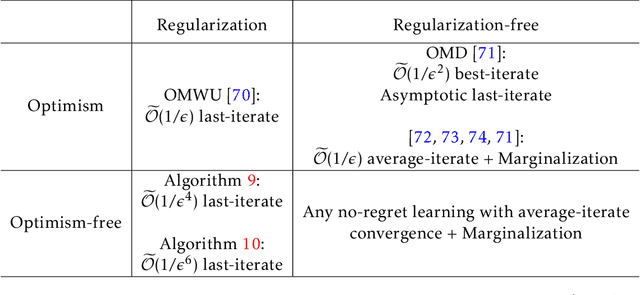
The Power of Regularization in Solving Extensive-Form Games
Jun 19, 2022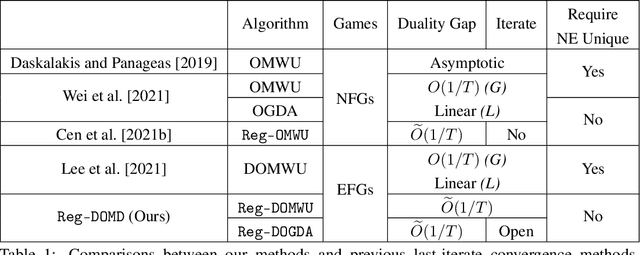
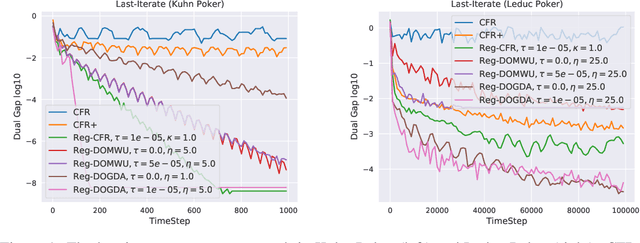
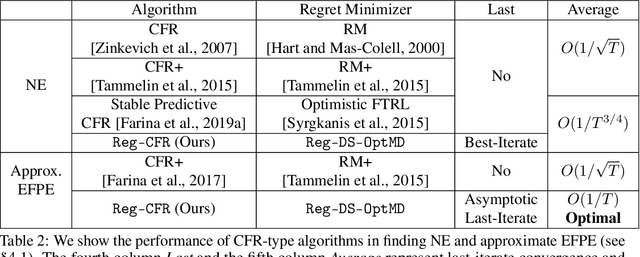
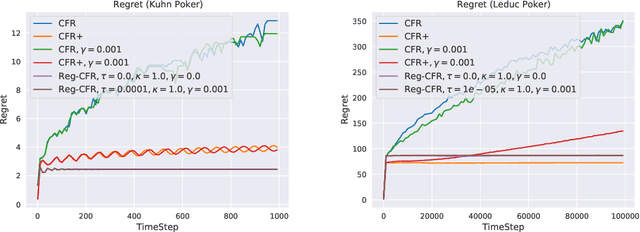
In this paper, we investigate the power of regularization, a common technique in reinforcement learning and optimization, in solving extensive-form games (EFGs). We propose a series of new algorithms based on regularizing the payoff functions of the game, and establish a set of convergence results that strictly improve over the existing ones, with either weaker assumptions or stronger convergence guarantees. In particular, we first show that dilated optimistic mirror descent (DOMD), an efficient variant of OMD for solving EFGs, with adaptive regularization can achieve a fast $\tilde O(1/T)$ last-iterate convergence in terms of duality gap without the uniqueness assumption of the Nash equilibrium (NE). Moreover, regularized dilated optimistic multiplicative weights update (Reg-DOMWU), an instance of Reg-DOMD, further enjoys the $\tilde O(1/T)$ last-iterate convergence rate of the distance to the set of NE. This addresses an open question on whether iterate convergence can be obtained for OMWU algorithms without the uniqueness assumption in both the EFG and normal-form game literature. Second, we show that regularized counterfactual regret minimization (Reg-CFR), with a variant of optimistic mirror descent algorithm as regret-minimizer, can achieve $O(1/T^{1/4})$ best-iterate, and $O(1/T^{3/4})$ average-iterate convergence rate for finding NE in EFGs. Finally, we show that Reg-CFR can achieve asymptotic last-iterate convergence, and optimal $O(1/T)$ average-iterate convergence rate, for finding the NE of perturbed EFGs, which is useful for finding approximate extensive-form perfect equilibria (EFPE). To the best of our knowledge, they constitute the first last-iterate convergence results for CFR-type algorithms, while matching the SOTA average-iterate convergence rate in finding NE for non-perturbed EFGs. We also provide numerical results to corroborate the advantages of our algorithms.