 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYipei Wang
Learning the irreversible progression trajectory of Alzheimer's disease
Mar 10, 2024
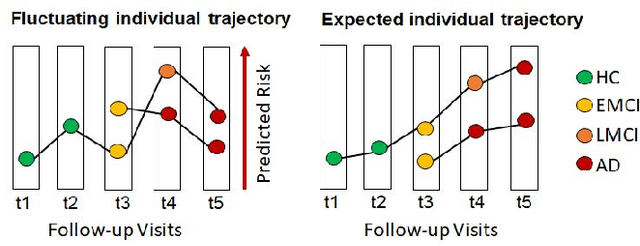
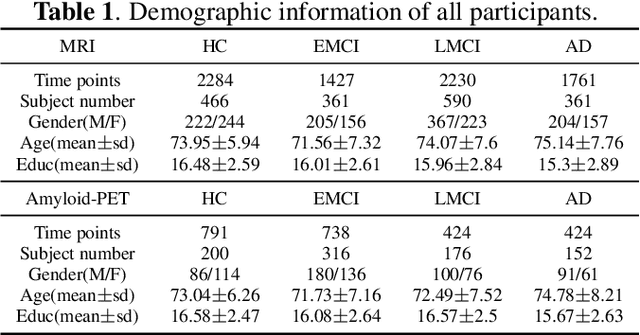

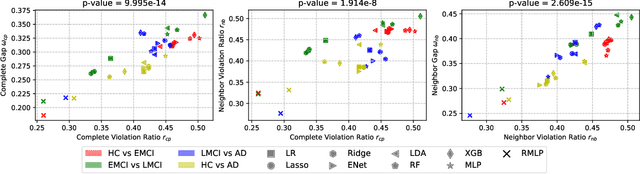
Alzheimer's disease (AD) is a progressive and irreversible brain disorder that unfolds over the course of 30 years. Therefore, it is critical to capture the disease progression in an early stage such that intervention can be applied before the onset of symptoms. Machine learning (ML) models have been shown effective in predicting the onset of AD. Yet for subjects with follow-up visits, existing techniques for AD classification only aim for accurate group assignment, where the monotonically increasing risk across follow-up visits is usually ignored. Resulted fluctuating risk scores across visits violate the irreversibility of AD, hampering the trustworthiness of models and also providing little value to understanding the disease progression. To address this issue, we propose a novel regularization approach to predict AD longitudinally. Our technique aims to maintain the expected monotonicity of increasing disease risk during progression while preserving expressiveness. Specifically, we introduce a monotonicity constraint that encourages the model to predict disease risk in a consistent and ordered manner across follow-up visits. We evaluate our method using the longitudinal structural MRI and amyloid-PET imaging data from the Alzheimer's Disease Neuroimaging Initiative (ADNI). Our model outperforms existing techniques in capturing the progressiveness of disease risk, and at the same time preserves prediction accuracy.
Semi-weakly-supervised neural network training for medical image registration
Feb 16, 2024For training registration networks, weak supervision from segmented corresponding regions-of-interest (ROIs) have been proven effective for (a) supplementing unsupervised methods, and (b) being used independently in registration tasks in which unsupervised losses are unavailable or ineffective. This correspondence-informing supervision entails cost in annotation that requires significant specialised effort. This paper describes a semi-weakly-supervised registration pipeline that improves the model performance, when only a small corresponding-ROI-labelled dataset is available, by exploiting unlabelled image pairs. We examine two types of augmentation methods by perturbation on network weights and image resampling, such that consistency-based unsupervised losses can be applied on unlabelled data. The novel WarpDDF and RegCut approaches are proposed to allow commutative perturbation between an image pair and the predicted spatial transformation (i.e. respective input and output of registration networks), distinct from existing perturbation methods for classification or segmentation. Experiments using 589 male pelvic MR images, labelled with eight anatomical ROIs, show the improvement in registration performance and the ablated contributions from the individual strategies. Furthermore, this study attempts to construct one of the first computational atlases for pelvic structures, enabled by registering inter-subject MRs, and quantifies the significant differences due to the proposed semi-weak supervision with a discussion on the potential clinical use of example atlas-derived statistics.
BioDrone: A Bionic Drone-based Single Object Tracking Benchmark for Robust Vision
Feb 07, 2024Single object tracking (SOT) is a fundamental problem in computer vision, with a wide range of applications, including autonomous driving, augmented reality, and robot navigation. The robustness of SOT faces two main challenges: tiny target and fast motion. These challenges are especially manifested in videos captured by unmanned aerial vehicles (UAV), where the target is usually far away from the camera and often with significant motion relative to the camera. To evaluate the robustness of SOT methods, we propose BioDrone -- the first bionic drone-based visual benchmark for SOT. Unlike existing UAV datasets, BioDrone features videos captured from a flapping-wing UAV system with a major camera shake due to its aerodynamics. BioDrone hence highlights the tracking of tiny targets with drastic changes between consecutive frames, providing a new robust vision benchmark for SOT. To date, BioDrone offers the largest UAV-based SOT benchmark with high-quality fine-grained manual annotations and automatically generates frame-level labels, designed for robust vision analyses. Leveraging our proposed BioDrone, we conduct a systematic evaluation of existing SOT methods, comparing the performance of 20 representative models and studying novel means of optimizing a SOTA method (KeepTrack KeepTrack) for robust SOT. Our evaluation leads to new baselines and insights for robust SOT. Moving forward, we hope that BioDrone will not only serve as a high-quality benchmark for robust SOT, but also invite future research into robust computer vision. The database, toolkits, evaluation server, and baseline results are available at http://biodrone.aitestunion.com.
* This paper is published in IJCV (refer to DOI). Please cite the published IJCV
Prototypical few-shot segmentation for cross-institution male pelvic structures with spatial registration
Sep 13, 2022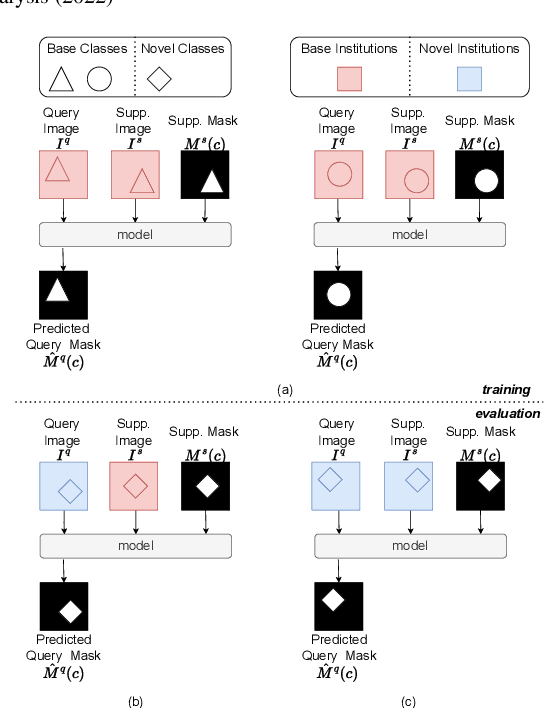

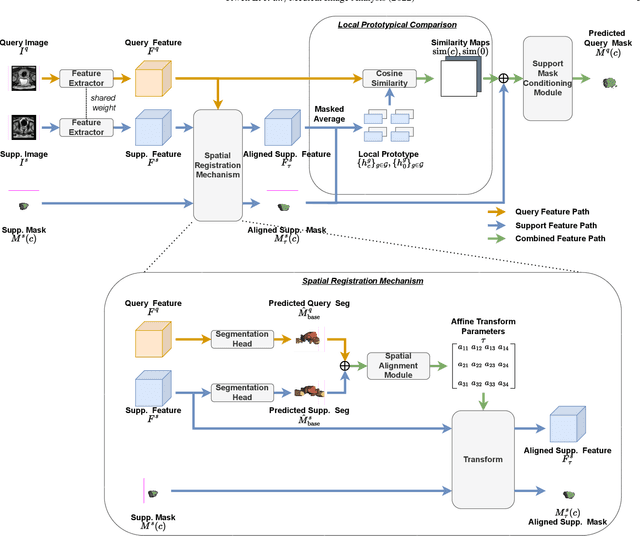

The prowess that makes few-shot learning desirable in medical image analysis is the efficient use of the support image data, which are labelled to classify or segment new classes, a task that otherwise requires substantially more training images and expert annotations. This work describes a fully 3D prototypical few-shot segmentation algorithm, such that the trained networks can be effectively adapted to clinically interesting structures that are absent in training, using only a few labelled images from a different institute. First, to compensate for the widely recognised spatial variability between institutions in episodic adaptation of novel classes, a novel spatial registration mechanism is integrated into prototypical learning, consisting of a segmentation head and an spatial alignment module. Second, to assist the training with observed imperfect alignment, support mask conditioning module is proposed to further utilise the annotation available from the support images. Extensive experiments are presented in an application of segmenting eight anatomical structures important for interventional planning, using a data set of 589 pelvic T2-weighted MR images, acquired at seven institutes. The results demonstrate the efficacy in each of the 3D formulation, the spatial registration, and the support mask conditioning, all of which made positive contributions independently or collectively. Compared with the previously proposed 2D alternatives, the few-shot segmentation performance was improved with statistical significance, regardless whether the support data come from the same or different institutes.
A Unified Study of Machine Learning Explanation Evaluation Metrics
Mar 27, 2022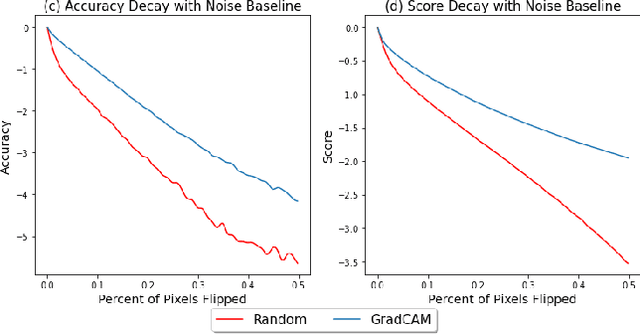

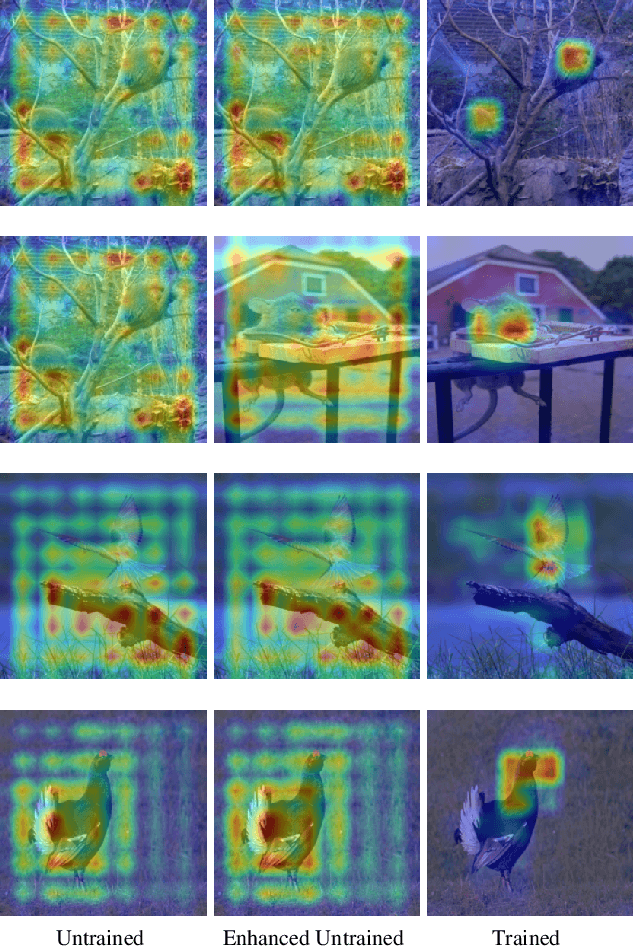

The growing need for trustworthy machine learning has led to the blossom of interpretability research. Numerous explanation methods have been developed to serve this purpose. However, these methods are deficiently and inappropriately evaluated. Many existing metrics for explanations are introduced by researchers as by-products of their proposed explanation techniques to demonstrate the advantages of their methods. Although widely used, they are more or less accused of problems. We claim that the lack of acknowledged and justified metrics results in chaos in benchmarking these explanation methods -- Do we really have good/bad explanation when a metric gives a high/low score? We split existing metrics into two categories and demonstrate that they are insufficient to properly evaluate explanations for multiple reasons. We propose guidelines in dealing with the problems in evaluating machine learning explanation and encourage researchers to carefully deal with these problems when developing explanation techniques and metrics.
Self-Interpretable Model with TransformationEquivariant Interpretation
Nov 09, 2021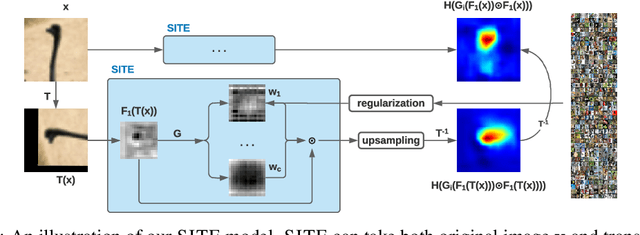



In this paper, we propose a self-interpretable model SITE with transformation-equivariant interpretations. We focus on the robustness and self-consistency of the interpretations of geometric transformations. Apart from the transformation equivariance, as a self-interpretable model, SITE has comparable expressive power as the benchmark black-box classifiers, while being able to present faithful and robust interpretations with high quality. It is worth noticing that although applied in most of the CNN visualization methods, the bilinear upsampling approximation is a rough approximation, which can only provide interpretations in the form of heatmaps (instead of pixel-wise). It remains an open question whether such interpretations can be direct to the input space (as shown in the MNIST experiments). Besides, we consider the translation and rotation transformations in our model. In future work, we will explore the robust interpretations under more complex transformations such as scaling and distortion. Moreover, we clarify that SITE is not limited to geometric transformation (that we used in the computer vision domain), and will explore SITEin other domains in future work.
Gland Instance Segmentation Using Deep Multichannel Neural Networks
Nov 23, 2017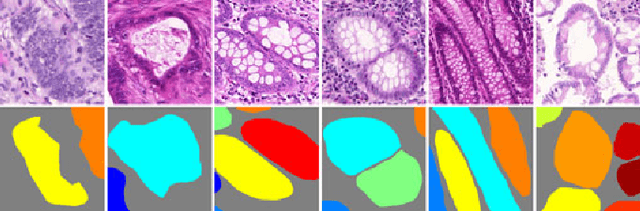

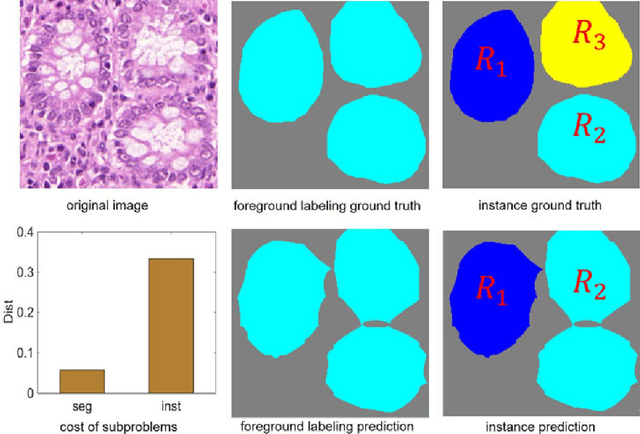
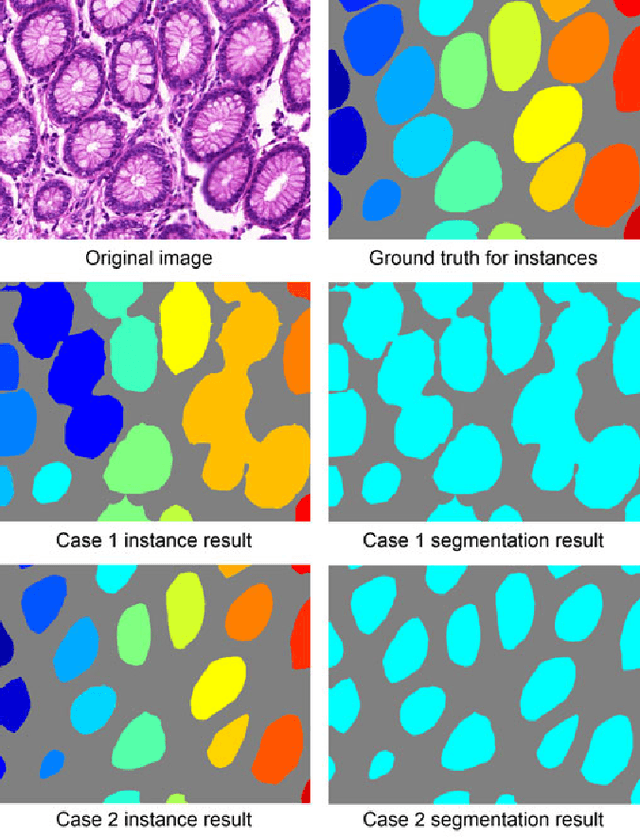
Objective: A new image instance segmentation method is proposed to segment individual glands (instances) in colon histology images. This process is challenging since the glands not only need to be segmented from a complex background, they must also be individually identified. Methods: We leverage the idea of image-to-image prediction in recent deep learning by designing an algorithm that automatically exploits and fuses complex multichannel information - regional, location, and boundary cues - in gland histology images. Our proposed algorithm, a deep multichannel framework, alleviates heavy feature design due to the use of convolutional neural networks and is able to meet multifarious requirements by altering channels. Results: Compared with methods reported in the 2015 MICCAI Gland Segmentation Challenge and other currently prevalent instance segmentation methods, we observe state-of-the-art results based on the evaluation metrics. Conclusion: The proposed deep multichannel algorithm is an effective method for gland instance segmentation. Significance: The generalization ability of our model not only enable the algorithm to solve gland instance segmentation problems, but the channel is also alternative that can be replaced for a specific task.
* arXiv admin note: substantial text overlap with arXiv:1607.04889
Learning Multi-level Features For Sensor-based Human Action Recognition
Sep 02, 2017
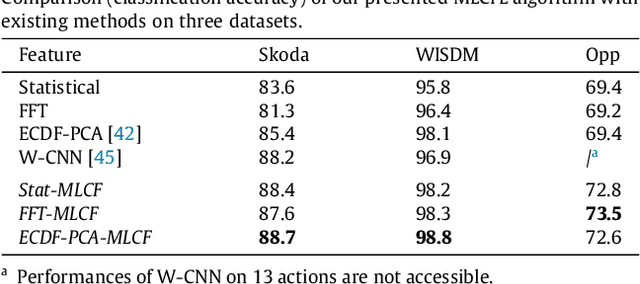
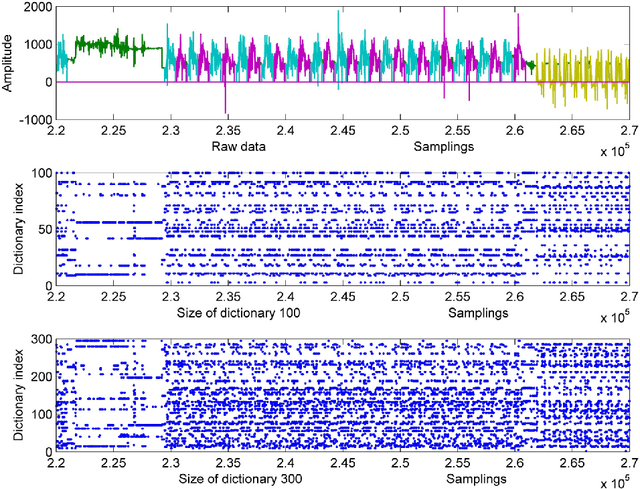
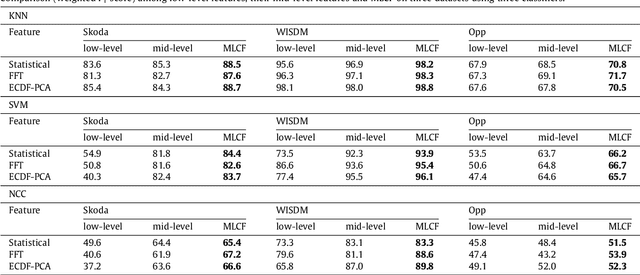
This paper proposes a multi-level feature learning framework for human action recognition using a single body-worn inertial sensor. The framework consists of three phases, respectively designed to analyze signal-based (low-level), components (mid-level) and semantic (high-level) information. Low-level features capture the time and frequency domain property while mid-level representations learn the composition of the action. The Max-margin Latent Pattern Learning (MLPL) method is proposed to learn high-level semantic descriptions of latent action patterns as the output of our framework. The proposed method achieves the state-of-the-art performances, 88.7%, 98.8% and 72.6% (weighted F1 score) respectively, on Skoda, WISDM and OPP datasets.
* 26 pages, 23 figures
End-to-End Subtitle Detection and Recognition for Videos in East Asian Languages via CNN Ensemble with Near-Human-Level Performance
Nov 18, 2016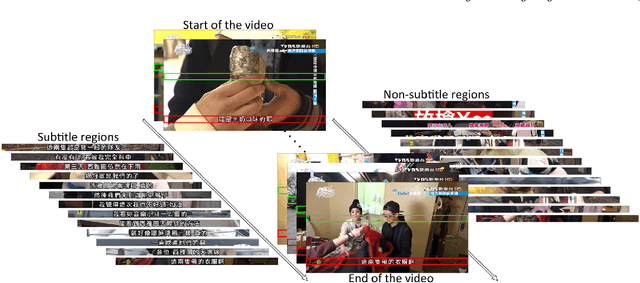
In this paper, we propose an innovative end-to-end subtitle detection and recognition system for videos in East Asian languages. Our end-to-end system consists of multiple stages. Subtitles are firstly detected by a novel image operator based on the sequence information of consecutive video frames. Then, an ensemble of Convolutional Neural Networks (CNNs) trained on synthetic data is adopted for detecting and recognizing East Asian characters. Finally, a dynamic programming approach leveraging language models is applied to constitute results of the entire body of text lines. The proposed system achieves average end-to-end accuracies of 98.2% and 98.3% on 40 videos in Simplified Chinese and 40 videos in Traditional Chinese respectively, which is a significant outperformance of other existing methods. The near-perfect accuracy of our system dramatically narrows the gap between human cognitive ability and state-of-the-art algorithms used for such a task.