 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSriraj Badam
Fresh Content Needs More Attention: Multi-funnel Fresh Content Recommendation
Jun 02, 2023
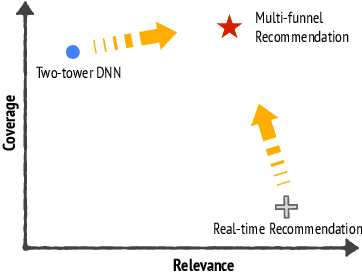
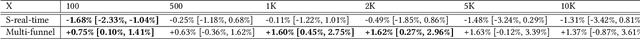
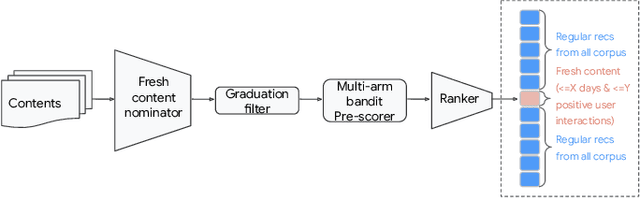

Recommendation system serves as a conduit connecting users to an incredibly large, diverse and ever growing collection of contents. In practice, missing information on fresh (and tail) contents needs to be filled in order for them to be exposed and discovered by their audience. We here share our success stories in building a dedicated fresh content recommendation stack on a large commercial platform. To nominate fresh contents, we built a multi-funnel nomination system that combines (i) a two-tower model with strong generalization power for coverage, and (ii) a sequence model with near real-time update on user feedback for relevance. The multi-funnel setup effectively balances between coverage and relevance. An in-depth study uncovers the relationship between user activity level and their proximity toward fresh contents, which further motivates a contextual multi-funnel setup. Nominated fresh candidates are then scored and ranked by systems considering prediction uncertainty to further bootstrap content with less exposure. We evaluate the benefits of the dedicated fresh content recommendation stack, and the multi-funnel nomination system in particular, through user corpus co-diverted live experiments. We conduct multiple rounds of live experiments on a commercial platform serving billion of users demonstrating efficacy of our proposed methods.
Value of Exploration: Measurements, Findings and Algorithms
May 12, 2023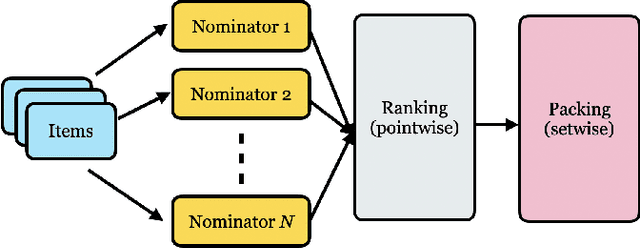

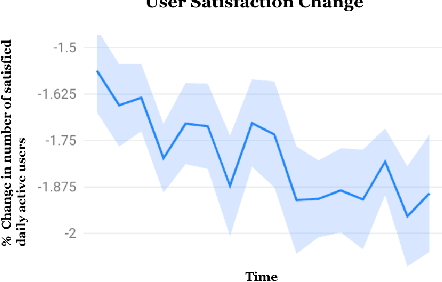
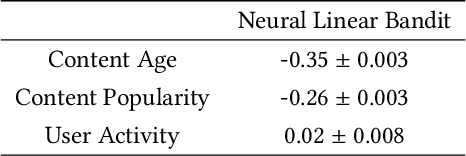
Effective exploration is believed to positively influence the long-term user experience on recommendation platforms. Determining its exact benefits, however, has been challenging. Regular A/B tests on exploration often measure neutral or even negative engagement metrics while failing to capture its long-term benefits. To address this, we present a systematic study to formally quantify the value of exploration by examining its effects on the content corpus, a key entity in the recommender system that directly affects user experiences. Specifically, we introduce new metrics and the associated experiment design to measure the benefit of exploration on the corpus change, and further connect the corpus change to the long-term user experience. Furthermore, we investigate the possibility of introducing the Neural Linear Bandit algorithm to build an exploration-based ranking system, and use it as the backbone algorithm for our case study. We conduct extensive live experiments on a large-scale commercial recommendation platform that serves billions of users to validate the new experiment designs, quantify the long-term values of exploration, and to verify the effectiveness of the adopted neural linear bandit algorithm for exploration.
Reward Shaping for User Satisfaction in a REINFORCE Recommender
Sep 30, 2022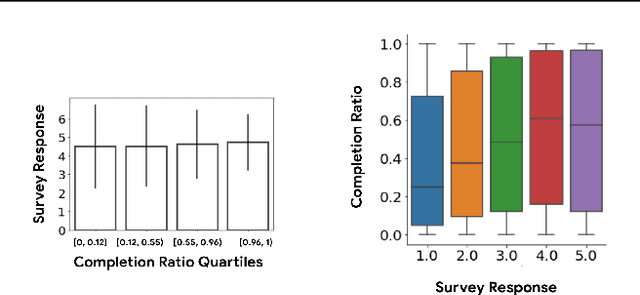
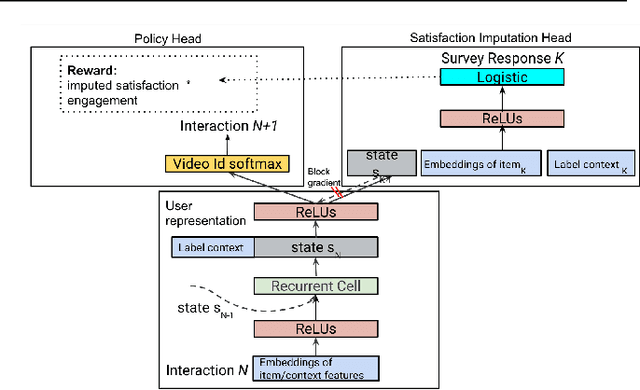
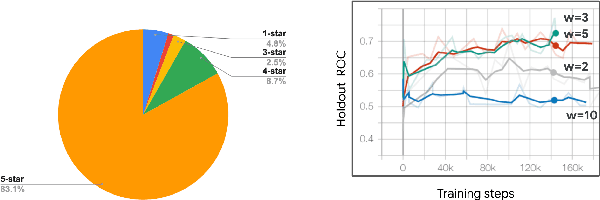
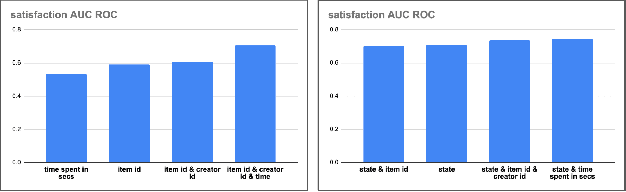
How might we design Reinforcement Learning (RL)-based recommenders that encourage aligning user trajectories with the underlying user satisfaction? Three research questions are key: (1) measuring user satisfaction, (2) combatting sparsity of satisfaction signals, and (3) adapting the training of the recommender agent to maximize satisfaction. For measurement, it has been found that surveys explicitly asking users to rate their experience with consumed items can provide valuable orthogonal information to the engagement/interaction data, acting as a proxy to the underlying user satisfaction. For sparsity, i.e, only being able to observe how satisfied users are with a tiny fraction of user-item interactions, imputation models can be useful in predicting satisfaction level for all items users have consumed. For learning satisfying recommender policies, we postulate that reward shaping in RL recommender agents is powerful for driving satisfying user experiences. Putting everything together, we propose to jointly learn a policy network and a satisfaction imputation network: The role of the imputation network is to learn which actions are satisfying to the user; while the policy network, built on top of REINFORCE, decides which items to recommend, with the reward utilizing the imputed satisfaction. We use both offline analysis and live experiments in an industrial large-scale recommendation platform to demonstrate the promise of our approach for satisfying user experiences.
Recency Dropout for Recurrent Recommender Systems
Jan 26, 2022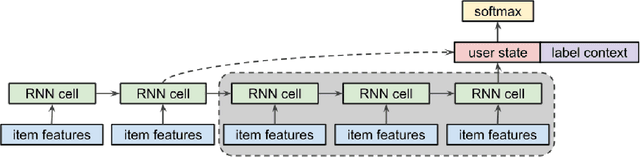
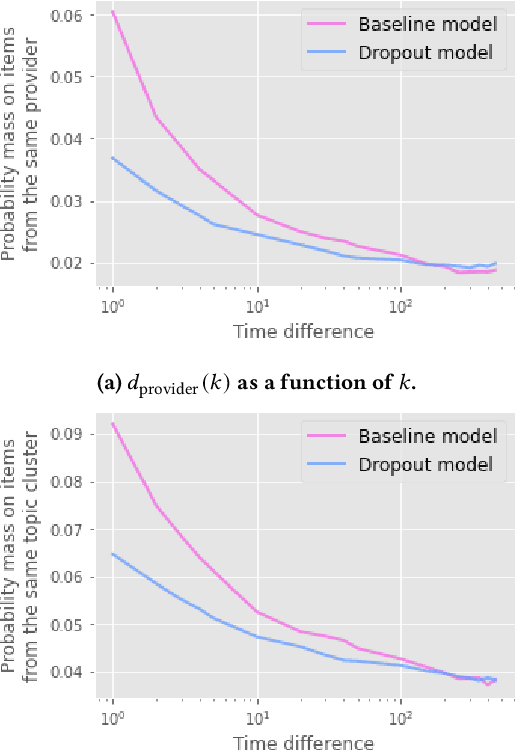
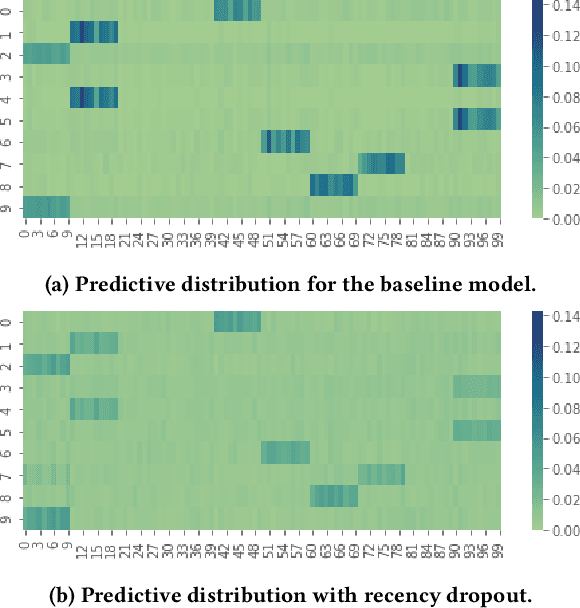
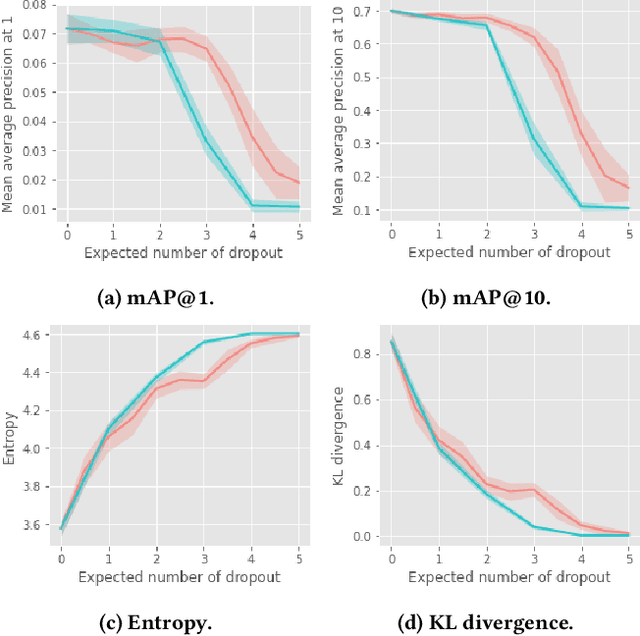
Recurrent recommender systems have been successful in capturing the temporal dynamics in users' activity trajectories. However, recurrent neural networks (RNNs) are known to have difficulty learning long-term dependencies. As a consequence, RNN-based recommender systems tend to overly focus on short-term user interests. This is referred to as the recency bias, which could negatively affect the long-term user experience as well as the health of the ecosystem. In this paper, we introduce the recency dropout technique, a simple yet effective data augmentation technique to alleviate the recency bias in recurrent recommender systems. We demonstrate the effectiveness of recency dropout in various experimental settings including a simulation study, offline experiments, as well as live experiments on a large-scale industrial recommendation platform.