 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXin Zhao
MetaRM: Shifted Distributions Alignment via Meta-Learning
May 01, 2024
The success of Reinforcement Learning from Human Feedback (RLHF) in language model alignment is critically dependent on the capability of the reward model (RM). However, as the training process progresses, the output distribution of the policy model shifts, leading to the RM's reduced ability to distinguish between responses. This issue is further compounded when the RM, trained on a specific data distribution, struggles to generalize to examples outside of that distribution. These two issues can be united as a challenge posed by the shifted distribution of the environment. To surmount this challenge, we introduce MetaRM, a method leveraging meta-learning to align the RM with the shifted environment distribution. MetaRM is designed to train the RM by minimizing data loss, particularly for data that can improve the differentiation ability to examples of the shifted target distribution. Extensive experiments demonstrate that MetaRM significantly improves the RM's distinguishing ability in iterative RLHF optimization, and also provides the capacity to identify subtle differences in out-of-distribution samples.
EulerFormer: Sequential User Behavior Modeling with Complex Vector Attention
Apr 04, 2024
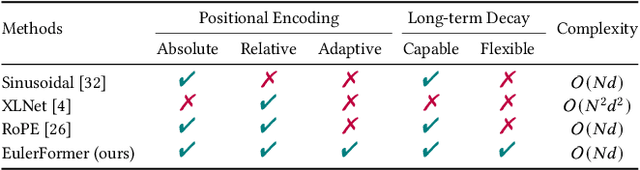
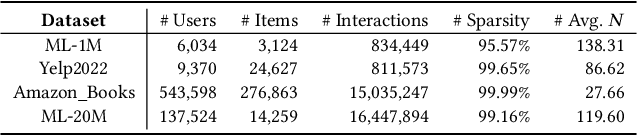
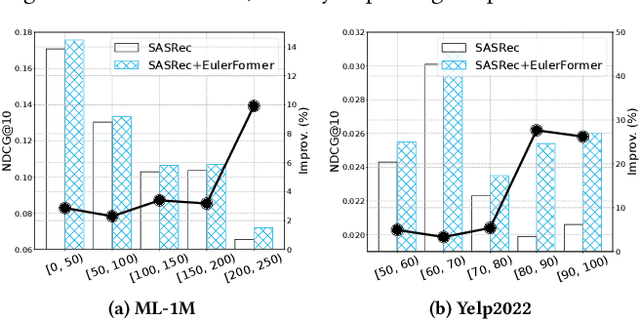
To capture user preference, transformer models have been widely applied to model sequential user behavior data. The core of transformer architecture lies in the self-attention mechanism, which computes the pairwise attention scores in a sequence. Due to the permutation-equivariant nature, positional encoding is used to enhance the attention between token representations. In this setting, the pairwise attention scores can be derived by both semantic difference and positional difference. However, prior studies often model the two kinds of difference measurements in different ways, which potentially limits the expressive capacity of sequence modeling. To address this issue, this paper proposes a novel transformer variant with complex vector attention, named EulerFormer, which provides a unified theoretical framework to formulate both semantic difference and positional difference. The EulerFormer involves two key technical improvements. First, it employs a new transformation function for efficiently transforming the sequence tokens into polar-form complex vectors using Euler's formula, enabling the unified modeling of both semantic and positional information in a complex rotation form.Secondly, it develops a differential rotation mechanism, where the semantic rotation angles can be controlled by an adaptation function, enabling the adaptive integration of the semantic and positional information according to the semantic contexts.Furthermore, a phase contrastive learning task is proposed to improve the isotropy of contextual representations in EulerFormer. Our theoretical framework possesses a high degree of completeness and generality. It is more robust to semantic variations and possesses moresuperior theoretical properties in principle. Extensive experiments conducted on four public datasets demonstrate the effectiveness and efficiency of our approach.
UAlign: Pushing the Limit of Template-free Retrosynthesis Prediction with Unsupervised SMILES Alignment
Mar 25, 2024Retrosynthesis planning poses a formidable challenge in the organic chemical industry, particularly in pharmaceuticals. Single-step retrosynthesis prediction, a crucial step in the planning process, has witnessed a surge in interest in recent years due to advancements in AI for science. Various deep learning-based methods have been proposed for this task in recent years, incorporating diverse levels of additional chemical knowledge dependency. This paper introduces UAlign, a template-free graph-to-sequence pipeline for retrosynthesis prediction. By combining graph neural networks and Transformers, our method can more effectively leverage the inherent graph structure of molecules. Based on the fact that the majority of molecule structures remain unchanged during a chemical reaction, we propose a simple yet effective SMILES alignment technique to facilitate the reuse of unchanged structures for reactant generation. Extensive experiments show that our method substantially outperforms state-of-the-art template-free and semi-template-based approaches. Importantly, Our template-free method achieves effectiveness comparable to, or even surpasses, established powerful template-based methods. Scientific contribution: We present a novel graph-to-sequence template-free retrosynthesis prediction pipeline that overcomes the limitations of Transformer-based methods in molecular representation learning and insufficient utilization of chemical information. We propose an unsupervised learning mechanism for establishing product-atom correspondence with reactant SMILES tokens, achieving even better results than supervised SMILES alignment methods. Extensive experiments demonstrate that UAlign significantly outperforms state-of-the-art template-free methods and rivals or surpasses template-based approaches, with up to 5\% (top-5) and 5.4\% (top-10) increased accuracy over the strongest baseline.
PeLK: Parameter-efficient Large Kernel ConvNets with Peripheral Convolution
Mar 16, 2024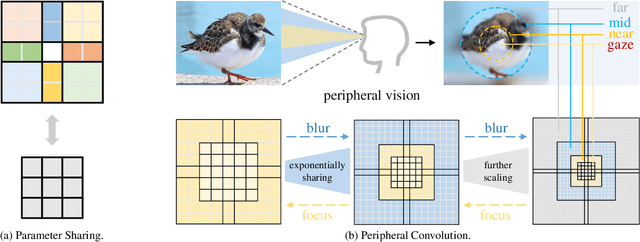

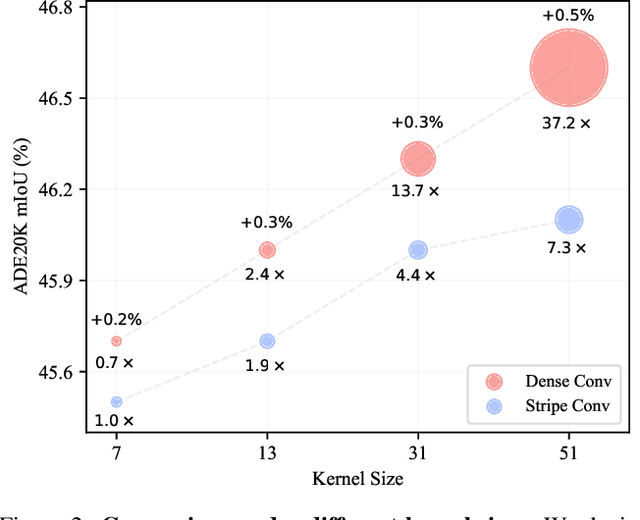

Recently, some large kernel convnets strike back with appealing performance and efficiency. However, given the square complexity of convolution, scaling up kernels can bring about an enormous amount of parameters and the proliferated parameters can induce severe optimization problem. Due to these issues, current CNNs compromise to scale up to 51x51 in the form of stripe convolution (i.e., 51x5 + 5x51) and start to saturate as the kernel size continues growing. In this paper, we delve into addressing these vital issues and explore whether we can continue scaling up kernels for more performance gains. Inspired by human vision, we propose a human-like peripheral convolution that efficiently reduces over 90% parameter count of dense grid convolution through parameter sharing, and manage to scale up kernel size to extremely large. Our peripheral convolution behaves highly similar to human, reducing the complexity of convolution from O(K^2) to O(logK) without backfiring performance. Built on this, we propose Parameter-efficient Large Kernel Network (PeLK). Our PeLK outperforms modern vision Transformers and ConvNet architectures like Swin, ConvNeXt, RepLKNet and SLaK on various vision tasks including ImageNet classification, semantic segmentation on ADE20K and object detection on MS COCO. For the first time, we successfully scale up the kernel size of CNNs to an unprecedented 101x101 and demonstrate consistent improvements.
Tracing the Roots of Facts in Multilingual Language Models: Independent, Shared, and Transferred Knowledge
Mar 08, 2024



Acquiring factual knowledge for language models (LMs) in low-resource languages poses a serious challenge, thus resorting to cross-lingual transfer in multilingual LMs (ML-LMs). In this study, we ask how ML-LMs acquire and represent factual knowledge. Using the multilingual factual knowledge probing dataset, mLAMA, we first conducted a neuron investigation of ML-LMs (specifically, multilingual BERT). We then traced the roots of facts back to the knowledge source (Wikipedia) to identify the ways in which ML-LMs acquire specific facts. We finally identified three patterns of acquiring and representing facts in ML-LMs: language-independent, cross-lingual shared and transferred, and devised methods for differentiating them. Our findings highlight the challenge of maintaining consistent factual knowledge across languages, underscoring the need for better fact representation learning in ML-LMs.
IRConStyle: Image Restoration Framework Using Contrastive Learning and Style Transfer
Mar 07, 2024Recently, the contrastive learning paradigm has achieved remarkable success in high-level tasks such as classification, detection, and segmentation. However, contrastive learning applied in low-level tasks, like image restoration, is limited, and its effectiveness is uncertain. This raises a question: Why does the contrastive learning paradigm not yield satisfactory results in image restoration? In this paper, we conduct in-depth analyses and propose three guidelines to address the above question. In addition, inspired by style transfer and based on contrastive learning, we propose a novel module for image restoration called \textbf{ConStyle}, which can be efficiently integrated into any U-Net structure network. By leveraging the flexibility of ConStyle, we develop a \textbf{general restoration network} for image restoration. ConStyle and the general restoration network together form an image restoration framework, namely \textbf{IRConStyle}. To demonstrate the capability and compatibility of ConStyle, we replace the general restoration network with transformer-based, CNN-based, and MLP-based networks, respectively. We perform extensive experiments on various image restoration tasks, including denoising, deblurring, deraining, and dehazing. The results on 19 benchmarks demonstrate that ConStyle can be integrated with any U-Net-based network and significantly enhance performance. For instance, ConStyle NAFNet significantly outperforms the original NAFNet on SOTS outdoor (dehazing) and Rain100H (deraining) datasets, with PSNR improvements of 4.16 dB and 3.58 dB with 85% fewer parameters.
Adaptive Online Learning of Separable Path Graph Transforms for Intra-prediction
Feb 26, 2024Current video coding standards, including H.264/AVC, HEVC, and VVC, employ discrete cosine transform (DCT), discrete sine transform (DST), and secondary to Karhunen-Loeve transforms (KLTs) decorrelate the intra-prediction residuals. However, the efficiency of these transforms in decorrelation can be limited when the signal has a non-smooth and non-periodic structure, such as those occurring in textures with intricate patterns. This paper introduces a novel adaptive separable path graph-based transform (GBT) that can provide better decorrelation than the DCT for intra-predicted texture data. The proposed GBT is learned in an online scenario with sequential K-means clustering, which groups similar blocks during encoding and decoding to adaptively learn the GBT for the current block from previously reconstructed areas with similar characteristics. A signaling overhead is added to the bitstream of each coding block to indicate the usage of the proposed graph-based transform. We assess the performance of this method combined with H.264/AVC intra-coding tools and demonstrate that it can significantly outperform H.264/AVC DCT for intra-predicted texture data.
Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models
Feb 26, 2024Large language models (LLMs) demonstrate remarkable multilingual capabilities without being pre-trained on specially curated multilingual parallel corpora. It remains a challenging problem to explain the underlying mechanisms by which LLMs process multilingual texts. In this paper, we delve into the composition of Transformer architectures in LLMs to pinpoint language-specific regions. Specially, we propose a novel detection method, language activation probability entropy (LAPE), to identify language-specific neurons within LLMs. Based on LAPE, we conduct comprehensive experiments on two representative LLMs, namely LLaMA-2 and BLOOM. Our findings indicate that LLMs' proficiency in processing a particular language is predominantly due to a small subset of neurons, primarily situated in the models' top and bottom layers. Furthermore, we showcase the feasibility to "steer" the output language of LLMs by selectively activating or deactivating language-specific neurons. Our research provides important evidence to the understanding and exploration of the multilingual capabilities of LLMs.
BioDrone: A Bionic Drone-based Single Object Tracking Benchmark for Robust Vision
Feb 07, 2024Single object tracking (SOT) is a fundamental problem in computer vision, with a wide range of applications, including autonomous driving, augmented reality, and robot navigation. The robustness of SOT faces two main challenges: tiny target and fast motion. These challenges are especially manifested in videos captured by unmanned aerial vehicles (UAV), where the target is usually far away from the camera and often with significant motion relative to the camera. To evaluate the robustness of SOT methods, we propose BioDrone -- the first bionic drone-based visual benchmark for SOT. Unlike existing UAV datasets, BioDrone features videos captured from a flapping-wing UAV system with a major camera shake due to its aerodynamics. BioDrone hence highlights the tracking of tiny targets with drastic changes between consecutive frames, providing a new robust vision benchmark for SOT. To date, BioDrone offers the largest UAV-based SOT benchmark with high-quality fine-grained manual annotations and automatically generates frame-level labels, designed for robust vision analyses. Leveraging our proposed BioDrone, we conduct a systematic evaluation of existing SOT methods, comparing the performance of 20 representative models and studying novel means of optimizing a SOTA method (KeepTrack KeepTrack) for robust SOT. Our evaluation leads to new baselines and insights for robust SOT. Moving forward, we hope that BioDrone will not only serve as a high-quality benchmark for robust SOT, but also invite future research into robust computer vision. The database, toolkits, evaluation server, and baseline results are available at http://biodrone.aitestunion.com.
* This paper is published in IJCV (refer to DOI). Please cite the published IJCV
RA-Rec: An Efficient ID Representation Alignment Framework for LLM-based Recommendation
Feb 07, 2024Large language models (LLM) have recently emerged as a powerful tool for a variety of natural language processing tasks, bringing a new surge of combining LLM with recommendation systems, termed as LLM-based RS. Current approaches generally fall into two main paradigms, the ID direct usage paradigm and the ID translation paradigm, noting their core weakness stems from lacking recommendation knowledge and uniqueness. To address this limitation, we propose a new paradigm, ID representation, which incorporates pre-trained ID embeddings into LLMs in a complementary manner. In this work, we present RA-Rec, an efficient ID representation alignment framework for LLM-based recommendation, which is compatible with multiple ID-based methods and LLM architectures. Specifically, we treat ID embeddings as soft prompts and design an innovative alignment module and an efficient tuning method with tailored data construction for alignment. Extensive experiments demonstrate RA-Rec substantially outperforms current state-of-the-art methods, achieving up to 3.0% absolute HitRate@100 improvements while utilizing less than 10x training data.