 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiao Bai
TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting
Apr 23, 2024
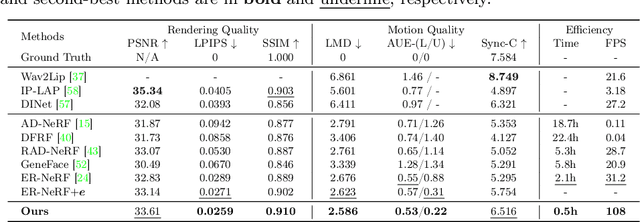

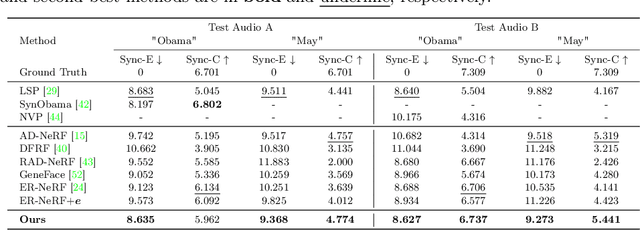
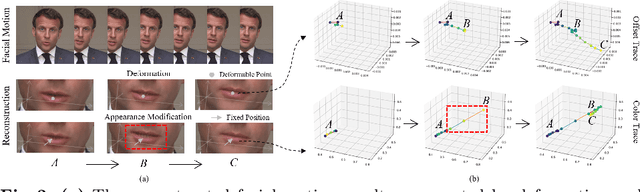
Radiance fields have demonstrated impressive performance in synthesizing lifelike 3D talking heads. However, due to the difficulty in fitting steep appearance changes, the prevailing paradigm that presents facial motions by directly modifying point appearance may lead to distortions in dynamic regions. To tackle this challenge, we introduce TalkingGaussian, a deformation-based radiance fields framework for high-fidelity talking head synthesis. Leveraging the point-based Gaussian Splatting, facial motions can be represented in our method by applying smooth and continuous deformations to persistent Gaussian primitives, without requiring to learn the difficult appearance change like previous methods. Due to this simplification, precise facial motions can be synthesized while keeping a highly intact facial feature. Under such a deformation paradigm, we further identify a face-mouth motion inconsistency that would affect the learning of detailed speaking motions. To address this conflict, we decompose the model into two branches separately for the face and inside mouth areas, therefore simplifying the learning tasks to help reconstruct more accurate motion and structure of the mouth region. Extensive experiments demonstrate that our method renders high-quality lip-synchronized talking head videos, with better facial fidelity and higher efficiency compared with previous methods.
Learning Transferable Negative Prompts for Out-of-Distribution Detection
Apr 04, 2024Existing prompt learning methods have shown certain capabilities in Out-of-Distribution (OOD) detection, but the lack of OOD images in the target dataset in their training can lead to mismatches between OOD images and In-Distribution (ID) categories, resulting in a high false positive rate. To address this issue, we introduce a novel OOD detection method, named 'NegPrompt', to learn a set of negative prompts, each representing a negative connotation of a given class label, for delineating the boundaries between ID and OOD images. It learns such negative prompts with ID data only, without any reliance on external outlier data. Further, current methods assume the availability of samples of all ID classes, rendering them ineffective in open-vocabulary learning scenarios where the inference stage can contain novel ID classes not present during training. In contrast, our learned negative prompts are transferable to novel class labels. Experiments on various ImageNet benchmarks show that NegPrompt surpasses state-of-the-art prompt-learning-based OOD detection methods and maintains a consistent lead in hard OOD detection in closed- and open-vocabulary classification scenarios. Code is available at https://github.com/mala-lab/negprompt.
DNGaussian: Optimizing Sparse-View 3D Gaussian Radiance Fields with Global-Local Depth Normalization
Mar 13, 2024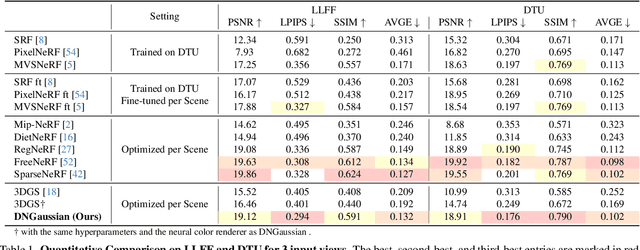
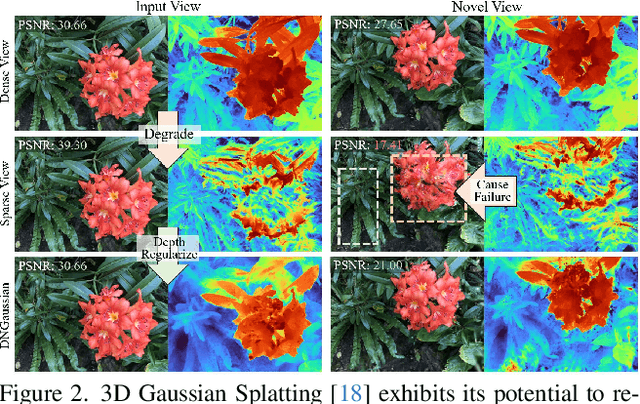
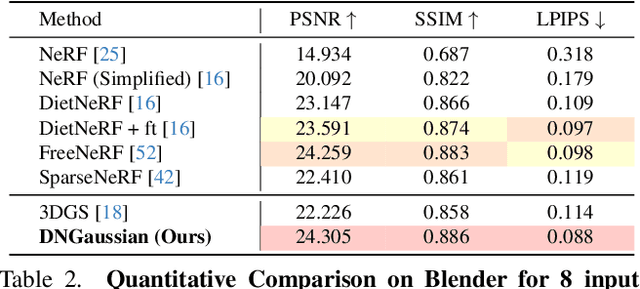
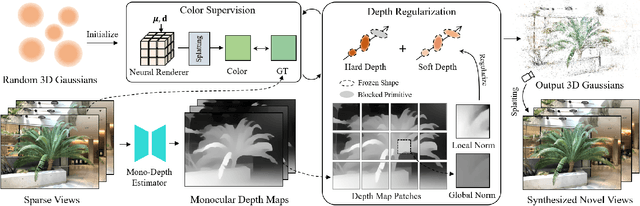
Radiance fields have demonstrated impressive performance in synthesizing novel views from sparse input views, yet prevailing methods suffer from high training costs and slow inference speed. This paper introduces DNGaussian, a depth-regularized framework based on 3D Gaussian radiance fields, offering real-time and high-quality few-shot novel view synthesis at low costs. Our motivation stems from the highly efficient representation and surprising quality of the recent 3D Gaussian Splatting, despite it will encounter a geometry degradation when input views decrease. In the Gaussian radiance fields, we find this degradation in scene geometry primarily lined to the positioning of Gaussian primitives and can be mitigated by depth constraint. Consequently, we propose a Hard and Soft Depth Regularization to restore accurate scene geometry under coarse monocular depth supervision while maintaining a fine-grained color appearance. To further refine detailed geometry reshaping, we introduce Global-Local Depth Normalization, enhancing the focus on small local depth changes. Extensive experiments on LLFF, DTU, and Blender datasets demonstrate that DNGaussian outperforms state-of-the-art methods, achieving comparable or better results with significantly reduced memory cost, a $25 \times$ reduction in training time, and over $3000 \times$ faster rendering speed.
Robust Synthetic-to-Real Transfer for Stereo Matching
Mar 12, 2024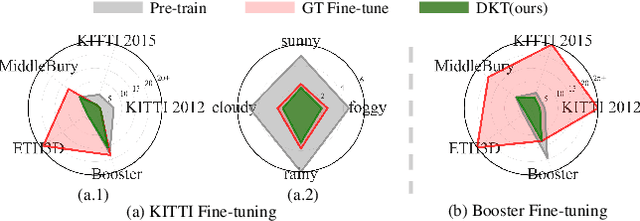
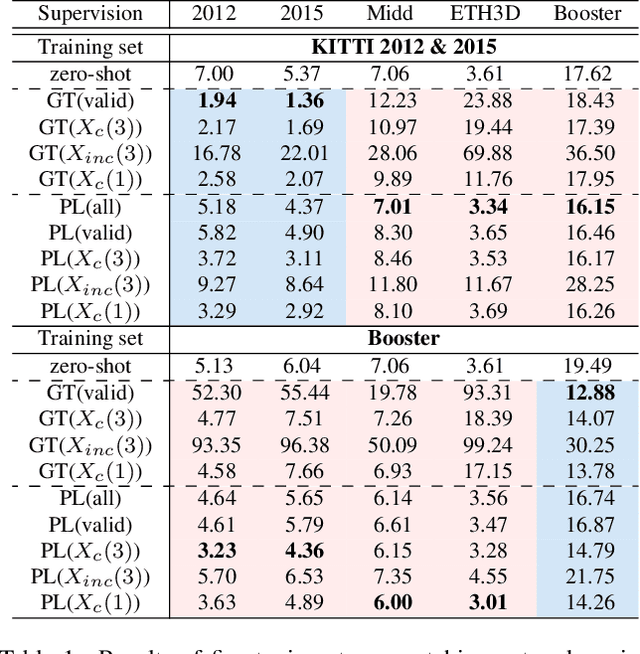
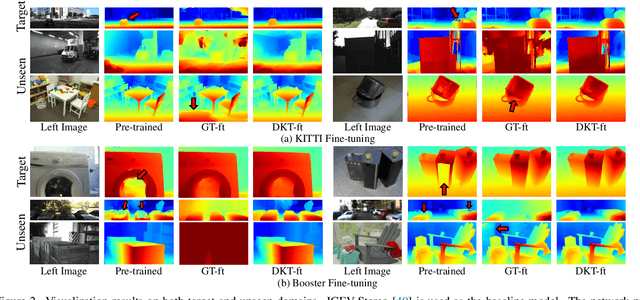
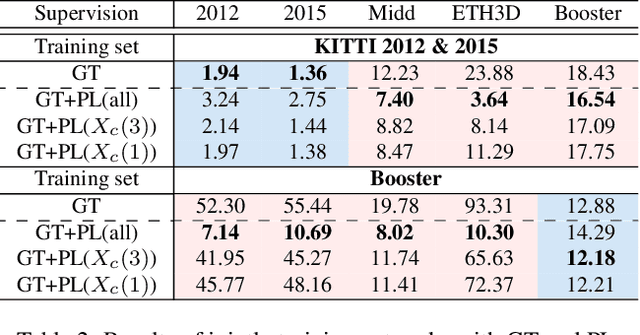
With advancements in domain generalized stereo matching networks, models pre-trained on synthetic data demonstrate strong robustness to unseen domains. However, few studies have investigated the robustness after fine-tuning them in real-world scenarios, during which the domain generalization ability can be seriously degraded. In this paper, we explore fine-tuning stereo matching networks without compromising their robustness to unseen domains. Our motivation stems from comparing Ground Truth (GT) versus Pseudo Label (PL) for fine-tuning: GT degrades, but PL preserves the domain generalization ability. Empirically, we find the difference between GT and PL implies valuable information that can regularize networks during fine-tuning. We also propose a framework to utilize this difference for fine-tuning, consisting of a frozen Teacher, an exponential moving average (EMA) Teacher, and a Student network. The core idea is to utilize the EMA Teacher to measure what the Student has learned and dynamically improve GT and PL for fine-tuning. We integrate our framework with state-of-the-art networks and evaluate its effectiveness on several real-world datasets. Extensive experiments show that our method effectively preserves the domain generalization ability during fine-tuning.
Simple Image-level Classification Improves Open-vocabulary Object Detection
Dec 19, 2023Open-Vocabulary Object Detection (OVOD) aims to detect novel objects beyond a given set of base categories on which the detection model is trained. Recent OVOD methods focus on adapting the image-level pre-trained vision-language models (VLMs), such as CLIP, to a region-level object detection task via, eg., region-level knowledge distillation, regional prompt learning, or region-text pre-training, to expand the detection vocabulary. These methods have demonstrated remarkable performance in recognizing regional visual concepts, but they are weak in exploiting the VLMs' powerful global scene understanding ability learned from the billion-scale image-level text descriptions. This limits their capability in detecting hard objects of small, blurred, or occluded appearance from novel/base categories, whose detection heavily relies on contextual information. To address this, we propose a novel approach, namely Simple Image-level Classification for Context-Aware Detection Scoring (SIC-CADS), to leverage the superior global knowledge yielded from CLIP for complementing the current OVOD models from a global perspective. The core of SIC-CADS is a multi-modal multi-label recognition (MLR) module that learns the object co-occurrence-based contextual information from CLIP to recognize all possible object categories in the scene. These image-level MLR scores can then be utilized to refine the instance-level detection scores of the current OVOD models in detecting those hard objects. This is verified by extensive empirical results on two popular benchmarks, OV-LVIS and OV-COCO, which show that SIC-CADS achieves significant and consistent improvement when combined with different types of OVOD models. Further, SIC-CADS also improves the cross-dataset generalization ability on Objects365 and OpenImages. The code is available at https://github.com/mala-lab/SIC-CADS.
Out-of-Distribution Detection in Long-Tailed Recognition with Calibrated Outlier Class Learning
Dec 19, 2023Existing out-of-distribution (OOD) methods have shown great success on balanced datasets but become ineffective in long-tailed recognition (LTR) scenarios where 1) OOD samples are often wrongly classified into head classes and/or 2) tail-class samples are treated as OOD samples. To address these issues, current studies fit a prior distribution of auxiliary/pseudo OOD data to the long-tailed in-distribution (ID) data. However, it is difficult to obtain such an accurate prior distribution given the unknowingness of real OOD samples and heavy class imbalance in LTR. A straightforward solution to avoid the requirement of this prior is to learn an outlier class to encapsulate the OOD samples. The main challenge is then to tackle the aforementioned confusion between OOD samples and head/tail-class samples when learning the outlier class. To this end, we introduce a novel calibrated outlier class learning (COCL) approach, in which 1) a debiased large margin learning method is introduced in the outlier class learning to distinguish OOD samples from both head and tail classes in the representation space and 2) an outlier-class-aware logit calibration method is defined to enhance the long-tailed classification confidence. Extensive empirical results on three popular benchmarks CIFAR10-LT, CIFAR100-LT, and ImageNet-LT demonstrate that COCL substantially outperforms state-of-the-art OOD detection methods in LTR while being able to improve the classification accuracy on ID data. Code is available at https://github.com/mala-lab/COCL.
Deep Learning-based 3D Point Cloud Classification: A Systematic Survey and Outlook
Nov 05, 2023
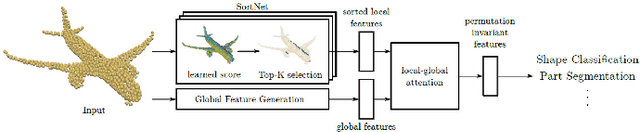
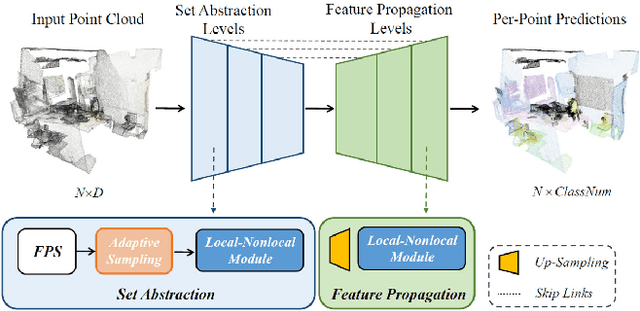
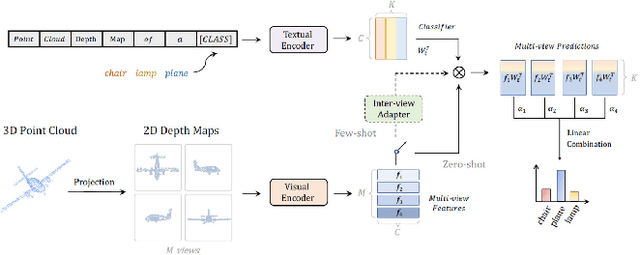
In recent years, point cloud representation has become one of the research hotspots in the field of computer vision, and has been widely used in many fields, such as autonomous driving, virtual reality, robotics, etc. Although deep learning techniques have achieved great success in processing regular structured 2D grid image data, there are still great challenges in processing irregular, unstructured point cloud data. Point cloud classification is the basis of point cloud analysis, and many deep learning-based methods have been widely used in this task. Therefore, the purpose of this paper is to provide researchers in this field with the latest research progress and future trends. First, we introduce point cloud acquisition, characteristics, and challenges. Second, we review 3D data representations, storage formats, and commonly used datasets for point cloud classification. We then summarize deep learning-based methods for point cloud classification and complement recent research work. Next, we compare and analyze the performance of the main methods. Finally, we discuss some challenges and future directions for point cloud classification.
Towards Fully Decoupled End-to-End Person Search
Sep 10, 2023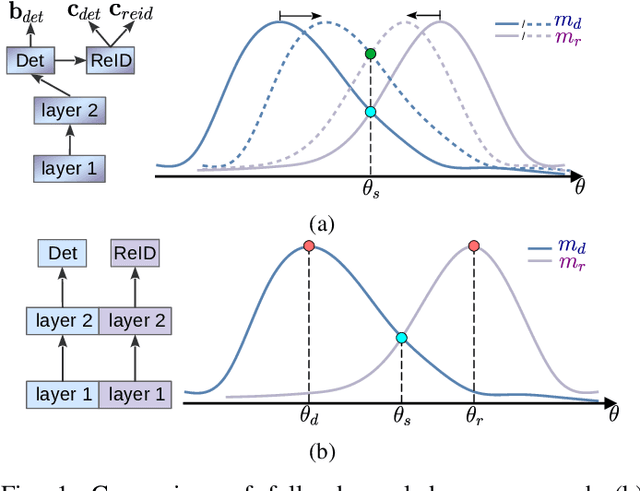
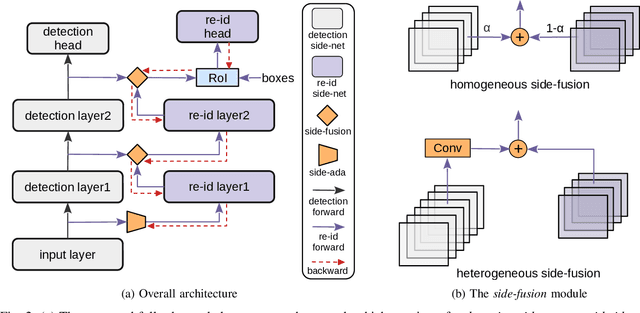


End-to-end person search aims to jointly detect and re-identify a target person in raw scene images with a unified model. The detection task unifies all persons while the re-id task discriminates different identities, resulting in conflict optimal objectives. Existing works proposed to decouple end-to-end person search to alleviate such conflict. Yet these methods are still sub-optimal on one or two of the sub-tasks due to their partially decoupled models, which limits the overall person search performance. In this paper, we propose to fully decouple person search towards optimal person search. A task-incremental person search network is proposed to incrementally construct an end-to-end model for the detection and re-id sub-task, which decouples the model architecture for the two sub-tasks. The proposed task-incremental network allows task-incremental training for the two conflicting tasks. This enables independent learning for different objectives thus fully decoupled the model for persons earch. Comprehensive experimental evaluations demonstrate the effectiveness of the proposed fully decoupled models for end-to-end person search.
Unsupervised Recognition of Unknown Objects for Open-World Object Detection
Aug 31, 2023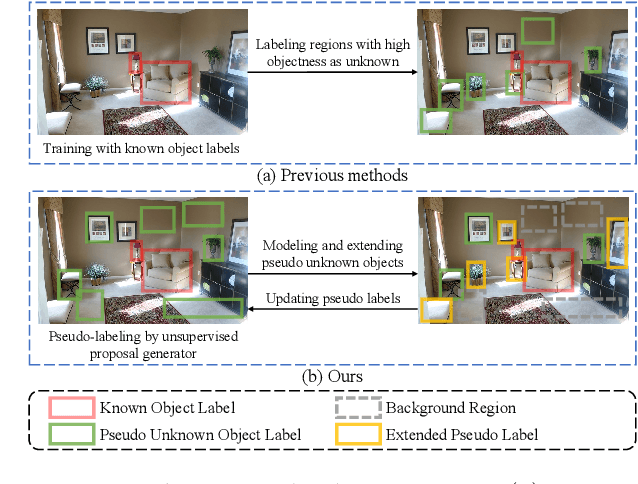
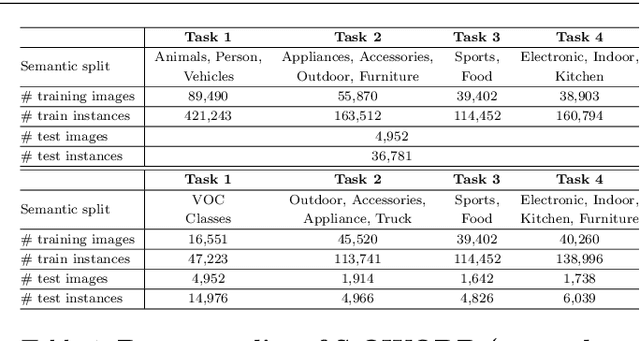
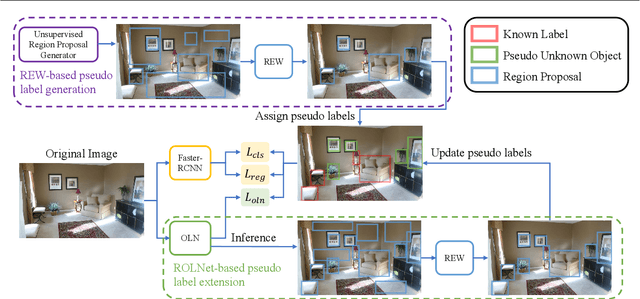
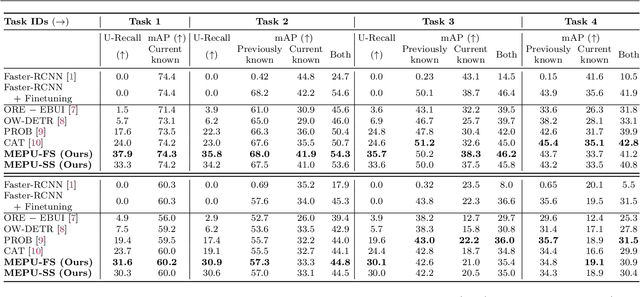
Open-World Object Detection (OWOD) extends object detection problem to a realistic and dynamic scenario, where a detection model is required to be capable of detecting both known and unknown objects and incrementally learning newly introduced knowledge. Current OWOD models, such as ORE and OW-DETR, focus on pseudo-labeling regions with high objectness scores as unknowns, whose performance relies heavily on the supervision of known objects. While they can detect the unknowns that exhibit similar features to the known objects, they suffer from a severe label bias problem that they tend to detect all regions (including unknown object regions) that are dissimilar to the known objects as part of the background. To eliminate the label bias, this paper proposes a novel approach that learns an unsupervised discriminative model to recognize true unknown objects from raw pseudo labels generated by unsupervised region proposal methods. The resulting model can be further refined by a classification-free self-training method which iteratively extends pseudo unknown objects to the unlabeled regions. Experimental results show that our method 1) significantly outperforms the prior SOTA in detecting unknown objects while maintaining competitive performance of detecting known object classes on the MS COCO dataset, and 2) achieves better generalization ability on the LVIS and Objects365 datasets.
Efficient Region-Aware Neural Radiance Fields for High-Fidelity Talking Portrait Synthesis
Jul 18, 2023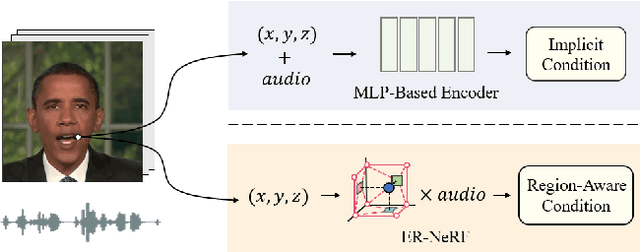

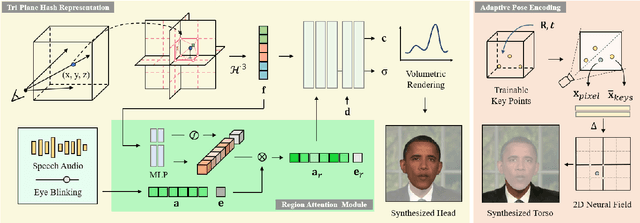

This paper presents ER-NeRF, a novel conditional Neural Radiance Fields (NeRF) based architecture for talking portrait synthesis that can concurrently achieve fast convergence, real-time rendering, and state-of-the-art performance with small model size. Our idea is to explicitly exploit the unequal contribution of spatial regions to guide talking portrait modeling. Specifically, to improve the accuracy of dynamic head reconstruction, a compact and expressive NeRF-based Tri-Plane Hash Representation is introduced by pruning empty spatial regions with three planar hash encoders. For speech audio, we propose a Region Attention Module to generate region-aware condition feature via an attention mechanism. Different from existing methods that utilize an MLP-based encoder to learn the cross-modal relation implicitly, the attention mechanism builds an explicit connection between audio features and spatial regions to capture the priors of local motions. Moreover, a direct and fast Adaptive Pose Encoding is introduced to optimize the head-torso separation problem by mapping the complex transformation of the head pose into spatial coordinates. Extensive experiments demonstrate that our method renders better high-fidelity and audio-lips synchronized talking portrait videos, with realistic details and high efficiency compared to previous methods.