 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenhui Zhu
TimeMIL: Advancing Multivariate Time Series Classification via a Time-aware Multiple Instance Learning
May 06, 2024
Deep neural networks, including transformers and convolutional neural networks, have significantly improved multivariate time series classification (MTSC). However, these methods often rely on supervised learning, which does not fully account for the sparsity and locality of patterns in time series data (e.g., diseases-related anomalous points in ECG). To address this challenge, we formally reformulate MTSC as a weakly supervised problem, introducing a novel multiple-instance learning (MIL) framework for better localization of patterns of interest and modeling time dependencies within time series. Our novel approach, TimeMIL, formulates the temporal correlation and ordering within a time-aware MIL pooling, leveraging a tokenized transformer with a specialized learnable wavelet positional token. The proposed method surpassed 26 recent state-of-the-art methods, underscoring the effectiveness of the weakly supervised TimeMIL in MTSC.
Imaging Signal Recovery Using Neural Network Priors Under Uncertain Forward Model Parameters
May 05, 2024Inverse imaging problems (IIPs) arise in various applications, with the main objective of reconstructing an image from its compressed measurements. This problem is often ill-posed for being under-determined with multiple interchangeably consistent solutions. The best solution inherently depends on prior knowledge or assumptions, such as the sparsity of the image. Furthermore, the reconstruction process for most IIPs relies significantly on the imaging (i.e. forward model) parameters, which might not be fully known, or the measurement device may undergo calibration drifts. These uncertainties in the forward model create substantial challenges, where inaccurate reconstructions usually happen when the postulated parameters of the forward model do not fully match the actual ones. In this work, we devoted to tackling accurate reconstruction under the context of a set of possible forward model parameters that exist. Here, we propose a novel Moment-Aggregation (MA) framework that is compatible with the popular IIP solution by using a neural network prior. Specifically, our method can reconstruct the signal by considering all candidate parameters of the forward model simultaneously during the update of the neural network. We theoretically demonstrate the convergence of the MA framework, which has a similar complexity with reconstruction under the known forward model parameters. Proof-of-concept experiments demonstrate that the proposed MA achieves performance comparable to the forward model with the known precise parameter in reconstruction across both compressive sensing and phase retrieval applications, with a PSNR gap of 0.17 to 1.94 over various datasets, including MNIST, X-ray, Glas, and MoNuseg. This highlights our method's significant potential in reconstruction under an uncertain forward model.
Reconstructing Retinal Visual Images from 3T fMRI Data Enhanced by Unsupervised Learning
Apr 07, 2024The reconstruction of human visual inputs from brain activity, particularly through functional Magnetic Resonance Imaging (fMRI), holds promising avenues for unraveling the mechanisms of the human visual system. Despite the significant strides made by deep learning methods in improving the quality and interpretability of visual reconstruction, there remains a substantial demand for high-quality, long-duration, subject-specific 7-Tesla fMRI experiments. The challenge arises in integrating diverse smaller 3-Tesla datasets or accommodating new subjects with brief and low-quality fMRI scans. In response to these constraints, we propose a novel framework that generates enhanced 3T fMRI data through an unsupervised Generative Adversarial Network (GAN), leveraging unpaired training across two distinct fMRI datasets in 7T and 3T, respectively. This approach aims to overcome the limitations of the scarcity of high-quality 7-Tesla data and the challenges associated with brief and low-quality scans in 3-Tesla experiments. In this paper, we demonstrate the reconstruction capabilities of the enhanced 3T fMRI data, highlighting its proficiency in generating superior input visual images compared to data-intensive methods trained and tested on a single subject.
* Accepted by ISBI 2024
SC-MIL: Sparsely Coded Multiple Instance Learning for Whole Slide Image Classification
Oct 31, 2023Multiple Instance Learning (MIL) has been widely used in weakly supervised whole slide image (WSI) classification. Typical MIL methods include a feature embedding part that embeds the instances into features via a pre-trained feature extractor and the MIL aggregator that combines instance embeddings into predictions. The current focus has been directed toward improving these parts by refining the feature embeddings through self-supervised pre-training and modeling the correlations between instances separately. In this paper, we proposed a sparsely coded MIL (SC-MIL) that addresses those two aspects at the same time by leveraging sparse dictionary learning. The sparse dictionary learning captures the similarities of instances by expressing them as a sparse linear combination of atoms in an over-complete dictionary. In addition, imposing sparsity help enhance the instance feature embeddings by suppressing irrelevant instances while retaining the most relevant ones. To make the conventional sparse coding algorithm compatible with deep learning, we unrolled it into an SC module by leveraging deep unrolling. The proposed SC module can be incorporated into any existing MIL framework in a plug-and-play manner with an acceptable computation cost. The experimental results on multiple datasets demonstrated that the proposed SC module could substantially boost the performance of state-of-the-art MIL methods. The codes are available at \href{https://github.com/sotiraslab/SCMIL.git}{https://github.com/sotiraslab/SCMIL.git}.
PDL: Regularizing Multiple Instance Learning with Progressive Dropout Layers
Aug 19, 2023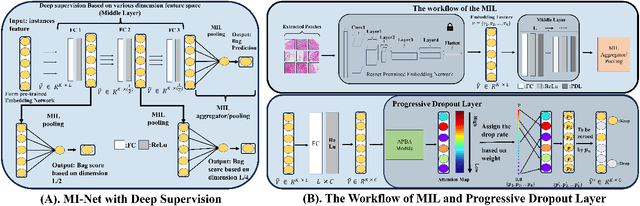
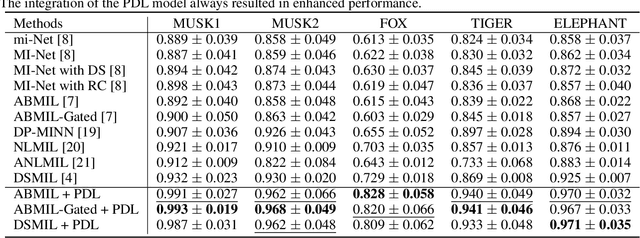
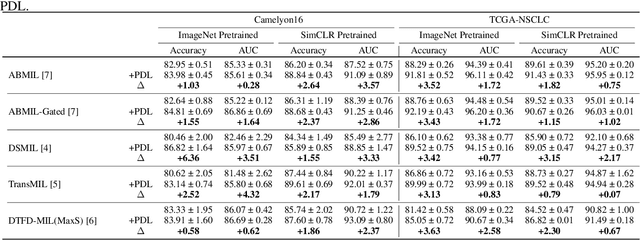
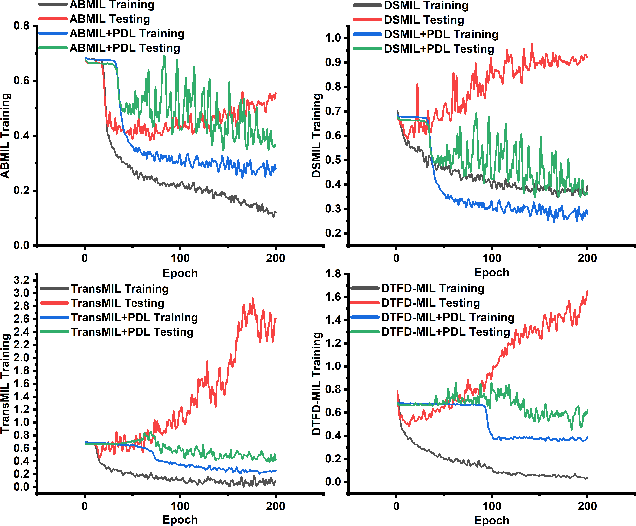
Multiple instance learning (MIL) was a weakly supervised learning approach that sought to assign binary class labels to collections of instances known as bags. However, due to their weak supervision nature, the MIL methods were susceptible to overfitting and required assistance in developing comprehensive representations of target instances. While regularization typically effectively combated overfitting, its integration with the MIL model has been frequently overlooked in prior studies. Meanwhile, current regularization methods for MIL have shown limitations in their capacity to uncover a diverse array of representations. In this study, we delve into the realm of regularization within the MIL model, presenting a novel approach in the form of a Progressive Dropout Layer (PDL). We aim to not only address overfitting but also empower the MIL model in uncovering intricate and impactful feature representations. The proposed method was orthogonal to existing MIL methods and could be easily integrated into them to boost performance. Our extensive evaluation across a range of MIL benchmark datasets demonstrated that the incorporation of the PDL into multiple MIL methods not only elevated their classification performance but also augmented their potential for weakly-supervised feature localizations.
NNMobile-Net: Rethinking CNN Design for Deep Learning-Based Retinopathy Research
Jun 02, 2023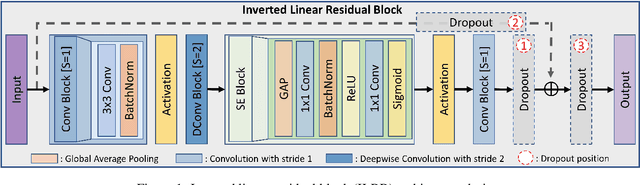
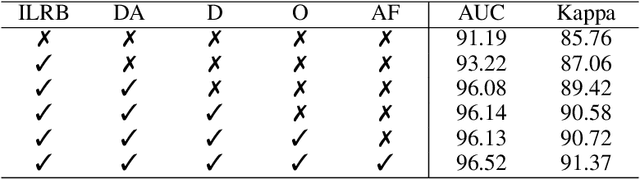
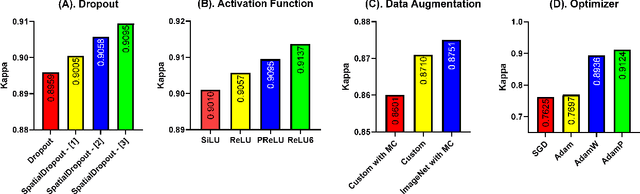
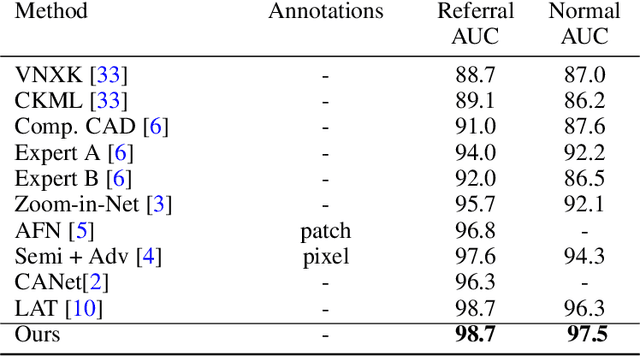
Retinal diseases (RD) are the leading cause of severe vision loss or blindness. Deep learning-based automated tools play an indispensable role in assisting clinicians in diagnosing and monitoring RD in modern medicine. Recently, an increasing number of works in this field have taken advantage of Vision Transformer to achieve state-of-the-art performance with more parameters and higher model complexity compared to Convolutional Neural Networks (CNNs). Such sophisticated and task-specific model designs, however, are prone to be overfitting and hinder their generalizability. In this work, we argue that a channel-aware and well-calibrated CNN model may overcome these problems. To this end, we empirically studied CNN's macro and micro designs and its training strategies. Based on the investigation, we proposed a no-new-MobleNet (nn-MobileNet) developed for retinal diseases. In our experiments, our generic, simple and efficient model superseded most current state-of-the-art methods on four public datasets for multiple tasks, including diabetic retinopathy grading, fundus multi-disease detection, and diabetic macular edema classification. Our work may provide novel insights into deep learning architecture design and advance retinopathy research.
A Surface-Based Federated Chow Test Model for Integrating APOE Status, Tau Deposition Measure, and Hippocampal Surface Morphometry
Mar 31, 2023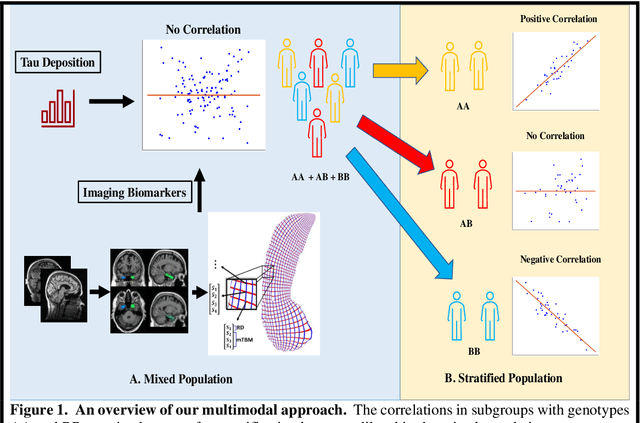
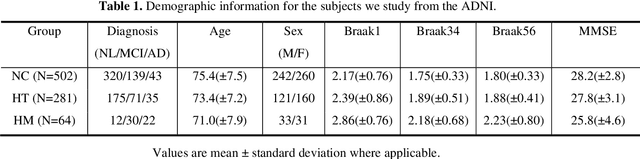
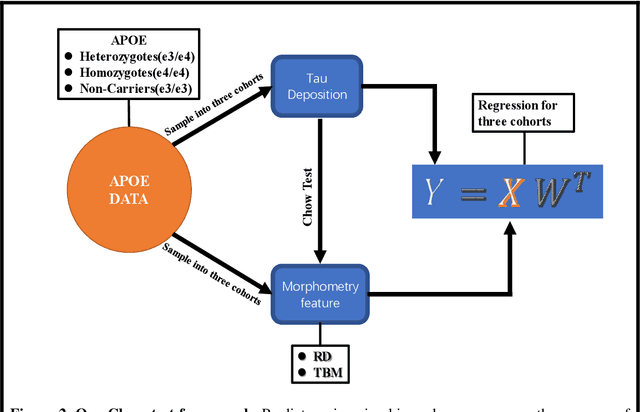
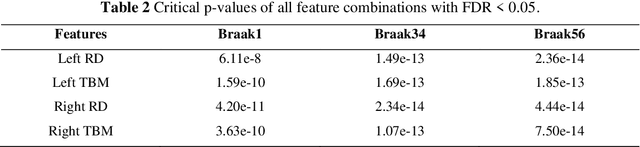
Background: Alzheimer's Disease (AD) is the most common type of age-related dementia, affecting 6.2 million people aged 65 or older according to CDC data. It is commonly agreed that discovering an effective AD diagnosis biomarker could have enormous public health benefits, potentially preventing or delaying up to 40% of dementia cases. Tau neurofibrillary tangles are the primary driver of downstream neurodegeneration and subsequent cognitive impairment in AD, resulting in structural deformations such as hippocampal atrophy that can be observed in magnetic resonance imaging (MRI) scans. Objective: To build a surface-based model to 1) detect differences between APOE subgroups in patterns of tau deposition and hippocampal atrophy, and 2) use the extracted surface-based features to predict cognitive decline. Methods: Using data obtained from different institutions, we develop a surface-based federated Chow test model to study the synergistic effects of APOE, a previously reported significant risk factor of AD, and tau on hippocampal surface morphometry. Results: We illustrate that the APOE-specific morphometry features correlate with AD progression and better predict future AD conversion than other MRI biomarkers. For example, a strong association between atrophy and abnormal tau was identified in hippocampal subregion cornu ammonis 1 (CA1 subfield) and subiculum in e4 homozygote cohort. Conclusion: Our model allows for identifying MRI biomarkers for AD and cognitive decline prediction and may uncover a corner of the neural mechanism of the influence of APOE and tau deposition on hippocampal morphology.
TetCNN: Convolutional Neural Networks on Tetrahedral Meshes
Feb 14, 2023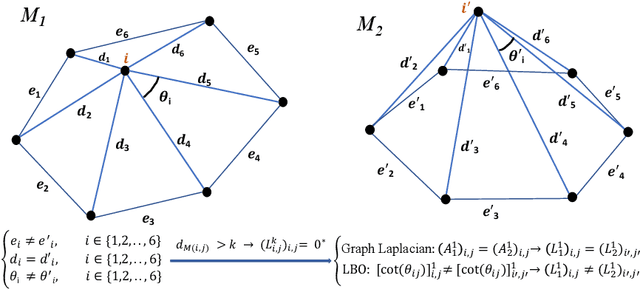
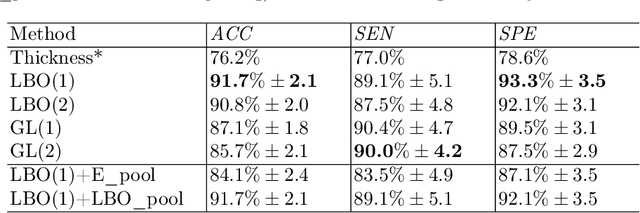
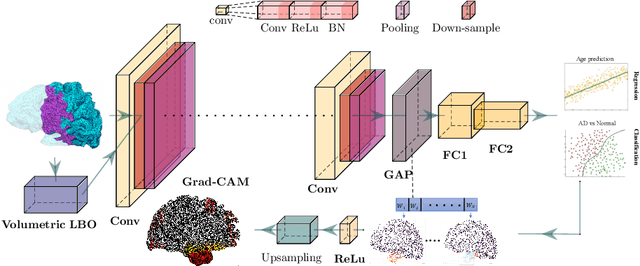
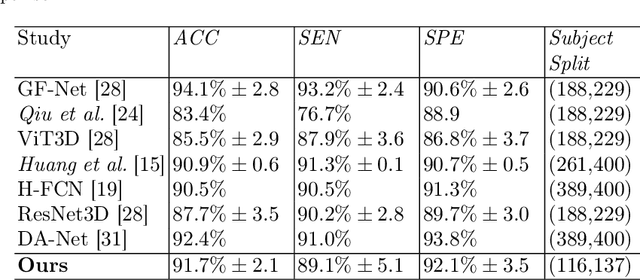
Convolutional neural networks (CNN) have been broadly studied on images, videos, graphs, and triangular meshes. However, it has seldom been studied on tetrahedral meshes. Given the merits of using volumetric meshes in applications like brain image analysis, we introduce a novel interpretable graph CNN framework for the tetrahedral mesh structure. Inspired by ChebyNet, our model exploits the volumetric Laplace-Beltrami Operator (LBO) to define filters over commonly used graph Laplacian which lacks the Riemannian metric information of 3D manifolds. For pooling adaptation, we introduce new objective functions for localized minimum cuts in the Graclus algorithm based on the LBO. We employ a piece-wise constant approximation scheme that uses the clustering assignment matrix to estimate the LBO on sampled meshes after each pooling. Finally, adapting the Gradient-weighted Class Activation Mapping algorithm for tetrahedral meshes, we use the obtained heatmaps to visualize discovered regions-of-interest as biomarkers. We demonstrate the effectiveness of our model on cortical tetrahedral meshes from patients with Alzheimer's disease, as there is scientific evidence showing the correlation of cortical thickness to neurodegenerative disease progression. Our results show the superiority of our LBO-based convolution layer and adapted pooling over the conventionally used unitary cortical thickness, graph Laplacian, and point cloud representation.
OTRE: Where Optimal Transport Guided Unpaired Image-to-Image Translation Meets Regularization by Enhancing
Feb 09, 2023



Non-mydriatic retinal color fundus photography (CFP) is widely available due to the advantage of not requiring pupillary dilation, however, is prone to poor quality due to operators, systemic imperfections, or patient-related causes. Optimal retinal image quality is mandated for accurate medical diagnoses and automated analyses. Herein, we leveraged the Optimal Transport (OT) theory to propose an unpaired image-to-image translation scheme for mapping low-quality retinal CFPs to high-quality counterparts. Furthermore, to improve the flexibility, robustness, and applicability of our image enhancement pipeline in the clinical practice, we generalized a state-of-the-art model-based image reconstruction method, regularization by denoising, by plugging in priors learned by our OT-guided image-to-image translation network. We named it as regularization by enhancing (RE). We validated the integrated framework, OTRE, on three publicly available retinal image datasets by assessing the quality after enhancement and their performance on various downstream tasks, including diabetic retinopathy grading, vessel segmentation, and diabetic lesion segmentation. The experimental results demonstrated the superiority of our proposed framework over some state-of-the-art unsupervised competitors and a state-of-the-art supervised method.
Optimal Transport Guided Unsupervised Learning for Enhancing low-quality Retinal Images
Feb 06, 2023



Real-world non-mydriatic retinal fundus photography is prone to artifacts, imperfections and low-quality when certain ocular or systemic co-morbidities exist. Artifacts may result in inaccuracy or ambiguity in clinical diagnoses. In this paper, we proposed a simple but effective end-to-end framework for enhancing poor-quality retinal fundus images. Leveraging the optimal transport theory, we proposed an unpaired image-to-image translation scheme for transporting low-quality images to their high-quality counterparts. We theoretically proved that a Generative Adversarial Networks (GAN) model with a generator and discriminator is sufficient for this task. Furthermore, to mitigate the inconsistency of information between the low-quality images and their enhancements, an information consistency mechanism was proposed to maximally maintain structural consistency (optical discs, blood vessels, lesions) between the source and enhanced domains. Extensive experiments were conducted on the EyeQ dataset to demonstrate the superiority of our proposed method perceptually and quantitatively.