 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianling Wang
Empowering Large Language Models for Textual Data Augmentation
Apr 26, 2024
With the capabilities of understanding and executing natural language instructions, Large language models (LLMs) can potentially act as a powerful tool for textual data augmentation. However, the quality of augmented data depends heavily on the augmentation instructions provided, and the effectiveness can fluctuate across different downstream tasks. While manually crafting and selecting instructions can offer some improvement, this approach faces scalability and consistency issues in practice due to the diversity of downstream tasks. In this work, we address these limitations by proposing a new solution, which can automatically generate a large pool of augmentation instructions and select the most suitable task-informed instructions, thereby empowering LLMs to create high-quality augmented data for different downstream tasks. Empirically, the proposed approach consistently generates augmented data with better quality compared to non-LLM and LLM-based data augmentation methods, leading to the best performance on 26 few-shot learning tasks sourced from a wide range of application domains.
Countering Mainstream Bias via End-to-End Adaptive Local Learning
Apr 13, 2024Collaborative filtering (CF) based recommendations suffer from mainstream bias -- where mainstream users are favored over niche users, leading to poor recommendation quality for many long-tail users. In this paper, we identify two root causes of this mainstream bias: (i) discrepancy modeling, whereby CF algorithms focus on modeling mainstream users while neglecting niche users with unique preferences; and (ii) unsynchronized learning, where niche users require more training epochs than mainstream users to reach peak performance. Targeting these causes, we propose a novel end-To-end Adaptive Local Learning (TALL) framework to provide high-quality recommendations to both mainstream and niche users. TALL uses a loss-driven Mixture-of-Experts module to adaptively ensemble experts to provide customized local models for different users. Further, it contains an adaptive weight module to synchronize the learning paces of different users by dynamically adjusting weights in the loss. Extensive experiments demonstrate the state-of-the-art performance of the proposed model. Code and data are provided at \url{https://github.com/JP-25/end-To-end-Adaptive-Local-Leanring-TALL-}
* ECIR 2024
Mamba4Rec: Towards Efficient Sequential Recommendation with Selective State Space Models
Mar 06, 2024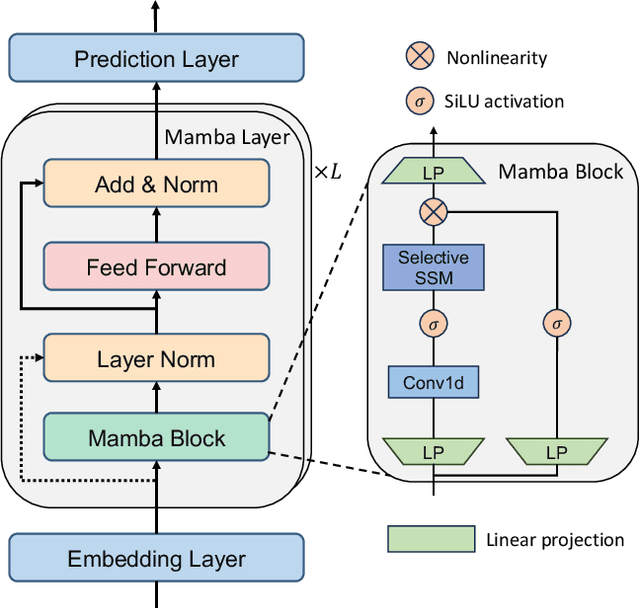



Sequential recommendation aims to estimate the dynamic user preferences and sequential dependencies among historical user behaviors. Although Transformer-based models have proven to be effective for sequential recommendation, they suffer from the inference inefficiency problem stemming from the quadratic computational complexity of attention operators, especially for long-range behavior sequences. Inspired by the recent success of state space models (SSMs), we propose Mamba4Rec, which is the first work to explore the potential of selective SSMs for efficient sequential recommendation. Built upon the basic Mamba block which is a selective SSM with an efficient hardware-aware parallel algorithm, we incorporate a series of sequential modeling techniques to further promote the model performance and meanwhile maintain the inference efficiency. Experiments on two public datasets demonstrate that Mamba4Rec is able to well address the effectiveness-efficiency dilemma, and defeat both RNN- and attention-based baselines in terms of both effectiveness and efficiency.
Large Language Models as Data Augmenters for Cold-Start Item Recommendation
Feb 18, 2024The reasoning and generalization capabilities of LLMs can help us better understand user preferences and item characteristics, offering exciting prospects to enhance recommendation systems. Though effective while user-item interactions are abundant, conventional recommendation systems struggle to recommend cold-start items without historical interactions. To address this, we propose utilizing LLMs as data augmenters to bridge the knowledge gap on cold-start items during training. We employ LLMs to infer user preferences for cold-start items based on textual description of user historical behaviors and new item descriptions. The augmented training signals are then incorporated into learning the downstream recommendation models through an auxiliary pairwise loss. Through experiments on public Amazon datasets, we demonstrate that LLMs can effectively augment the training signals for cold-start items, leading to significant improvements in cold-start item recommendation for various recommendation models.
Everything Perturbed All at Once: Enabling Differentiable Graph Attacks
Aug 29, 2023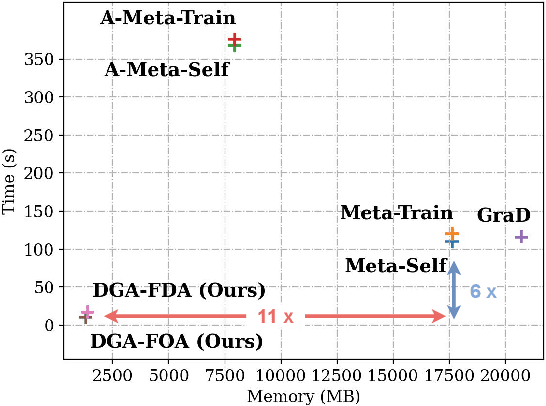
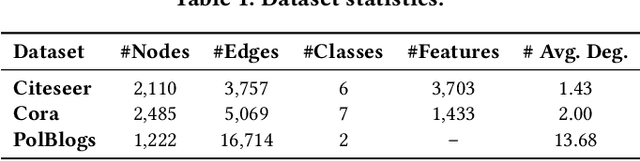
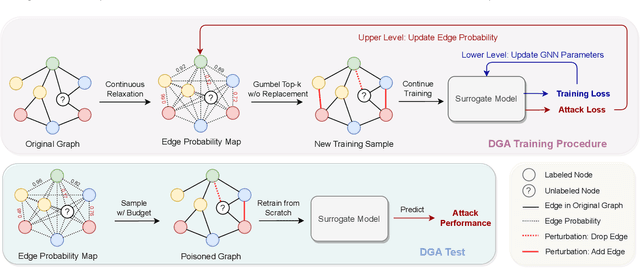
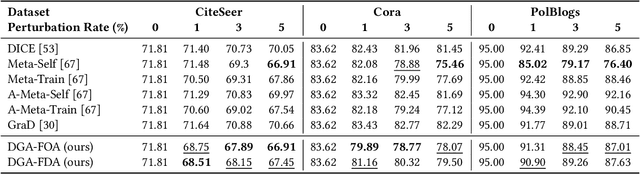
As powerful tools for representation learning on graphs, graph neural networks (GNNs) have played an important role in applications including social networks, recommendation systems, and online web services. However, GNNs have been shown to be vulnerable to adversarial attacks, which can significantly degrade their effectiveness. Recent state-of-the-art approaches in adversarial attacks rely on gradient-based meta-learning to selectively perturb a single edge with the highest attack score until they reach the budget constraint. While effective in identifying vulnerable links, these methods are plagued by high computational costs. By leveraging continuous relaxation and parameterization of the graph structure, we propose a novel attack method called Differentiable Graph Attack (DGA) to efficiently generate effective attacks and meanwhile eliminate the need for costly retraining. Compared to the state-of-the-art, DGA achieves nearly equivalent attack performance with 6 times less training time and 11 times smaller GPU memory footprint on different benchmark datasets. Additionally, we provide extensive experimental analyses of the transferability of the DGA among different graph models, as well as its robustness against widely-used defense mechanisms.
Fresh Content Needs More Attention: Multi-funnel Fresh Content Recommendation
Jun 02, 2023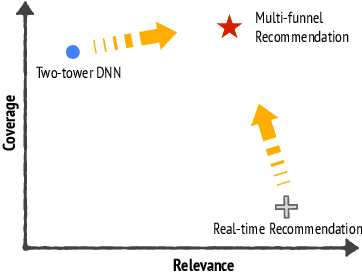
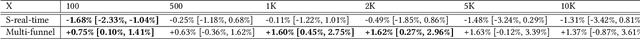
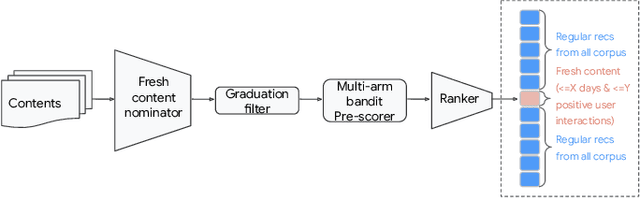

Recommendation system serves as a conduit connecting users to an incredibly large, diverse and ever growing collection of contents. In practice, missing information on fresh (and tail) contents needs to be filled in order for them to be exposed and discovered by their audience. We here share our success stories in building a dedicated fresh content recommendation stack on a large commercial platform. To nominate fresh contents, we built a multi-funnel nomination system that combines (i) a two-tower model with strong generalization power for coverage, and (ii) a sequence model with near real-time update on user feedback for relevance. The multi-funnel setup effectively balances between coverage and relevance. An in-depth study uncovers the relationship between user activity level and their proximity toward fresh contents, which further motivates a contextual multi-funnel setup. Nominated fresh candidates are then scored and ranked by systems considering prediction uncertainty to further bootstrap content with less exposure. We evaluate the benefits of the dedicated fresh content recommendation stack, and the multi-funnel nomination system in particular, through user corpus co-diverted live experiments. We conduct multiple rounds of live experiments on a commercial platform serving billion of users demonstrating efficacy of our proposed methods.
Learning Strong Graph Neural Networks with Weak Information
May 29, 2023



Graph Neural Networks (GNNs) have exhibited impressive performance in many graph learning tasks. Nevertheless, the performance of GNNs can deteriorate when the input graph data suffer from weak information, i.e., incomplete structure, incomplete features, and insufficient labels. Most prior studies, which attempt to learn from the graph data with a specific type of weak information, are far from effective in dealing with the scenario where diverse data deficiencies exist and mutually affect each other. To fill the gap, in this paper, we aim to develop an effective and principled approach to the problem of graph learning with weak information (GLWI). Based on the findings from our empirical analysis, we derive two design focal points for solving the problem of GLWI, i.e., enabling long-range propagation in GNNs and allowing information propagation to those stray nodes isolated from the largest connected component. Accordingly, we propose D$^2$PT, a dual-channel GNN framework that performs long-range information propagation not only on the input graph with incomplete structure, but also on a global graph that encodes global semantic similarities. We further develop a prototype contrastive alignment algorithm that aligns the class-level prototypes learned from two channels, such that the two different information propagation processes can mutually benefit from each other and the finally learned model can well handle the GLWI problem. Extensive experiments on eight real-world benchmark datasets demonstrate the effectiveness and efficiency of our proposed methods in various GLWI scenarios.
Enhancing User Personalization in Conversational Recommenders
Feb 13, 2023



Conversational recommenders are emerging as a powerful tool to personalize a user's recommendation experience. Through a back-and-forth dialogue, users can quickly hone in on just the right items. Many approaches to conversational recommendation, however, only partially explore the user preference space and make limiting assumptions about how user feedback can be best incorporated, resulting in long dialogues and poor recommendation performance. In this paper, we propose a novel conversational recommendation framework with two unique features: (i) a greedy NDCG attribute selector, to enhance user personalization in the interactive preference elicitation process by prioritizing attributes that most effectively represent the actual preference space of the user; and (ii) a user representation refiner, to effectively fuse together the user preferences collected from the interactive elicitation process to obtain a more personalized understanding of the user. Through extensive experiments on four frequently used datasets, we find the proposed framework not only outperforms all the state-of-the-art conversational recommenders (in terms of both recommendation performance and conversation efficiency), but also provides a more personalized experience for the user under the proposed multi-groundtruth multi-round conversational recommendation setting.
Closed-book Question Generation via Contrastive Learning
Oct 13, 2022



Question Generation (QG) is a fundamental NLP task for many downstream applications. Recent studies on open-book QG, where supportive question-context pairs are provided to models, have achieved promising progress. However, generating natural questions under a more practical closed-book setting that lacks these supporting documents still remains a challenge. In this work, to learn better representations from semantic information hidden in question-answer pairs under the closed-book setting, we propose a new QG model empowered by a contrastive learning module and an answer reconstruction module. We present a new closed-book QA dataset -- WikiCQA involving abstractive long answers collected from a wiki-style website. In the experiments, we validate the proposed QG model on both public datasets and the new WikiCQA dataset. Empirical results show that the proposed QG model outperforms baselines in both automatic evaluation and human evaluation. In addition, we show how to leverage the proposed model to improve existing closed-book QA systems. We observe that by pre-training a closed-book QA model on our generated synthetic QA pairs, significant QA improvement can be achieved on both seen and unseen datasets, which further demonstrates the effectiveness of our QG model for enhancing unsupervised and semi-supervised QA.
Towards Fair Conversational Recommender Systems
Aug 08, 2022
Conversational recommender systems have demonstrated great success. They can accurately capture a user's current detailed preference - through a multi-round interaction cycle - to effectively guide users to a more personalized recommendation. Alas, conversational recommender systems can be plagued by the adverse effects of bias, much like traditional recommenders. In this work, we argue for increased attention on the presence of and methods for counteracting bias in these emerging systems. As a starting point, we propose three fundamental questions that should be deeply examined to enable fairness in conversational recommender systems.