 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEric Mazumdar
Rethinking Scaling Laws for Learning in Strategic Environments
Feb 21, 2024
The deployment of ever-larger machine learning models reflects a growing consensus that the more expressive the model$\unicode{x2013}$and the more data one has access to$\unicode{x2013}$the more one can improve performance. As models get deployed in a variety of real world scenarios, they inevitably face strategic environments. In this work, we consider the natural question of how the interplay of models and strategic interactions affects scaling laws. We find that strategic interactions can break the conventional view of scaling laws$\unicode{x2013}$meaning that performance does not necessarily monotonically improve as models get larger and/ or more expressive (even with infinite data). We show the implications of this phenomenon in several contexts including strategic regression, strategic classification, and multi-agent reinforcement learning through examples of strategic environments in which$\unicode{x2013}$by simply restricting the expressivity of one's model or policy class$\unicode{x2013}$one can achieve strictly better equilibrium outcomes. Motivated by these examples, we then propose a new paradigm for model-selection in games wherein an agent seeks to choose amongst different model classes to use as their action set in a game.
Two-Timescale Q-Learning with Function Approximation in Zero-Sum Stochastic Games
Dec 08, 2023We consider two-player zero-sum stochastic games and propose a two-timescale $Q$-learning algorithm with function approximation that is payoff-based, convergent, rational, and symmetric between the two players. In two-timescale $Q$-learning, the fast-timescale iterates are updated in spirit to the stochastic gradient descent and the slow-timescale iterates (which we use to compute the policies) are updated by taking a convex combination between its previous iterate and the latest fast-timescale iterate. Introducing the slow timescale as well as its update equation marks as our main algorithmic novelty. In the special case of linear function approximation, we establish, to the best of our knowledge, the first last-iterate finite-sample bound for payoff-based independent learning dynamics of these types. The result implies a polynomial sample complexity to find a Nash equilibrium in such stochastic games. To establish the results, we model our proposed algorithm as a two-timescale stochastic approximation and derive the finite-sample bound through a Lyapunov-based approach. The key novelty lies in constructing a valid Lyapunov function to capture the evolution of the slow-timescale iterates. Specifically, through a change of variable, we show that the update equation of the slow-timescale iterates resembles the classical smoothed best-response dynamics, where the regularized Nash gap serves as a valid Lyapunov function. This insight enables us to construct a valid Lyapunov function via a generalized variant of the Moreau envelope of the regularized Nash gap. The construction of our Lyapunov function might be of broad independent interest in studying the behavior of stochastic approximation algorithms.
Coupled Gradient Flows for Strategic Non-Local Distribution Shift
Jul 07, 2023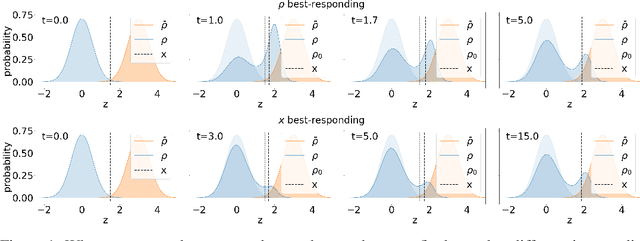

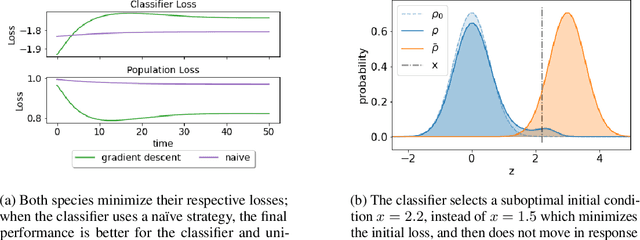
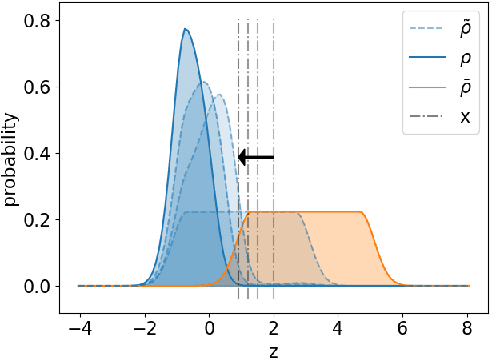
We propose a novel framework for analyzing the dynamics of distribution shift in real-world systems that captures the feedback loop between learning algorithms and the distributions on which they are deployed. Prior work largely models feedback-induced distribution shift as adversarial or via an overly simplistic distribution-shift structure. In contrast, we propose a coupled partial differential equation model that captures fine-grained changes in the distribution over time by accounting for complex dynamics that arise due to strategic responses to algorithmic decision-making, non-local endogenous population interactions, and other exogenous sources of distribution shift. We consider two common settings in machine learning: cooperative settings with information asymmetries, and competitive settings where a learner faces strategic users. For both of these settings, when the algorithm retrains via gradient descent, we prove asymptotic convergence of the retraining procedure to a steady-state, both in finite and in infinite dimensions, obtaining explicit rates in terms of the model parameters. To do so we derive new results on the convergence of coupled PDEs that extends what is known on multi-species systems. Empirically, we show that our approach captures well-documented forms of distribution shifts like polarization and disparate impacts that simpler models cannot capture.
A Finite-Sample Analysis of Payoff-Based Independent Learning in Zero-Sum Stochastic Games
Mar 03, 2023We study two-player zero-sum stochastic games, and propose a form of independent learning dynamics called Doubly Smoothed Best-Response dynamics, which integrates a discrete and doubly smoothed variant of the best-response dynamics into temporal-difference (TD)-learning and minimax value iteration. The resulting dynamics are payoff-based, convergent, rational, and symmetric among players. Our main results provide finite-sample guarantees. In particular, we prove the first-known $\tilde{\mathcal{O}}(1/\epsilon^2)$ sample complexity bound for payoff-based independent learning dynamics, up to a smoothing bias. In the special case where the stochastic game has only one state (i.e., matrix games), we provide a sharper $\tilde{\mathcal{O}}(1/\epsilon)$ sample complexity. Our analysis uses a novel coupled Lyapunov drift approach to capture the evolution of multiple sets of coupled and stochastic iterates, which might be of independent interest.
Algorithmic Collective Action in Machine Learning
Feb 08, 2023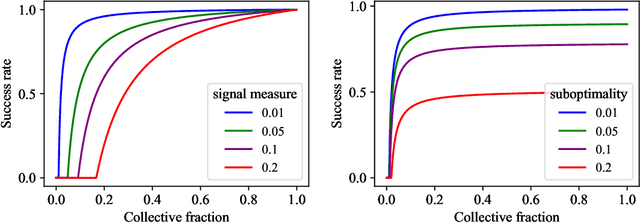
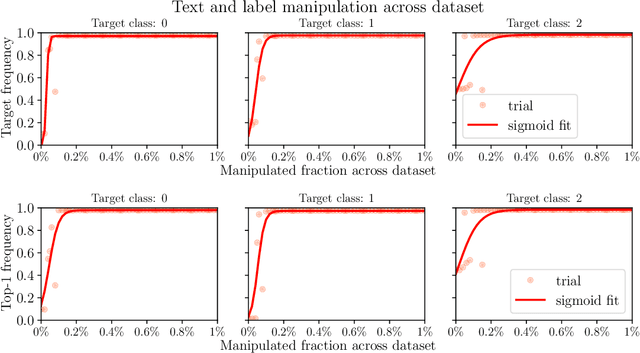
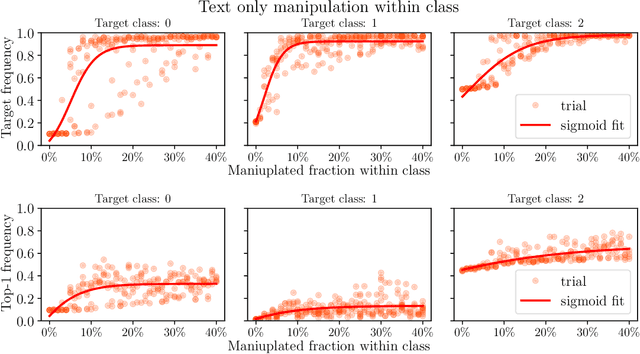
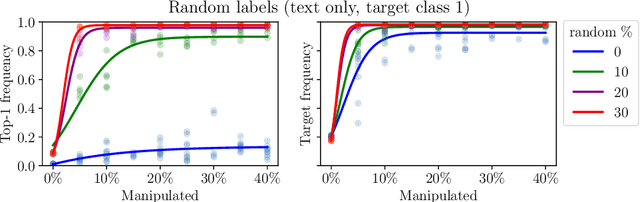
We initiate a principled study of algorithmic collective action on digital platforms that deploy machine learning algorithms. We propose a simple theoretical model of a collective interacting with a firm's learning algorithm. The collective pools the data of participating individuals and executes an algorithmic strategy by instructing participants how to modify their own data to achieve a collective goal. We investigate the consequences of this model in three fundamental learning-theoretic settings: the case of a nonparametric optimal learning algorithm, a parametric risk minimizer, and gradient-based optimization. In each setting, we come up with coordinated algorithmic strategies and characterize natural success criteria as a function of the collective's size. Complementing our theory, we conduct systematic experiments on a skill classification task involving tens of thousands of resumes from a gig platform for freelancers. Through more than two thousand model training runs of a BERT-like language model, we see a striking correspondence emerge between our empirical observations and the predictions made by our theory. Taken together, our theory and experiments broadly support the conclusion that algorithmic collectives of exceedingly small fractional size can exert significant control over a platform's learning algorithm.
Convergent First-Order Methods for Bi-level Optimization and Stackelberg Games
Feb 02, 2023We propose an algorithm to solve a class of bi-level optimization problems using only first-order information. In particular, we focus on a class where the inner minimization has unique solutions. Unlike contemporary algorithms, our algorithm does not require the use of an oracle estimator for the gradient of the bi-level objective or an approximate solver for the inner problem. Instead, we alternate between descending on the inner problem using na\"ive optimization methods and descending on the upper-level objective function using specially constructed gradient estimators. We provide non-asymptotic convergence rates to stationary points of the bi-level objective in the absence of convexity of the closed-loop function and further show asymptotic convergence to only local minima of the bi-level problem. The approach is inspired by ideas from the literature on two-timescale stochastic approximation algorithms.
A Note on Zeroth-Order Optimization on the Simplex
Aug 02, 2022We construct a zeroth-order gradient estimator for a smooth function defined on the probability simplex. The proposed estimator queries the simplex only. We prove that projected gradient descent and the exponential weights algorithm, when run with this estimator instead of exact gradients, converge at a $\mathcal O(T^{-1/4})$ rate.
Langevin Monte Carlo for Contextual Bandits
Jun 22, 2022
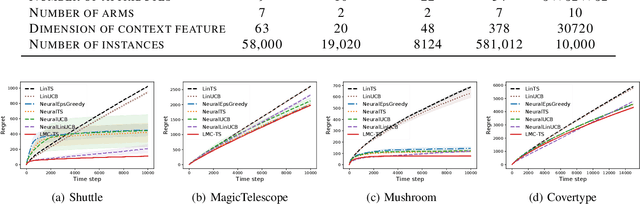

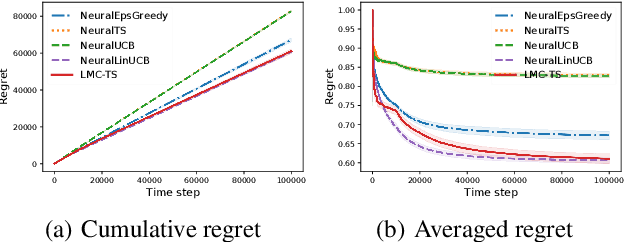
We study the efficiency of Thompson sampling for contextual bandits. Existing Thompson sampling-based algorithms need to construct a Laplace approximation (i.e., a Gaussian distribution) of the posterior distribution, which is inefficient to sample in high dimensional applications for general covariance matrices. Moreover, the Gaussian approximation may not be a good surrogate for the posterior distribution for general reward generating functions. We propose an efficient posterior sampling algorithm, viz., Langevin Monte Carlo Thompson Sampling (LMC-TS), that uses Markov Chain Monte Carlo (MCMC) methods to directly sample from the posterior distribution in contextual bandits. Our method is computationally efficient since it only needs to perform noisy gradient descent updates without constructing the Laplace approximation of the posterior distribution. We prove that the proposed algorithm achieves the same sublinear regret bound as the best Thompson sampling algorithms for a special case of contextual bandits, viz., linear contextual bandits. We conduct experiments on both synthetic data and real-world datasets on different contextual bandit models, which demonstrates that directly sampling from the posterior is both computationally efficient and competitive in performance.
Decentralized, Communication- and Coordination-free Learning in Structured Matching Markets
Jun 06, 2022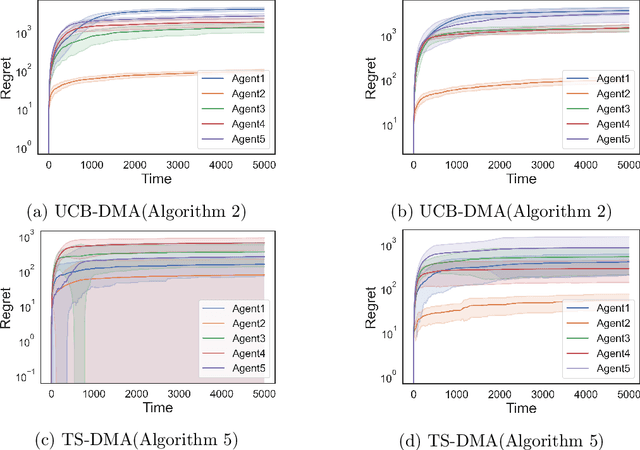

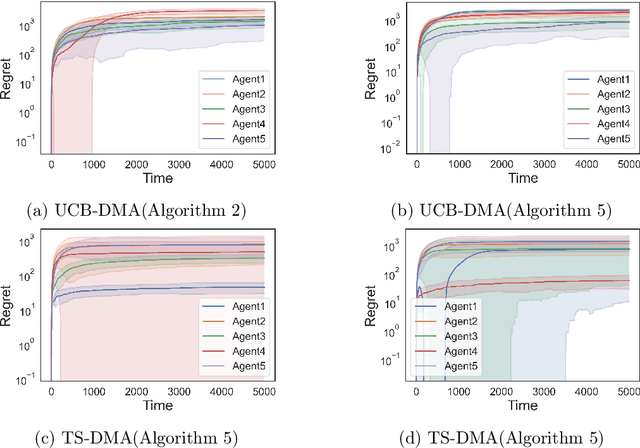
We study the problem of online learning in competitive settings in the context of two-sided matching markets. In particular, one side of the market, the agents, must learn about their preferences over the other side, the firms, through repeated interaction while competing with other agents for successful matches. We propose a class of decentralized, communication- and coordination-free algorithms that agents can use to reach to their stable match in structured matching markets. In contrast to prior works, the proposed algorithms make decisions based solely on an agent's own history of play and requires no foreknowledge of the firms' preferences. Our algorithms are constructed by splitting up the statistical problem of learning one's preferences, from noisy observations, from the problem of competing for firms. We show that under realistic structural assumptions on the underlying preferences of the agents and firms, the proposed algorithms incur a regret which grows at most logarithmically in the time horizon. Our results show that, in the case of matching markets, competition need not drastically affect the performance of decentralized, communication and coordination free online learning algorithms.
Who Leads and Who Follows in Strategic Classification?
Jun 23, 2021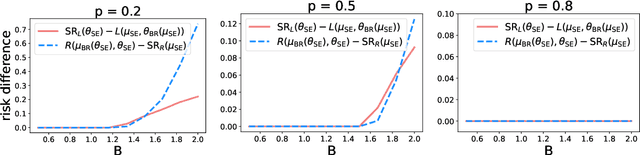
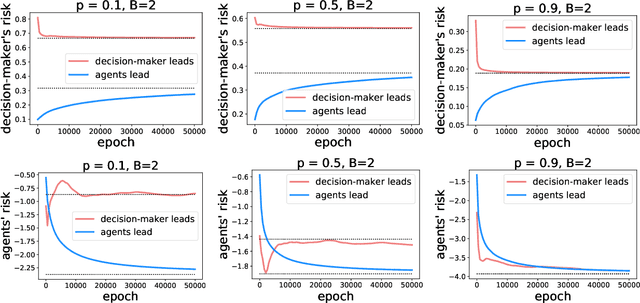
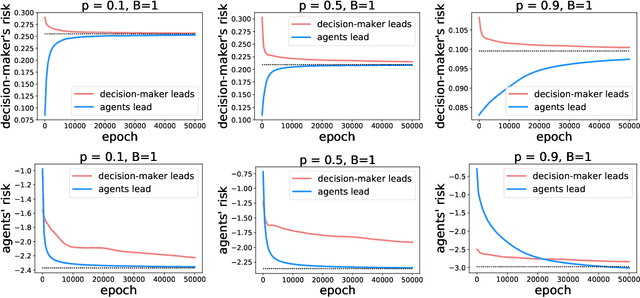
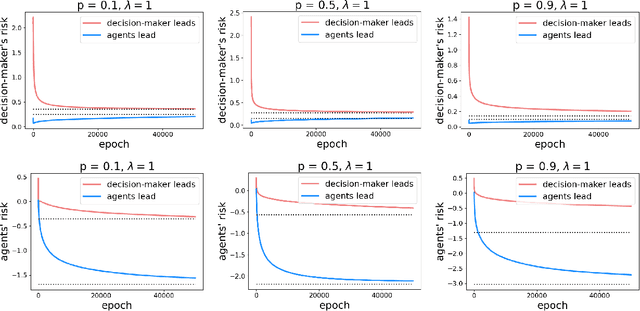
As predictive models are deployed into the real world, they must increasingly contend with strategic behavior. A growing body of work on strategic classification treats this problem as a Stackelberg game: the decision-maker "leads" in the game by deploying a model, and the strategic agents "follow" by playing their best response to the deployed model. Importantly, in this framing, the burden of learning is placed solely on the decision-maker, while the agents' best responses are implicitly treated as instantaneous. In this work, we argue that the order of play in strategic classification is fundamentally determined by the relative frequencies at which the decision-maker and the agents adapt to each other's actions. In particular, by generalizing the standard model to allow both players to learn over time, we show that a decision-maker that makes updates faster than the agents can reverse the order of play, meaning that the agents lead and the decision-maker follows. We observe in standard learning settings that such a role reversal can be desirable for both the decision-maker and the strategic agents. Finally, we show that a decision-maker with the freedom to choose their update frequency can induce learning dynamics that converge to Stackelberg equilibria with either order of play.