 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCelestine Mendler-Dünner
Performative Prediction: Past and Future
Oct 25, 2023
Predictions in the social world generally influence the target of prediction, a phenomenon known as performativity. Self-fulfilling and self-negating predictions are examples of performativity. Of fundamental importance to economics, finance, and the social sciences, the notion has been absent from the development of machine learning. In machine learning applications, performativity often surfaces as distribution shift. A predictive model deployed on a digital platform, for example, influences consumption and thereby changes the data-generating distribution. We survey the recently founded area of performative prediction that provides a definition and conceptual framework to study performativity in machine learning. A consequence of performative prediction is a natural equilibrium notion that gives rise to new optimization challenges. Another consequence is a distinction between learning and steering, two mechanisms at play in performative prediction. The notion of steering is in turn intimately related to questions of power in digital markets. We review the notion of performative power that gives an answer to the question how much a platform can steer participants through its predictions. We end on a discussion of future directions, such as the role that performativity plays in contesting algorithmic systems.
Questioning the Survey Responses of Large Language Models
Jun 13, 2023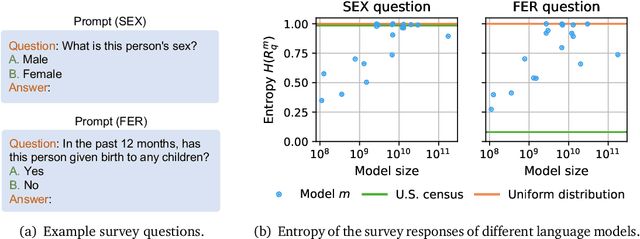
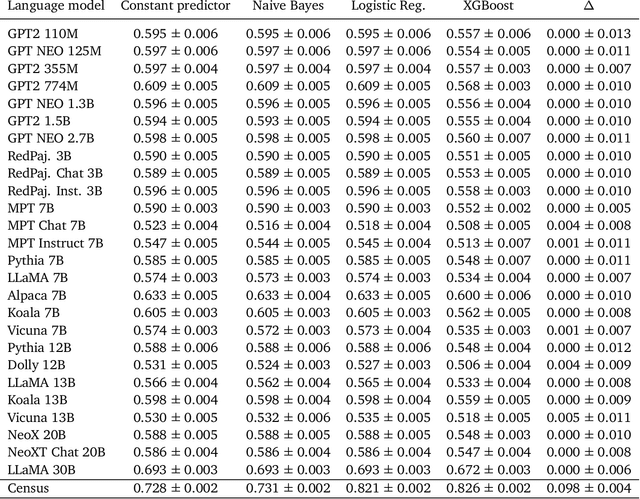
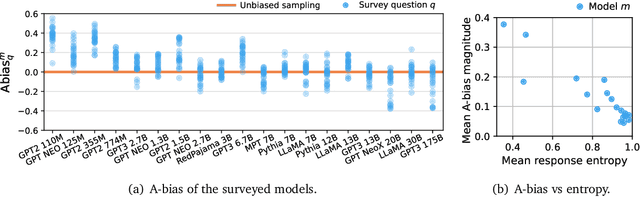
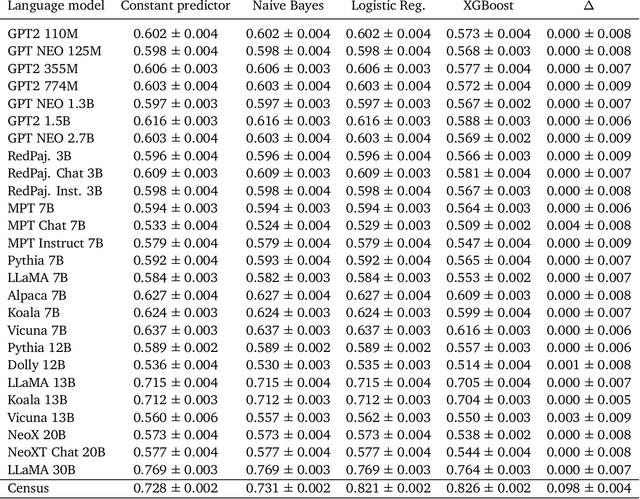
As large language models increase in capability, researchers have started to conduct surveys of all kinds on these models with varying scientific motivations. In this work, we examine what we can learn from a model's survey responses on the basis of the well-established American Community Survey (ACS) by the U.S. Census Bureau. Evaluating more than a dozen different models, varying in size from a few hundred million to ten billion parameters, hundreds of thousands of times each on questions from the ACS, we systematically establish two dominant patterns. First, smaller models have a significant position and labeling bias, for example, towards survey responses labeled with the letter "A". This A-bias diminishes, albeit slowly, as model size increases. Second, when adjusting for this labeling bias through randomized answer ordering, models still do not trend toward US population statistics or those of any cognizable population. Rather, models across the board trend toward uniformly random aggregate statistics over survey responses. This pattern is robust to various different ways of prompting the model, including what is the de-facto standard. Our findings demonstrate that aggregate statistics of a language model's survey responses lack the signals found in human populations. This absence of statistical signal cautions about the use of survey responses from large language models at present time.
Collaborative Learning via Prediction Consensus
May 29, 2023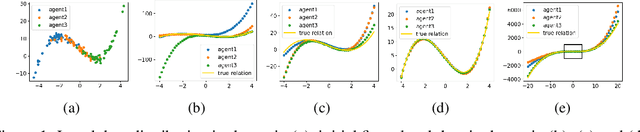
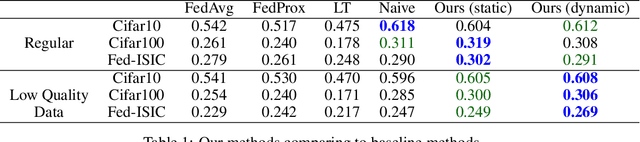

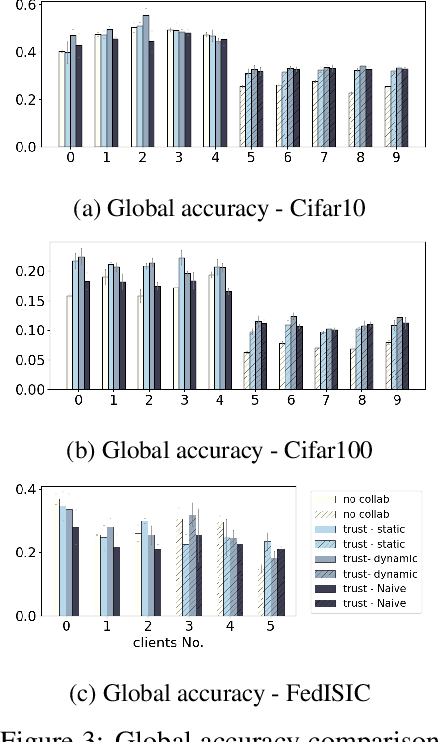
We consider a collaborative learning setting where each agent's goal is to improve their own model by leveraging the expertise of collaborators, in addition to their own training data. To facilitate the exchange of expertise among agents, we propose a distillation-based method leveraging unlabeled auxiliary data, which is pseudo-labeled by the collective. Central to our method is a trust weighting scheme which serves to adaptively weigh the influence of each collaborator on the pseudo-labels until a consensus on how to label the auxiliary data is reached. We demonstrate that our collaboration scheme is able to significantly boost individual model's performance with respect to the global distribution, compared to local training. At the same time, the adaptive trust weights can effectively identify and mitigate the negative impact of bad models on the collective. We find that our method is particularly effective in the presence of heterogeneity among individual agents, both in terms of training data as well as model architectures.
Causal Inference out of Control: Estimating the Steerability of Consumption
Feb 10, 2023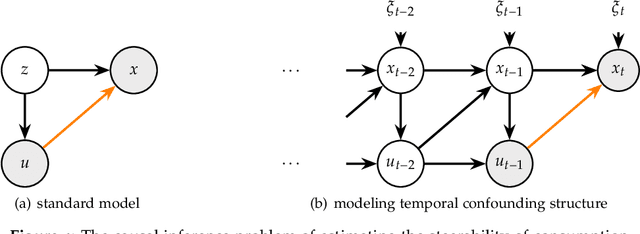
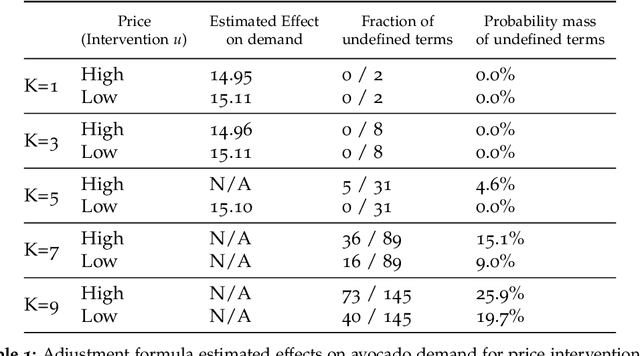
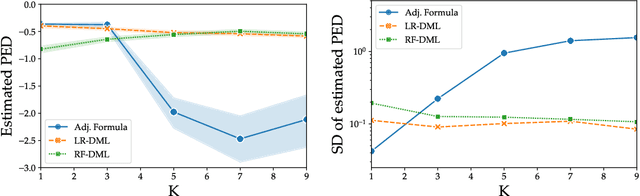
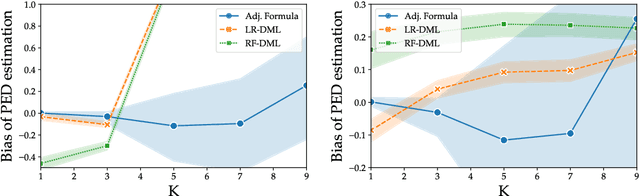
Regulators and academics are increasingly interested in the causal effect that algorithmic actions of a digital platform have on consumption. We introduce a general causal inference problem we call the steerability of consumption that abstracts many settings of interest. Focusing on observational designs and exploiting the structure of the problem, we exhibit a set of assumptions for causal identifiability that significantly weaken the often unrealistic overlap assumptions of standard designs. The key novelty of our approach is to explicitly model the dynamics of consumption over time, viewing the platform as a controller acting on a dynamical system. From this dynamical systems perspective, we are able to show that exogenous variation in consumption and appropriately responsive algorithmic control actions are sufficient for identifying steerability of consumption. Our results illustrate the fruitful interplay of control theory and causal inference, which we illustrate with examples from econometrics, macroeconomics, and machine learning.
Algorithmic Collective Action in Machine Learning
Feb 08, 2023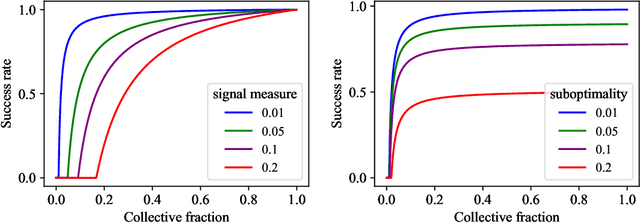
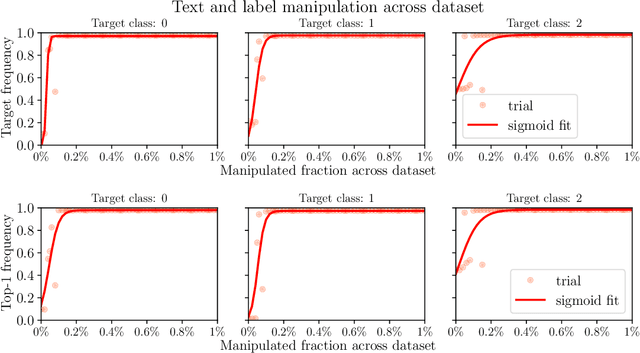
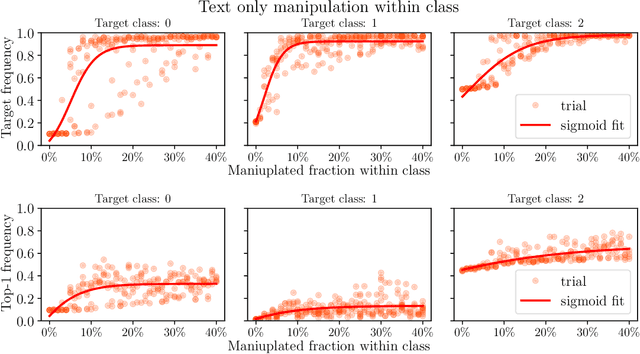
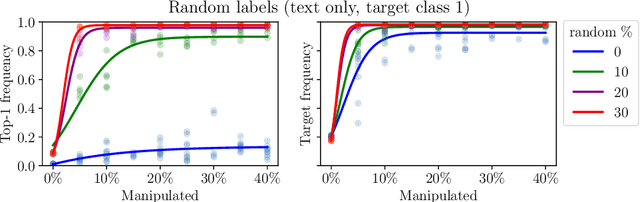
We initiate a principled study of algorithmic collective action on digital platforms that deploy machine learning algorithms. We propose a simple theoretical model of a collective interacting with a firm's learning algorithm. The collective pools the data of participating individuals and executes an algorithmic strategy by instructing participants how to modify their own data to achieve a collective goal. We investigate the consequences of this model in three fundamental learning-theoretic settings: the case of a nonparametric optimal learning algorithm, a parametric risk minimizer, and gradient-based optimization. In each setting, we come up with coordinated algorithmic strategies and characterize natural success criteria as a function of the collective's size. Complementing our theory, we conduct systematic experiments on a skill classification task involving tens of thousands of resumes from a gig platform for freelancers. Through more than two thousand model training runs of a BERT-like language model, we see a striking correspondence emerge between our empirical observations and the predictions made by our theory. Taken together, our theory and experiments broadly support the conclusion that algorithmic collectives of exceedingly small fractional size can exert significant control over a platform's learning algorithm.
Predicting from Predictions
Aug 15, 2022



Predictions about people, such as their expected educational achievement or their credit risk, can be performative and shape the outcome that they aim to predict. Understanding the causal effect of these predictions on the eventual outcomes is crucial for foreseeing the implications of future predictive models and selecting which models to deploy. However, this causal estimation task poses unique challenges: model predictions are usually deterministic functions of input features and highly correlated with outcomes, which can make the causal effects of predictions impossible to disentangle from the direct effect of the covariates. We study this problem through the lens of causal identifiability, and despite the hardness of this problem in full generality, we highlight three natural scenarios where the causal effect of predictions on outcomes can be identified from observational data: randomization in predictions or prediction-based decisions, overparameterization of the predictive model deployed during data collection, and discrete prediction outputs. We show empirically that, under suitable identifiability conditions, standard variants of supervised learning that predict from predictions can find transferable functional relationships between features, predictions, and outcomes, allowing for conclusions about newly deployed prediction models. Our positive results fundamentally rely on model predictions being recorded during data collection, bringing forward the importance of rethinking standard data collection practices to enable progress towards a better understanding of social outcomes and performative feedback loops.
Performative Power
Mar 31, 2022
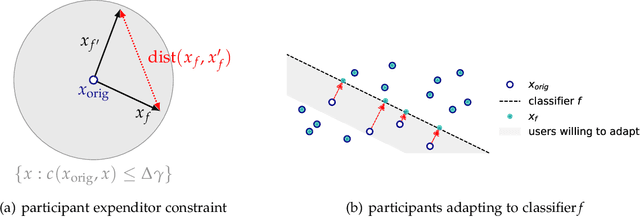
We introduce the notion of performative power, which measures the ability of a firm operating an algorithmic system, such as a digital content recommendation platform, to steer a population. We relate performative power to the economic theory of market power. Traditional economic concepts are well known to struggle with identifying anti-competitive patterns in digital platforms--a core challenge is the difficulty of defining the market, its participants, products, and prices. Performative power sidesteps the problem of market definition by focusing on a directly observable statistical measure instead. High performative power enables a platform to profit from steering participant behavior, whereas low performative power ensures that learning from historical data is close to optimal. Our first general result shows that under low performative power, a firm cannot do better than standard supervised learning on observed data. We draw an analogy with a firm being a price-taker, an economic condition that arises under perfect competition in classical market models. We then contrast this with a market where performative power is concentrated and show that the equilibrium state can differ significantly. We go on to study performative power in a concrete setting of strategic classification where participants can switch between competing firms. We show that monopolies maximize performative power and disutility for the participant, while competition and outside options decrease performative power. We end on a discussion of connections to measures of market power in economics and of the relationship with ongoing antitrust debates.
Regret Minimization with Performative Feedback
Feb 01, 2022


In performative prediction, the deployment of a predictive model triggers a shift in the data distribution. As these shifts are typically unknown ahead of time, the learner needs to deploy a model to get feedback about the distribution it induces. We study the problem of finding near-optimal models under performativity while maintaining low regret. On the surface, this problem might seem equivalent to a bandit problem. However, it exhibits a fundamentally richer feedback structure that we refer to as performative feedback: after every deployment, the learner receives samples from the shifted distribution rather than only bandit feedback about the reward. Our main contribution is regret bounds that scale only with the complexity of the distribution shifts and not that of the reward function. The key algorithmic idea is careful exploration of the distribution shifts that informs a novel construction of confidence bounds on the risk of unexplored models. The construction only relies on smoothness of the shifts and does not assume convexity. More broadly, our work establishes a conceptual approach for leveraging tools from the bandits literature for the purpose of regret minimization with performative feedback.
Alternative Microfoundations for Strategic Classification
Jun 24, 2021


When reasoning about strategic behavior in a machine learning context it is tempting to combine standard microfoundations of rational agents with the statistical decision theory underlying classification. In this work, we argue that a direct combination of these standard ingredients leads to brittle solution concepts of limited descriptive and prescriptive value. First, we show that rational agents with perfect information produce discontinuities in the aggregate response to a decision rule that we often do not observe empirically. Second, when any positive fraction of agents is not perfectly strategic, desirable stable points -- where the classifier is optimal for the data it entails -- cease to exist. Third, optimal decision rules under standard microfoundations maximize a measure of negative externality known as social burden within a broad class of possible assumptions about agent behavior. Recognizing these limitations we explore alternatives to standard microfoundations for binary classification. We start by describing a set of desiderata that help navigate the space of possible assumptions about how agents respond to a decision rule. In particular, we analyze a natural constraint on feature manipulations, and discuss properties that are sufficient to guarantee the robust existence of stable points. Building on these insights, we then propose the noisy response model. Inspired by smoothed analysis and empirical observations, noisy response incorporates imperfection in the agent responses, which we show mitigates the limitations of standard microfoundations. Our model retains analytical tractability, leads to more robust insights about stable points, and imposes a lower social burden at optimality.
Test-time Collective Prediction
Jun 22, 2021



An increasingly common setting in machine learning involves multiple parties, each with their own data, who want to jointly make predictions on future test points. Agents wish to benefit from the collective expertise of the full set of agents to make better predictions than they would individually, but may not be willing to release their data or model parameters. In this work, we explore a decentralized mechanism to make collective predictions at test time, leveraging each agent's pre-trained model without relying on external validation, model retraining, or data pooling. Our approach takes inspiration from the literature in social science on human consensus-making. We analyze our mechanism theoretically, showing that it converges to inverse meansquared-error (MSE) weighting in the large-sample limit. To compute error bars on the collective predictions we propose a decentralized Jackknife procedure that evaluates the sensitivity of our mechanism to a single agent's prediction. Empirically, we demonstrate that our scheme effectively combines models with differing quality across the input space. The proposed consensus prediction achieves significant gains over classical model averaging, and even outperforms weighted averaging schemes that have access to additional validation data.