 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKilian Q. Weinberger
Don't Trust: Verify -- Grounding LLM Quantitative Reasoning with Autoformalization
Mar 26, 2024
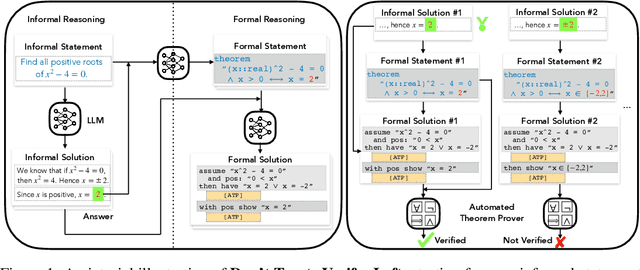
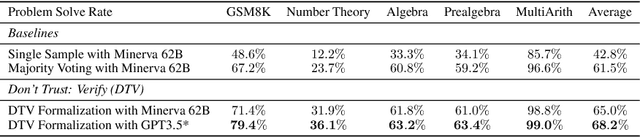

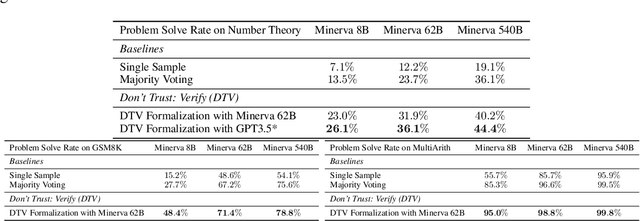
Large language models (LLM), such as Google's Minerva and OpenAI's GPT families, are becoming increasingly capable of solving mathematical quantitative reasoning problems. However, they still make unjustified logical and computational errors in their reasoning steps and answers. In this paper, we leverage the fact that if the training corpus of LLMs contained sufficiently many examples of formal mathematics (e.g. in Isabelle, a formal theorem proving environment), they can be prompted to translate i.e. autoformalize informal mathematical statements into formal Isabelle code -- which can be verified automatically for internal consistency. This provides a mechanism to automatically reject solutions whose formalized versions are inconsistent within themselves or with the formalized problem statement. We evaluate our method on GSM8K, MATH and MultiArith datasets and demonstrate that our approach provides a consistently better heuristic than vanilla majority voting -- the previously best method to identify correct answers, by more than 12% on GSM8K. In our experiments it improves results consistently across all datasets and LLM model sizes. The code can be found at https://github.com/jinpz/dtv.
Zero-shot Object-Level OOD Detection with Context-Aware Inpainting
Feb 07, 2024Machine learning algorithms are increasingly provided as black-box cloud services or pre-trained models, without access to their training data. This motivates the problem of zero-shot out-of-distribution (OOD) detection. Concretely, we aim to detect OOD objects that do not belong to the classifier's label set but are erroneously classified as in-distribution (ID) objects. Our approach, RONIN, uses an off-the-shelf diffusion model to replace detected objects with inpainting. RONIN conditions the inpainting process with the predicted ID label, drawing the input object closer to the in-distribution domain. As a result, the reconstructed object is very close to the original in the ID cases and far in the OOD cases, allowing RONIN to effectively distinguish ID and OOD samples. Throughout extensive experiments, we demonstrate that RONIN achieves competitive results compared to previous approaches across several datasets, both in zero-shot and non-zero-shot settings.
Online Feature Updates Improve Online (Generalized) Label Shift Adaptation
Feb 05, 2024This paper addresses the prevalent issue of label shift in an online setting with missing labels, where data distributions change over time and obtaining timely labels is challenging. While existing methods primarily focus on adjusting or updating the final layer of a pre-trained classifier, we explore the untapped potential of enhancing feature representations using unlabeled data at test-time. Our novel method, Online Label Shift adaptation with Online Feature Updates (OLS-OFU), leverages self-supervised learning to refine the feature extraction process, thereby improving the prediction model. Theoretical analyses confirm that OLS-OFU reduces algorithmic regret by capitalizing on self-supervised learning for feature refinement. Empirical studies on various datasets, under both online label shift and generalized label shift conditions, underscore the effectiveness and robustness of OLS-OFU, especially in cases of domain shifts.
Reward Finetuning for Faster and More Accurate Unsupervised Object Discovery
Nov 05, 2023Recent advances in machine learning have shown that Reinforcement Learning from Human Feedback (RLHF) can improve machine learning models and align them with human preferences. Although very successful for Large Language Models (LLMs), these advancements have not had a comparable impact in research for autonomous vehicles -- where alignment with human expectations can be imperative. In this paper, we propose to adapt similar RL-based methods to unsupervised object discovery, i.e. learning to detect objects from LiDAR points without any training labels. Instead of labels, we use simple heuristics to mimic human feedback. More explicitly, we combine multiple heuristics into a simple reward function that positively correlates its score with bounding box accuracy, i.e., boxes containing objects are scored higher than those without. We start from the detector's own predictions to explore the space and reinforce boxes with high rewards through gradient updates. Empirically, we demonstrate that our approach is not only more accurate, but also orders of magnitudes faster to train compared to prior works on object discovery.
Correction with Backtracking Reduces Hallucination in Summarization
Oct 31, 2023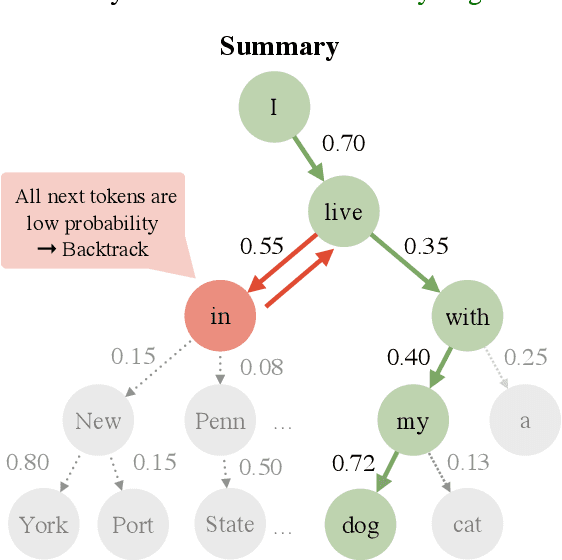
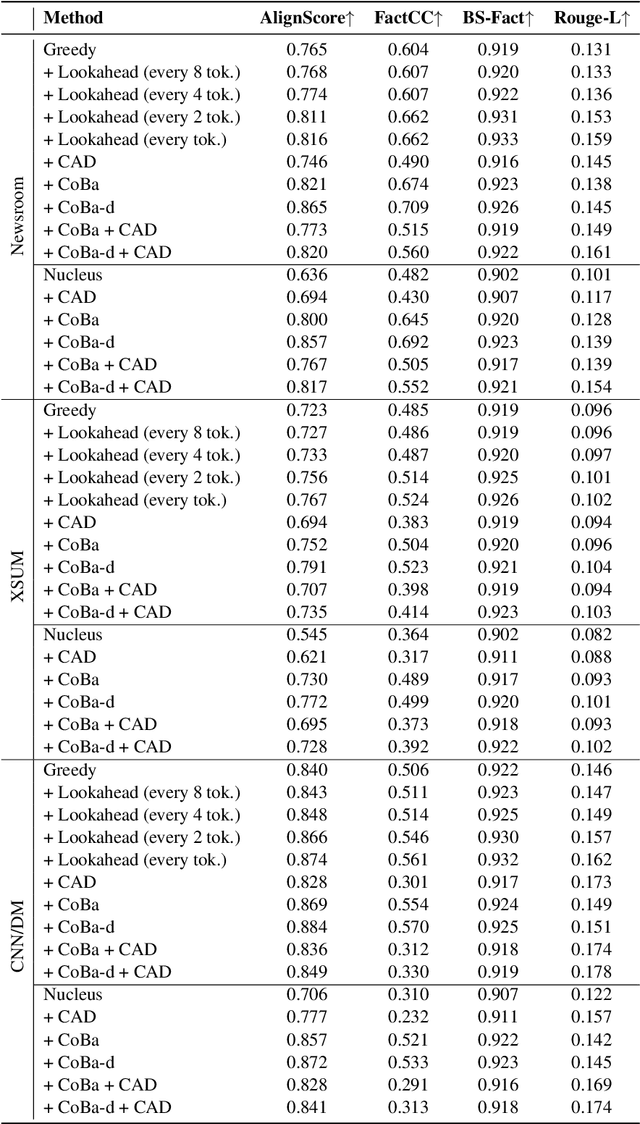
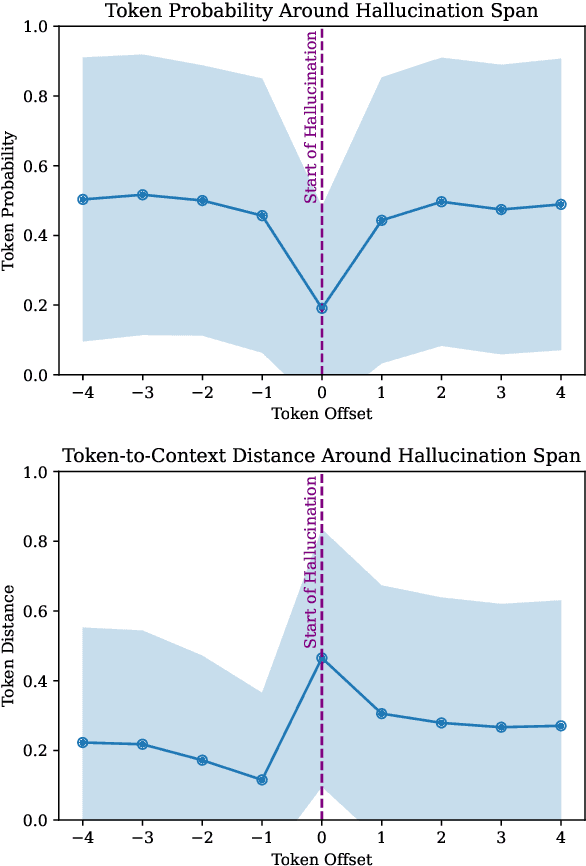
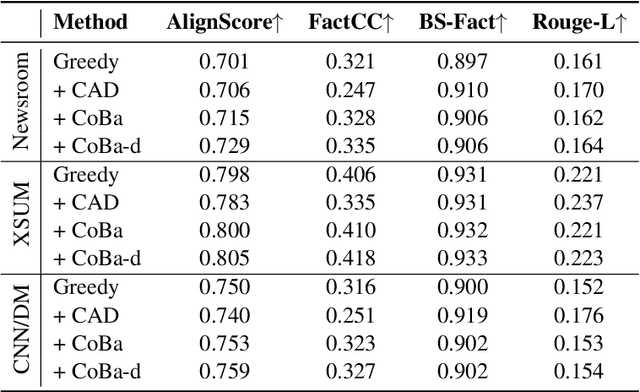
Abstractive summarization aims at generating natural language summaries of a source document that are succinct while preserving the important elements. Despite recent advances, neural text summarization models are known to be susceptible to hallucinating (or more correctly confabulating), that is to produce summaries with details that are not grounded in the source document. In this paper, we introduce a simple yet efficient technique, CoBa, to reduce hallucination in abstractive summarization. The approach is based on two steps: hallucination detection and mitigation. We show that the former can be achieved through measuring simple statistics about conditional word probabilities and distance to context words. Further, we demonstrate that straight-forward backtracking is surprisingly effective at mitigation. We thoroughly evaluate the proposed method with prior art on three benchmark datasets for text summarization. The results show that CoBa is effective and efficient in reducing hallucination, and offers great adaptability and flexibility.
Pre-Training LiDAR-Based 3D Object Detectors Through Colorization
Oct 23, 2023
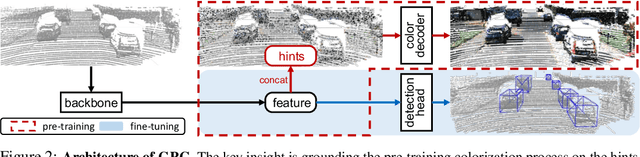
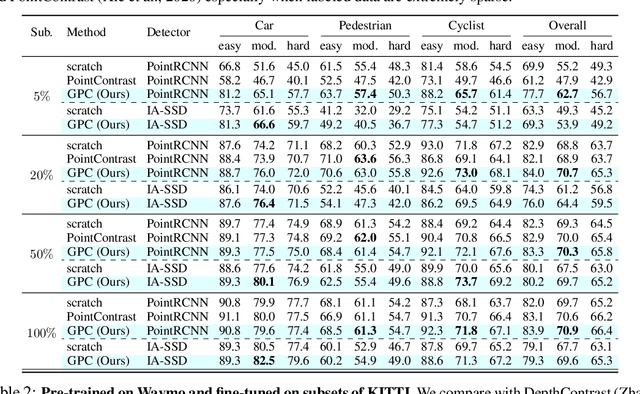

Accurate 3D object detection and understanding for self-driving cars heavily relies on LiDAR point clouds, necessitating large amounts of labeled data to train. In this work, we introduce an innovative pre-training approach, Grounded Point Colorization (GPC), to bridge the gap between data and labels by teaching the model to colorize LiDAR point clouds, equipping it with valuable semantic cues. To tackle challenges arising from color variations and selection bias, we incorporate color as "context" by providing ground-truth colors as hints during colorization. Experimental results on the KITTI and Waymo datasets demonstrate GPC's remarkable effectiveness. Even with limited labeled data, GPC significantly improves fine-tuning performance; notably, on just 20% of the KITTI dataset, GPC outperforms training from scratch with the entire dataset. In sum, we introduce a fresh perspective on pre-training for 3D object detection, aligning the objective with the model's intended role and ultimately advancing the accuracy and efficiency of 3D object detection for autonomous vehicles.
Unsupervised Domain Adaptation for Self-Driving from Past Traversal Features
Sep 21, 2023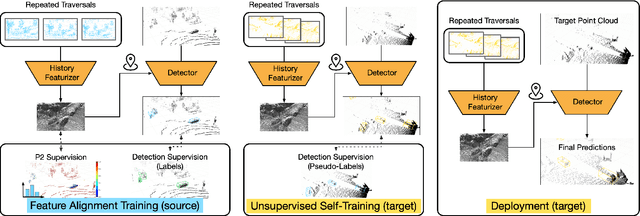
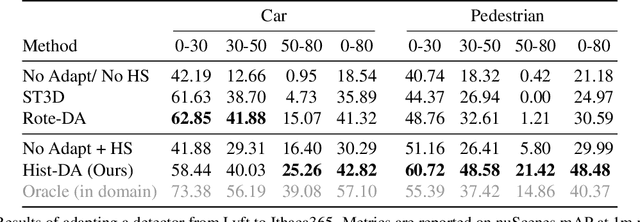
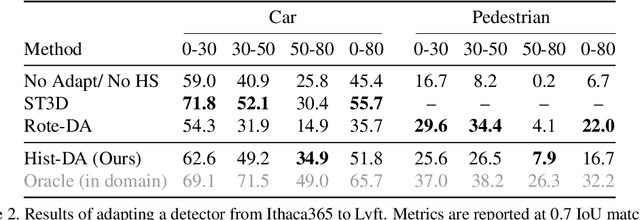
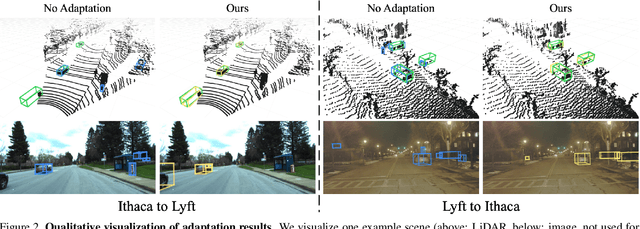
The rapid development of 3D object detection systems for self-driving cars has significantly improved accuracy. However, these systems struggle to generalize across diverse driving environments, which can lead to safety-critical failures in detecting traffic participants. To address this, we propose a method that utilizes unlabeled repeated traversals of multiple locations to adapt object detectors to new driving environments. By incorporating statistics computed from repeated LiDAR scans, we guide the adaptation process effectively. Our approach enhances LiDAR-based detection models using spatial quantized historical features and introduces a lightweight regression head to leverage the statistics for feature regularization. Additionally, we leverage the statistics for a novel self-training process to stabilize the training. The framework is detector model-agnostic and experiments on real-world datasets demonstrate significant improvements, achieving up to a 20-point performance gain, especially in detecting pedestrians and distant objects. Code is available at https://github.com/zhangtravis/Hist-DA.
On the Effectiveness of Offline RL for Dialogue Response Generation
Jul 23, 2023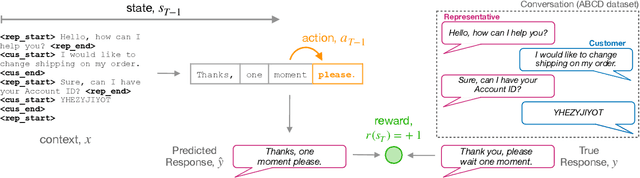
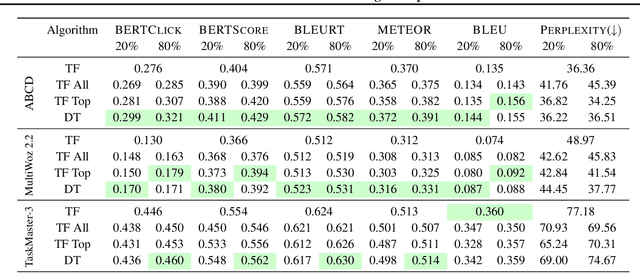
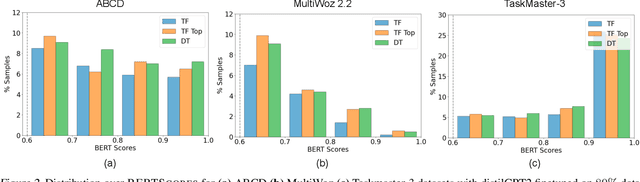

A common training technique for language models is teacher forcing (TF). TF attempts to match human language exactly, even though identical meanings can be expressed in different ways. This motivates use of sequence-level objectives for dialogue response generation. In this paper, we study the efficacy of various offline reinforcement learning (RL) methods to maximize such objectives. We present a comprehensive evaluation across multiple datasets, models, and metrics. Offline RL shows a clear performance improvement over teacher forcing while not inducing training instability or sacrificing practical training budgets.
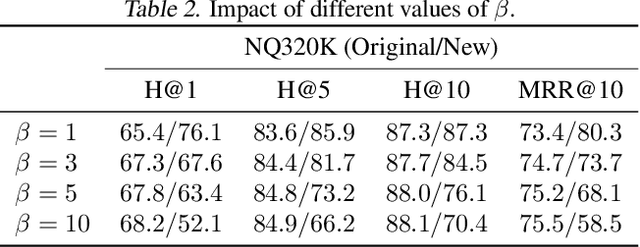
IncDSI: Incrementally Updatable Document Retrieval
Jul 19, 2023

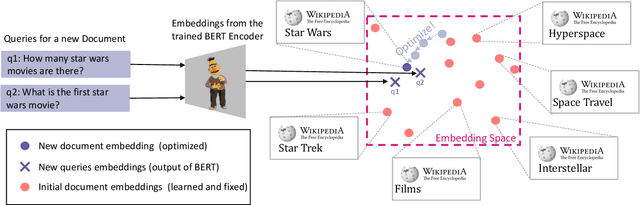
Differentiable Search Index is a recently proposed paradigm for document retrieval, that encodes information about a corpus of documents within the parameters of a neural network and directly maps queries to corresponding documents. These models have achieved state-of-the-art performances for document retrieval across many benchmarks. These kinds of models have a significant limitation: it is not easy to add new documents after a model is trained. We propose IncDSI, a method to add documents in real time (about 20-50ms per document), without retraining the model on the entire dataset (or even parts thereof). Instead we formulate the addition of documents as a constrained optimization problem that makes minimal changes to the network parameters. Although orders of magnitude faster, our approach is competitive with re-training the model on the whole dataset and enables the development of document retrieval systems that can be updated with new information in real-time. Our code for IncDSI is available at https://github.com/varshakishore/IncDSI.
Unsupervised Adaptation from Repeated Traversals for Autonomous Driving
Mar 27, 2023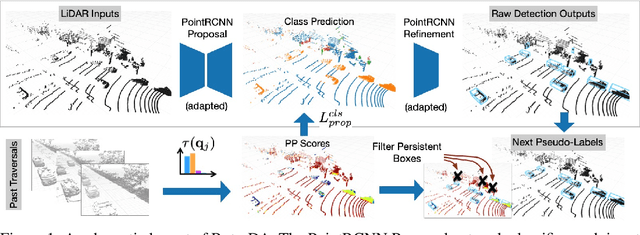

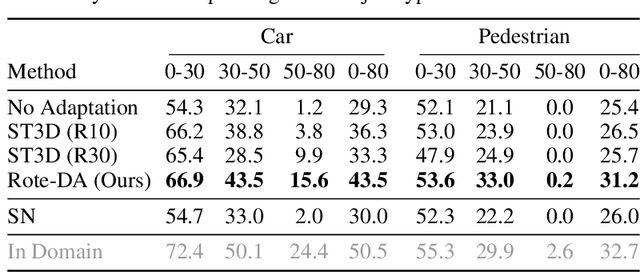
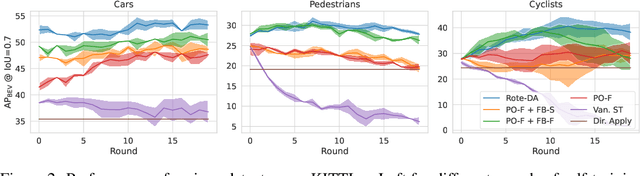
For a self-driving car to operate reliably, its perceptual system must generalize to the end-user's environment -- ideally without additional annotation efforts. One potential solution is to leverage unlabeled data (e.g., unlabeled LiDAR point clouds) collected from the end-users' environments (i.e. target domain) to adapt the system to the difference between training and testing environments. While extensive research has been done on such an unsupervised domain adaptation problem, one fundamental problem lingers: there is no reliable signal in the target domain to supervise the adaptation process. To overcome this issue we observe that it is easy to collect unsupervised data from multiple traversals of repeated routes. While different from conventional unsupervised domain adaptation, this assumption is extremely realistic since many drivers share the same roads. We show that this simple additional assumption is sufficient to obtain a potent signal that allows us to perform iterative self-training of 3D object detectors on the target domain. Concretely, we generate pseudo-labels with the out-of-domain detector but reduce false positives by removing detections of supposedly mobile objects that are persistent across traversals. Further, we reduce false negatives by encouraging predictions in regions that are not persistent. We experiment with our approach on two large-scale driving datasets and show remarkable improvement in 3D object detection of cars, pedestrians, and cyclists, bringing us a step closer to generalizable autonomous driving.