 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiawei Zhang
Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs
Apr 10, 2024
Large language models (LLMs), while exhibiting exceptional performance, suffer from hallucinations, especially on knowledge-intensive tasks. Existing works propose to augment LLMs with individual text units retrieved from external knowledge corpora to alleviate the issue. However, in many domains, texts are interconnected (e.g., academic papers in a bibliographic graph are linked by citations and co-authorships) which form a (text-attributed) graph. The knowledge in such graphs is encoded not only in single texts/nodes but also in their associated connections. To facilitate the research of augmenting LLMs with graphs, we manually construct a Graph Reasoning Benchmark dataset called GRBench, containing 1,740 questions that can be answered with the knowledge from 10 domain graphs. Then, we propose a simple and effective framework called Graph Chain-of-thought (Graph-CoT) to augment LLMs with graphs by encouraging LLMs to reason on the graph iteratively. Each Graph-CoT iteration consists of three sub-steps: LLM reasoning, LLM-graph interaction, and graph execution. We conduct systematic experiments with three LLM backbones on GRBench, where Graph-CoT outperforms the baselines consistently. The code is available at https://github.com/PeterGriffinJin/Graph-CoT.
KnowHalu: Hallucination Detection via Multi-Form Knowledge Based Factual Checking
Apr 03, 2024This paper introduces KnowHalu, a novel approach for detecting hallucinations in text generated by large language models (LLMs), utilizing step-wise reasoning, multi-formulation query, multi-form knowledge for factual checking, and fusion-based detection mechanism. As LLMs are increasingly applied across various domains, ensuring that their outputs are not hallucinated is critical. Recognizing the limitations of existing approaches that either rely on the self-consistency check of LLMs or perform post-hoc fact-checking without considering the complexity of queries or the form of knowledge, KnowHalu proposes a two-phase process for hallucination detection. In the first phase, it identifies non-fabrication hallucinations--responses that, while factually correct, are irrelevant or non-specific to the query. The second phase, multi-form based factual checking, contains five key steps: reasoning and query decomposition, knowledge retrieval, knowledge optimization, judgment generation, and judgment aggregation. Our extensive evaluations demonstrate that KnowHalu significantly outperforms SOTA baselines in detecting hallucinations across diverse tasks, e.g., improving by 15.65% in QA tasks and 5.50% in summarization tasks, highlighting its effectiveness and versatility in detecting hallucinations in LLM-generated content.
GPTA: Generative Prompt Tuning Assistant for Synergistic Downstream Neural Network Enhancement with LLMs
Mar 29, 2024This study introduces GPTA, a Large Language Model assistance training framework, that enhances the training of downstream task models via prefix prompt. By minimizing data exposure to LLM, the framework addresses the security and legal challenges of applying LLM in downstream task model training. GPTA utilizes a new synergistic training approach, optimizing the downstream models with parameter gradients and LLMs with the novel ``dialogue gradient''. The framework not only demonstrates significant improvements in model performance across six NLP benchmark datasets, but also reduces overfitting in low-resource scenarios effectively. The detailed analyses further validate that our pioneer framework provides a cost-efficient and adaptive method for downstream task model training with LLM support.
VersaT2I: Improving Text-to-Image Models with Versatile Reward
Mar 27, 2024Recent text-to-image (T2I) models have benefited from large-scale and high-quality data, demonstrating impressive performance. However, these T2I models still struggle to produce images that are aesthetically pleasing, geometrically accurate, faithful to text, and of good low-level quality. We present VersaT2I, a versatile training framework that can boost the performance with multiple rewards of any T2I model. We decompose the quality of the image into several aspects such as aesthetics, text-image alignment, geometry, low-level quality, etc. Then, for every quality aspect, we select high-quality images in this aspect generated by the model as the training set to finetune the T2I model using the Low-Rank Adaptation (LoRA). Furthermore, we introduce a gating function to combine multiple quality aspects, which can avoid conflicts between different quality aspects. Our method is easy to extend and does not require any manual annotation, reinforcement learning, or model architecture changes. Extensive experiments demonstrate that VersaT2I outperforms the baseline methods across various quality criteria.
EffiPerception: an Efficient Framework for Various Perception Tasks
Mar 18, 2024
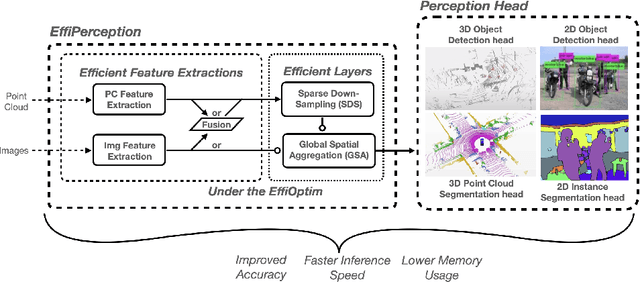
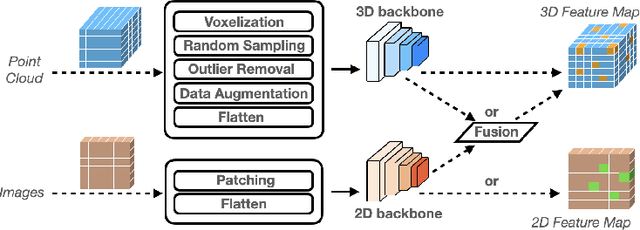
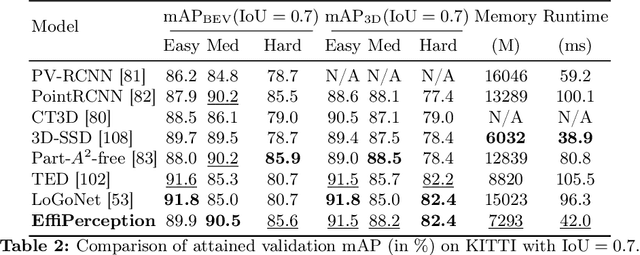
The accuracy-speed-memory trade-off is always the priority to consider for several computer vision perception tasks. Previous methods mainly focus on a single or small couple of these tasks, such as creating effective data augmentation, feature extractor, learning strategies, etc. These approaches, however, could be inherently task-specific: their proposed model's performance may depend on a specific perception task or a dataset. Targeting to explore common learning patterns and increasing the module robustness, we propose the EffiPerception framework. It could achieve great accuracy-speed performance with relatively low memory cost under several perception tasks: 2D Object Detection, 3D Object Detection, 2D Instance Segmentation, and 3D Point Cloud Segmentation. Overall, the framework consists of three parts: (1) Efficient Feature Extractors, which extract the input features for each modality. (2) Efficient Layers, plug-in plug-out layers that further process the feature representation, aggregating core learned information while pruning noisy proposals. (3) The EffiOptim, an 8-bit optimizer to further cut down the computational cost and facilitate performance stability. Extensive experiments on the KITTI, semantic-KITTI, and COCO datasets revealed that EffiPerception could show great accuracy-speed-memory overall performance increase within the four detection and segmentation tasks, in comparison to earlier, well-respected methods.
Regulating Chatbot Output via Inter-Informational Competition
Mar 17, 2024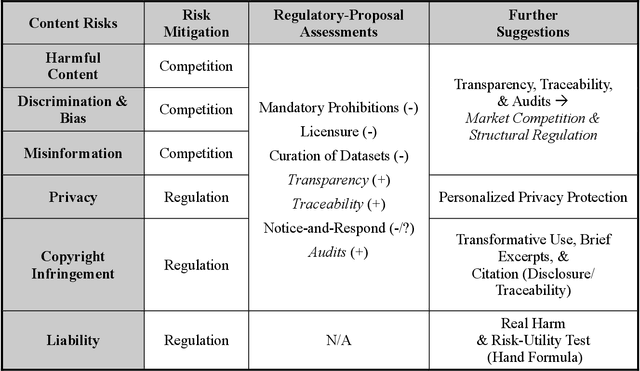
The advent of ChatGPT has sparked over a year of regulatory frenzy. However, few existing studies have rigorously questioned the assumption that, if left unregulated, AI chatbot's output would inflict tangible, severe real harm on human affairs. Most researchers have overlooked the critical possibility that the information market itself can effectively mitigate these risks and, as a result, they tend to use regulatory tools to address the issue directly. This Article develops a yardstick for reevaluating both AI-related content risks and corresponding regulatory proposals by focusing on inter-informational competition among various outlets. The decades-long history of regulating information and communications technologies indicates that regulators tend to err too much on the side of caution and to put forward excessive regulatory measures when encountering the uncertainties brought about by new technologies. In fact, a trove of empirical evidence has demonstrated that market competition among information outlets can effectively mitigate most risks and that overreliance on regulation is not only unnecessary but detrimental, as well. This Article argues that sufficient competition among chatbots and other information outlets in the information marketplace can sufficiently mitigate and even resolve most content risks posed by generative AI technologies. This renders certain loudly advocated regulatory strategies, like mandatory prohibitions, licensure, curation of datasets, and notice-and-response regimes, truly unnecessary and even toxic to desirable competition and innovation throughout the AI industry. Ultimately, the ideas that I advance in this Article should pour some much-needed cold water on the regulatory frenzy over generative AI and steer the issue back to a rational track.
MuseGraph: Graph-oriented Instruction Tuning of Large Language Models for Generic Graph Mining
Mar 13, 2024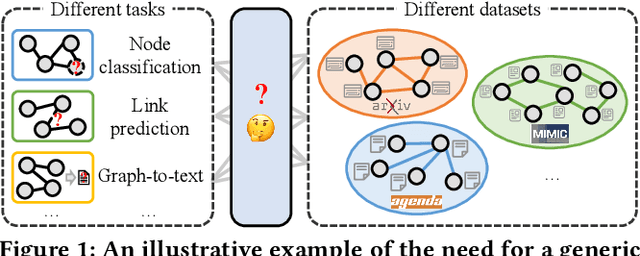
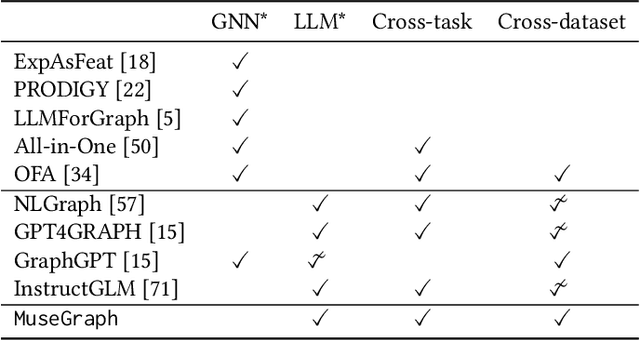
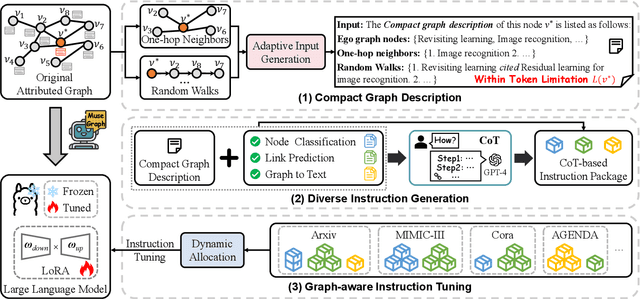
Graphs with abundant attributes are essential in modeling interconnected entities and improving predictions in various real-world applications. Traditional Graph Neural Networks (GNNs), which are commonly used for modeling attributed graphs, need to be re-trained every time when applied to different graph tasks and datasets. Although the emergence of Large Language Models (LLMs) has introduced a new paradigm in natural language processing, the generative potential of LLMs in graph mining remains largely under-explored. To this end, we propose a novel framework MuseGraph, which seamlessly integrates the strengths of GNNs and LLMs and facilitates a more effective and generic approach for graph mining across different tasks and datasets. Specifically, we first introduce a compact graph description via the proposed adaptive input generation to encapsulate key information from the graph under the constraints of language token limitations. Then, we propose a diverse instruction generation mechanism, which distills the reasoning capabilities from LLMs (e.g., GPT-4) to create task-specific Chain-of-Thought-based instruction packages for different graph tasks. Finally, we propose a graph-aware instruction tuning with a dynamic instruction package allocation strategy across tasks and datasets, ensuring the effectiveness and generalization of the training process. Our experimental results demonstrate significant improvements in different graph tasks, showcasing the potential of our MuseGraph in enhancing the accuracy of graph-oriented downstream tasks while keeping the generation powers of LLMs.
DNGaussian: Optimizing Sparse-View 3D Gaussian Radiance Fields with Global-Local Depth Normalization
Mar 13, 2024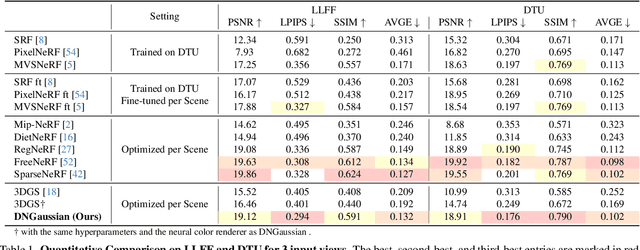
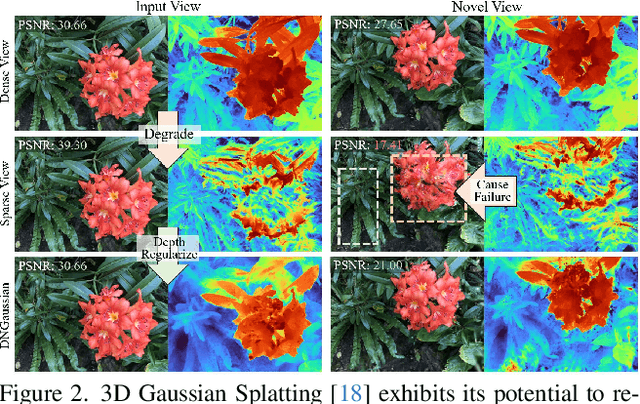
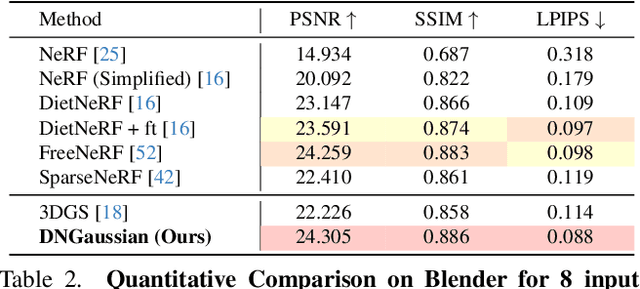
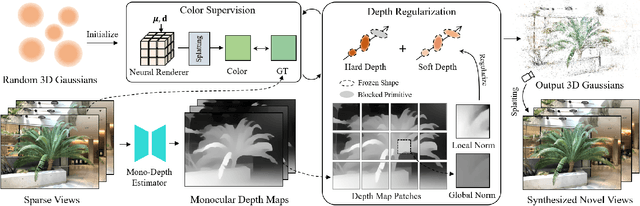
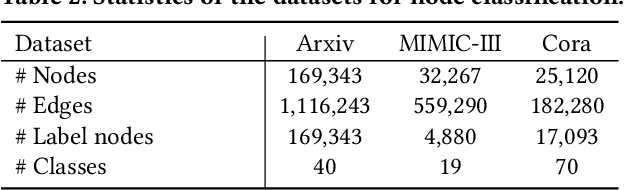
Radiance fields have demonstrated impressive performance in synthesizing novel views from sparse input views, yet prevailing methods suffer from high training costs and slow inference speed. This paper introduces DNGaussian, a depth-regularized framework based on 3D Gaussian radiance fields, offering real-time and high-quality few-shot novel view synthesis at low costs. Our motivation stems from the highly efficient representation and surprising quality of the recent 3D Gaussian Splatting, despite it will encounter a geometry degradation when input views decrease. In the Gaussian radiance fields, we find this degradation in scene geometry primarily lined to the positioning of Gaussian primitives and can be mitigated by depth constraint. Consequently, we propose a Hard and Soft Depth Regularization to restore accurate scene geometry under coarse monocular depth supervision while maintaining a fine-grained color appearance. To further refine detailed geometry reshaping, we introduce Global-Local Depth Normalization, enhancing the focus on small local depth changes. Extensive experiments on LLFF, DTU, and Blender datasets demonstrate that DNGaussian outperforms state-of-the-art methods, achieving comparable or better results with significantly reduced memory cost, a $25 \times$ reduction in training time, and over $3000 \times$ faster rendering speed.
Robust Synthetic-to-Real Transfer for Stereo Matching
Mar 12, 2024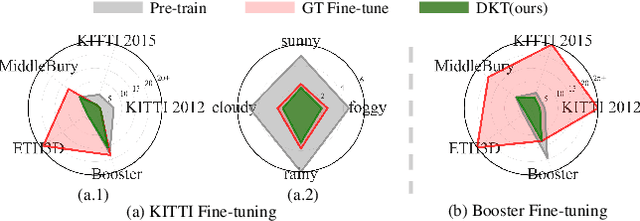
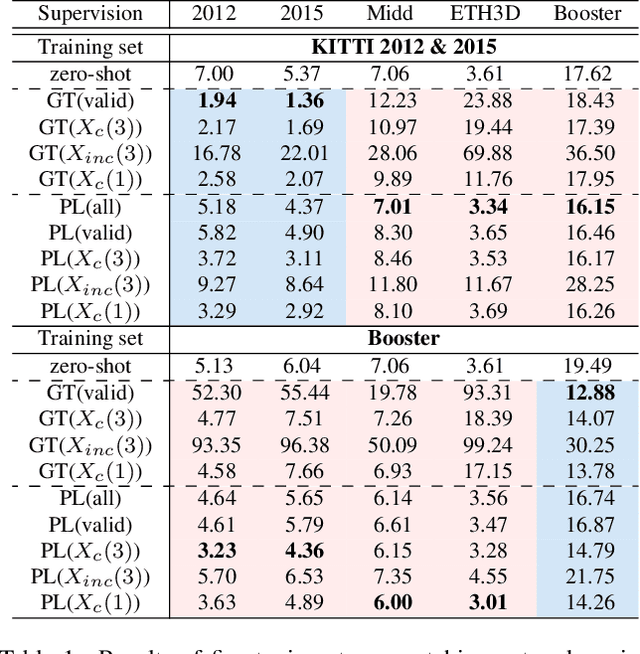
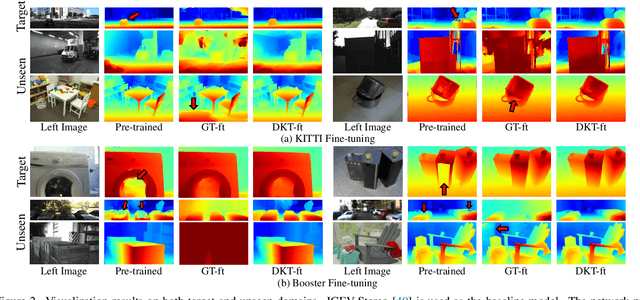
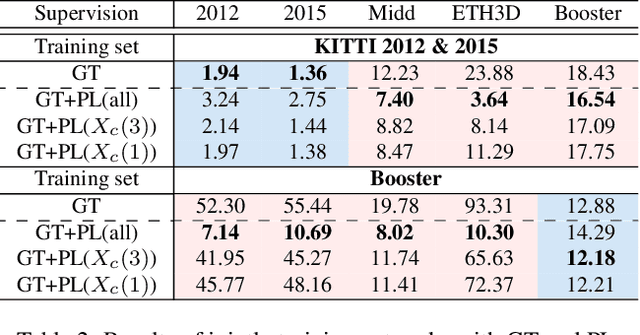
With advancements in domain generalized stereo matching networks, models pre-trained on synthetic data demonstrate strong robustness to unseen domains. However, few studies have investigated the robustness after fine-tuning them in real-world scenarios, during which the domain generalization ability can be seriously degraded. In this paper, we explore fine-tuning stereo matching networks without compromising their robustness to unseen domains. Our motivation stems from comparing Ground Truth (GT) versus Pseudo Label (PL) for fine-tuning: GT degrades, but PL preserves the domain generalization ability. Empirically, we find the difference between GT and PL implies valuable information that can regularize networks during fine-tuning. We also propose a framework to utilize this difference for fine-tuning, consisting of a frozen Teacher, an exponential moving average (EMA) Teacher, and a Student network. The core idea is to utilize the EMA Teacher to measure what the Student has learned and dynamically improve GT and PL for fine-tuning. We integrate our framework with state-of-the-art networks and evaluate its effectiveness on several real-world datasets. Extensive experiments show that our method effectively preserves the domain generalization ability during fine-tuning.