 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaohan Yu
Robust Synthetic-to-Real Transfer for Stereo Matching
Mar 12, 2024
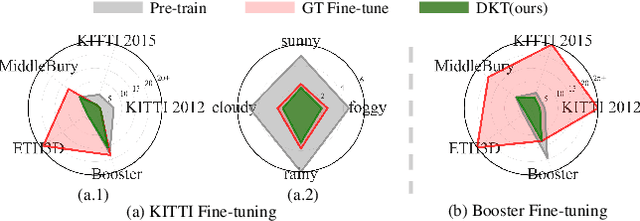
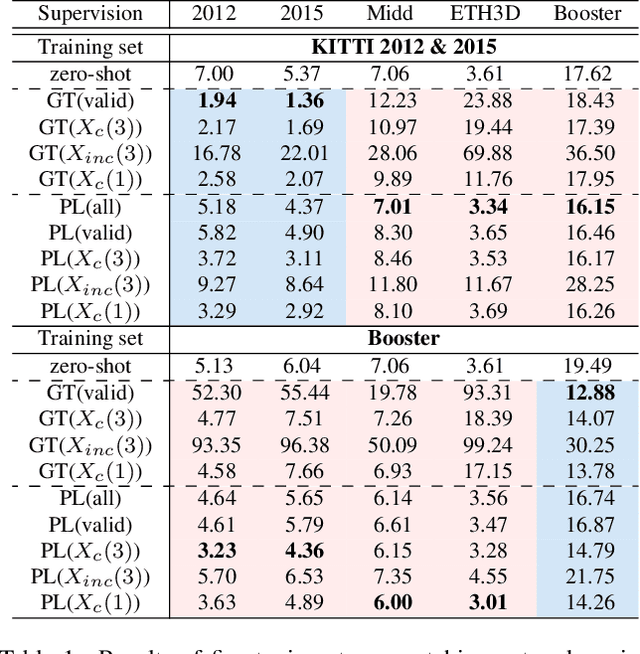
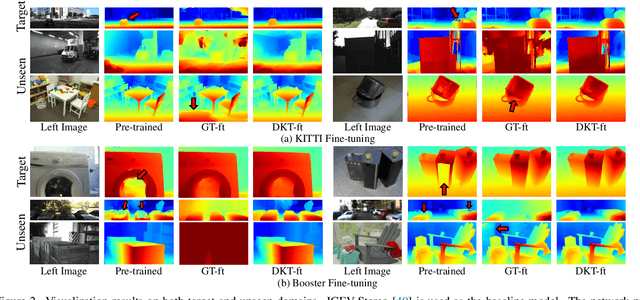
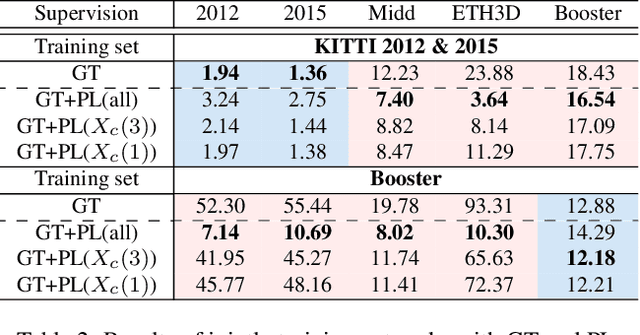
With advancements in domain generalized stereo matching networks, models pre-trained on synthetic data demonstrate strong robustness to unseen domains. However, few studies have investigated the robustness after fine-tuning them in real-world scenarios, during which the domain generalization ability can be seriously degraded. In this paper, we explore fine-tuning stereo matching networks without compromising their robustness to unseen domains. Our motivation stems from comparing Ground Truth (GT) versus Pseudo Label (PL) for fine-tuning: GT degrades, but PL preserves the domain generalization ability. Empirically, we find the difference between GT and PL implies valuable information that can regularize networks during fine-tuning. We also propose a framework to utilize this difference for fine-tuning, consisting of a frozen Teacher, an exponential moving average (EMA) Teacher, and a Student network. The core idea is to utilize the EMA Teacher to measure what the Student has learned and dynamically improve GT and PL for fine-tuning. We integrate our framework with state-of-the-art networks and evaluate its effectiveness on several real-world datasets. Extensive experiments show that our method effectively preserves the domain generalization ability during fine-tuning.
Multi-Tower Multi-Interest Recommendation with User Representation Repel
Mar 08, 2024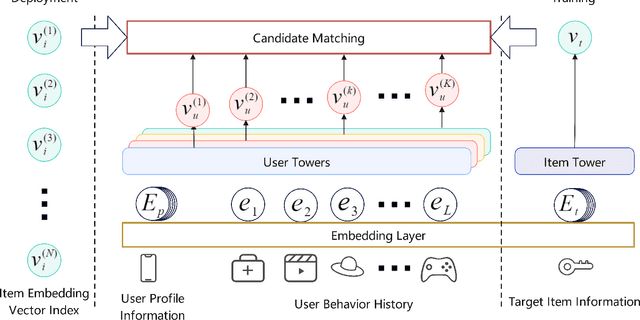
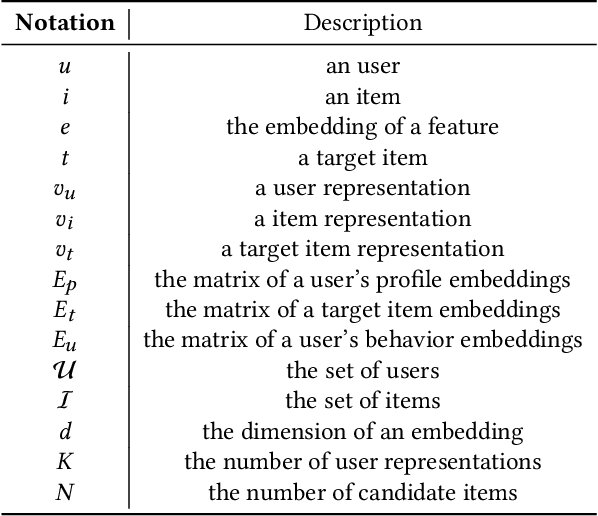
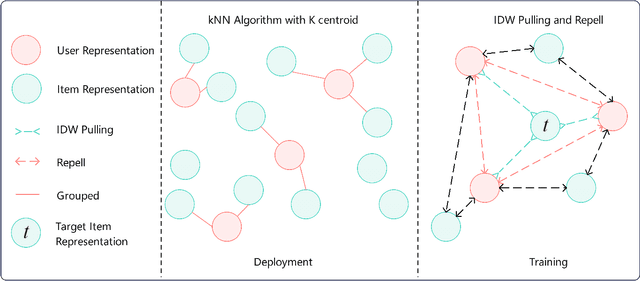
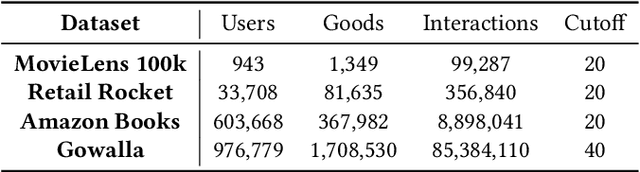
In the era of information overload, the value of recommender systems has been profoundly recognized in academia and industry alike. Multi-interest sequential recommendation, in particular, is a subfield that has been receiving increasing attention in recent years. By generating multiple-user representations, multi-interest learning models demonstrate superior expressiveness than single-user representation models, both theoretically and empirically. Despite major advancements in the field, three major issues continue to plague the performance and adoptability of multi-interest learning methods, the difference between training and deployment objectives, the inability to access item information, and the difficulty of industrial adoption due to its single-tower architecture. We address these challenges by proposing a novel multi-tower multi-interest framework with user representation repel. Experimental results across multiple large-scale industrial datasets proved the effectiveness and generalizability of our proposed framework.
RA-Rec: An Efficient ID Representation Alignment Framework for LLM-based Recommendation
Feb 07, 2024Large language models (LLM) have recently emerged as a powerful tool for a variety of natural language processing tasks, bringing a new surge of combining LLM with recommendation systems, termed as LLM-based RS. Current approaches generally fall into two main paradigms, the ID direct usage paradigm and the ID translation paradigm, noting their core weakness stems from lacking recommendation knowledge and uniqueness. To address this limitation, we propose a new paradigm, ID representation, which incorporates pre-trained ID embeddings into LLMs in a complementary manner. In this work, we present RA-Rec, an efficient ID representation alignment framework for LLM-based recommendation, which is compatible with multiple ID-based methods and LLM architectures. Specifically, we treat ID embeddings as soft prompts and design an innovative alignment module and an efficient tuning method with tailored data construction for alignment. Extensive experiments demonstrate RA-Rec substantially outperforms current state-of-the-art methods, achieving up to 3.0% absolute HitRate@100 improvements while utilizing less than 10x training data.
The Open DAC 2023 Dataset and Challenges for Sorbent Discovery in Direct Air Capture
Nov 01, 2023New methods for carbon dioxide removal are urgently needed to combat global climate change. Direct air capture (DAC) is an emerging technology to capture carbon dioxide directly from ambient air. Metal-organic frameworks (MOFs) have been widely studied as potentially customizable adsorbents for DAC. However, discovering promising MOF sorbents for DAC is challenging because of the vast chemical space to explore and the need to understand materials as functions of humidity and temperature. We explore a computational approach benefiting from recent innovations in machine learning (ML) and present a dataset named Open DAC 2023 (ODAC23) consisting of more than 38M density functional theory (DFT) calculations on more than 8,800 MOF materials containing adsorbed CO2 and/or H2O. ODAC23 is by far the largest dataset of MOF adsorption calculations at the DFT level of accuracy currently available. In addition to probing properties of adsorbed molecules, the dataset is a rich source of information on structural relaxation of MOFs, which will be useful in many contexts beyond specific applications for DAC. A large number of MOFs with promising properties for DAC are identified directly in ODAC23. We also trained state-of-the-art ML models on this dataset to approximate calculations at the DFT level. This open-source dataset and our initial ML models will provide an important baseline for future efforts to identify MOFs for a wide range of applications, including DAC.
Research on Patch Attentive Neural Process
Jan 29, 2022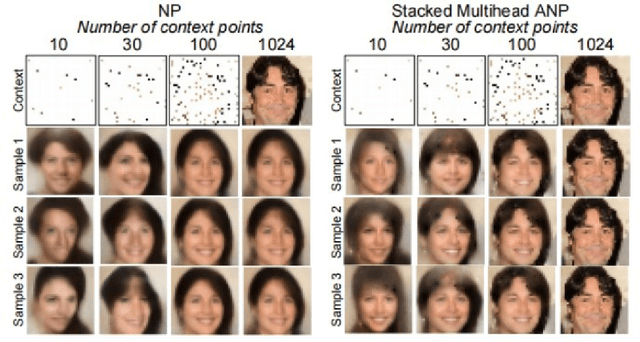
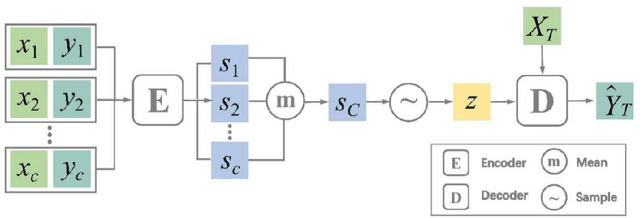
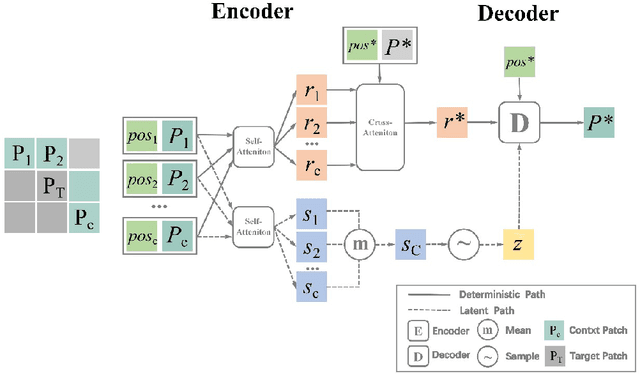
Attentive Neural Process (ANP) improves the fitting ability of Neural Process (NP) and improves its prediction accuracy, but the higher time complexity of the model imposes a limitation on the length of the input sequence. Inspired by models such as Vision Transformer (ViT) and Masked Auto-Encoder (MAE), we propose Patch Attentive Neural Process (PANP) using image patches as input and improve the structure of deterministic paths based on ANP, which allows the model to extract image features more accurately and efficiently reconstruction.
A Compositional Feature Embedding and Similarity Metric for Ultra-Fine-Grained Visual Categorization
Oct 06, 2021
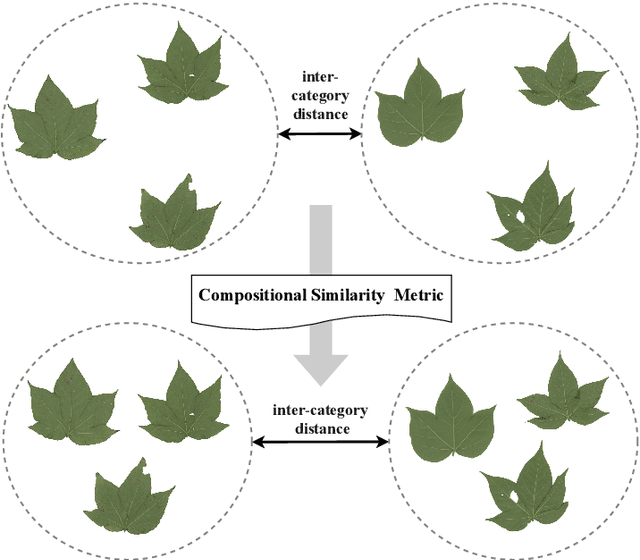
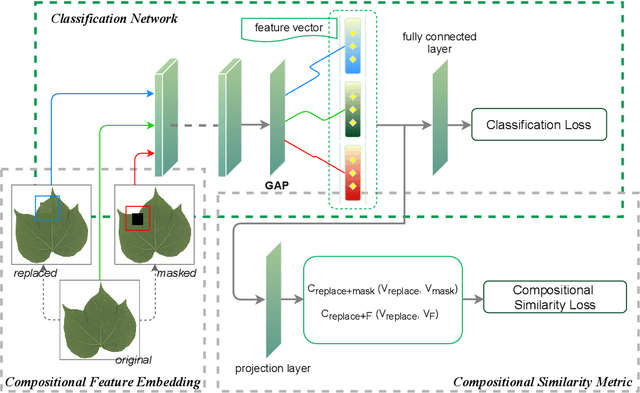
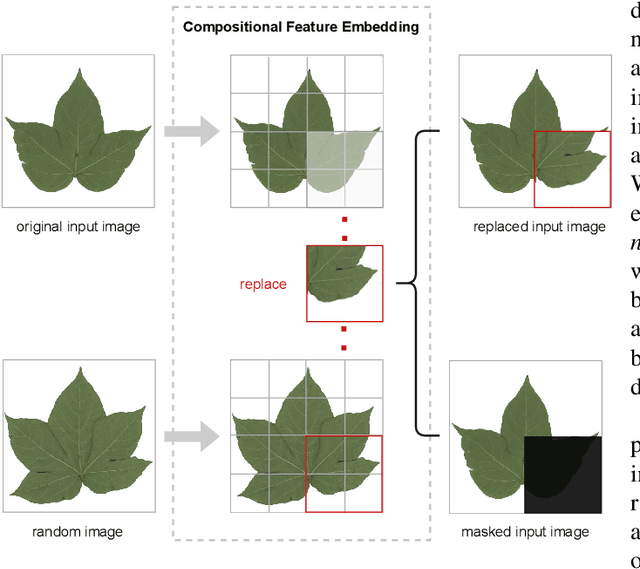
Fine-grained visual categorization (FGVC), which aims at classifying objects with small inter-class variances, has been significantly advanced in recent years. However, ultra-fine-grained visual categorization (ultra-FGVC), which targets at identifying subclasses with extremely similar patterns, has not received much attention. In ultra-FGVC datasets, the samples per category are always scarce as the granularity moves down, which will lead to overfitting problems. Moreover, the difference among different categories is too subtle to distinguish even for professional experts. Motivated by these issues, this paper proposes a novel compositional feature embedding and similarity metric (CECS). Specifically, in the compositional feature embedding module, we randomly select patches in the original input image, and these patches are then replaced by patches from the images of different categories or masked out. Then the replaced and masked images are used to augment the original input images, which can provide more diverse samples and thus largely alleviate overfitting problem resulted from limited training samples. Besides, learning with diverse samples forces the model to learn not only the most discriminative features but also other informative features in remaining regions, enhancing the generalization and robustness of the model. In the compositional similarity metric module, a new similarity metric is developed to improve the classification performance by narrowing the intra-category distance and enlarging the inter-category distance. Experimental results on two ultra-FGVC datasets and one FGVC dataset with recent benchmark methods consistently demonstrate that the proposed CECS method achieves the state of-the-art performance.
Mask-Guided Feature Extraction and Augmentation for Ultra-Fine-Grained Visual Categorization
Sep 16, 2021
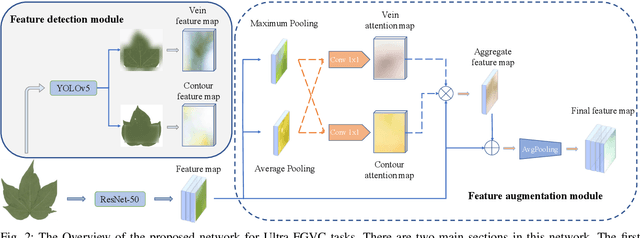
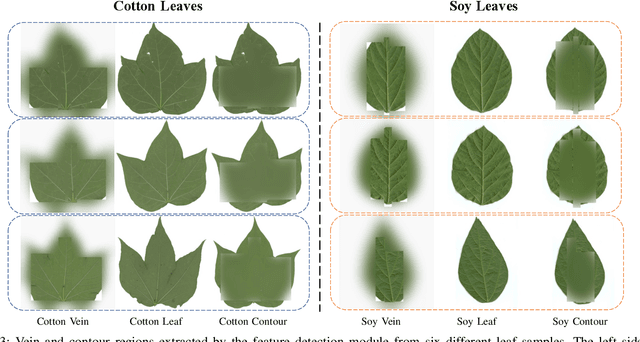
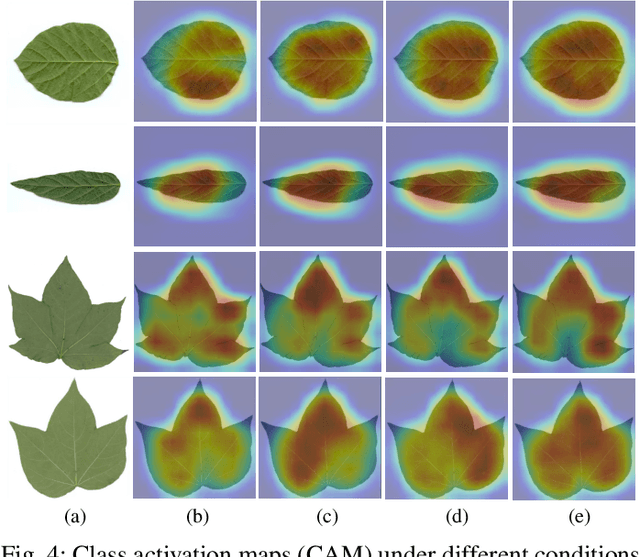
While the fine-grained visual categorization (FGVC) problems have been greatly developed in the past years, the Ultra-fine-grained visual categorization (Ultra-FGVC) problems have been understudied. FGVC aims at classifying objects from the same species (very similar categories), while the Ultra-FGVC targets at more challenging problems of classifying images at an ultra-fine granularity where even human experts may fail to identify the visual difference. The challenges for Ultra-FGVC mainly comes from two aspects: one is that the Ultra-FGVC often arises overfitting problems due to the lack of training samples; and another lies in that the inter-class variance among images is much smaller than normal FGVC tasks, which makes it difficult to learn discriminative features for each class. To solve these challenges, a mask-guided feature extraction and feature augmentation method is proposed in this paper to extract discriminative and informative regions of images which are then used to augment the original feature map. The advantage of the proposed method is that the feature detection and extraction model only requires a small amount of target region samples with bounding boxes for training, then it can automatically locate the target area for a large number of images in the dataset at a high detection accuracy. Experimental results on two public datasets and ten state-of-the-art benchmark methods consistently demonstrate the effectiveness of the proposed method both visually and quantitatively.
PGTRNet: Two-phase Weakly Supervised Object Detection with Pseudo Ground Truth Refining
Aug 25, 2021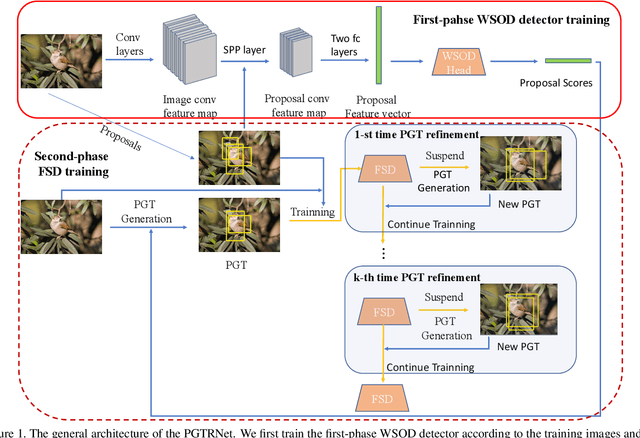

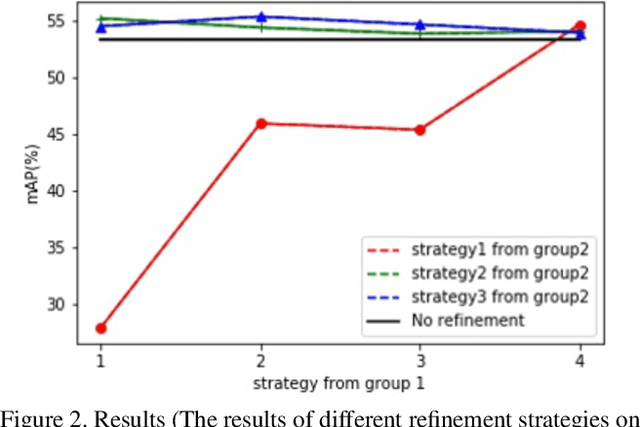
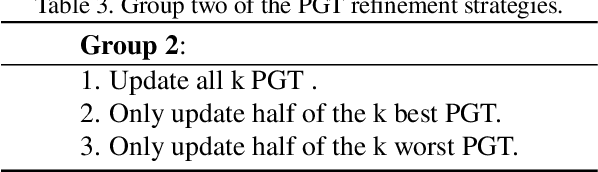
Weakly Supervised Object Detection (WSOD), aiming to train detectors with only image-level annotations, has arisen increasing attention. Current state-of-the-art approaches mainly follow a two-stage training strategy whichintegrates a fully supervised detector (FSD) with a pure WSOD model. There are two main problems hindering the performance of the two-phase WSOD approaches, i.e., insufficient learning problem and strict reliance between the FSD and the pseudo ground truth (PGT) generated by theWSOD model. This paper proposes pseudo ground truth refinement network (PGTRNet), a simple yet effective method without introducing any extra learnable parameters, to cope with these problems. PGTRNet utilizes multiple bounding boxes to establish the PGT, mitigating the insufficient learning problem. Besides, we propose a novel online PGT refinement approach to steadily improve the quality of PGTby fully taking advantage of the power of FSD during the second-phase training, decoupling the first and second-phase models. Elaborate experiments are conducted on the PASCAL VOC 2007 benchmark to verify the effectiveness of our methods. Experimental results demonstrate that PGTRNet boosts the backbone model by 2.074% mAP and achieves the state-of-the-art performance, showing the significant potentials of the second-phase training.
Feature Fusion Vision Transformer for Fine-Grained Visual Categorization
Jul 07, 2021
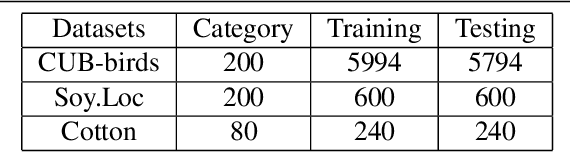
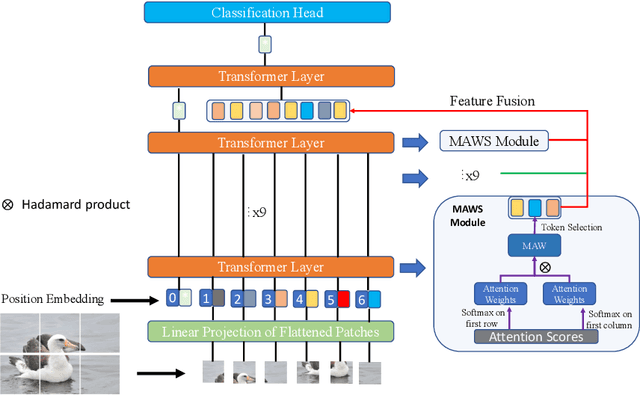
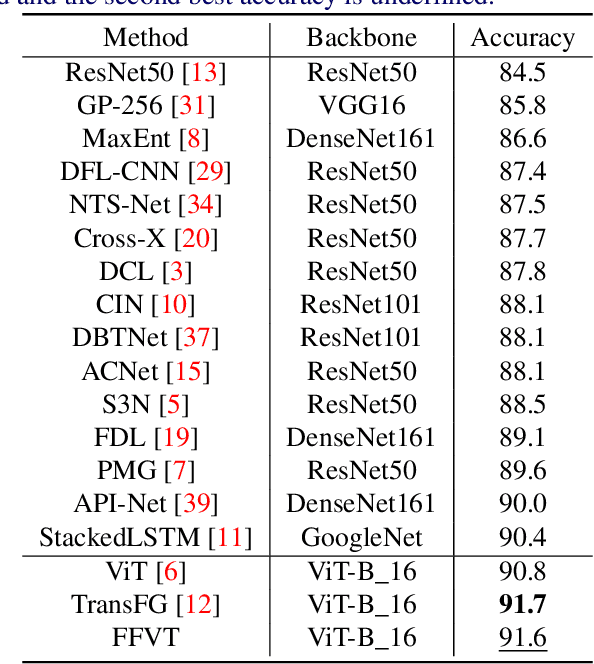
The core for tackling the fine-grained visual categorization (FGVC) is to learn subtle yet discriminative features. Most previous works achieve this by explicitly selecting the discriminative parts or integrating the attention mechanism via CNN-based approaches.However, these methods enhance the computational complexity and make the modeldominated by the regions containing the most of the objects. Recently, vision trans-former (ViT) has achieved SOTA performance on general image recognition tasks. Theself-attention mechanism aggregates and weights the information from all patches to the classification token, making it perfectly suitable for FGVC. Nonetheless, the classifi-cation token in the deep layer pays more attention to the global information, lacking the local and low-level features that are essential for FGVC. In this work, we proposea novel pure transformer-based framework Feature Fusion Vision Transformer (FFVT)where we aggregate the important tokens from each transformer layer to compensate thelocal, low-level and middle-level information. We design a novel token selection mod-ule called mutual attention weight selection (MAWS) to guide the network effectively and efficiently towards selecting discriminative tokens without introducing extra param-eters. We verify the effectiveness of FFVT on three benchmarks where FFVT achieves the state-of-the-art performance.
EAR-NET: Error Attention Refining Network For Retinal Vessel Segmentation
Jul 03, 2021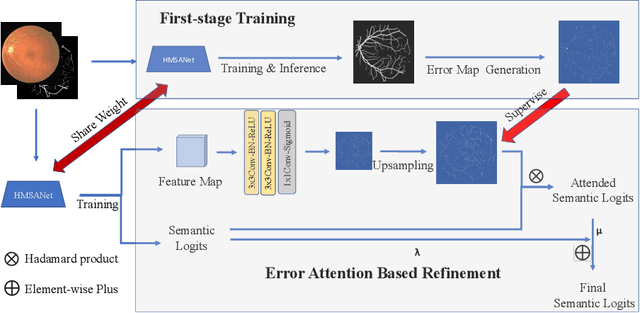
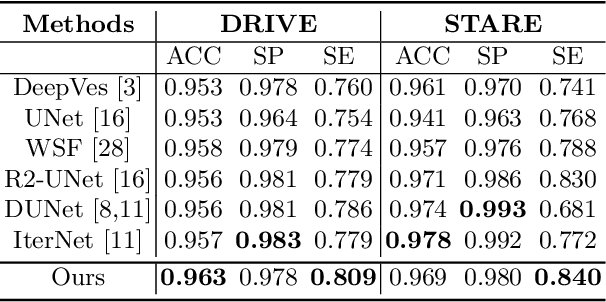

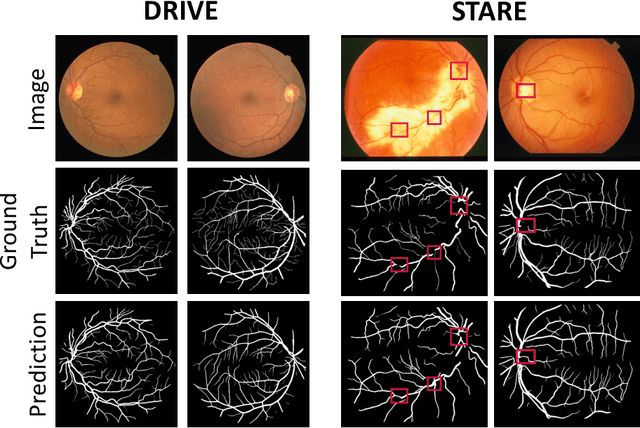
The precise detection of blood vessels in retinal images is crucial to the early diagnosis of the retinal vascular diseases, e.g., diabetic, hypertensive and solar retinopathies. Existing works often fail in predicting the abnormal areas, e.g, sudden brighter and darker areas and are inclined to predict a pixel to background due to the significant class imbalance, leading to high accuracy and specificity while low sensitivity. To that end, we propose a novel error attention refining network (ERA-Net) that is capable of learning and predicting the potential false predictions in a two-stage manner for effective retinal vessel segmentation. The proposed ERA-Net in the refine stage drives the model to focus on and refine the segmentation errors produced in the initial training stage. To achieve this, unlike most previous attention approaches that run in an unsupervised manner, we introduce a novel error attention mechanism which considers the differences between the ground truth and the initial segmentation masks as the ground truth to supervise the attention map learning. Experimental results demonstrate that our method achieves state-of-the-art performance on two common retinal blood vessel datasets.