 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiyang Wu
AGL-NET: Aerial-Ground Cross-Modal Global Localization with Varying Scales
Apr 04, 2024
We present AGL-NET, a novel learning-based method for global localization using LiDAR point clouds and satellite maps. AGL-NET tackles two critical challenges: bridging the representation gap between image and points modalities for robust feature matching, and handling inherent scale discrepancies between global view and local view. To address these challenges, AGL-NET leverages a unified network architecture with a novel two-stage matching design. The first stage extracts informative neural features directly from raw sensor data and performs initial feature matching. The second stage refines this matching process by extracting informative skeleton features and incorporating a novel scale alignment step to rectify scale variations between LiDAR and map data. Furthermore, a novel scale and skeleton loss function guides the network toward learning scale-invariant feature representations, eliminating the need for pre-processing satellite maps. This significantly improves real-world applicability in scenarios with unknown map scales. To facilitate rigorous performance evaluation, we introduce a meticulously designed dataset within the CARLA simulator specifically tailored for metric localization training and assessment. The code and dataset will be made publicly available.
On the Safety Concerns of Deploying LLMs/VLMs in Robotics: Highlighting the Risks and Vulnerabilities
Feb 24, 2024In this paper, we highlight the critical issues of robustness and safety associated with integrating large language models (LLMs) and vision-language models (VLMs) into robotics applications. Recent works have focused on using LLMs and VLMs to improve the performance of robotics tasks, such as manipulation, navigation, etc. However, such integration can introduce significant vulnerabilities, in terms of their susceptibility to adversarial attacks due to the language models, potentially leading to catastrophic consequences. By examining recent works at the interface of LLMs/VLMs and robotics, we show that it is easy to manipulate or misguide the robot's actions, leading to safety hazards. We define and provide examples of several plausible adversarial attacks, and conduct experiments on three prominent robot frameworks integrated with a language model, including KnowNo VIMA, and Instruct2Act, to assess their susceptibility to these attacks. Our empirical findings reveal a striking vulnerability of LLM/VLM-robot integrated systems: simple adversarial attacks can significantly undermine the effectiveness of LLM/VLM-robot integrated systems. Specifically, our data demonstrate an average performance deterioration of 21.2% under prompt attacks and a more alarming 30.2% under perception attacks. These results underscore the critical need for robust countermeasures to ensure the safe and reliable deployment of the advanced LLM/VLM-based robotic systems.
LANCAR: Leveraging Language for Context-Aware Robot Locomotion in Unstructured Environments
Sep 30, 2023Robotic locomotion is a challenging task, especially in unstructured terrains. In practice, the optimal locomotion policy can be context-dependent by using the contextual information of encountered terrains in decision-making. Humans can interpret the environmental context for robots, but the ambiguity of human language makes it challenging to use in robot locomotion directly. In this paper, we propose a novel approach, LANCAR, that introduces a context translator that works with reinforcement learning (RL) agents for context-aware locomotion. Our formulation allows a robot to interpret the contextual information from environments generated by human observers or Vision-Language Models (VLM) with Large Language Models (LLM) and use this information to generate contextual embeddings. We incorporate the contextual embeddings with the robot's internal environmental observations as the input to the RL agent's decision neural network. We evaluate LANCAR with contextual information in varying ambiguity levels and compare its performance using several alternative approaches. Our experimental results demonstrate that our approach exhibits good generalizability and adaptability across diverse terrains, by achieving at least 10% of performance improvement in episodic reward over baselines. The experiment video can be found at the following link: https://raaslab.org/projects/LLM_Context_Estimation/.
iPLAN: Intent-Aware Planning in Heterogeneous Traffic via Distributed Multi-Agent Reinforcement Learning
Jun 09, 2023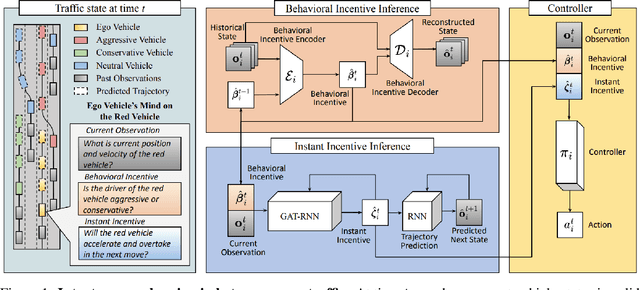
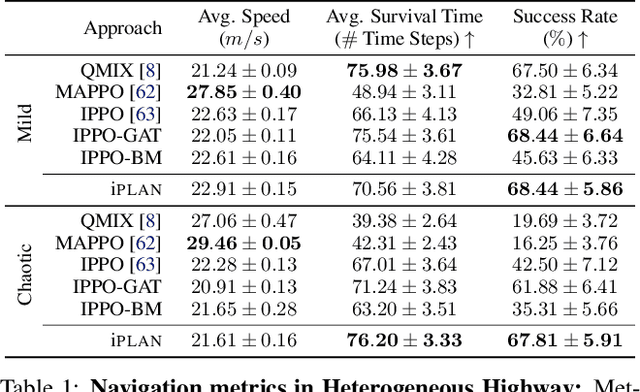
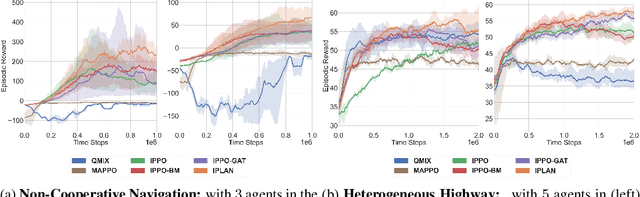
Navigating safely and efficiently in dense and heterogeneous traffic scenarios is challenging for autonomous vehicles (AVs) due to their inability to infer the behaviors or intentions of nearby drivers. In this work, we propose a distributed multi-agent reinforcement learning (MARL) algorithm with trajectory and intent prediction in dense and heterogeneous traffic scenarios. Our approach for intent-aware planning, iPLAN, allows agents to infer nearby drivers' intents solely from their local observations. We model two distinct incentives for agents' strategies: Behavioral incentives for agents' long-term planning based on their driving behavior or personality; Instant incentives for agents' short-term planning for collision avoidance based on the current traffic state. We design a two-stream inference module that allows agents to infer their opponents' incentives and incorporate their inferred information into decision-making. We perform experiments on two simulation environments, Non-Cooperative Navigation and Heterogeneous Highway. In Heterogeneous Highway, results show that, compared with centralized MARL baselines such as QMIX and MAPPO, our method yields a 4.0% and 35.7% higher episodic reward in mild and chaotic traffic, with 48.1% higher success rate and 80.6% longer survival time in chaotic traffic. We also compare with a decentralized baseline IPPO and demonstrate a higher episodic reward of 9.2% and 10.3% in mild traffic and chaotic traffic, 25.3% higher success rate, and 13.7% longer survival time.
FireCommander: An Interactive, Probabilistic Multi-agent Environment for Joint Perception-Action Tasks
Oct 31, 2020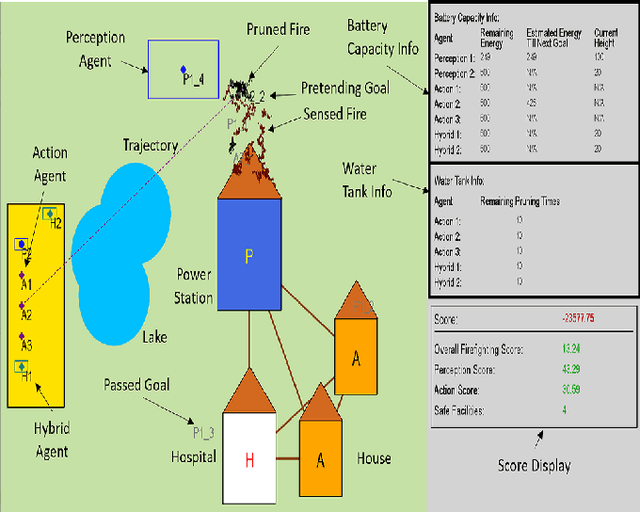

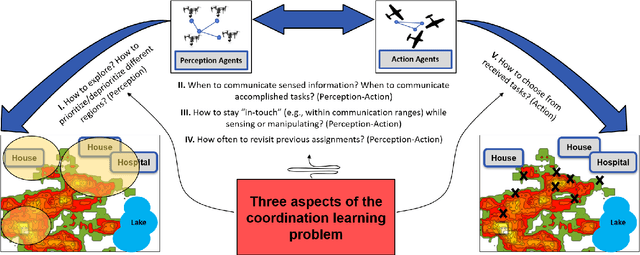

The purpose of this tutorial is to help individuals use the \underline{FireCommander} game environment for research applications. The FireCommander is an interactive, probabilistic joint perception-action reconnaissance environment in which a composite team of agents (e.g., robots) cooperate to fight dynamic, propagating firespots (e.g., targets). In FireCommander game, a team of agents must be tasked to optimally deal with a wildfire situation in an environment with propagating fire areas and some facilities such as houses, hospitals, power stations, etc. The team of agents can accomplish their mission by first sensing (e.g., estimating fire states), communicating the sensed fire-information among each other and then taking action to put the firespots out based on the sensed information (e.g., dropping water on estimated fire locations). The FireCommander environment can be useful for research topics spanning a wide range of applications from Reinforcement Learning (RL) and Learning from Demonstration (LfD), to Coordination, Psychology, Human-Robot Interaction (HRI) and Teaming. There are four important facets of the FireCommander environment that overall, create a non-trivial game: (1) Complex Objectives: Multi-objective Stochastic Environment, (2)Probabilistic Environment: Agents' actions result in probabilistic performance, (3) Hidden Targets: Partially Observable Environment and, (4) Uni-task Robots: Perception-only and Action-only agents. The FireCommander environment is first-of-its-kind in terms of including Perception-only and Action-only agents for coordination. It is a general multi-purpose game that can be useful in a variety of combinatorial optimization problems and stochastic games, such as applications of Reinforcement Learning (RL), Learning from Demonstration (LfD) and Inverse RL (iRL).