 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYi Su
VISION2UI: A Real-World Dataset with Layout for Code Generation from UI Designs
Apr 09, 2024
Automatically generating UI code from webpage design visions can significantly alleviate the burden of developers, enabling beginner developers or designers to directly generate Web pages from design diagrams. Currently, prior research has accomplished the objective of generating UI code from rudimentary design visions or sketches through designing deep neural networks. Inspired by the groundbreaking advancements achieved by Multimodal Large Language Models (MLLMs), the automatic generation of UI code from high-fidelity design images is now emerging as a viable possibility. Nevertheless, our investigation reveals that existing MLLMs are hampered by the scarcity of authentic, high-quality, and large-scale datasets, leading to unsatisfactory performance in automated UI code generation. To mitigate this gap, we present a novel dataset, termed VISION2UI, extracted from real-world scenarios, augmented with comprehensive layout information, tailored specifically for finetuning MLLMs in UI code generation. Specifically, this dataset is derived through a series of operations, encompassing collecting, cleaning, and filtering of the open-source Common Crawl dataset. In order to uphold its quality, a neural scorer trained on labeled samples is utilized to refine the data, retaining higher-quality instances. Ultimately, this process yields a dataset comprising 2,000 (Much more is coming soon) parallel samples encompassing design visions and UI code. The dataset is available at https://huggingface.co/datasets/xcodemind/vision2ui.
Online Feature Updates Improve Online (Generalized) Label Shift Adaptation
Feb 05, 2024This paper addresses the prevalent issue of label shift in an online setting with missing labels, where data distributions change over time and obtaining timely labels is challenging. While existing methods primarily focus on adjusting or updating the final layer of a pre-trained classifier, we explore the untapped potential of enhancing feature representations using unlabeled data at test-time. Our novel method, Online Label Shift adaptation with Online Feature Updates (OLS-OFU), leverages self-supervised learning to refine the feature extraction process, thereby improving the prediction model. Theoretical analyses confirm that OLS-OFU reduces algorithmic regret by capitalizing on self-supervised learning for feature refinement. Empirical studies on various datasets, under both online label shift and generalized label shift conditions, underscore the effectiveness and robustness of OLS-OFU, especially in cases of domain shifts.
KGLens: A Parameterized Knowledge Graph Solution to Assess What an LLM Does and Doesn't Know
Dec 15, 2023Current approaches to evaluating large language models (LLMs) with pre-existing Knowledge Graphs (KG) mostly ignore the structure of the KG and make arbitrary choices of which part of the graph to evaluate. In this paper, we introduce KGLens, a method to evaluate LLMs by generating natural language questions from a KG in a structure aware manner so that we can characterize its performance on a more aggregated level. KGLens uses a parameterized KG, where each edge is augmented with a beta distribution that guides how to sample edges from the KG for QA testing. As the evaluation proceeds, different edges of the parameterized KG are sampled and assessed appropriately, converging to a more global picture of the performance of the LLMs on the KG as a whole. In our experiments, we construct three domain-specific KGs for knowledge assessment, comprising over 19,000 edges, 700 relations, and 21,000 entities. The results demonstrate that KGLens can not only assess overall performance but also provide topic, temporal, and relation analyses of LLMs. This showcases the adaptability and customizability of KGLens, emphasizing its ability to focus the evaluation based on specific criteria.
A Novel Hybrid Ordinal Learning Model with Health Care Application
Dec 15, 2023
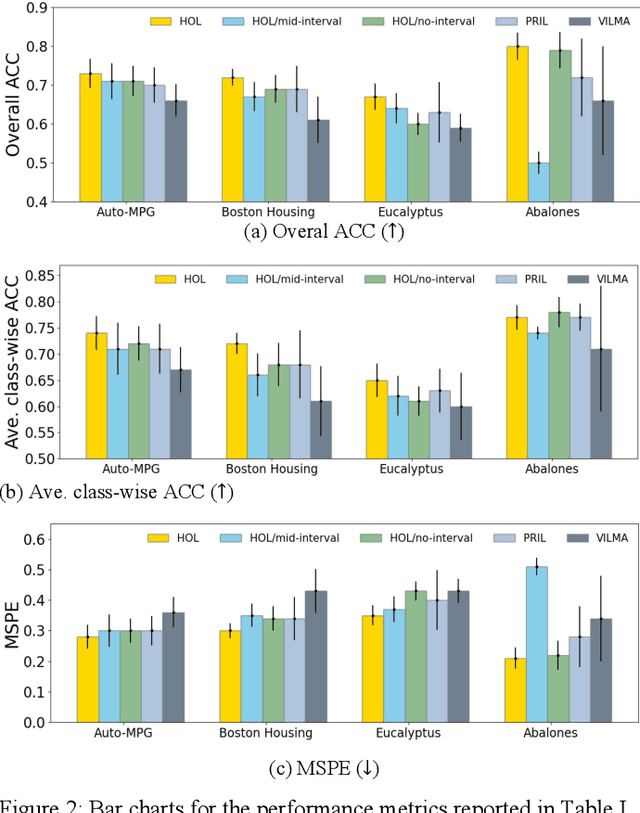

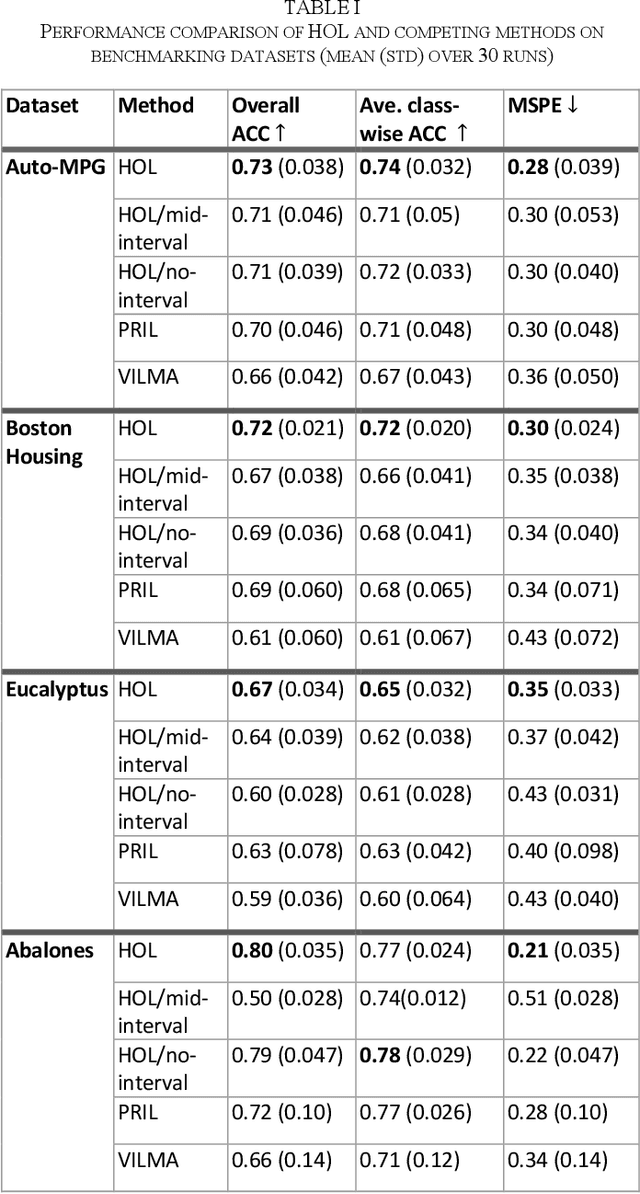
Ordinal learning (OL) is a type of machine learning models with broad utility in health care applications such as diagnosis of different grades of a disease (e.g., mild, modest, severe) and prediction of the speed of disease progression (e.g., very fast, fast, moderate, slow). This paper aims to tackle a situation when precisely labeled samples are limited in the training set due to cost or availability constraints, whereas there could be an abundance of samples with imprecise labels. We focus on imprecise labels that are intervals, i.e., one can know that a sample belongs to an interval of labels but cannot know which unique label it has. This situation is quite common in health care datasets due to limitations of the diagnostic instrument, sparse clinical visits, or/and patient dropout. Limited research has been done to develop OL models with imprecise/interval labels. We propose a new Hybrid Ordinal Learner (HOL) to integrate samples with both precise and interval labels to train a robust OL model. We also develop a tractable and efficient optimization algorithm to solve the HOL formulation. We compare HOL with several recently developed OL methods on four benchmarking datasets, which demonstrate the superior performance of HOL. Finally, we apply HOL to a real-world dataset for predicting the speed of progressing to Alzheimer's Disease (AD) for individuals with Mild Cognitive Impairment (MCI) based on a combination of multi-modality neuroimaging and demographic/clinical datasets. HOL achieves high accuracy in the prediction and outperforms existing methods. The capability of accurately predicting the speed of progression to AD for each individual with MCI has the potential for helping facilitate more individually-optimized interventional strategies.
Leveraging Large Language Models for Exploiting ASR Uncertainty
Sep 12, 2023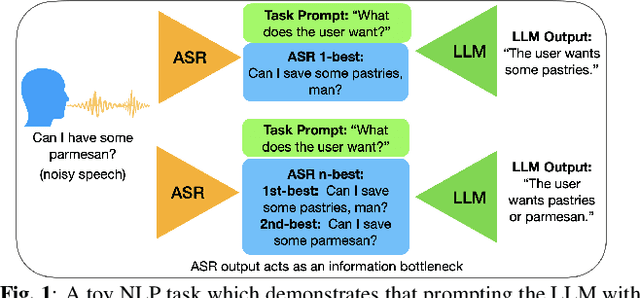
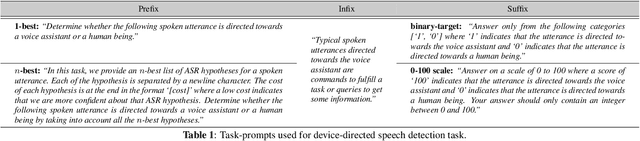

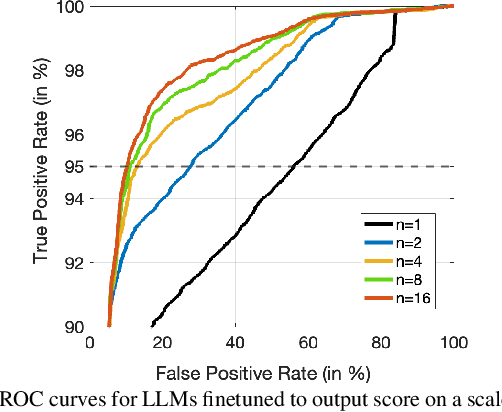
While large language models excel in a variety of natural language processing (NLP) tasks, to perform well on spoken language understanding (SLU) tasks, they must either rely on off-the-shelf automatic speech recognition (ASR) systems for transcription, or be equipped with an in-built speech modality. This work focuses on the former scenario, where LLM's accuracy on SLU tasks is constrained by the accuracy of a fixed ASR system on the spoken input. Specifically, we tackle speech-intent classification task, where a high word-error-rate can limit the LLM's ability to understand the spoken intent. Instead of chasing a high accuracy by designing complex or specialized architectures regardless of deployment costs, we seek to answer how far we can go without substantially changing the underlying ASR and LLM, which can potentially be shared by multiple unrelated tasks. To this end, we propose prompting the LLM with an n-best list of ASR hypotheses instead of only the error-prone 1-best hypothesis. We explore prompt-engineering to explain the concept of n-best lists to the LLM; followed by the finetuning of Low-Rank Adapters on the downstream tasks. Our approach using n-best lists proves to be effective on a device-directed speech detection task as well as on a keyword spotting task, where systems using n-best list prompts outperform those using 1-best ASR hypothesis; thus paving the way for an efficient method to exploit ASR uncertainty via LLMs for speech-based applications.
Intensity-free Convolutional Temporal Point Process: Incorporating Local and Global Event Contexts
Jun 24, 2023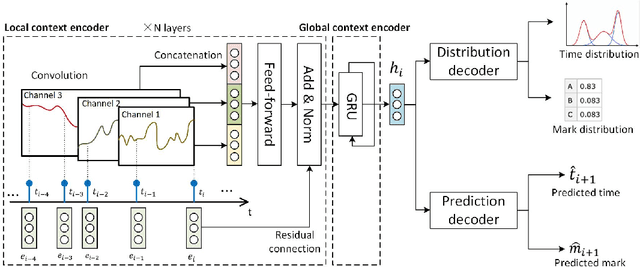
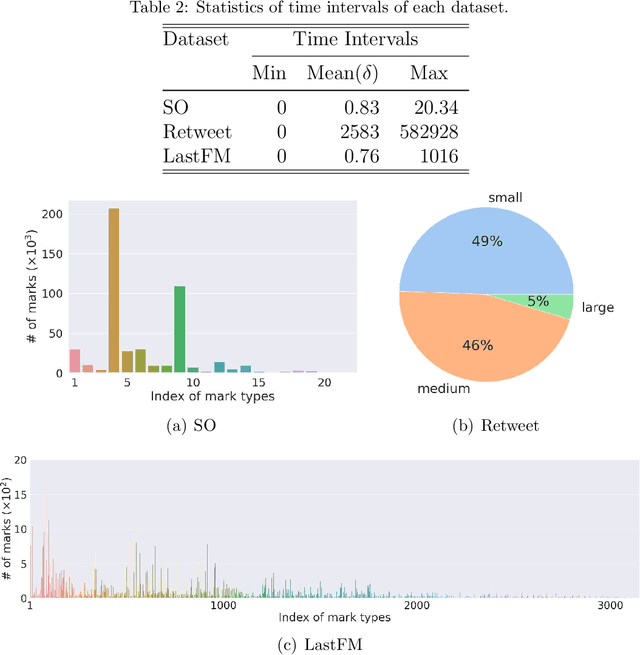
Event prediction in the continuous-time domain is a crucial but rather difficult task. Temporal point process (TPP) learning models have shown great advantages in this area. Existing models mainly focus on encoding global contexts of events using techniques like recurrent neural networks (RNNs) or self-attention mechanisms. However, local event contexts also play an important role in the occurrences of events, which has been largely ignored. Popular convolutional neural networks, which are designated for local context capturing, have never been applied to TPP modelling due to their incapability of modelling in continuous time. In this work, we propose a novel TPP modelling approach that combines local and global contexts by integrating a continuous-time convolutional event encoder with an RNN. The presented framework is flexible and scalable to handle large datasets with long sequences and complex latent patterns. The experimental result shows that the proposed model improves the performance of probabilistic sequential modelling and the accuracy of event prediction. To our best knowledge, this is the first work that applies convolutional neural networks to TPP modelling.
Unified Off-Policy Learning to Rank: a Reinforcement Learning Perspective
Jun 13, 2023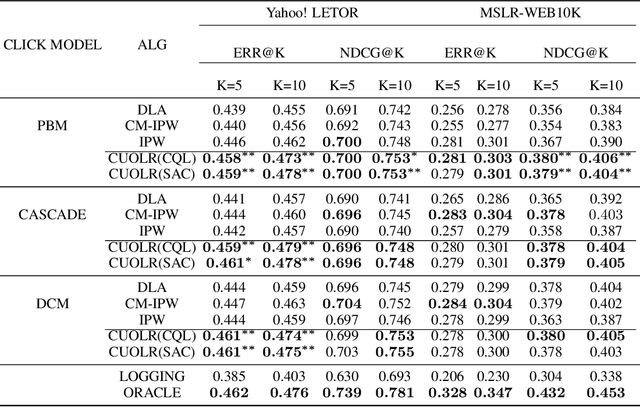
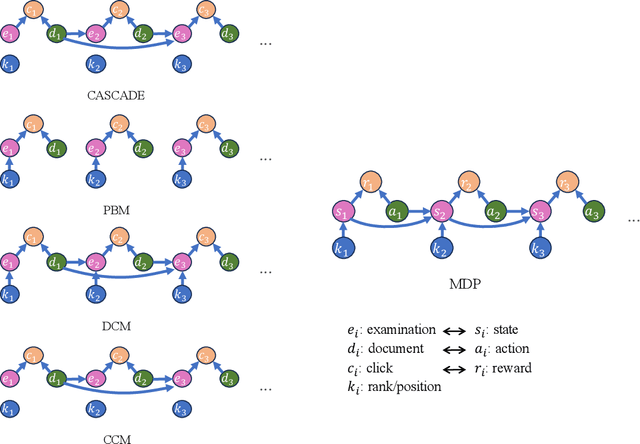
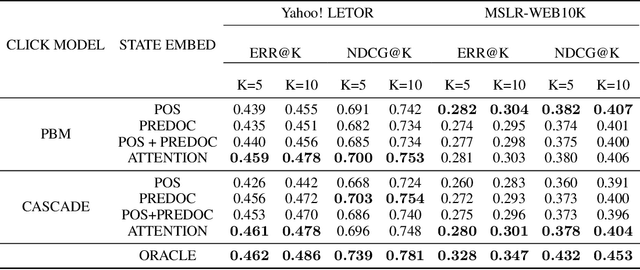
Off-policy Learning to Rank (LTR) aims to optimize a ranker from data collected by a deployed logging policy. However, existing off-policy learning to rank methods often make strong assumptions about how users generate the click data, i.e., the click model, and hence need to tailor their methods specifically under different click models. In this paper, we unified the ranking process under general stochastic click models as a Markov Decision Process (MDP), and the optimal ranking could be learned with offline reinforcement learning (RL) directly. Building upon this, we leverage offline RL techniques for off-policy LTR and propose the Click Model-Agnostic Unified Off-policy Learning to Rank (CUOLR) method, which could be easily applied to a wide range of click models. Through a dedicated formulation of the MDP, we show that offline RL algorithms can adapt to various click models without complex debiasing techniques and prior knowledge of the model. Results on various large-scale datasets demonstrate that CUOLR consistently outperforms the state-of-the-art off-policy learning to rank algorithms while maintaining consistency and robustness under different click models.
Value of Exploration: Measurements, Findings and Algorithms
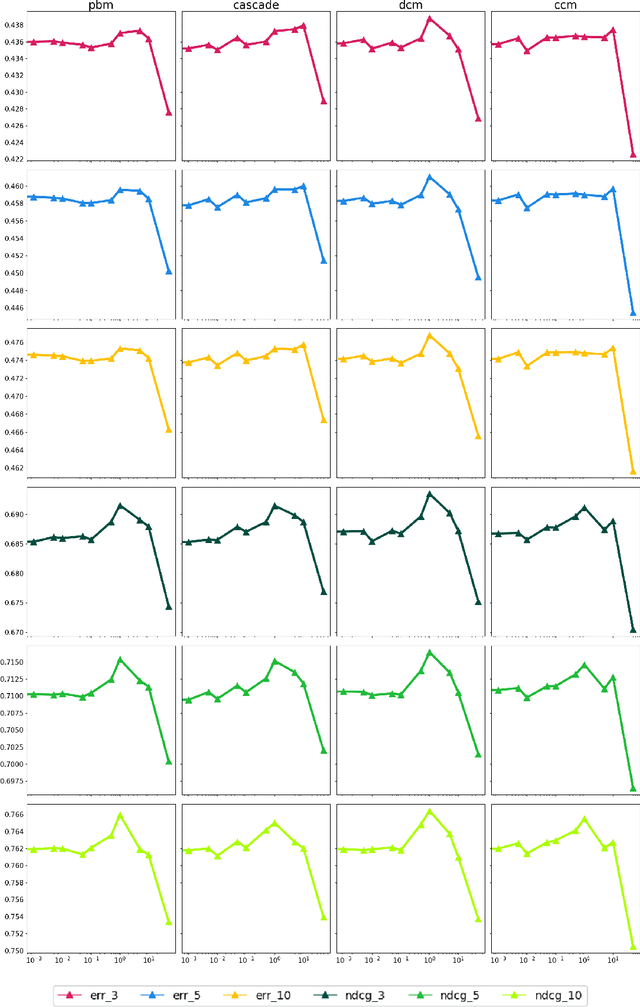
May 12, 2023

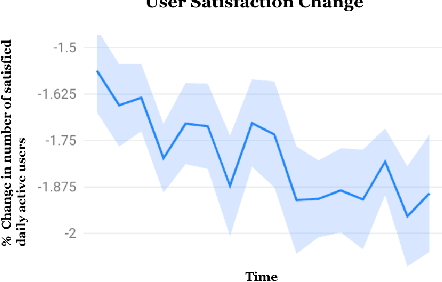
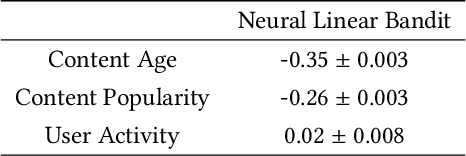
Effective exploration is believed to positively influence the long-term user experience on recommendation platforms. Determining its exact benefits, however, has been challenging. Regular A/B tests on exploration often measure neutral or even negative engagement metrics while failing to capture its long-term benefits. To address this, we present a systematic study to formally quantify the value of exploration by examining its effects on the content corpus, a key entity in the recommender system that directly affects user experiences. Specifically, we introduce new metrics and the associated experiment design to measure the benefit of exploration on the corpus change, and further connect the corpus change to the long-term user experience. Furthermore, we investigate the possibility of introducing the Neural Linear Bandit algorithm to build an exploration-based ranking system, and use it as the backbone algorithm for our case study. We conduct extensive live experiments on a large-scale commercial recommendation platform that serves billions of users to validate the new experiment designs, quantify the long-term values of exploration, and to verify the effectiveness of the adopted neural linear bandit algorithm for exploration.
Test-Time Adaptation with Perturbation Consistency Learning
Apr 25, 2023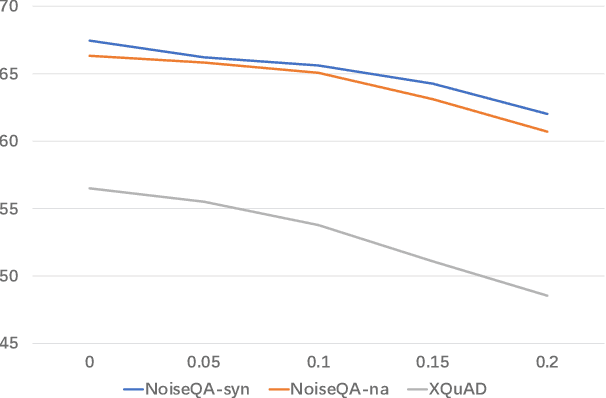
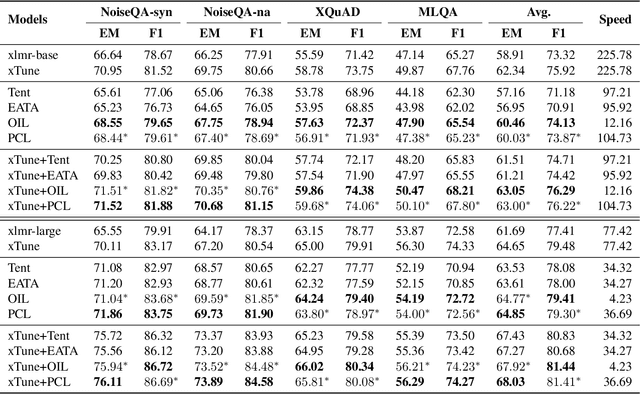
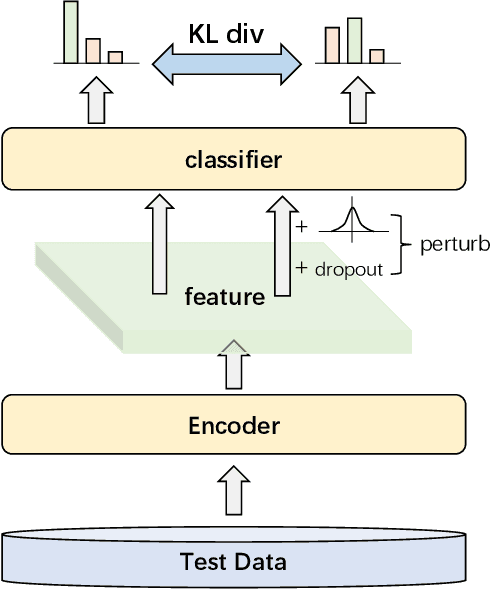
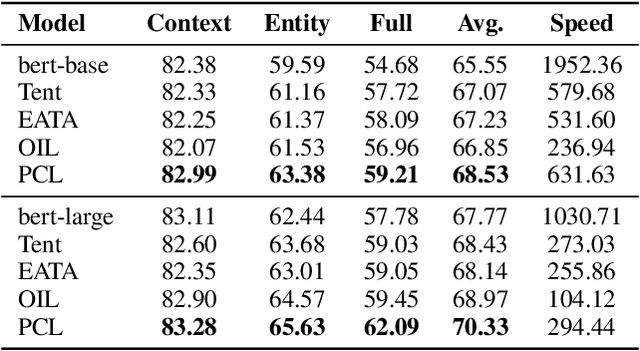
Currently, pre-trained language models (PLMs) do not cope well with the distribution shift problem, resulting in models trained on the training set failing in real test scenarios. To address this problem, the test-time adaptation (TTA) shows great potential, which updates model parameters to suit the test data at the testing time. Existing TTA methods rely on well-designed auxiliary tasks or self-training strategies based on pseudo-label. However, these methods do not achieve good trade-offs regarding performance gains and computational costs. To obtain some insights into such a dilemma, we take two representative TTA methods, i.e., Tent and OIL, for exploration and find that stable prediction is the key to achieving a good balance. Accordingly, in this paper, we propose perturbation consistency learning (PCL), a simple test-time adaptation method to promote the model to make stable predictions for samples with distribution shifts. Extensive experiments on adversarial robustness and cross-lingual transferring demonstrate that our method can achieve higher or comparable performance with less inference time over strong PLM backbones and previous state-of-the-art TTA methods.
A Surface-Based Federated Chow Test Model for Integrating APOE Status, Tau Deposition Measure, and Hippocampal Surface Morphometry
Mar 31, 2023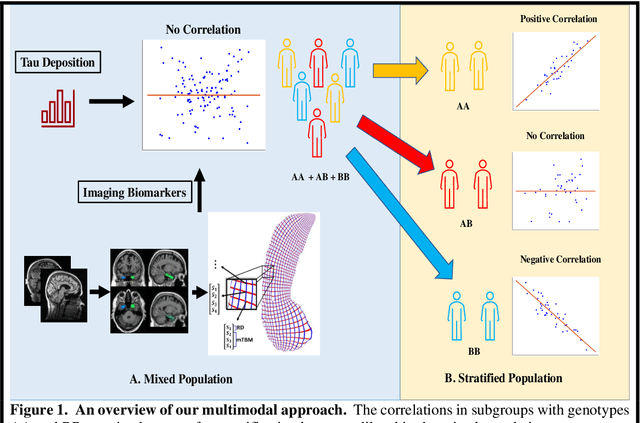
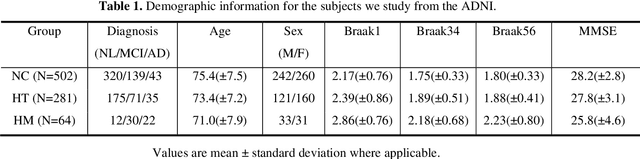
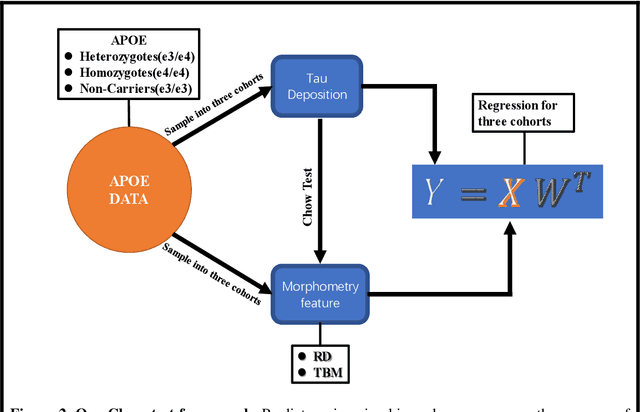
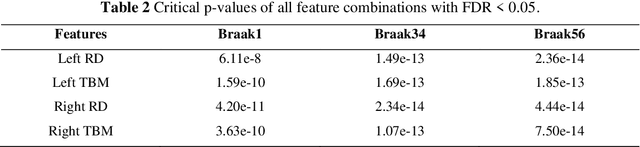
Background: Alzheimer's Disease (AD) is the most common type of age-related dementia, affecting 6.2 million people aged 65 or older according to CDC data. It is commonly agreed that discovering an effective AD diagnosis biomarker could have enormous public health benefits, potentially preventing or delaying up to 40% of dementia cases. Tau neurofibrillary tangles are the primary driver of downstream neurodegeneration and subsequent cognitive impairment in AD, resulting in structural deformations such as hippocampal atrophy that can be observed in magnetic resonance imaging (MRI) scans. Objective: To build a surface-based model to 1) detect differences between APOE subgroups in patterns of tau deposition and hippocampal atrophy, and 2) use the extracted surface-based features to predict cognitive decline. Methods: Using data obtained from different institutions, we develop a surface-based federated Chow test model to study the synergistic effects of APOE, a previously reported significant risk factor of AD, and tau on hippocampal surface morphometry. Results: We illustrate that the APOE-specific morphometry features correlate with AD progression and better predict future AD conversion than other MRI biomarkers. For example, a strong association between atrophy and abnormal tau was identified in hippocampal subregion cornu ammonis 1 (CA1 subfield) and subiculum in e4 homozygote cohort. Conclusion: Our model allows for identifying MRI biomarkers for AD and cognitive decline prediction and may uncover a corner of the neural mechanism of the influence of APOE and tau deposition on hippocampal morphology.